GCM 이란?
기존의 방식
1.GCM(Google Cloud Messaging)이란, 구글 서버를 이용해서 안드로이드 기기에 푸시를 보내는 것.
5.
기존에 알아야 할사실
기존의 방식
1.GCM은 HTTP Request를 통해 메세지를 보낼 수 있음.
2.GCM은 한번에 1000개씩 보낼 수 있음.
3.저희 서버에 등록된 GCM Key는 약 70만개.
4.모든 사람이 공정하게 푸시를 받아야 함. (매번 푸시 발송 순서가 달라야함.)
6.
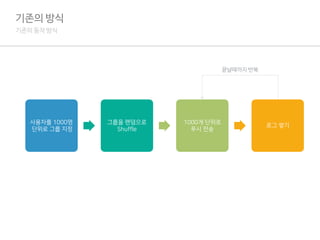
기존의 방식
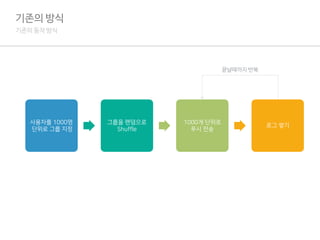
기존의 동작방식
사용자를 1000명
단위로 그룹 지정
그룹을 랜덤으로
Shuffle
1000개 단위로
푸시 전송
로그 쌓기
끝날때까지 반복
7.
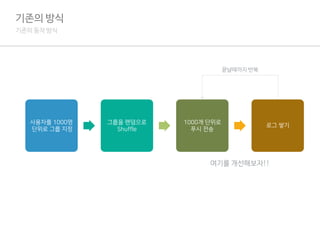
기존의 방식
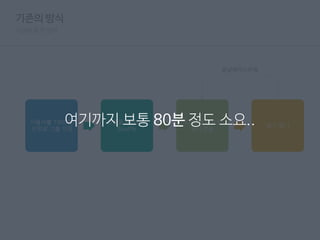
기존의 동작방식
사용자를 1000명
단위로 그룹 지정
그룹을 랜덤으로
Shuffle
1000개 단위로
푸시 전송
로그 쌓기
끝날때까지 반복
여기까지 보통 80분 정도 소요..
8.
기존의 방식
기존의 동작방식
사용자를 1000명
단위로 그룹 지정
그룹을 랜덤으로
Shuffle
1000개 단위로
푸시 전송
로그 쌓기
끝날때까지 반복
9.
기존의 방식
기존의 동작방식
사용자를 1000명
단위로 그룹 지정
그룹을 랜덤으로
Shuffle
1000개 단위로
푸시 전송
로그 쌓기
끝날때까지 반복
여기를 개선해보자!!
PHP에서 Async의 지원
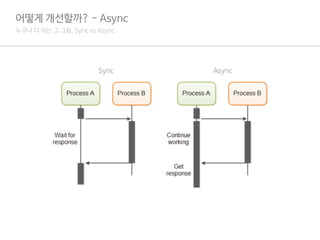
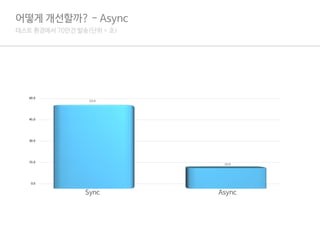
어떻게개선할까? - Async
1.PHP의 모든 로직은 전부 Sync가 기반.
2.PHP에서 Async를 사용하기 위해서는 Pthread 모듈이나 Ev, Uv 등을 사용해야 함.
3.하지만, 내장 Curl의 경우 Multi Curl을 지원해서 비동기로 처리가 가능.
4.즉, Curl에 한해서는 기본 PHP로 Async스럽게 사용할 수 있음.
5.이 Multi Curl을 Async(그리고 Promise)를 통해서 구현해놓은 라이브러리가 Guzzle Http.
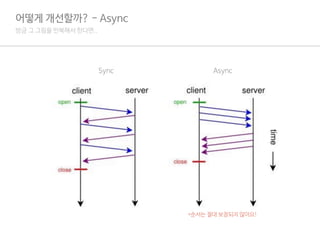
여기까지 했을 때의문제.
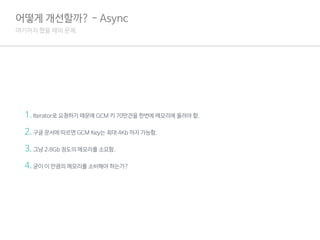
어떻게 개선할까? - Async
1.Iterator로 요청하기 때문에 GCM 키 70만건을 한번에 메모리에 올려야 함.
2.구글 문서에 따르면 GCM Key는 최대 4Kb 까지 가능함.
3.그냥 2.8Gb 정도의 메모리를 소요함.
4.굳이 이 만큼의 메모리를 소비해야 하는가?
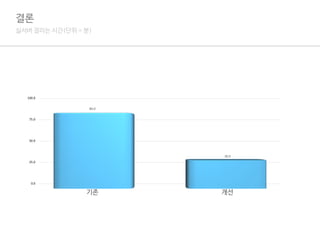
결론
1.Async는 속도를 향상시킬 수 있음. 따라서, Async로 할 수 있는 작업은 Async로 바꾸자.
2.Generator는 메모리를 효율적으로 사용할 수 있음. 따라서, Generator로 할 수 있다면 Generator를 사용해보자.
3.그렇지만 이게 정답은 아님.
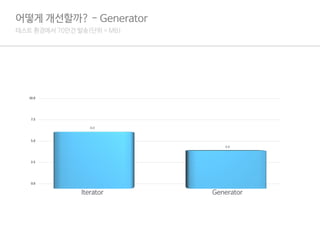
정리







![어떻게 개선할까? - Async
Request 생성 매서드 하나 만들고..
public function createRequest($tokens, $message, $url = '')
{
return new Request(
'POST',
new Uri('https://android.googleapis.com/gcm/send'),
'1.1',
[
'Authorization' => "key=xxxxxxxxxxxxxxx",
'Content-Type' => 'application/json',
],
new StringStream(json_encode([
'registration_ids' => $tokens,
'data' => [
'alert' => $message,
'url' => $url
],
]))
);
}
Request, Uri, StringStream은 PSR-7 객체입니다.](https://image.slidesharecdn.com/pug-160630-async-160810015533/85/PHP-GCM-feat-Async-Generator-16-320.jpg)
![어떻게 개선할까? - Async
나머진 그냥 예시 참고해서 만들면 됨.
http://docs.guzzlephp.org/en/latest/quickstart.html
$requests = [];
foreach ($this->getChunkedTokens() as $tokens) {
$message = $this->getMessate();
$url = $this->getUrl();
$requests[] = $this->createRequest($tokens, $message, $url);
}
$pool = new Pool($this->client, $requests, [
'concurrency' => 20, // 메모리에 맞춰서 알아서..
'fulfilled' => function ($response, $index) {
$this->output->writeln(date('[Y-m-d H:i:s] ') ."success in {$index} !!");
},
'rejected' => function ($reason, $index) {
$this->output->writeln(date('[Y-m-d H:i:s] ') ."fail in {$index} ..");
},
]);
$pool->promise()->wait();](https://image.slidesharecdn.com/pug-160630-async-160810015533/85/PHP-GCM-feat-Async-Generator-17-320.jpg)


![어떻게 개선할까? - Generator
기존의 소스
$requests = [];
foreach ($this->getChunkedTokens() as $tokens) {
$message = $this->getMessage();
$url = $this->getUrl();
$requests[] = $this->createRequest($tokens, $message, $url);
}
$pool = new Pool($this->client, $requests, [
'concurrency' => 30, // 메모리에 맞춰서 알아서..
'fulfilled' => function ($response, $index) {
$this->output->writeln(date('[Y-m-d H:i:s] ') ."success in {$index} !!");
},
'rejected' => function ($reason, $index) {
$this->output->writeln(date('[Y-m-d H:i:s] ') ."fail in {$index} ..");
},
]);
$pool->promise()->wait();](https://image.slidesharecdn.com/pug-160630-async-160810015533/85/PHP-GCM-feat-Async-Generator-22-320.jpg)
![어떻게 개선할까? - Generator
Generator 다듬어진 소스
$requests = function () {
foreach ($this->getChunkedTokens() as $tokens) {
$message = $this->getMessage();
$url = $this->getUrl();
yield $this->createRequest($tokens, $message, $url);
}
};
$pool = new Pool($this->client, $requests(), [
'concurrency' => 30, // 메모리에 맞춰서 알아서..
'fulfilled' => function ($response, $index) {
$this->output->writeln(date('[Y-m-d H:i:s] ') ."success in {$index} !!");
},
'rejected' => function ($reason, $index) {
$this->output->writeln(date('[Y-m-d H:i:s] ') ."fail in {$index} ..");
},
]);
$pool->promise()->wait();](https://image.slidesharecdn.com/pug-160630-async-160810015533/85/PHP-GCM-feat-Async-Generator-23-320.jpg)






![[CB19] アンチウイルスをオラクルとしたWindows Defenderに対する新しい攻撃手法 by 市川遼](https://cdn.slidesharecdn.com/ss_thumbnails/codeblue2019-ja-191211062732-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC07] 게임 개발에서의 클라이언트 보안 - 송창규](https://cdn.slidesharecdn.com/ss_thumbnails/revival-130427235801-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[우리가 데이터를 쓰는 법] 모바일 게임 로그 데이터 분석 이야기 - 엔터메이트 공신배 팀장](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=640&height=640&fit=bounds)






![[보안 PARTNER DAY] 모바일게임 리소스 보안](https://cdn.slidesharecdn.com/ss_thumbnails/naverd2hexa-171229071326-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[NEXT] GCM을 이용한 게시글 자동 갱신](https://cdn.slidesharecdn.com/ss_thumbnails/day10gcm-141209112851-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)








