2.4 动态语义 21
的动态语义(dynamic semantics)。动态语义允许对象对其生命期的两个不同时候发来的相同
消息作出不同的回应。例如,看这个抽象例子:
Method junk for the class X
if (local state #1) then
F do something
else if (local state #2) then
do something different
End Method
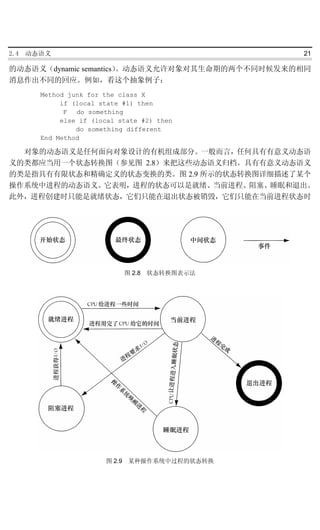
对象的动态语义是任何面向对象设计的有机组成部分。一般而言,任何具有有意义动态语
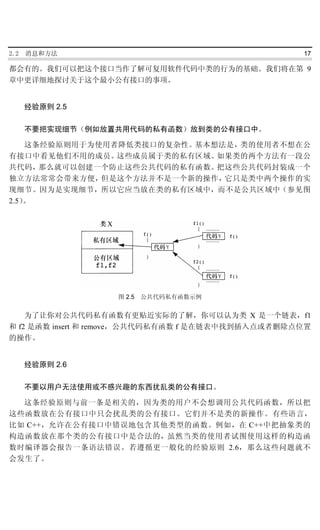
义的类都应当用一个状态转换图(参见图 2.8)来把这些动态语义归档。具有有意义动态语义
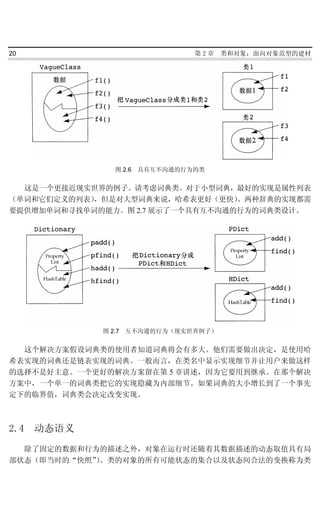
的类是指具有有限状态和精确定义的状态变换的类。图 2.9 所示的状态转换图详细描述了某个
操作系统中进程的动态语义。它表明,进程的状态可以是就绪、当前进程、阻塞、睡眠和退出。
此外,进程创建时只能是就绪状态,它们只能在退出状态被销毁,它们只能在当前进程状态时
图 2.8 状态转换图表示法
图 2.9 某种操作系统中过程的状态转换






![16 第2章 类和对象:面向对象范型的建材
的人显然依赖于闹钟的公有界面。但是,闹钟不应当依赖于那个人。如果闹钟依赖于使用者,
比如说那个在卧室中用闹钟的人,那么闹钟就无法被用来制造定时锁保险箱,除非把那个人
也绑定在保险箱上。这样的依赖性是不受欢迎的,因为我们想要把闹钟用于其他的领域,而
不想为此依赖于使用者。所以,最好把闹钟看作一个小型机器,这个小型机器对它的使用者
一无所知,它仅仅是执行定义于公有界面的行为,而不管发送消息的是谁。
图 2.4 使用闹钟
经验原则 2.3
尽量减少类的协议中的消息。
就在几年前,还有人撰文提倡刚好与这条经验原则相反的实践。当时是这样说的:关于
这个类的操作,凡是类的实现者能想象到的,将来就会有用户用到。那么,既然如此,为什
么不实现这些操作呢?如果你采纳这样的经验原则,那么你肯定会钟爱我的链表类——它的
公有接口有 4 000 个操作。问题时,当你想对两个链表对象执行合并操作时,你认为链表类
一定提供了这个操作,所以你依照字母顺序检查消息列表,但是却找不到哪个操作是以
merge、union、combine 或者你知道的其他同义词命名的。不幸的是,真正的操作是一个重载
的加号(在 C++中是 operator+) 。庞大的公有接口的问题是,你永远都无法找到你想要找的
东西。这严重损害了接口的可复用性。而如果让接口最小化,我们就可以让系统易于理解,
并使组件易于复用。
经验原则 2.4
实现所有类都理解的最基本公有接口[例如,拷贝操作(深拷贝与浅拷贝)、相等性判
断、正确输出内容、从 ASCII 描述解析等等]。
如果一个开发者设计和实现的类要被另一个开发者在其他应用程序中复用,那么提供一
1
个常用的最小公有接口常常很有用。这个最小公有接口包含的功能是人们合理地预期每个类
1
译注:特别是Framework设计尤其如此。很多Framework设计时都在根类中提供了这一最小公有接口(单根继承结构)。](https://image.slidesharecdn.com/ood02-091211113911-phpapp02/85/Ood-02-6-320.jpg)





![经验原则小结 25
Method
方法。消息的实现。
Object
对象。属于它的类的一个样例,包含它自己的标识、类的行为、类的接口、类的数据的
一份拷贝。也称为类的实例。
Overloaded function
重载函数。系统中的两个函数可以有相同的名字的能力,只要它们的参数类型不同(类
内重载)或者所属的类不同(类间重载)。
Protocol
协议。类能响应的消息列表。
Self object
Self 对象。控制位于方法内部时,接受消息的对象的引用。
经验原则小结
经验原则 2.1 所有数据都应当隐藏在它所在的类内部。
经验原则 2.2 类的使用者必须依赖类的公有接口,但类不能依赖它的使用者。
经验原则 2.3 尽量减少类的协议中的消息。
经验原则 2.4 实现所有类都理解的最基本公有接口[例如,拷贝操作(深拷贝与浅拷
贝)、相等性判断、正确输出内容、从 ASCII 描述解析等等]
。
经验原则 2.5 不要把实现细节(例如放置共用代码的私有函数)放到类的公有接口中。
经验原则 2.6 不要以用户无法使用或不感兴趣的东西扰乱类的公有接口。
经验原则 2.7 类之间应该零耦合,或者只有导出耦合关系。也即,一个类要么同另一
个类毫无关系,要么只使用另一个类的公有接口中的操作。
经验原则 2.8 类应当只表示一个关键抽象。
经验原则 2.9 把相关的数据和行为集中放置。
经验原则 2.10 把不相关的信息放在另一个类中(也即:互不沟通的行为)。
经验原则 2.11 确保你为之建模的抽象概念是类,而不只是对象扮演的角色。](https://image.slidesharecdn.com/ood02-091211113911-phpapp02/85/Ood-02-15-320.jpg)




































![设计模式:可复用面向对象软件的基础 ([美] Eric_ (Z-Library).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ericz-library-240904160510-5f95a247-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Lucene 3[1] 0 原理与代码分析](https://cdn.slidesharecdn.com/ss_thumbnails/lucene31-0-100225194736-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



