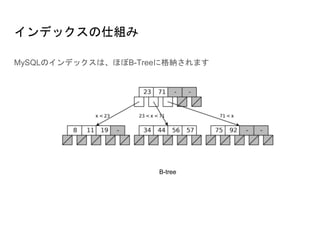
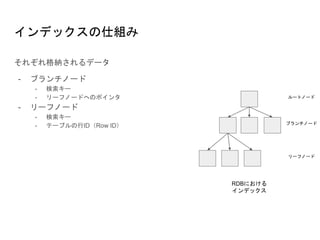
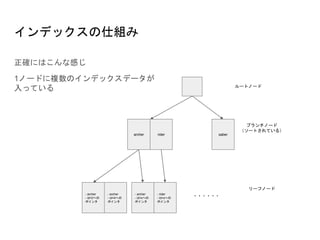
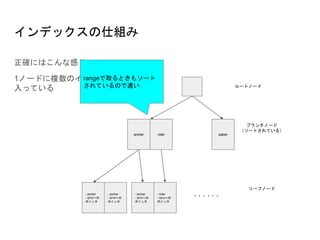
カバリングインデックスの例
先程のテーブルの例だと以下のようなクエリで、カバリングインデックスとなる
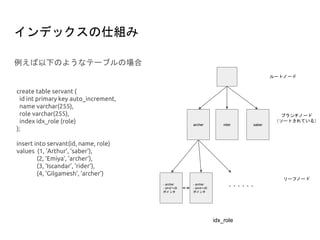
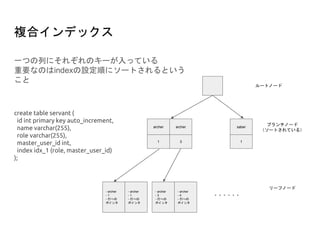
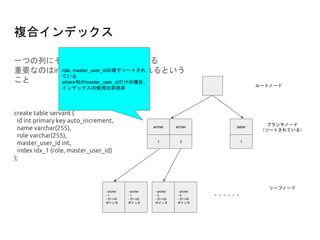
create table servant(
id int primary key auto_increment,
name varchar(255),
role varchar(255),
master_user_id int,
index idx_1 (role, master_user_id)
);
select
role, master_user_id
from servant
where role in (‘archer’, ‘lancer’)
limit 100;
























































![[OSC 2017 Tokyo/Fall] OSSコンソーシアム DB部会 MySQL 8.0](https://cdn.slidesharecdn.com/ss_thumbnails/20170909osc-osscons-mysql8-170918232718-thumbnail.jpg?width=640&height=640&fit=bounds)






























