Download to read offline



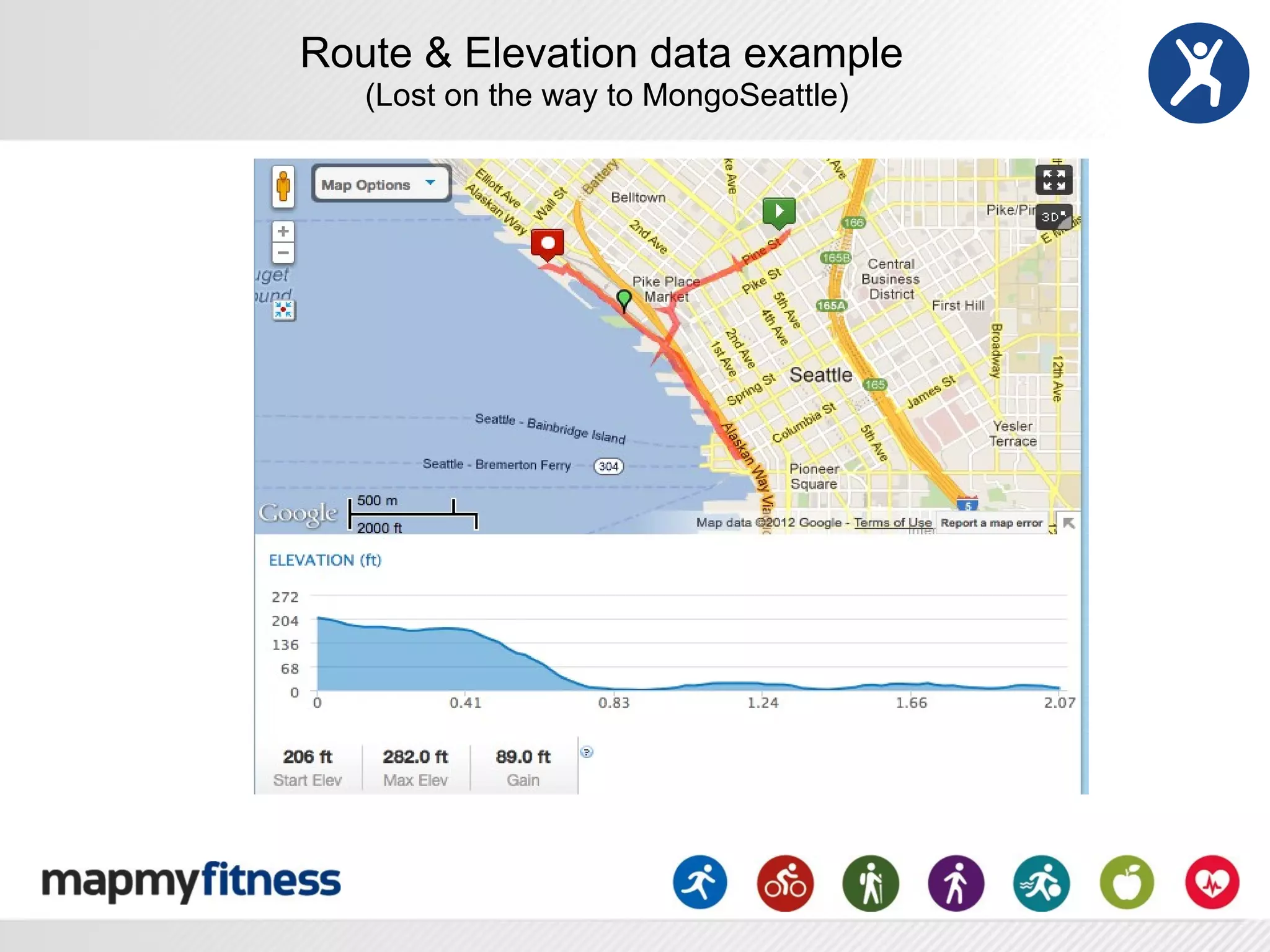


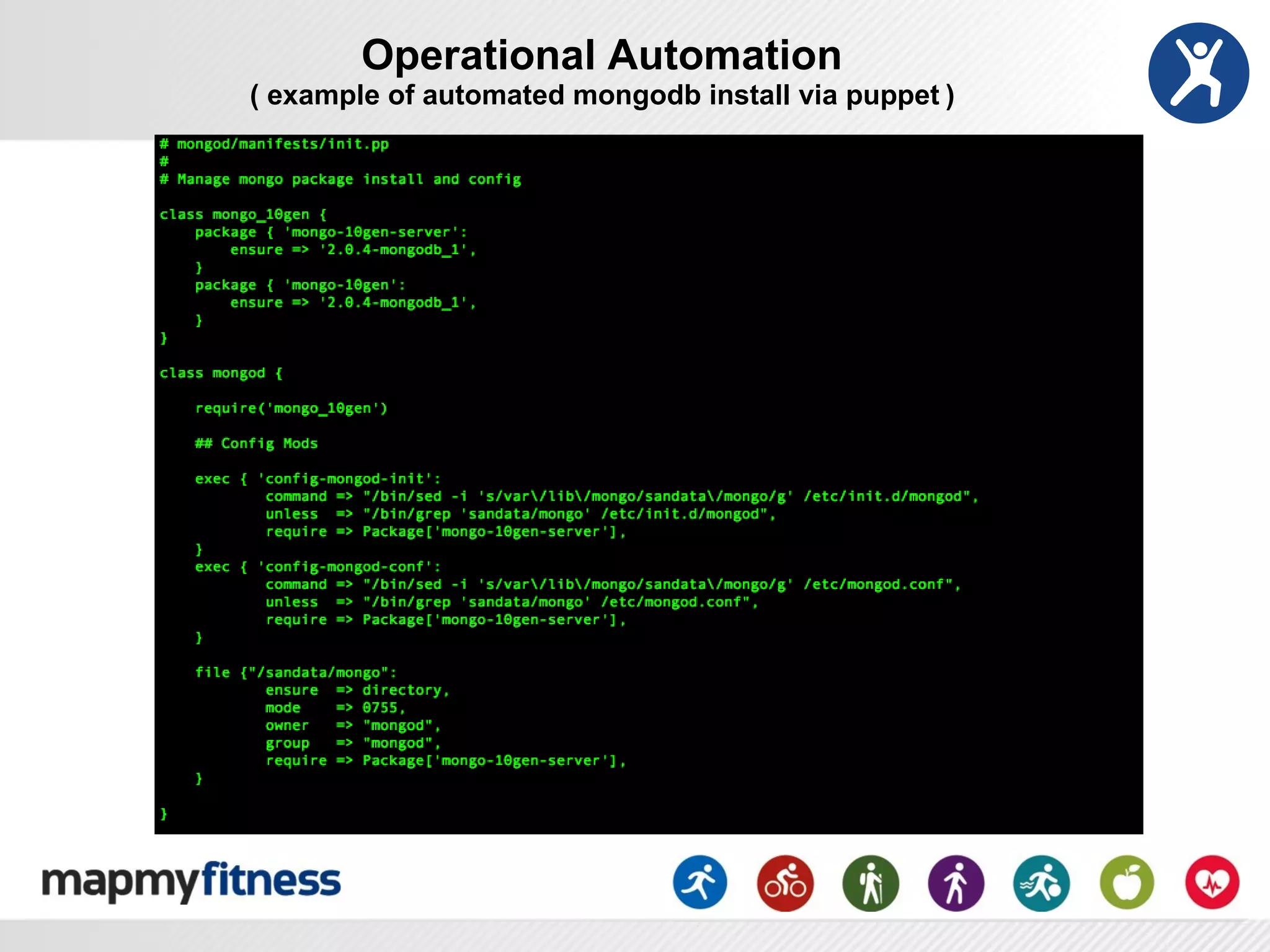


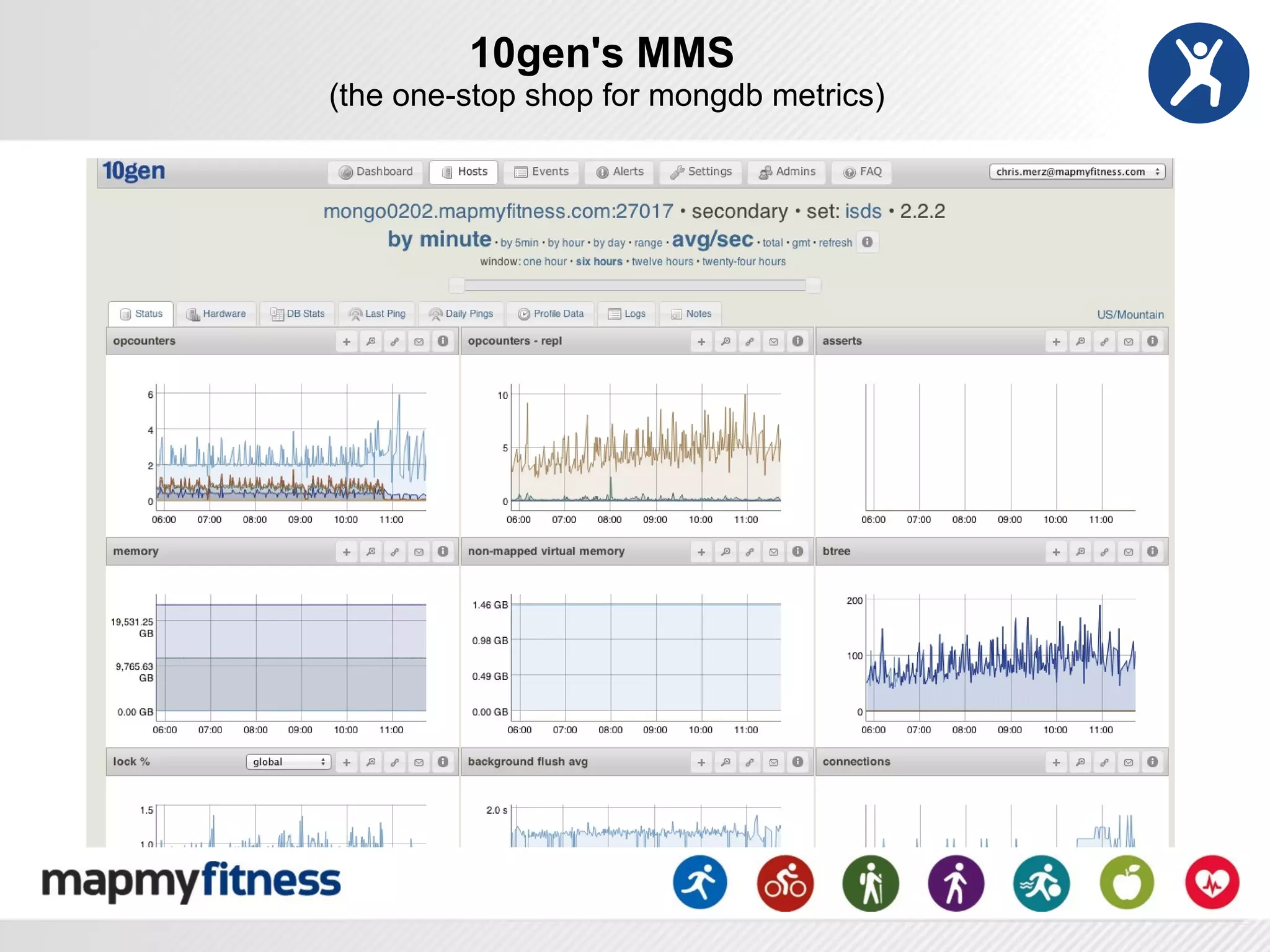
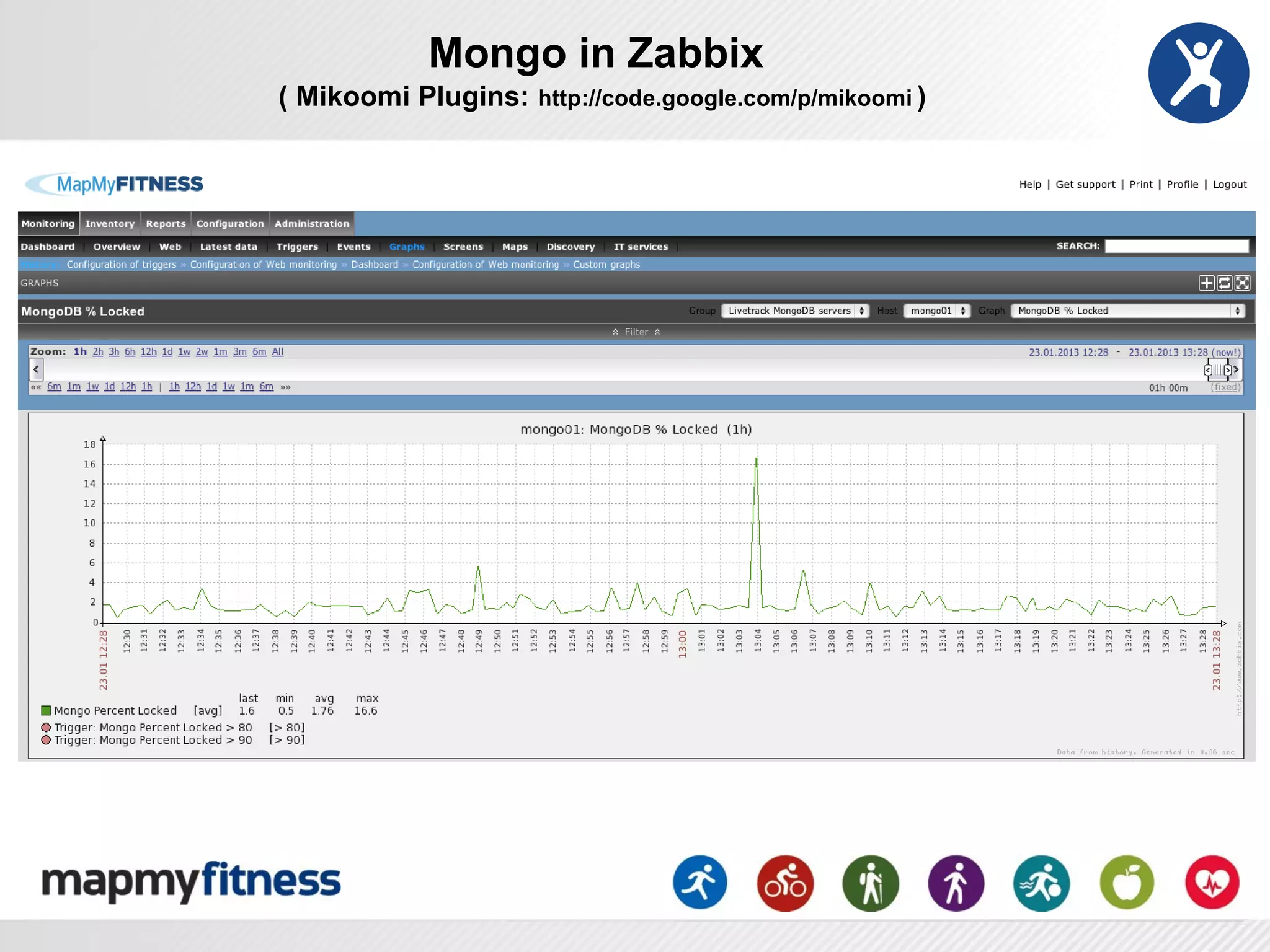









This document provides an overview of how MongoDB is used at MapMyFitness (MMF) from a DevOps perspective. It describes how MMF stores the majority of its data, including over 120 million user-generated routes and activities totaling over 7TB, in various MongoDB collections. It also discusses MMF's implementation patterns for MongoDB, including replica sets, sharding, and automation. The document outlines considerations for monitoring, maintenance, security, and performance tuning of MongoDB at scale.





















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)













