Downloaded 15 times








![Challenges –(very) brief overview
•
What questions to ask? [SIGMOD13, VLDB13,ICDT14, SIGMOD14]
•
How to define & determine correctness of answers? [ICDE11, WWW12]
•
Who to ask? how many people? How to best use the resources? [ICDE12, VLDB13, ICDT13, ICDE13] Crowd Mining
Data Mining
Data Cleaning
Probabilistic Data
Optimizations and Incremental Computation
EU-FP7 ERC
MoDaSMob Data Sourcing
8](https://image.slidesharecdn.com/oxford14-141113130617-conversion-gate01/85/Tova-Milo-on-Crowd-Mining-8-320.jpg)





![Contributions (at a very high level)
•
Formal model for crowd mining; allowed questions and the answers interpretation; personal rules and their overall significance.
•
A Frameworkof the generic components required for mining the crowd
•
Significance and error estimations. [and, how will this change if we ask more questions…]
•
Crowd-mining algorithms
•
[Implementation & benchmark. both synthetic & real data.]
Crowd Mining 15](https://image.slidesharecdn.com/oxford14-141113130617-conversion-gate01/85/Tova-Milo-on-Crowd-Mining-15-320.jpg)





![Completing the picture (second attempt…)
How to measure the efficiency of Crowd Mining Algorithms ???
•
Two distinguished cost factors:
–
Crowd complexity:# of crowd queries used by the algorithm
–
Computational complexity:the complexity of computing the crowd queries and processing the answers
[Crowd comp. lower bound is a trivial computational comp. lower bound]
•
There exists a tradeoffbetween the complexity measures
–
Naïve questions selection -> more crowd questions
Crowd Mining 24](https://image.slidesharecdn.com/oxford14-141113130617-conversion-gate01/85/Tova-Milo-on-Crowd-Mining-24-320.jpg)




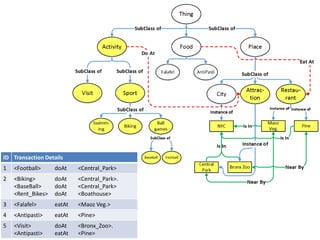
![Crowd Mining Query language (based on SPARQL and DMQL)
•
SPARQL-like where clause is evaluated against the ontology.
–
$ indicates a variable.
–
* used to indicate pathof length 0 or more
•
Satisfyingclause are fact sets to be mined from the crowd
–
MOREindicates that other frequently co-occuringfacts can also be returned
–
SUPPORT indicatesthreshold
Crowd Mining
SELECT FACT-SETS
WHERE
{$wsubclassOf*Attraction.
$xinstanceOf$w.
$xinsideNYC.
$xhasLabel“child friendly”.
$ysubclassOf*Activity.
$zinstanceOfRestaurant.
$znearBy$x.}
SATISFYING
{$y+ doAt$x.
[] eatAt$z.
MORE}
WITH SUPPORT = 0.4
“Find popular combinations of an activity in a child-friendly attraction in NYC, and a good restaurant near by (and any other relevant advice).”
30](https://image.slidesharecdn.com/oxford14-141113130617-conversion-gate01/85/Tova-Milo-on-Crowd-Mining-30-320.jpg)
![(Open and Closed) Questions to the crowd
Crowd Mining
How often do you eat at MaozVegeterian?
{ ( [] eatAt<Maoz_Vegeterian> ) }
How often do you swimin Central Park?
{ ( <Swim> doAt<Central_Park> ) }
Supp=0.1
Supp=0.3
What do you doin Central Park ?
{ ( $y doAt<Central_Park>) }
$y = Football, supp = 0.6
What else do you do when bikingin Central Park?
{ (<Biking> doAt<Central_Park>) ,
($y doAt<Central_Park>) }
$y = Football, supp = 0.6
31](https://image.slidesharecdn.com/oxford14-141113130617-conversion-gate01/85/Tova-Milo-on-Crowd-Mining-31-320.jpg)
![Example of extracted association rules
•
< Ball Games, doAt, Central_Park> (Supp:0.4 Conf:1)
< [ ] , eatAt, Maoz_Vegeterian> (Supp:0.2 Conf:0.2)
•
< visit, doAt, Bronx_Zoo> (Supp: 0.2 Conf: 1)
< [ ] , eatAt, Pine_Restaurant> (Supp: 0.2 Conf: 0.2)
Crowd Mining 32](https://image.slidesharecdn.com/oxford14-141113130617-conversion-gate01/85/Tova-Milo-on-Crowd-Mining-32-320.jpg)






This document discusses crowd mining, which involves using crowdsourcing techniques to extract knowledge from large amounts of data. It describes how crowd mining can be used to identify significant patterns and rules in data by asking targeted questions to crowds. The document outlines challenges in crowd mining, such as determining what questions to ask and how to measure answer quality. It also presents a framework and query language for crowd mining and examples of rules extracted from crowd data.















































