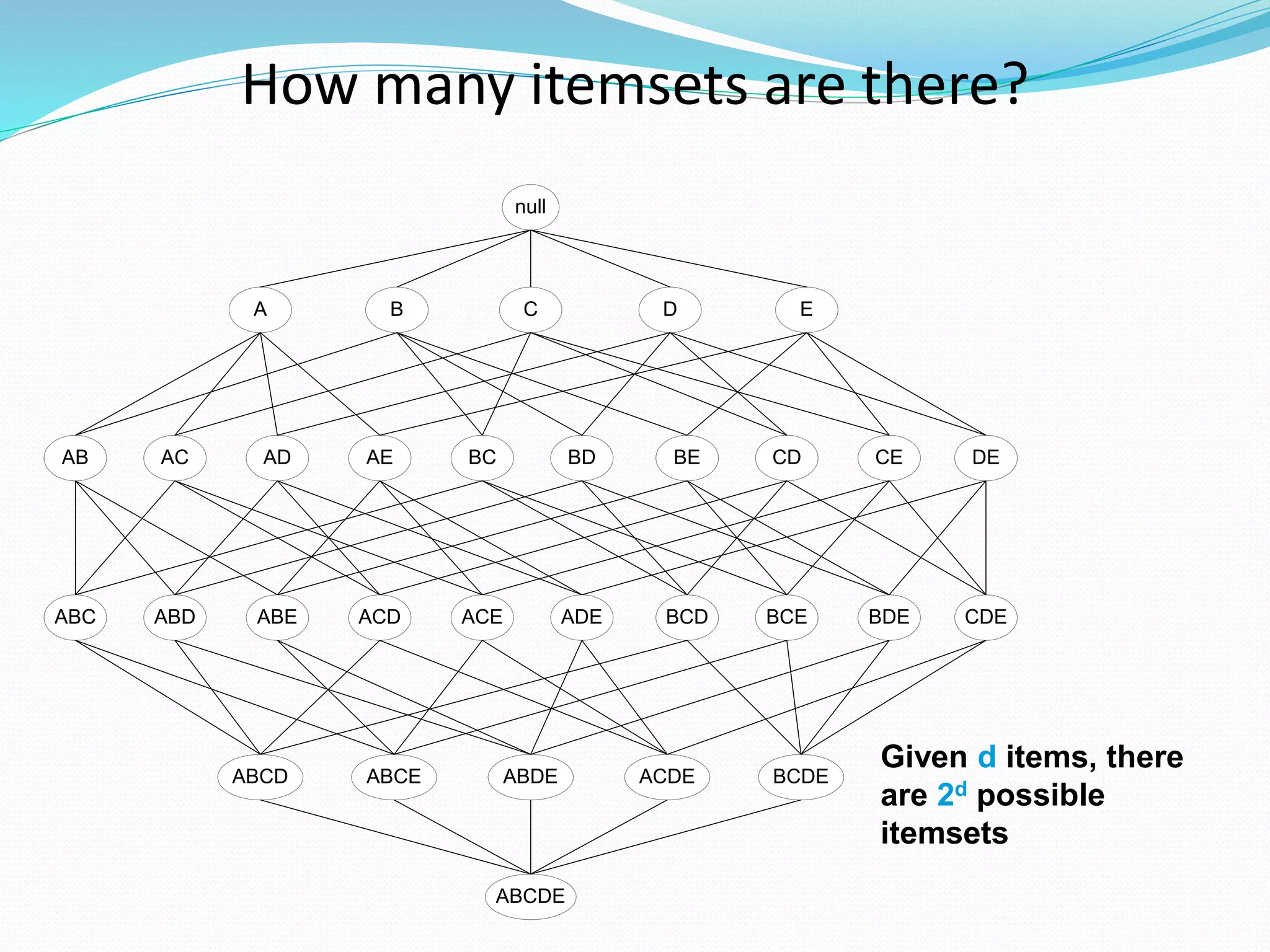
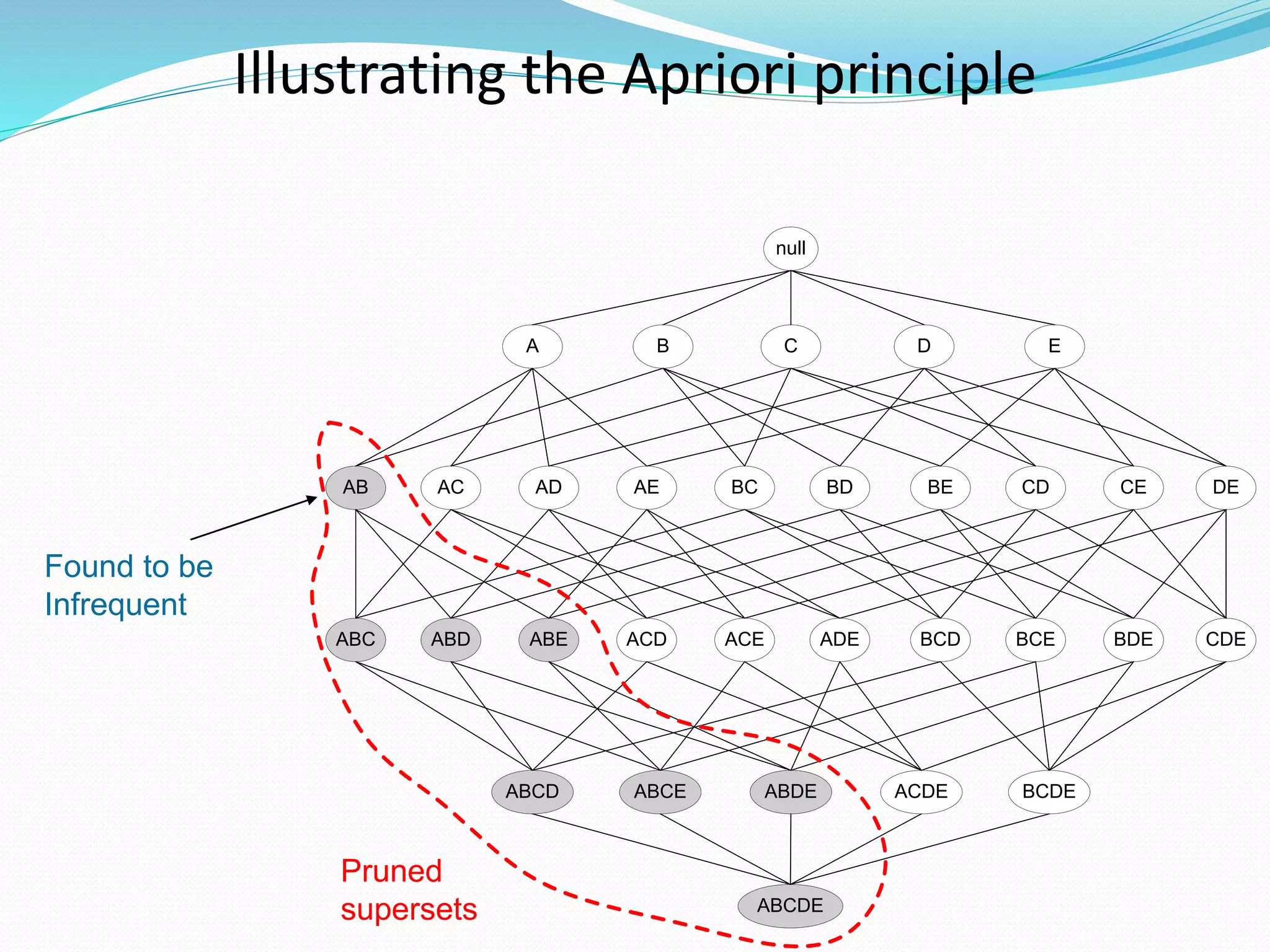
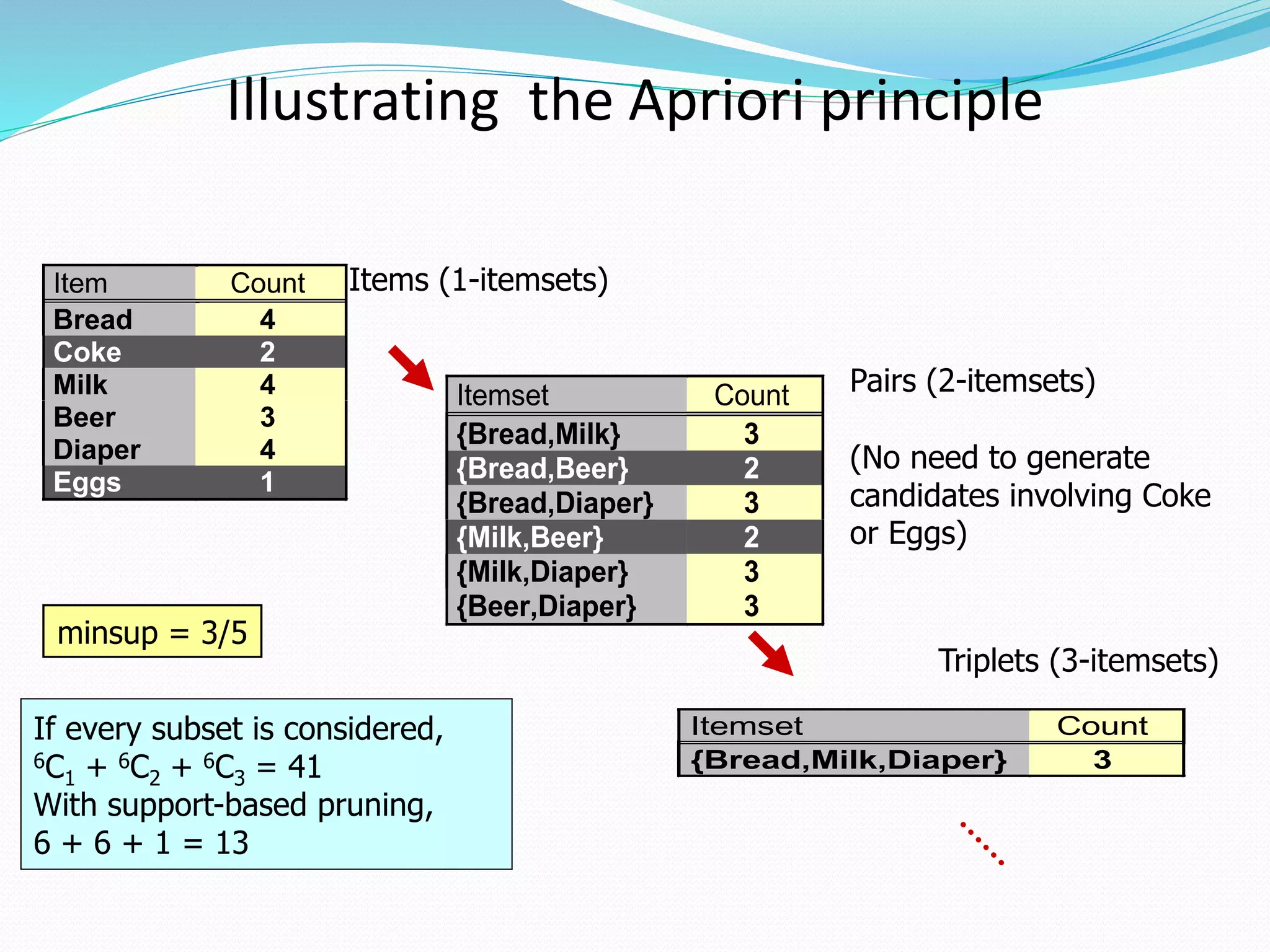
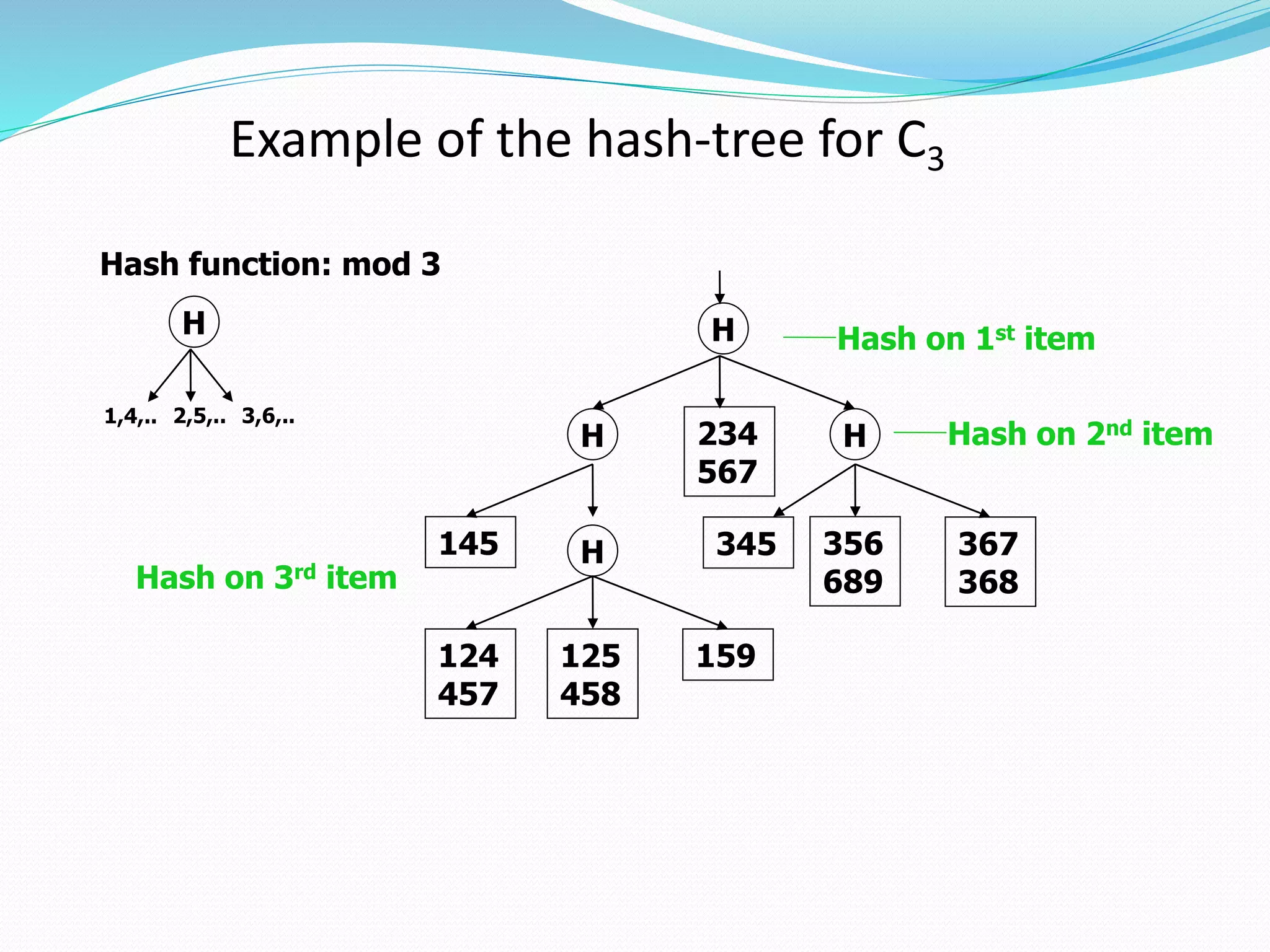
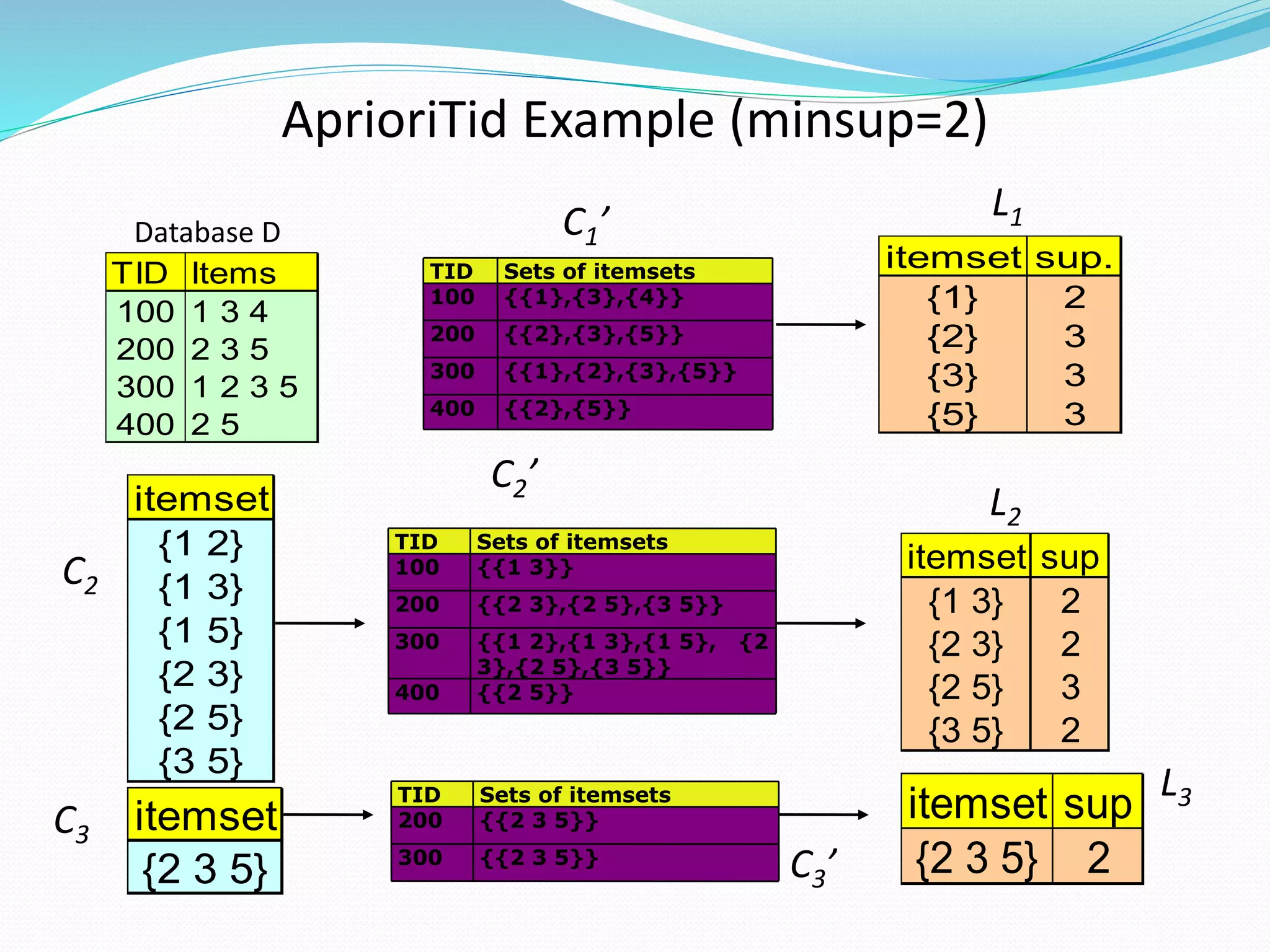
The document discusses the Apriori algorithm for finding frequent itemsets in transactional data. It begins by defining key concepts like itemsets, support count, and frequent itemsets. It then explains the core steps of the Apriori algorithm: generating candidate itemsets from frequent k-itemsets, scanning the database to determine frequent (k+1)-itemsets, and pruning infrequent supersets. The document also introduces optimizations like the AprioriTid algorithm, which makes a single pass over the data using data structures to count support.












![The AprioriTID algorithm
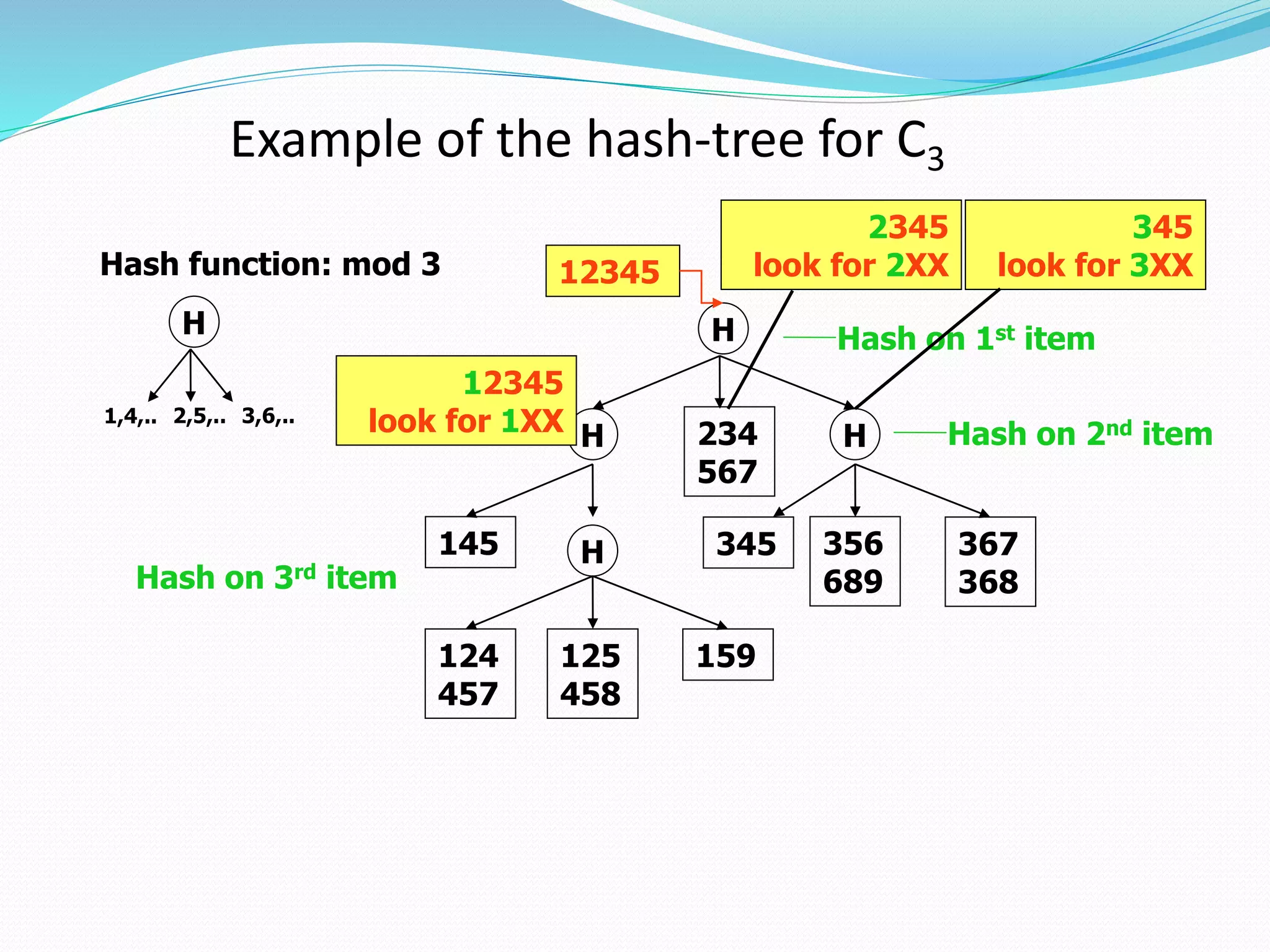
• L1 = {frequent 1-itemsets}
• C1’ = database D
• for (k=2, Lk-1’≠ empty; k++)
Ck = GenerateCandidates(Lk-1)
Ck’ = {}
for all entries t є Ck-1’
Ct= {cє Ck|t[c-c[k]]=1 and t[c-c[k-1]]=1}
for all cє Ct {c.count++}
if (Ct≠ {})
append Ct to Ck’
endif
endfor
Lk= {cє Ck|c.count >= minsup}
endfor
• return Uk Lk](https://image.slidesharecdn.com/apriorialgorithm-191029060819/75/Apriori-algorithm-19-2048.jpg)
![Discussion on the AprioriTID
algorithm
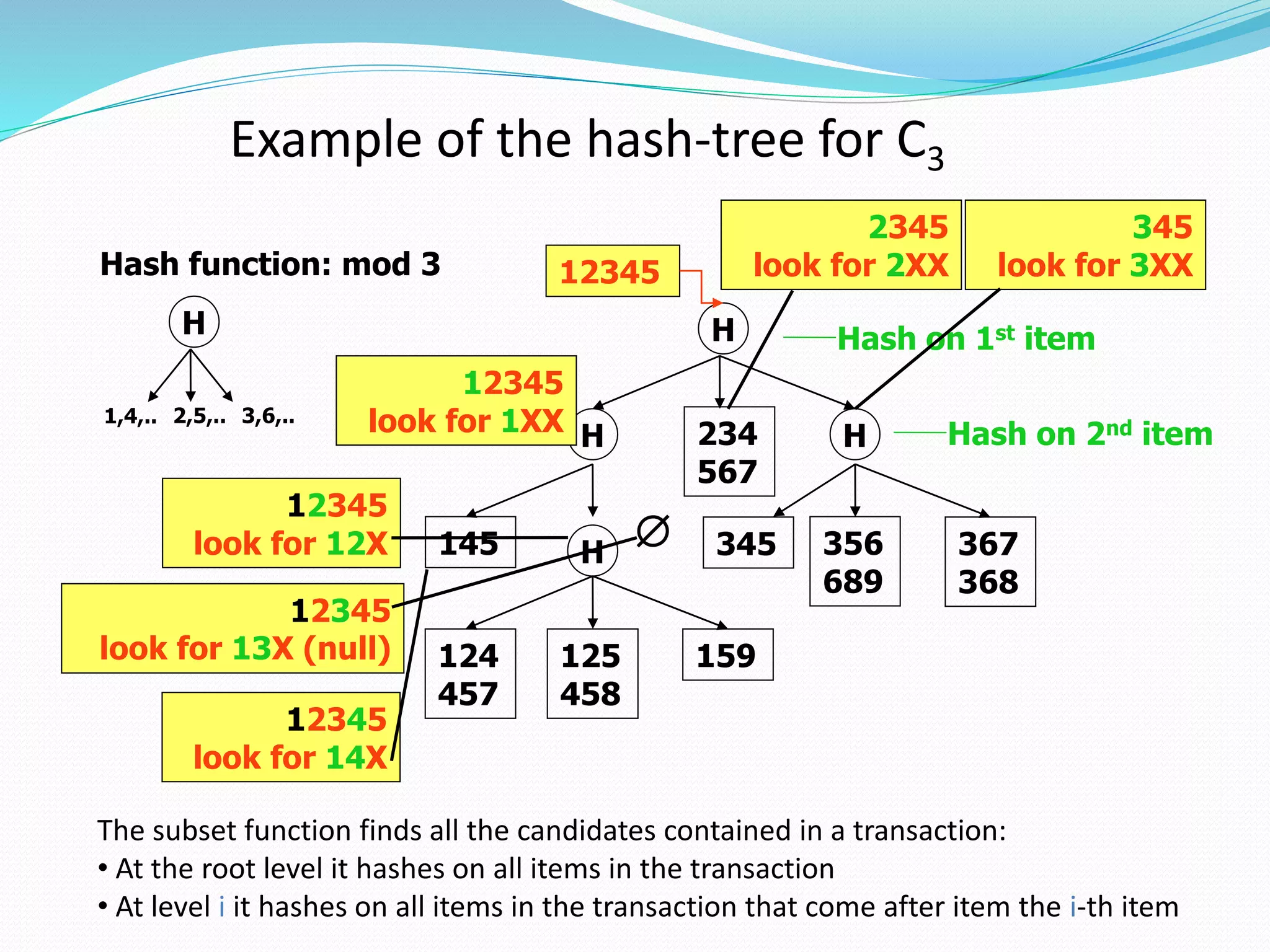
L1 = {frequent 1-itemsets}
C1’ = database D
for (k=2, Lk-1’≠ empty; k++)
Ck = GenerateCandidates(Lk-1)
Ck’ = {}
for all entries t є Ck-1’
Ct= {cє Ck|t[c-c[k]]=1 and t[c-c[k-
1]]=1}
for all cє Ct {c.count++}
if (Ct≠ {})
append Ct to Ck’
endif
endfor
Lk= {cє Ck|c.count >= minsup}
endfor
return Uk Lk
One single pass over the
data
Ck’ is generated from Ck-1’
For small values of k, Ck’
could be larger than the
database!
For large values of k, Ck’
can be very small](https://image.slidesharecdn.com/apriorialgorithm-191029060819/75/Apriori-algorithm-21-2048.jpg)













































































