NSDI’16 Reading
Network Architecturesand Protocols
Hiroya Kaneko
2016/05/29
Some figures are cited from original papers or slides
http://system-reading.connpass.com/event/31207/
2.
Contents
An Industrial-Scale SoftwareDefined Internet Exchange Point
Jihyung Arpit Gupta (Princeton University), et al.
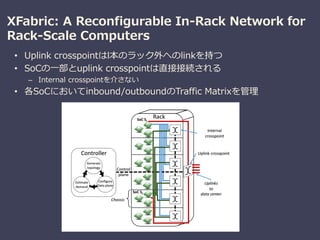
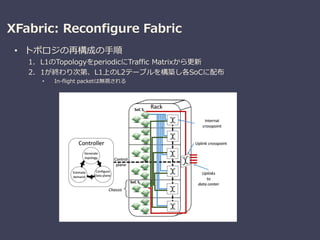
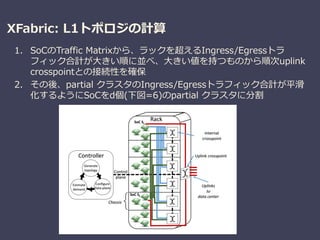
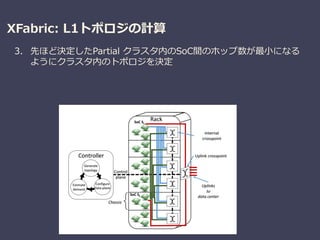
XFabric: A Reconfigurable In-Rack Network for Rack-Scale Computers
Sergey Legtchenko (Microsoft Research), et al.
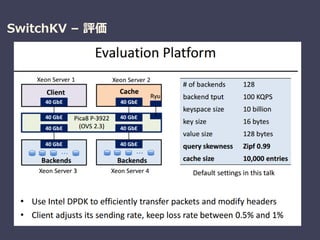
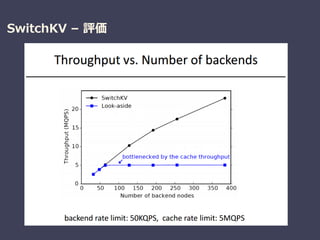
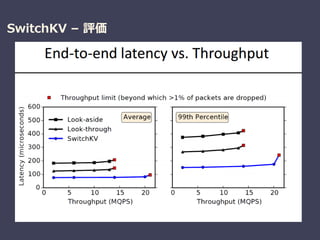
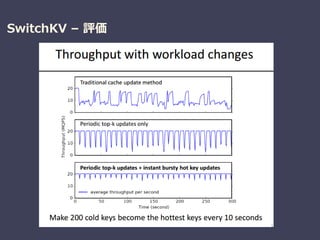
Be Fast, Cheap and in Control with SwitchKV
Xiaozhou Li (Intel Labs) , et al.
Bitcoin-NG: A Scalable Blockchain Protocol
Ittay Eyal (Cornell University), et al.
Exploring Cross-Application Cellular Traffic Optimization with Baidu TrafficGuard
Zhenhua Li (Tsinghua University and Baidu Mobile Security), et al.
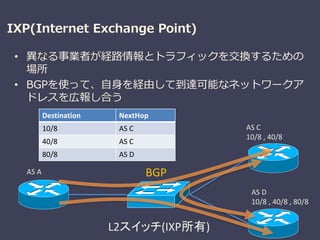
IXP(Internet Exchange Point)
•異なる事業者が経路情報とトラフィックを交換するための
場所
• BGPを使って、自身を経由して到達可能なネットワークア
ドレスを広報し合う
L2スイッチ(IXP所有)
AS C
10/8 , 40/8
AS D
10/8 , 40/8 , 80/8
AS A
Destination NextHop
10/8 AS C
40/8 AS C
80/8 AS D
BGP
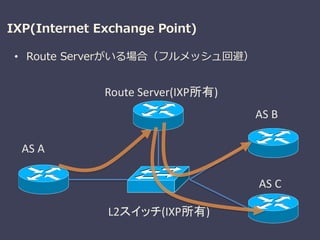
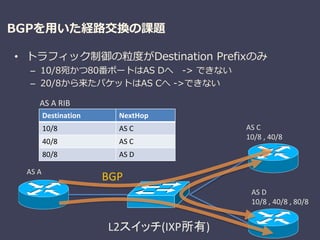
BGPを用いた経路交換の課題
• トラフィック制御の粒度がDestination Prefixのみ
–10/8宛かつ80番ポートはAS Dへ -> できない
– 20/8から来たパケットはAS Cへ ->できない
L2スイッチ(IXP所有)
AS C
10/8 , 40/8
AS D
10/8 , 40/8 , 80/8
AS A
Destination NextHop
10/8 AS C
40/8 AS C
80/8 AS D
BGP
AS A RIB
12.
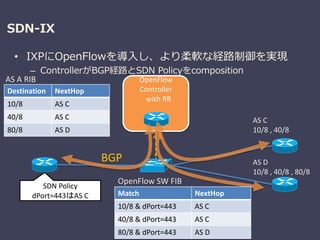
SDN-IX
• IXPにOpenFlowを導入し、より柔軟な経路制御を実現
– ControllerがBGP経路とSDNPolicyをcomposition
OpenFlow SW FIB
AS C
10/8 , 40/8
AS D
10/8 , 40/8 , 80/8
Destination NextHop
10/8 AS C
40/8 AS C
80/8 AS D
OpenFlow
Controller
with RR
BGP
SDN Policy
dPort=443はAS C Match NextHop
10/8 & dPort=443 AS C
40/8 & dPort=443 AS C
80/8 & dPort=443 AS D
AS A RIB
13.
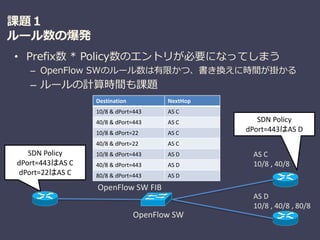
課題1
ルール数の爆発
• Prefix数 *Policy数のエントリが必要になってしまう
– OpenFlow SWのルール数は有限かつ、書き換えに時間が掛かる
– ルールの計算時間も課題
OpenFlow SW
AS C
10/8 , 40/8
AS D
10/8 , 40/8 , 80/8
Destination NextHop
10/8 & dPort=443 AS C
40/8 & dPort=443 AS C
10/8 & dPort=22 AS C
40/8 & dPort=22 AS C
10/8 & dPort=443 AS D
40/8 & dPort=443 AS D
80/8 & dPort=443 AS D
SDN Policy
dPort=443はAS C
dPort=22はAS C
SDN Policy
dPort=443はAS D
OpenFlow SW FIB
14.
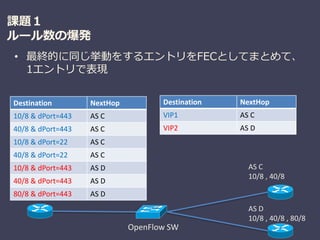
課題1
ルール数の爆発
• 最終的に同じ挙動をするエントリをFECとしてまとめて、
1エントリで表現
OpenFlow SW
ASC
10/8 , 40/8
AS D
10/8 , 40/8 , 80/8
Destination NextHop
10/8 & dPort=443 AS C
40/8 & dPort=443 AS C
10/8 & dPort=22 AS C
40/8 & dPort=22 AS C
10/8 & dPort=443 AS D
40/8 & dPort=443 AS D
80/8 & dPort=443 AS D
Destination NextHop
VIP1 AS C
VIP2 AS D
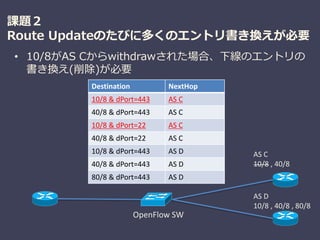
課題2
Route Updateのたびに多くのエントリ書き換えが必要
• 10/8がASCからwithdrawされた場合、下線のエントリの
書き換え(削除)が必要
OpenFlow SW
AS C
10/8 , 40/8
AS D
10/8 , 40/8 , 80/8
Destination NextHop
10/8 & dPort=443 AS C
40/8 & dPort=443 AS C
10/8 & dPort=22 AS C
40/8 & dPort=22 AS C
10/8 & dPort=443 AS D
40/8 & dPort=443 AS D
80/8 & dPort=443 AS D
Packetへのnexthopとreachability情報の埋め込み(2)
• 具体的なdstIPの値ではなく、Reachability bitを用いて
Ruleを記述する
OpenFlowSW
AS C
10/8 , 40/8
AS D
10/8 , 40/8 , 80/8
Rule NextHop
1X & dPort=443 AS C
1X & dPort=443 AS C
1X & dPort=22 AS C
1X & dPort=22 AS C
X1 & dPort=443 AS D
X1 & dPort=443 AS D
X1 & dPort=443 AS D
0(AS C)11
dMAC
Destination NextHop
10/8 & dPort=443 AS C
40/8 & dPort=443 AS C
10/8 & dPort=22 AS C
40/8 & dPort=22 AS C
10/8 & dPort=443 AS D
40/8 & dPort=443 AS D
80/8 & dPort=443 AS D
19.
Packetへのnexthopとreachability情報の埋め込み(3)
• 経路に変更があった場合、送出パケットのdMACを変更す
るのみ(スイッチ上のルールの変更は不要)
• 例:ASCが10/8をwithdrawした場合
– AS AのSDN ControllerがAS CのnexthopのdMACを変更(GARP)
OpenFlow SW
AS C
10/8 , 40/8
AS D
10/8 , 40/8 , 80/8
Rule NextHop
1X & dPort=443 AS C
1X & dPort=443 AS C
1X & dPort=22 AS C
1X & dPort=22 AS C
X1 & dPort=443 AS D
X1 & dPort=443 AS D
X1 & dPort=443 AS D
1(AS D)01
dMAC
Destination NextHop dMAC
(R2,N1の場合)
10/8 AS C 110 -> 011
40/8 AS C 110
80/8 AS D 011
AS A RIB

















































![[D20] 高速Software Switch/Router 開発から得られた高性能ソフトウェアルータ・スイッチ活用の知見 (July Tech Fest...](https://cdn.slidesharecdn.com/ss_thumbnails/jtf20182-180803022253-thumbnail.jpg?width=640&height=640&fit=bounds)







