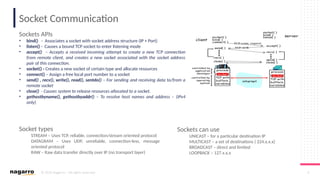
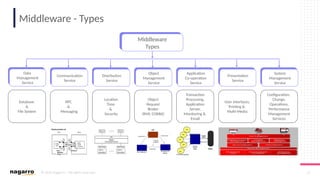
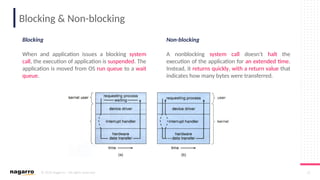
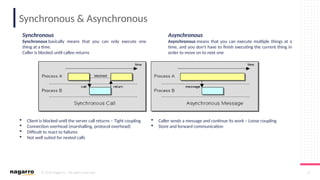
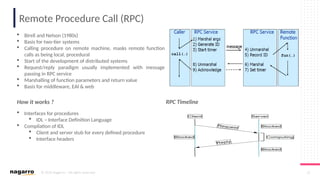
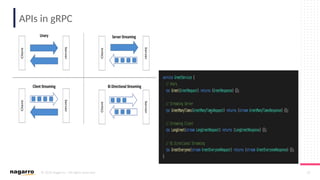
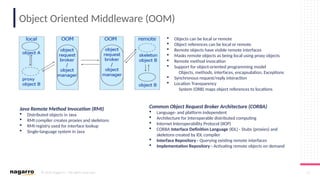
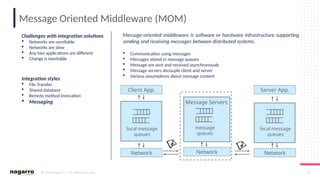
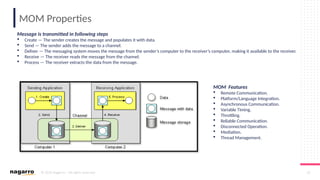
#6 Three types of sockets are supported:
Stream sockets allow processes to communicate using TCP. A stream socket provides bidirectional, reliable, sequenced, and unduplicated flow of data with no record boundaries. After the connection has been established, data can be read from and written to these sockets as a byte stream. The socket type is SOCK_STREAM.
Datagram sockets allow processes to use UDP to communicate. A datagram socket supports bidirectional flow of messages. A process on a datagram socket can receive messages in a different order from the sending sequence and can receive duplicate messages. Record boundaries in the data are preserved. The socket type is SOCK_DGRAM.
Raw sockets provide access to ICMP. These sockets are normally datagram oriented, although their exact characteristics are dependent on the interface provided by the protocol. Raw sockets are not for most applications. They are provided to support developing new communication protocols or for access to more esoteric facilities of an existing protocol. Only superuser processes can use raw sockets. The socket type is SOCK_RAW.
Local Loopback Address:
Local Loopback Address is used to let a system send a message to itself to make sure that TCP/IP stack is installed correctly on the machine.
In IPv4, IP addresses that start with decimal 127 or that has 01111111 in the first octet are loopback addresses(127.X.X.X). Typically 127.0.0.1 is used as the local loopback address.
This leads to the wastage of many potential IP addresses. But in IPv6 ::1 is used as local loopback address and therefore there isn’t any wastage of addresses.
The IP address 127.0.0.1 is a special-purpose IPv4 address called localhost or loopback address. All computers use this address as their own but it doesn't let them communicate with other devices as a real IP address does.
Your computer might have the 192.168.1.115 private IP address assigned to it so that it can communicate with a router and other networked devices. However, it still has this special 127.0.0.1 address attached to it to mean "this computer," or the one you're currently on.
The loopback address is only used by the computer you're on, and only for special circumstances — unlike a regular IP address that is used to transfer files to and from other networked devices.
For example, a web server running on a computer can point to 127.0.0.1 so that the pages can be run locally and tested before it's deployed.
In terms of IP addresses this means that any communications to that address effectively never leave or perhaps never actually enter your network interface card so that you always have a "connection".
This allows you to test client/server software (for example) with both parts running on the same machine.
A loopback address is "connected" to a virtual network card in your machine called the loopback adapter.
Anything sent to the virtual loopback adapter comes right back out of it. It's like it's "connected to itself."
For example, if I make a web request by typing "http://127.0.0.1/somesite.html" in my browser, that request goes through the (virtual) loopback adapter and then right back out of it.
So, if you have web server running on your system, and it's listening on 127.0.0.1, it will receive the request from your browser, and also be able to communicate with your browser by sending its response back to 127.0.0.1.
This is excellent for testing purposes, as you can see.
Nothing going through the loopback adapter goes out to the Internet, or leaves your system. The loopback adapter is completely contained within your system.
#17 What are protocol buffers?
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the "old" format.
How do they work?
You specify how you want the information you're serializing to be structured by defining protocol buffer message types in .proto files. Each protocol buffer message is a small logical record of information, containing a series of name-value pairs. Here's a very basic example of a .proto file that defines a message containing information about a person:
message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4; }
As you can see, the message format is simple – each message type has one or more uniquely numbered fields, and each field has a name and a value type, where value types can be numbers (integer or floating-point), booleans, strings, raw bytes, or even (as in the example above) other protocol buffer message types, allowing you to structure your data hierarchically. You can specify optional fields, required fields, and repeated fields. You can find more information about writing .proto files in the Protocol Buffer Language Guide.
Once you've defined your messages, you run the protocol buffer compiler for your application's language on your .proto file to generate data access classes. These provide simple accessors for each field (like name() and set_name()) as well as methods to serialize/parse the whole structure to/from raw bytes – so, for instance, if your chosen language is C++, running the compiler on the above example will generate a class called Person. You can then use this class in your application to populate, serialize, and retrieve Person protocol buffer messages. You might then write some code like this:
Person person;
person.set_name("John Doe");
person.set_id(1234);
person.set_email("jdoe@example.com");
fstream output("myfile", ios::out | ios::binary);
person.SerializeToOstream(&output);
Then, later on, you could read your message back in:
fstream input("myfile", ios::in | ios::binary);
Person person;
person.ParseFromIstream(&input);
cout << "Name: " << person.name() << endl;
cout << "E-mail: " << person.email() << endl;
You can add new fields to your message formats without breaking backwards-compatibility; old binaries simply ignore the new field when parsing. So if you have a communications protocol that uses protocol buffers as its data format, you can extend your protocol without having to worry about breaking existing code.
You'll find a complete reference for using generated protocol buffer code in the API Reference section, and you can find out more about how protocol buffer messages are encoded in Protocol Buffer Encoding.
#18 What are protocol buffers?
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the "old" format.
How do they work?
You specify how you want the information you're serializing to be structured by defining protocol buffer message types in .proto files. Each protocol buffer message is a small logical record of information, containing a series of name-value pairs. Here's a very basic example of a .proto file that defines a message containing information about a person:
message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4; }
As you can see, the message format is simple – each message type has one or more uniquely numbered fields, and each field has a name and a value type, where value types can be numbers (integer or floating-point), booleans, strings, raw bytes, or even (as in the example above) other protocol buffer message types, allowing you to structure your data hierarchically. You can specify optional fields, required fields, and repeated fields. You can find more information about writing .proto files in the Protocol Buffer Language Guide.
Once you've defined your messages, you run the protocol buffer compiler for your application's language on your .proto file to generate data access classes. These provide simple accessors for each field (like name() and set_name()) as well as methods to serialize/parse the whole structure to/from raw bytes – so, for instance, if your chosen language is C++, running the compiler on the above example will generate a class called Person. You can then use this class in your application to populate, serialize, and retrieve Person protocol buffer messages. You might then write some code like this:
Person person;
person.set_name("John Doe");
person.set_id(1234);
person.set_email("jdoe@example.com");
fstream output("myfile", ios::out | ios::binary);
person.SerializeToOstream(&output);
Then, later on, you could read your message back in:
fstream input("myfile", ios::in | ios::binary);
Person person;
person.ParseFromIstream(&input);
cout << "Name: " << person.name() << endl;
cout << "E-mail: " << person.email() << endl;
You can add new fields to your message formats without breaking backwards-compatibility; old binaries simply ignore the new field when parsing. So if you have a communications protocol that uses protocol buffers as its data format, you can extend your protocol without having to worry about breaking existing code.
You'll find a complete reference for using generated protocol buffer code in the API Reference section, and you can find out more about how protocol buffer messages are encoded in Protocol Buffer Encoding.
#19 What are protocol buffers?
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the "old" format.
How do they work?
You specify how you want the information you're serializing to be structured by defining protocol buffer message types in .proto files. Each protocol buffer message is a small logical record of information, containing a series of name-value pairs. Here's a very basic example of a .proto file that defines a message containing information about a person:
message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4; }
As you can see, the message format is simple – each message type has one or more uniquely numbered fields, and each field has a name and a value type, where value types can be numbers (integer or floating-point), booleans, strings, raw bytes, or even (as in the example above) other protocol buffer message types, allowing you to structure your data hierarchically. You can specify optional fields, required fields, and repeated fields. You can find more information about writing .proto files in the Protocol Buffer Language Guide.
Once you've defined your messages, you run the protocol buffer compiler for your application's language on your .proto file to generate data access classes. These provide simple accessors for each field (like name() and set_name()) as well as methods to serialize/parse the whole structure to/from raw bytes – so, for instance, if your chosen language is C++, running the compiler on the above example will generate a class called Person. You can then use this class in your application to populate, serialize, and retrieve Person protocol buffer messages. You might then write some code like this:
Person person;
person.set_name("John Doe");
person.set_id(1234);
person.set_email("jdoe@example.com");
fstream output("myfile", ios::out | ios::binary);
person.SerializeToOstream(&output);
Then, later on, you could read your message back in:
fstream input("myfile", ios::in | ios::binary);
Person person;
person.ParseFromIstream(&input);
cout << "Name: " << person.name() << endl;
cout << "E-mail: " << person.email() << endl;
You can add new fields to your message formats without breaking backwards-compatibility; old binaries simply ignore the new field when parsing. So if you have a communications protocol that uses protocol buffers as its data format, you can extend your protocol without having to worry about breaking existing code.
You'll find a complete reference for using generated protocol buffer code in the API Reference section, and you can find out more about how protocol buffer messages are encoded in Protocol Buffer Encoding.
#27 at most once (aka “best e.ort”; guarantees no-duplicates): in this mode, under normal operating conditions, packets will be delivered, but during failure packet loss might occur. Trying to do better than this will always cost system resources, so this mode hasthe best throughput.
at least once (guarantees no-loss): in this mode, the system will make sure that no packets get lost. Recovery from failures might cause duplicate packets to be sent, possibly out-of-order.
exactly once (guarantees no-loss and no-duplicates): this requires an expensive end-to-end two phase commit.
--------------------------
Ordering Guarantees
-------------------------
no ordering: absence of ordering guarantees is an ideal case for performance.
partitioned ordering: in this mode, a single partition can be defined for each message .ow that needs to be consumed in-order. While more expensive than the previous group, it can possibly have high performance implementations.
global order: due to the synchronization overhead, imposing a global ordering guarantee across different channels requires significant additional resources and can severely penalize performance.
#33
import org.apache.camel.CamelContext;
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.impl.DefaultCamelContext;
public class CamelHelloWorldTimerExample {
public static void main(String[] args) throws Exception {
CamelContext context = new DefaultCamelContext();
try {
context.addRoutes(new RouteBuilder() {
@Override
public void configure() throws Exception {
from("timer://myTimer?period=2000")
.setBody()
.simple("Hello World Camel fired at ${header.firedTime}")
.to("stream:out");
}
});
context.start();
Thread.sleep(10000);
} finally {
context.stop();
}
}
}
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.impl.DefaultCamelContext;
import org.apache.camel.CamelContext;
public class CamelFileApp {
public static void main(final String[] args) throws Exception {
String folderA = "file:demo/copyFrom";
String folderB= "file:demo/copyTo";
//First we get the CamelContext
CamelContext camelContext = new DefaultCamelContext();
//Next we provide the Route info and tell Camel to set idempotent=true
//by adding "?noop=true" to the URI
camelContext.addRoutes(new RouteBuilder() {
@Override
public void configure() {
from(folderA+"?noop=true").to(folderB);
}
});
//initiate Camel
camelContext.start();
Thread.sleep(60000);
//remember to terminate!!!
camelContext.stop();
}
}
#38
import org.apache.camel.CamelContext;
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.impl.DefaultCamelContext;
public class CamelHelloWorldTimerExample {
public static void main(String[] args) throws Exception {
CamelContext context = new DefaultCamelContext();
try {
context.addRoutes(new RouteBuilder() {
@Override
public void configure() throws Exception {
from("timer://myTimer?period=2000")
.setBody()
.simple("Hello World Camel fired at ${header.firedTime}")
.to("stream:out");
}
});
context.start();
Thread.sleep(10000);
} finally {
context.stop();
}
}
}
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.impl.DefaultCamelContext;
import org.apache.camel.CamelContext;
public class CamelFileApp {
public static void main(final String[] args) throws Exception {
String folderA = "file:demo/copyFrom";
String folderB= "file:demo/copyTo";
//First we get the CamelContext
CamelContext camelContext = new DefaultCamelContext();
//Next we provide the Route info and tell Camel to set idempotent=true
//by adding "?noop=true" to the URI
camelContext.addRoutes(new RouteBuilder() {
@Override
public void configure() {
from(folderA+"?noop=true").to(folderB);
}
});
//initiate Camel
camelContext.start();
Thread.sleep(60000);
//remember to terminate!!!
camelContext.stop();
}
}
#39
import org.apache.camel.CamelContext;
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.impl.DefaultCamelContext;
public class CamelHelloWorldTimerExample {
public static void main(String[] args) throws Exception {
CamelContext context = new DefaultCamelContext();
try {
context.addRoutes(new RouteBuilder() {
@Override
public void configure() throws Exception {
from("timer://myTimer?period=2000")
.setBody()
.simple("Hello World Camel fired at ${header.firedTime}")
.to("stream:out");
}
});
context.start();
Thread.sleep(10000);
} finally {
context.stop();
}
}
}
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.impl.DefaultCamelContext;
import org.apache.camel.CamelContext;
public class CamelFileApp {
public static void main(final String[] args) throws Exception {
String folderA = "file:demo/copyFrom";
String folderB= "file:demo/copyTo";
//First we get the CamelContext
CamelContext camelContext = new DefaultCamelContext();
//Next we provide the Route info and tell Camel to set idempotent=true
//by adding "?noop=true" to the URI
camelContext.addRoutes(new RouteBuilder() {
@Override
public void configure() {
from(folderA+"?noop=true").to(folderB);
}
});
//initiate Camel
camelContext.start();
Thread.sleep(60000);
//remember to terminate!!!
camelContext.stop();
}
}
#41
import org.apache.camel.CamelContext;
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.impl.DefaultCamelContext;
public class CamelHelloWorldTimerExample {
public static void main(String[] args) throws Exception {
CamelContext context = new DefaultCamelContext();
try {
context.addRoutes(new RouteBuilder() {
@Override
public void configure() throws Exception {
from("timer://myTimer?period=2000")
.setBody()
.simple("Hello World Camel fired at ${header.firedTime}")
.to("stream:out");
}
});
context.start();
Thread.sleep(10000);
} finally {
context.stop();
}
}
}
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.impl.DefaultCamelContext;
import org.apache.camel.CamelContext;
public class CamelFileApp {
public static void main(final String[] args) throws Exception {
String folderA = "file:demo/copyFrom";
String folderB= "file:demo/copyTo";
//First we get the CamelContext
CamelContext camelContext = new DefaultCamelContext();
//Next we provide the Route info and tell Camel to set idempotent=true
//by adding "?noop=true" to the URI
camelContext.addRoutes(new RouteBuilder() {
@Override
public void configure() {
from(folderA+"?noop=true").to(folderB);
}
});
//initiate Camel
camelContext.start();
Thread.sleep(60000);
//remember to terminate!!!
camelContext.stop();
}
}
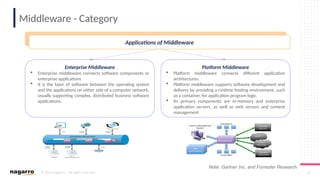
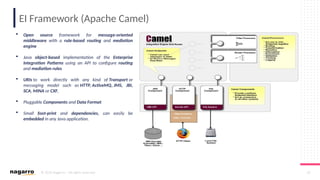
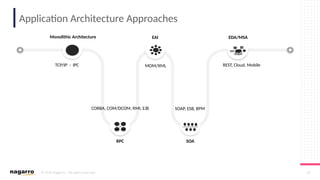
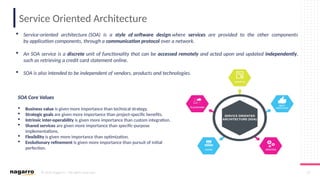
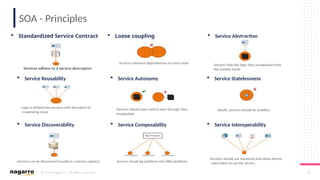
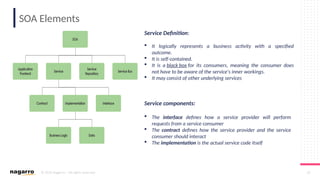
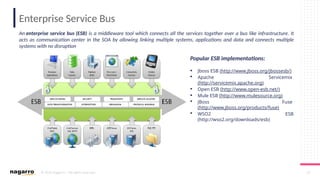
#50 ESB Core functionalities
Below are some of the core functionalities of an ESB oriented architecture:
DecouplingOne of the most important things that you can do via ESB is to decouple clients from service providers.
Transport Protocol ConversionESB gives you the ability to accept one input protocol and communicate with another service provider on a different protocol.
Message EnhancementESB allows you to isolate the client and make some basic changes to the message.
For example, changing date format of incoming message or appending informational data to messages.
Message TransformationESB lets you transform an incoming message into several outgoing formats and structure.
For example, XML to JSON, XML to Java objects.
RoutingESB has the ability to redirect a client request to a particular service provider based on deterministic or variable routing criteria.
SecurityESB protects services from unauthorized access.
Process Choreography & Service OrchestrationESB manages process flow and complex business services to perform a business operation.
Process choreography is about business services while service orchestration is the ability to manage the coordination of their actual implementations. It is also capable of abstracting business services from actual implemented services.
Transaction ManagementESB provides the ability to provide a single unit of work for a business request, providing framework for coordination of multiple disparate systems.
#51 ESB Core functionalities
Below are some of the core functionalities of an ESB oriented architecture:
DecouplingOne of the most important things that you can do via ESB is to decouple clients from service providers.
Transport Protocol ConversionESB gives you the ability to accept one input protocol and communicate with another service provider on a different protocol.
Message EnhancementESB allows you to isolate the client and make some basic changes to the message.
For example, changing date format of incoming message or appending informational data to messages.
Message TransformationESB lets you transform an incoming message into several outgoing formats and structure.
For example, XML to JSON, XML to Java objects.
RoutingESB has the ability to redirect a client request to a particular service provider based on deterministic or variable routing criteria.
SecurityESB protects services from unauthorized access.
Process Choreography & Service OrchestrationESB manages process flow and complex business services to perform a business operation.
Process choreography is about business services while service orchestration is the ability to manage the coordination of their actual implementations. It is also capable of abstracting business services from actual implemented services.
Transaction ManagementESB provides the ability to provide a single unit of work for a business request, providing framework for coordination of multiple disparate systems.
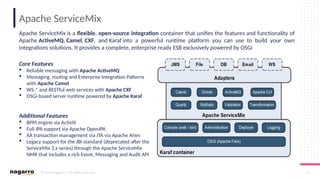
#53 Apache CXF™ is an open source services framework. CXF helps you build and develop services using frontend programming APIs, like JAX-WS and JAX-RS. These services can speak a variety of protocols such as SOAP, XML/HTTP, RESTful HTTP, or CORBA and work over a variety of transports such as HTTP, JMS or JBI.
Karaf is a lightweight, powerful, and enterprise ready applications runtime. It provides all the ecosystem and bootstrapping options you need for your applications. It runs on premise or on cloud. By polymorphic, it means that Karaf can host any kind of applications: WAR, OSGi, Spring, and much more.
The Java Business Integration spec (JBI) is a Java-based standard that defines a runtime architecture for plugins to interoperate via a mediated message exchange model.
#54 Apache CXF™ is an open source services framework. CXF helps you build and develop services using frontend programming APIs, like JAX-WS and JAX-RS. These services can speak a variety of protocols such as SOAP, XML/HTTP, RESTful HTTP, or CORBA and work over a variety of transports such as HTTP, JMS or JBI.
Karaf is a lightweight, powerful, and enterprise ready applications runtime. It provides all the ecosystem and bootstrapping options you need for your applications. It runs on premise or on cloud. By polymorphic, it means that Karaf can host any kind of applications: WAR, OSGi, Spring, and much more.
The Java Business Integration spec (JBI) is a Java-based standard that defines a runtime architecture for plugins to interoperate via a mediated message exchange model.