Download to read offline

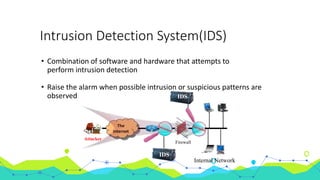




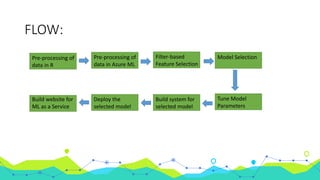

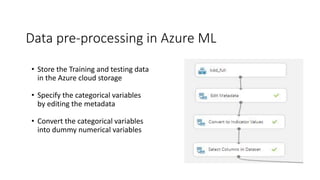







This document discusses using machine learning for intrusion detection. It begins by explaining what an intrusion detection system (IDS) is and why they are needed. It then describes the main types of IDS, including host-based, network-based, signature-based, and anomaly-based. It introduces the KDD Cup 99 dataset, which is used to train and evaluate machine learning models for intrusion detection. The document outlines the process used, including pre-processing the data in R and Azure ML, feature selection, model selection and parameter tuning, and building and deploying a boosted decision tree model as a web service for intrusion detection.



















































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)


