A Beginner's guide to understanding Autoencoder
•Download as PPTX, PDF•
11 likes•6,133 views

Autoencoder 입문자를 위한 자료

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Similar to A Beginner's guide to understanding Autoencoder
Similar to A Beginner's guide to understanding Autoencoder (20)
A Beginner's guide to understanding Autoencoder
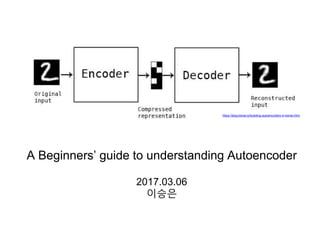
- 1. A Beginners’ guide to understanding Autoencoder 2017.03.06 이승은 https://blog.keras.io/building-autoencoders-in-keras.html
- 2. 2 Autoencoder를 한 문장으로 표현하면? Input’ = Decoder(Encoder(Input)) 즉, input을 압축한 후 재현하는 거. 그래서 label이 필요 없으니, Neural Nets에서 Unsupervised Learning으로 유명함
- 3. 3 코드로 만들고 코드를 해독하고1 Input(X)의 dimension이 줄어듦2 3 X -> X’ (dimension 동일) 그림으로 특징을 살펴볼까요? 가장 간단한 1 hidden layer로 살펴봅시다 (code: hidden layer) bottleneck code https://en.wikipedia.org/wiki/Autoencoder
- 4. 4 그림을 수식으로 확인하면 (encoder) (decoder) (X와 X’의 거리를 최소화하는 encoder, decoder 선택) (code) activation function (ReLU같이 non-linearity를 주는 함수) (output) x와 x’의 거리인 loss function을 최소화도록 training함 z의 dimension인 p는 x의 dimension인 d보다 작기 때문에 encoder는 x를 압축하여 표현한다고 생각할 수 있음 그리고 p < d 와 같은 regularization이 없으면 identity function(f(x)=x)를 학습하기 때문에 꼭 필요한 regularization임 deterministic한 mapping으로 code와 output을 표현할 수 있음 https://en.wikipedia.org/wiki/Autoencoder
- 5. 5 근데 autoencoder를 쓰면 뭐가 좋을까요...? 부제: code(z)은 어떤 의미를 가질까요?
- 6. 6 Autoencoder를 처음 제안한 논문(Baldi, P. and Hornik, K. 1989)에서는 “backpropagation으로 PCA를 구현”하는데 의의를 둠 Baldi, P. and Hornik, K. (1989) Neural networks and principal components analysis: Learning from examples without local minima. Neural Networks 그렇다면...PCA(Principal Component Analysis)는 무엇인지...?
- 7. 7 PCA(Principal Component Analysis), 주성분 분석이란 (혹시 orthogonal이나 projection 같은 단어를 혹시 모르시면 선형대수 기초라도 꼭 공부해보시길!) • N correlated variables을 M uncorrelated variables로 orthogonal transformation함. 그래 서 dimension이 N->M (M은 N보다 작거나 같음) 으로 줄어듬! 이때 M개의 uncorrelated variables을 principal components라 함 (단, 데이터가 high-dimensional space에서 linear-manifold하 게 있다는 가정이 필요함) • 즉, 데이터가 가장 많이 분산된 M orthogonal direction을 찾아서 N-dimensional 데이터 를 projection함. 그러면 그 과정에서 M orthogonal direction에 있던 데이터는 손실되겠 지만 데이터가 가장 많이 분산된 direction이므로 variation이 크지 않아 손실이 최소화 됨 • M orthogonal direction으로 표현될 수 없는 값들은 전체 데이터의 평균값으로 reconstruction(재구성)함 • (그림 2)처럼 빨간점이 초록색점으로 표현되기 때문에 이 거리만큼이 에러가 됨 (그림 1) PCA: 3차원 -> 2차원 (그림 2) PCA: 2차원 -> 1차원 http://www.nlpca.org/pca_principal_component_analysis.html https://en.wikipedia.org/wiki/Principal_component_analysis
- 8. 8 PCA보다 비효율적임 (아주 많은 양의 데이터로 학습을 하다보면 더 효율적이 될 수도 있음..) • 또한, code 사이로 non-linear layer를 추가하면 curved(non-linear) manifold 위나 근처에 있는 데이터를 효율적으로 표현하는 PCA의 generalize한 버전이 가능함 • Encoder는 input space의 좌료를 manifold의 좌표로 변환함 • Decoder는 반대로 manifold의 좌표를 output space의 좌표로 변환함 • 그러나 초기 weight이 good solution에 가까워야 local minima에 안빠짐 • input x와 output x’가 같도록 reconstruct하는 network를 만들고 reconstruction error를 최 소화하도록 gradient descent learning을 적 용함 • Code z은 M hidden unit으로 input N에 대한 compressed representation이 됨 • PCA와 autoencoder의 reconstruction error 는 동일하지만 hidden unit과 principal component는 꼭 일치 않을 수 있음 (PCA axes과 다르거나 skewed될 수 있기 때문!) PCA 구현을 위한 Autoencoder Lecture 15.1 — From PCA to autoencoders [Neural Networks for Machine Learning] by Geoffrey Hinton
- 9. 9 근데 그래서... autoencoder를 쓰면 뭐가 좋을까요...? Non-linear Dimension Reduction이 가능하나 입증이 애매하고 linear한 경우 PCA 성능이 더 좋았음 아직 잘 모르겠네요…?!?! (autoencoder에 대한 첫 반응은 그저 그랬..) 그래서 사람들도 당시 PCA를 더 많이 썼음! (시각화, 분류 시 매우 유용함)
- 10. 10 Baldi, P. and Hornik, K. Neural networks and principal components analysis: Learning from examples without local minima. Neural Networks Hinton & Salakhutdinov, Reduction the Dimensionality of Data with Neural Network, Science Pretraining을 Deep Autoencoder에 적용해보자! Reduction the Dimensionality of Data with Neural Network, Hinton & Salakhutdinov, Science, 2006 2006 1989
- 11. 11 Reduction the Dimensionality of Data with Neural Network, Hinton & Salakhutdinov, Science, 2006 [Lecture 15.2] Deep autoencoders by Geoffrey Hinton Hinton과 Salakhutdinov가 만든, 첫번째 성공적인 Deep Autoencoder • Deep Autoencoder는 non-linear dimension reduction 외에도 여러 장점이 있음 • flexible mapping 가능 • learning time은 training case 수에 비례하거나 더 적게 걸림 • 최종 encoding 모델이 꽤 빠름 • 그러나! backpropagation으로 weight을 최적화하기 어려워서 2006년 전에는 안 쓰 였음 • 초기 weight 값이 크면 local minima로 수렴 • 초기 weight 값이 작으면 backpropagation시 vanishing gradient 문제 발생 • 새로운 방법을 autoencoder에 적용하여 첫번째로 성공적인 deep autoencoder를 완성함 • layer-by-layer로 pre-training을 적용 • Echo-State Nets처럼 weight을 초기화(initialization)함 • Reconstruction의 용도(원랜 dimension reduction만..)가 주목받기 시작함
- 12. 12 Deep autoencoder의 구조를 이해하기 위해 알아야 할 것들이 있어요... 아래 내용을 살펴보고 다시 돌아가봐요! RBM과 DBF, 그리고 greedy layer-wise training
- 13. 13 • Boltzmann machine의 변형*으로 Input에 대한 확 률 분포를 learning할 수 있는 generative stochastic artificial neural network로 visible unit과 hidden unit으로 구성됨. 단, 각 unit은 binary unit 임. • Boltzmann machine과 다르게 1 layer of hidden unit으로 구성되고 hidden units 사이의 connection이 없음. 즉, visible unit의 상태가 주어질 때 hidden unit activation은 Mutually Independent함. • Bipartite graph이므로 역도 성립(hidden unit이 주어질 때, visible unit activation도 MI함) • 따라서, visible units이 주어지면 1 step만으로 thermal equilibrium(열평형)에 도달함 • 결과적으로 Boltzmann machine보다 학습 시 간이나 inference 시간을 크게 줄임 • dimensionality reduction, classification, collaborative filtering, feature learning, topic modeling 등 목적에 맞게 supervised, unsupervised에 다 쓰일 수 있음 RBM, Restricted Boltzmann machine *Boltzmann machine: hidden unit을 추가한 EBM(Energy Based Model)의 일종으로 Markov Network이기도 함. Energy로 확률을 구하고 Log-likelihood gradient를 계산한 후, MCMC sampling을 통해 stochastic하게 gradient을 추정하여 계산이 오래 걸리는 단점이 있음. 자세한 내용은 자료1(한글), 자료2(한글)를 찬찬히 보기를 추천함 Supervised 문제에도 RBM 적용 가능 unsupervised라면 y는 x’으로 치환
- 14. 14 RBM의 training http://www.cs.toronto.edu/~rsalakhu/deeplearning/yoshua_icml2009.pdf http://dsba.korea.ac.kr/wp/wp-content/seminar/Deep%20learning/RBM-2%20by%20H.S.Kim.pdf • 학습을 위해서 Negative Log-Likelihood(NLL)을 최소화해야함. 여기에 stochastic gradient descent를 적용하면 positive phase와 negative phase로 나눠짐 • Positive phase는 input vector와 조건부 확률(p(h|v))로 계산할 수 있지만, negative phase는 p(v,h)와 E( 정해진 모델 가능하지만 negative phase는 계산이 p(v,h)와 E(v,h) 를 계산하기 어렵기 때문에 Gibbs sampler를 이용한 MCMC 추정으로 approximation을 추정함 • Autoencoder와 다르게 BP(Backpropagation) 대신 무한번의 gibbs sampling으로 RBM 모델이 에너지 평형 상태에 이른다는 정보 이론의 CD-k를 통해 MLE 문제를 해 결함 (hinton 02) 계산이 어려움
- 15. 15 DBN, Deep Belief Network • RBM을 stacked하게 쌓아서 만든 probabilistic generative 모델 • Top 2 hidden layer는 undirected associative memory하고, 나머지 hidden layer는 directed graph함 • 그래서 stacked RBM이라고 부르기도 함 • 가장 큰 장점은 layer-by-layer learning으로 higher level feature를 전 layer에서 learning해 전달하는 것임. 이를 greedy layer-wise training 라고 함 • 각 layer에서는 unsupervised RBM learning을 한번씩 수행함(Gibbs sampling + KL divergence 최소화). 그리고 계산된 weight의 transpose 값을 inference weight으로 활용함 • 하위 layer의 결과를 다음 상위 layer의 input 데이터로 활용하므로, 각 layer의 최적 해는 상위 layer까지 다 고려했을 때의 최적해는 아닐 수 있으나 훨씬 효율적임 • Layer-wise한 pretraining의 weight 으로 initialize를 하고 전체 network는 다시 backpropagation으로 fine-tuning을 수행함. Fine-tuning은 supervised한 방법으로 수행 됨 A fast learning algorithm for deep belief nets, Hinton et al. Neural Computation 2006 http://www.cs.toronto.edu/~rsalakhu/deeplearning/yoshua_icml2009.pdf 모든 visible unit과 hidden unit의 dimension은 동일
- 16. 16 Reduction the Dimensionality of Data with Neural Network, Hinton & Salakhutdinov, Science, 2006 DBN 구조와 greedy layer-wise pre-training이 적용된 Deep Autoencoder • Pretraining: RBM 기반의 4개의 encoder, decoder stack으로 learning을 수행 (그래 서 Stacked AE라고도 함) • 각 stack은 one layer of feature detectors의 성격을 가짐. 위로 갈수록 추상화된 feature를 detect함 • 전체 loss를 최소화하는 게 아니라 layer별로 loss를 최소화함 (Loss function 계산식은 여기로..) • Unrolling(펼침): Encoder weight 값의 transpose 한 weight을 Decoder로 씀 • Encoder: weight initialization을 random 대신 pretraining 결과 활용 • Decoder: Encoder weight의 transpose matrix를 weight으로 씀 • Fine-tuning: 상기 과정에서 정해진 weight 값들에 대한 backprop으로 수행으 로 전체에 대한 최적화를 수행함 다시 Deep Autoencoder로 돌아오면...
- 17. 17 단, code vector의 dimension은 앞장 그림에서 보듯이 30임 8을 보면 실제 데이터(8이 약간 끊김)보다 나은 걸 알 수 있음. PCA는 30개의 linear unit으론 표현을 잘 못하는 게 보임 Reconstruction 결과 비교: 원본 vs. Deep Autoencoder vs. PCA 실제 데이터 Deep Autoencoder PCA 이 걸 계기로, dimension을 줄이는 ‘PCA 따라하기’에서 벗어나 reconstruction 단계가 주목받기 시작함!
- 18. 18 사실 기존의 autoencoder는 input을 represent하는 discriminative한 모델인 반면, RBM은 statistical distribution을 learning하는 확률론적인 모델로, generative 모델의 성격을 가짐. 그리고 이를 짬뽕한 deep autoencoder는 generative 모델의 성격을 어느정도 가지게 됨 그러나 p(h=0,1) = s(Wx+b)을 학습하는 게 아니라, h=s(Wx+b)를 학습하여 deterministic한 면도 여전히 가지고 있 다고 봐야함 Generative 와 Discriminative 가 짬뽕된 Deep Autoencoder http://sanghyukchun.github.io/61/ 일반적인 autoencoder RBM Deep Autoencoder (Stacked Autoencoder) 두 성격을 다 가지고 있음 요약하자면..
- 19. 19 Denoising autoencoder (2008) Extracting and Composing Robust Features with Denoising Autoencoders (P. Vincent, H. Larochelle Y. Bengio and P.A. Manzagol, ICML’08, pages 1096 - 1103, ACM, 2008) Sparse autoencoder (2008) Fast Inference in Sparse Coding Algorithms with Applications to Object Recognition (K. Kavukcuoglu, M. Ranzato, and Y. LeCun, CBLL-TR-2008-12-01, NYU, 2008) Sparse deep belief net model for visual area V2 (H. Lee, C. Ekanadham, and A.Y. Ng., NIPS 20, 2008) Stacked Denoising autoencoder (2010) Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion (P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio and P.A. Manzagol, J. Mach. Learn. Res. 11 3371-3408, 2010) Variational autoencoder (2013, 2014) Auto-encoding variational Bayes (D. P. Kingma and M. Welling. arXiv preprint arXiv:1312.6114, 2013) Stochastic backpropagation and approximate inference in deep generative models (Rezende, Danilo Jimenez, Mohamed, Shakir, and Wierstra, Daan. arXiv preprint arXiv:1401.4082, 2014) 2006 1989 2008 Autoencoder의 확장판들(variants) 2010 2013 하기 외에도 Contrative Autoencoder, Multimodal Autoencoder 등 수많은 variants가 존재함 진정한 의미의 generative model 완성 input을 손상시키고 복구함 endcoding할 때 input의 일부만 넣음 준비 시간이 부족해서(ㅠㅠ) denoising autoencoder만 간단히 정리했습니다...
- 20. 20 • 손상된 일부의 input를 가지고 training해서 복구된 original input을 output으로 만듦 • identity function을 learning을 방지하고 noise에 robust한 모델을 만들기 위함 • 손상 프로세스: input에 stochastic corruption(랜덤한 손상)을 추가함 • v의 확률로, random하게 input의 일부를 0으로 설정함(v~0.5) • 위 방법 말고 다른 방법의 corruption을 사용해도 무방함 • 손상 프로세스 취소: Corrupted input tilda X로부터 X’를 reconstruct(복원)함 • 이를 위해선 input distribution을 잘 알아야함 • Loss function은 x’와 noise가 없는 본래의 input x를 비교해서 계산함 • Unsupervised pretraining에서 RBM과 비슷하거나 더 좋은 성능을 보임 Denoising autoencoder https://www.slideshare.net/zukun/icml2012-tutorial-representationlearning
- 21. 21 그럼 요새는 autoencoder가 주로 어떻게 활용되나? Dimension reduction? Reconstruction? Pretraining? (대개 3가지는 함께하는 것이긴 하지만…) Supervised 문제에서 Pretraining하는 역할이 제일 주목받고 있음
- 22. 22 Unsupervised Pretraining의 효과 (1) • Bengio는 RBM와 DBN을 확장해서 continuous value input을 사용할 수 있게 확장 하고 DBN을 supervised learning task에 적용한 후 하기와 같은 실험을 수행함 • 그 결과, Greedy unsupervised layer-wise training이 deep networks를 최적화와 일반화(generalization)에도 도움이 된다는 걸 증명함. 특히, DBN 뿐 아니라 deep net, shallow net에서도 유용함을 밝힘 • 후에 이와 유사하게 autoencoder를 활용하여 supervised learning task의 성능을 높이는 연구들이 나옴 Greedy Layer-Wise Training for Deep Networks, Bengio et al. NIPS 2006 *Autoencoder를 AutoAssociator(AA)로 표현하는 경우도 있음 *
- 23. 23 https://www.slideshare.net/zukun/icml2012-tutorial-representationlearning Why does unsupervised pre-training help deep learning? (Dumitru Erhan, Yoshua Bengio, Aaron Courville, Pierre-Antoine Manzagol, Pascal Vincent,and Samy Bengio. JMLR, 11:625–660, February 2010) 최적해 근처로 initial weight을 주는 효과는 대단함! 하기는 SDAE(Stacked Denoising Autoencoder)로 pretraining한 후 supervised DBN에 적용한 결과 Unsupervised Pretraining의 효과 (2)
- 24. 24 끝
- 25. 25 https://ko.wikipedia.org/wiki/유클리드_기하학 http://astronaut94.tistory.com/6 Euclidean Space와 Manifold(다양체) Euclidean Space: Euclidean Plane는 2차원이기 때문에 3차원으로 가면 Euclidean Geometry로 확장됨. Euclidean Space에서 성립하는 5가지 공리가 있는데 그 내용은 하기와 같음 • 임의의 점과 다른 한 점을 연결하는 직선은 단 하나뿐이다. • 임의의 선분은 양끝으로 얼마든지 연장할 수 있다. • 임의의 점을 중심으로 하고 임의의 길이를 반지름으로 하는 원을 그릴 수 있다. • 직각은 모두 서로 같다. • 평행선 공준: 두 직선이 한 직선과 만날 때, 같은 쪽에 있는 내각의 합이 2직각(180˚)보다 작으 면 이 두 직선을 연장할 때 2직각보다 작은 내각을 이루는 쪽에서 반드시 만난다. Manifold: a topological space that is locally Euclidean, 즉, 작은 영역에서 Euclidean 인 위상 공간으로 비유클리드 공간이 생기면서 생겨난 개념 • 유클리드 공간에서의 5번째 공리인 평행선 공리가 지구의 관점에선 안 맞지만 영역 을 아주 작게 만들어서 땅을 한정지으면 성립함. • 이렇게 작은 영역에서는 유클리드의 5번째 공리까지 모든 공리가 성립할 수 있으므 로 이 공간을 Manifold라고 함
- 26. 26 “Bottleneck” code i.e., low-dimensional, typically dense, distributed representation “Overcomplete” code i.e., high-dimensional, always sparse, distributed representation Code Input Target = input Code Input Target = input Bottleneck code vs. Overcomplete code https://www.slideshare.net/danieljohnlewis/piotr-mirowski-review-autoencoders-deep-learning-ciuuk14 Code를 표시하는 두 가지 방법에 대한 설명임. 일반적인 autoencoder는 low-dimensional 하기 때문에 항상 bottleneck code라고 보면 됨. 단, sparse coding인 sparse autoencoder는 overcomplete code의 형태임
- 28. 28 Pretraining 적용 시의 Loss Function (수식) http://stats.stackexchange.com/questions/119959/what-does-pre-training-mean-in-deep-autoencoder
- 29. 29 Unsupervised pretraining이 잘 작동하는 이유는? Why does unsupervised pre-training help deep learning? Dumitru Erhan et al, JMLR 2010 • Regularization hypothesis • 모델을 P(x)에 가깝도록 만듦 • P(X)를 잘 표현하면 P(y|X)도 잘 표현할 수 있음 • Optimization hypothesis • unsupervised pretraining으로 최적해에 더 가까운 initial로 시작함 • random initialization에서는 얻을 수 없는 lower local minimum에 도달 가능 • layer별로 training하는 게 훨씬 쉬움