
Download to read offline






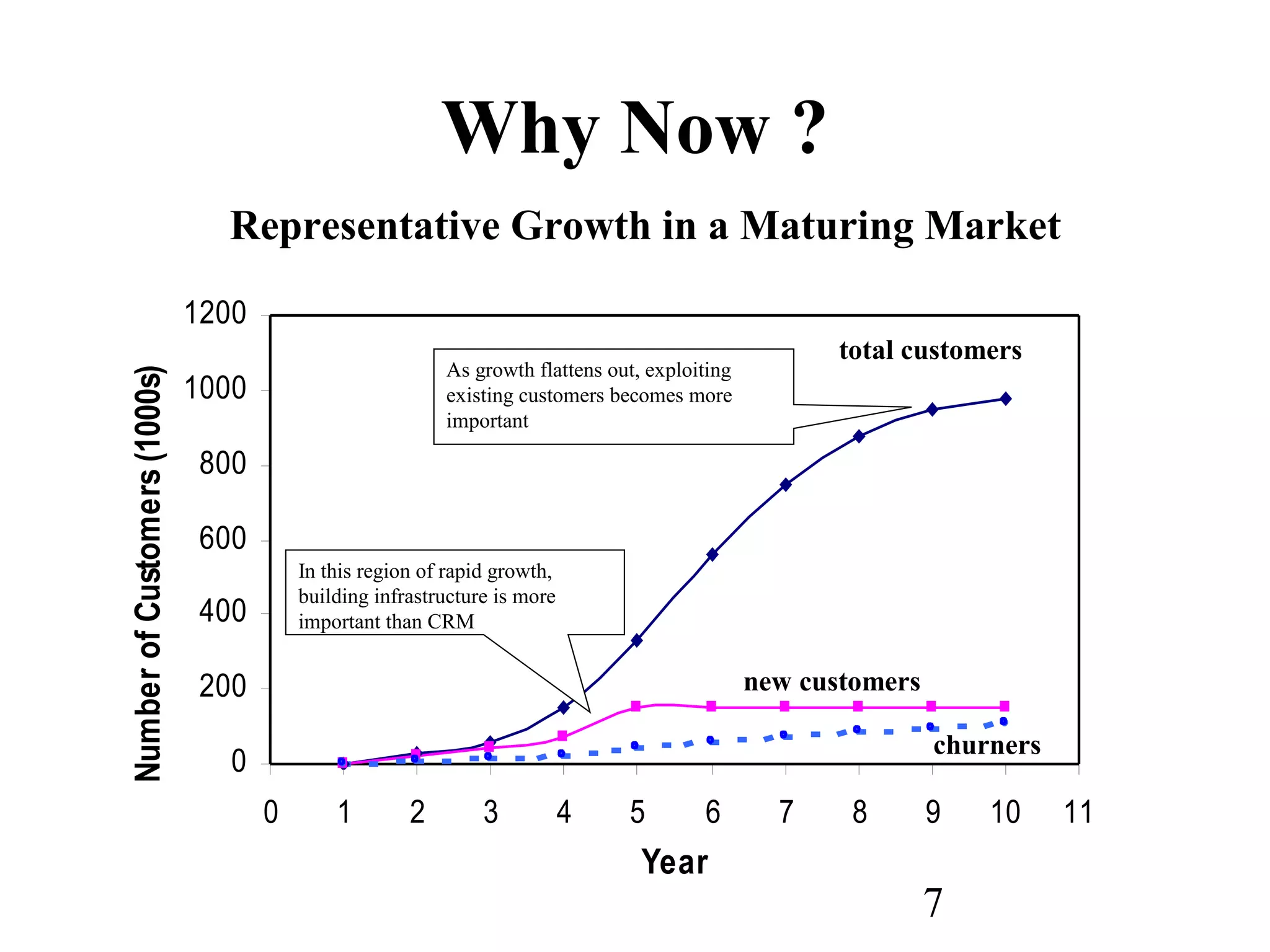
















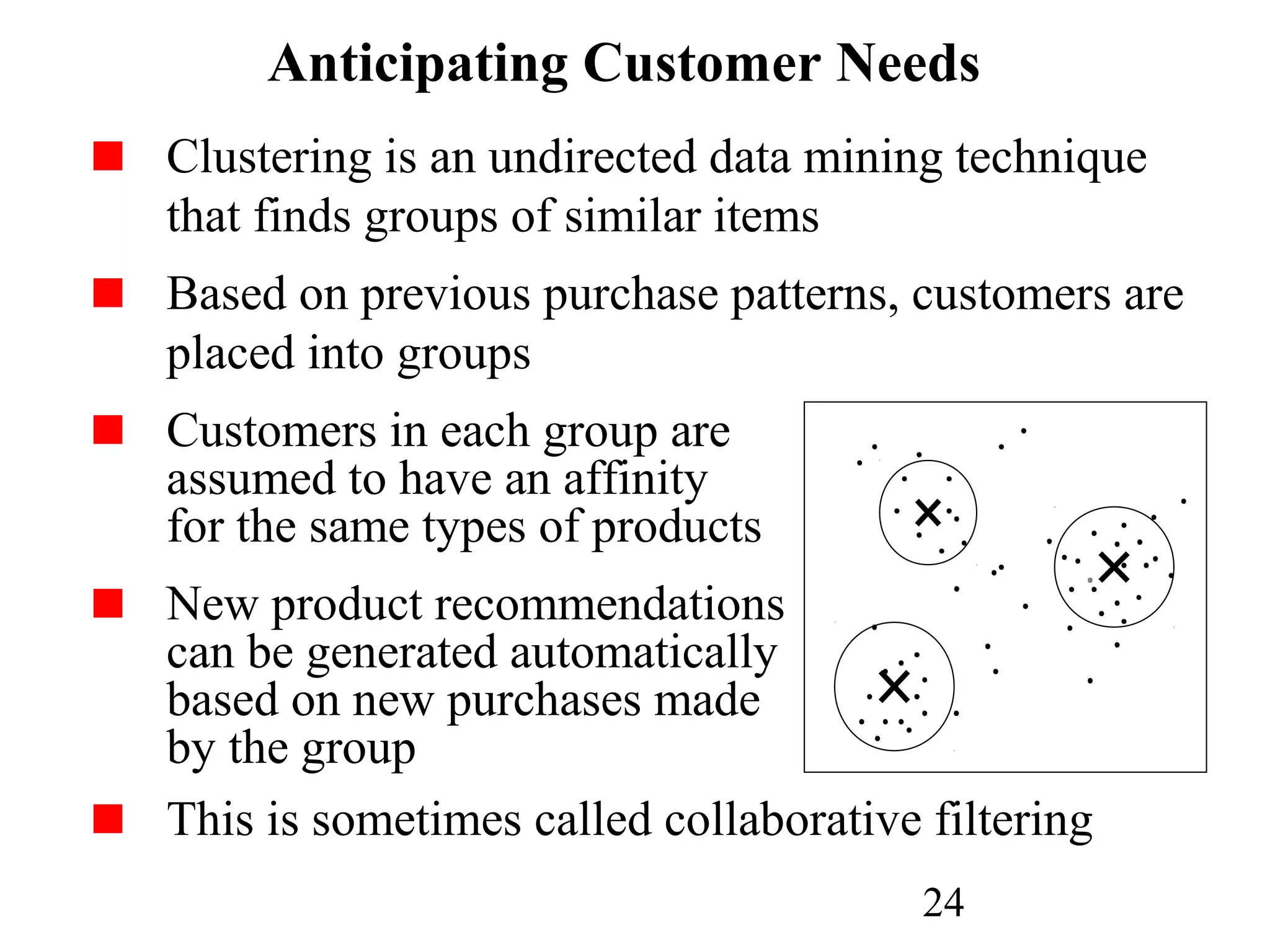








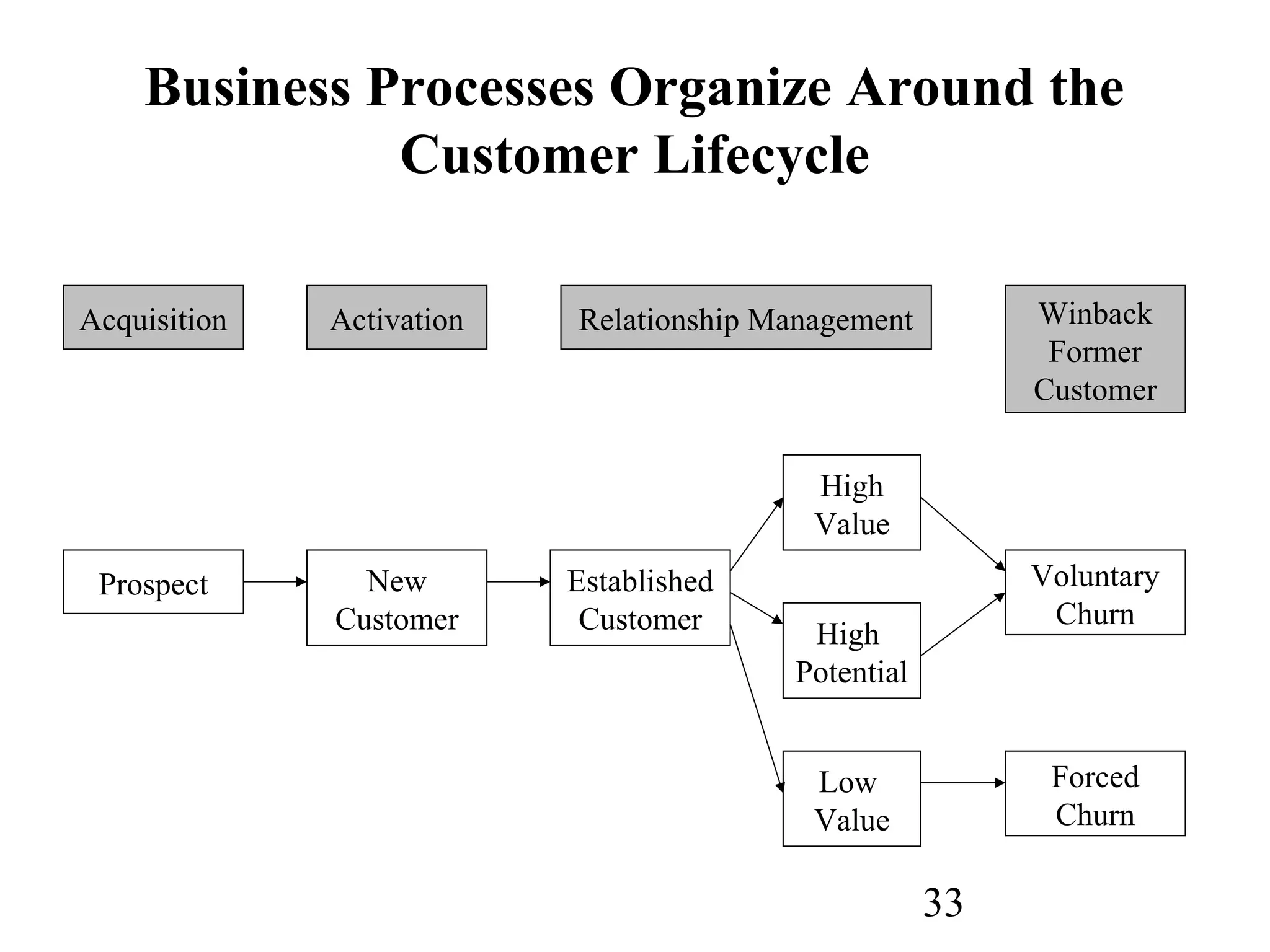

























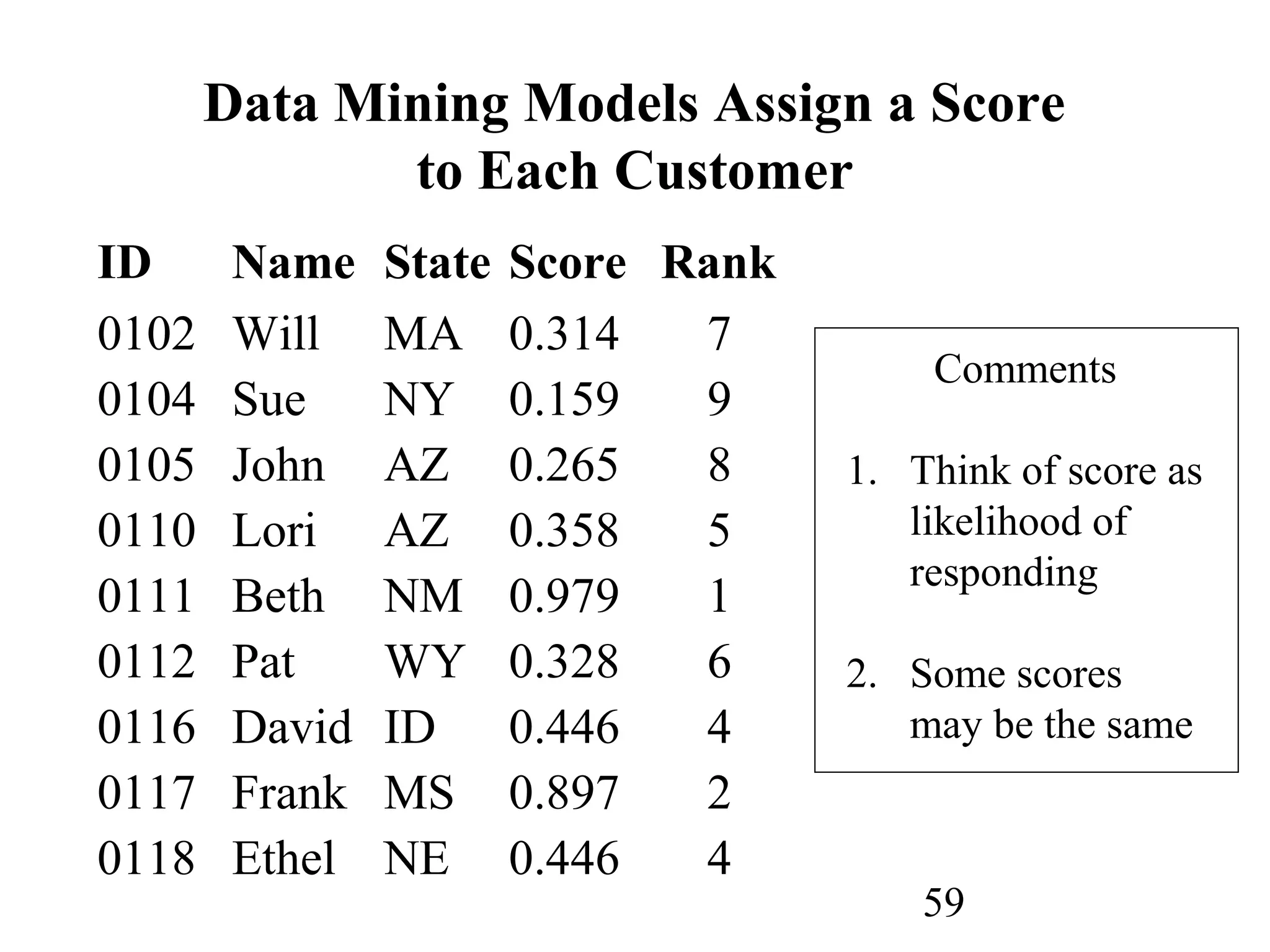


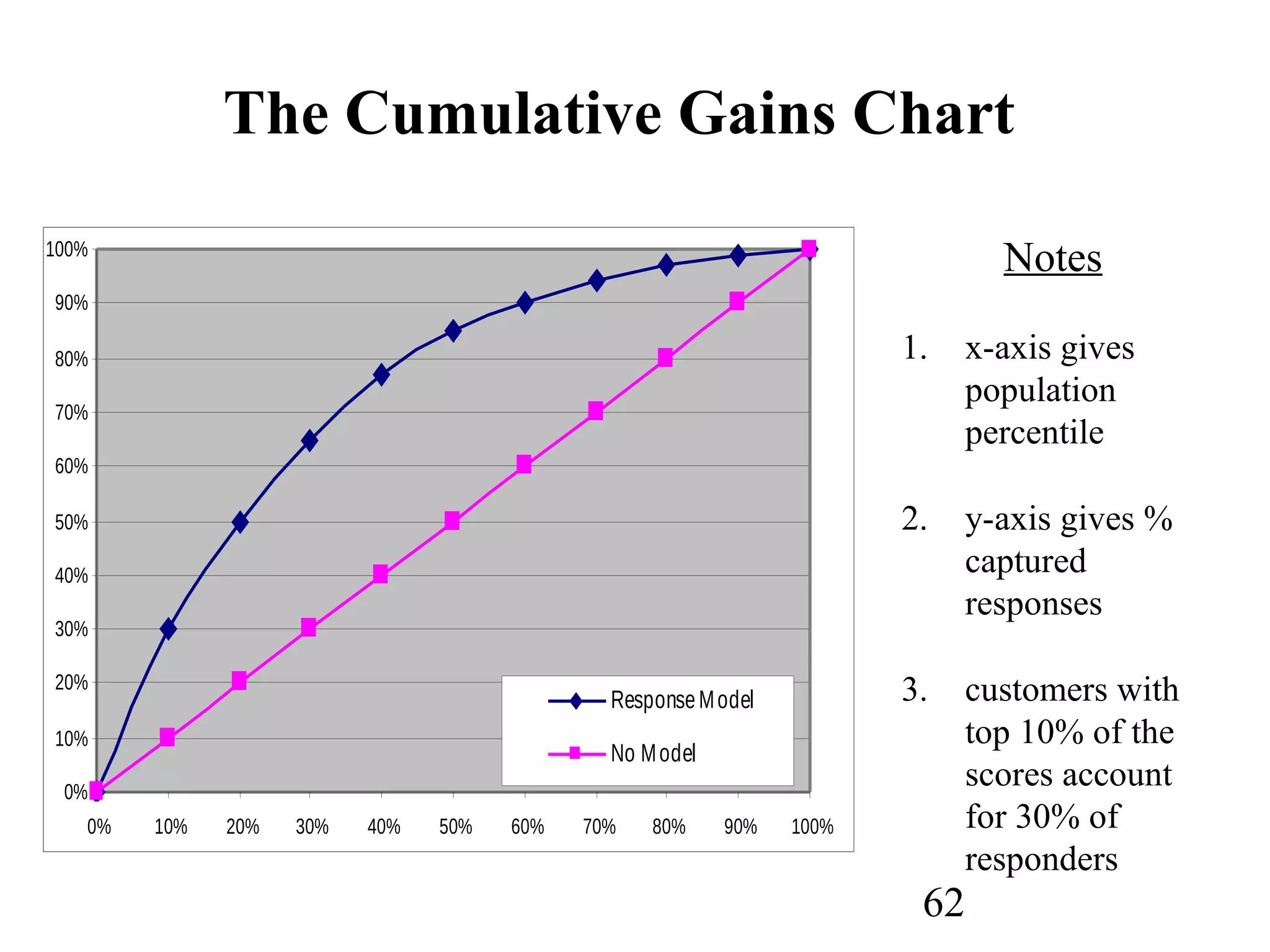
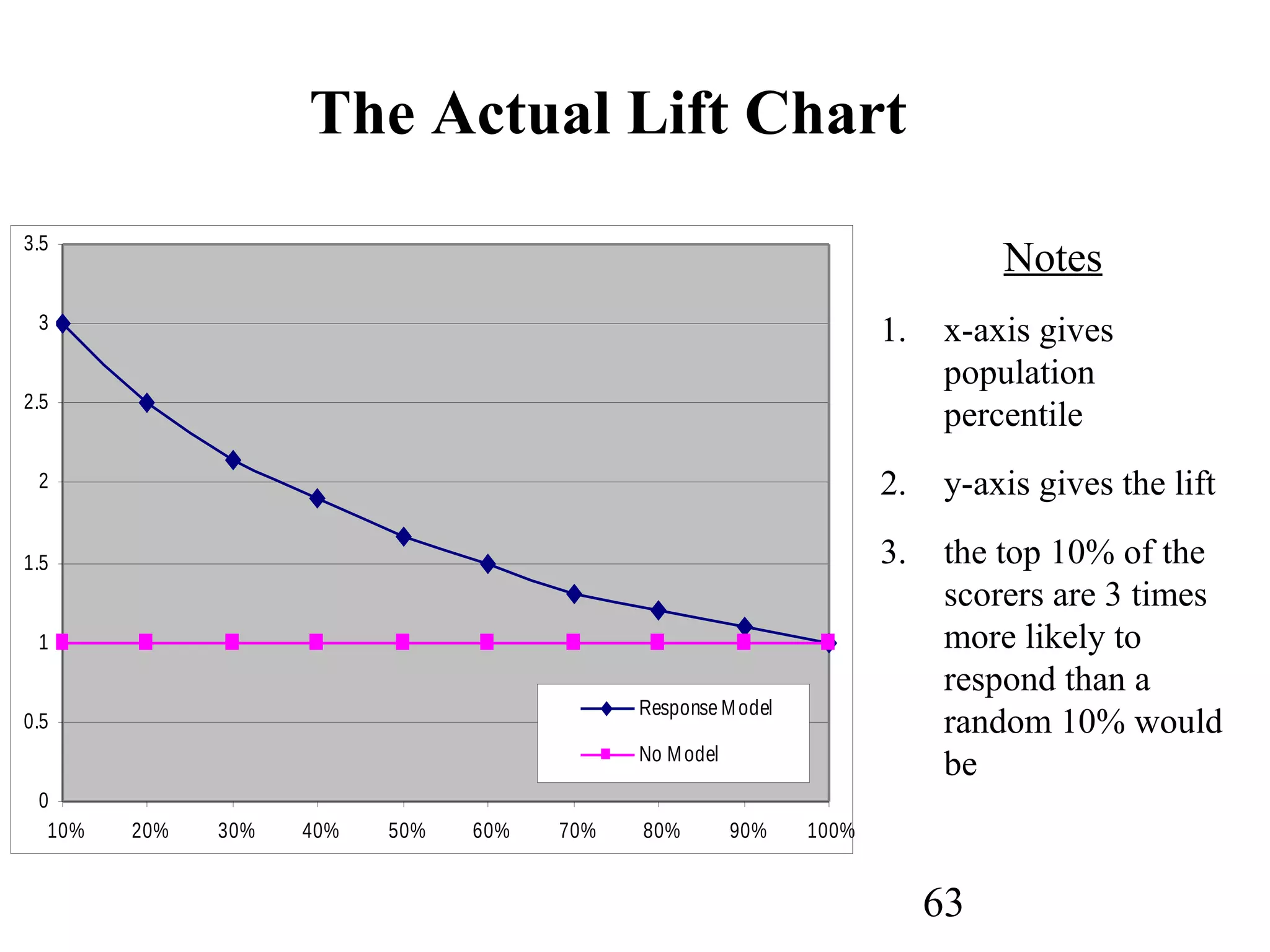









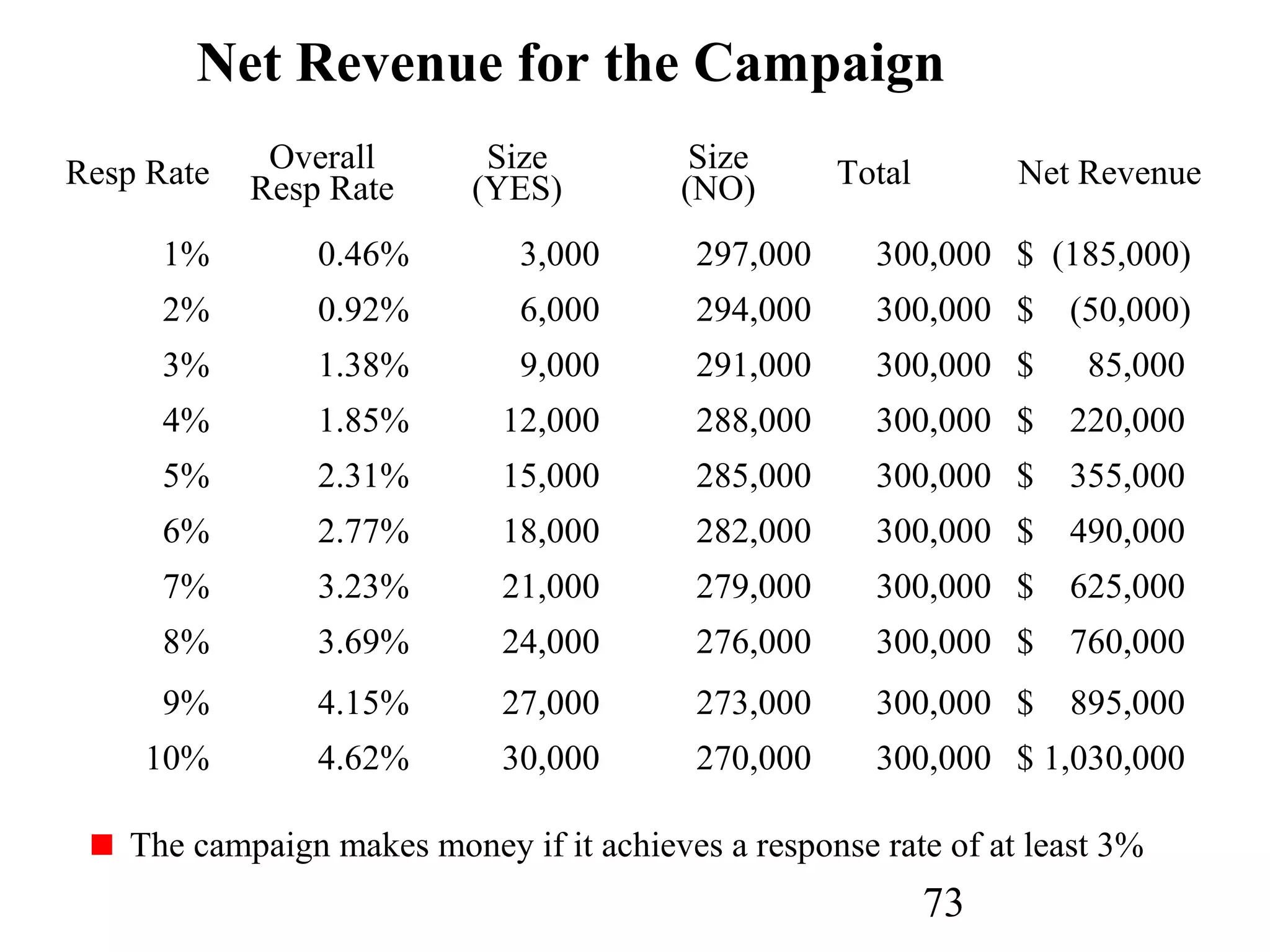
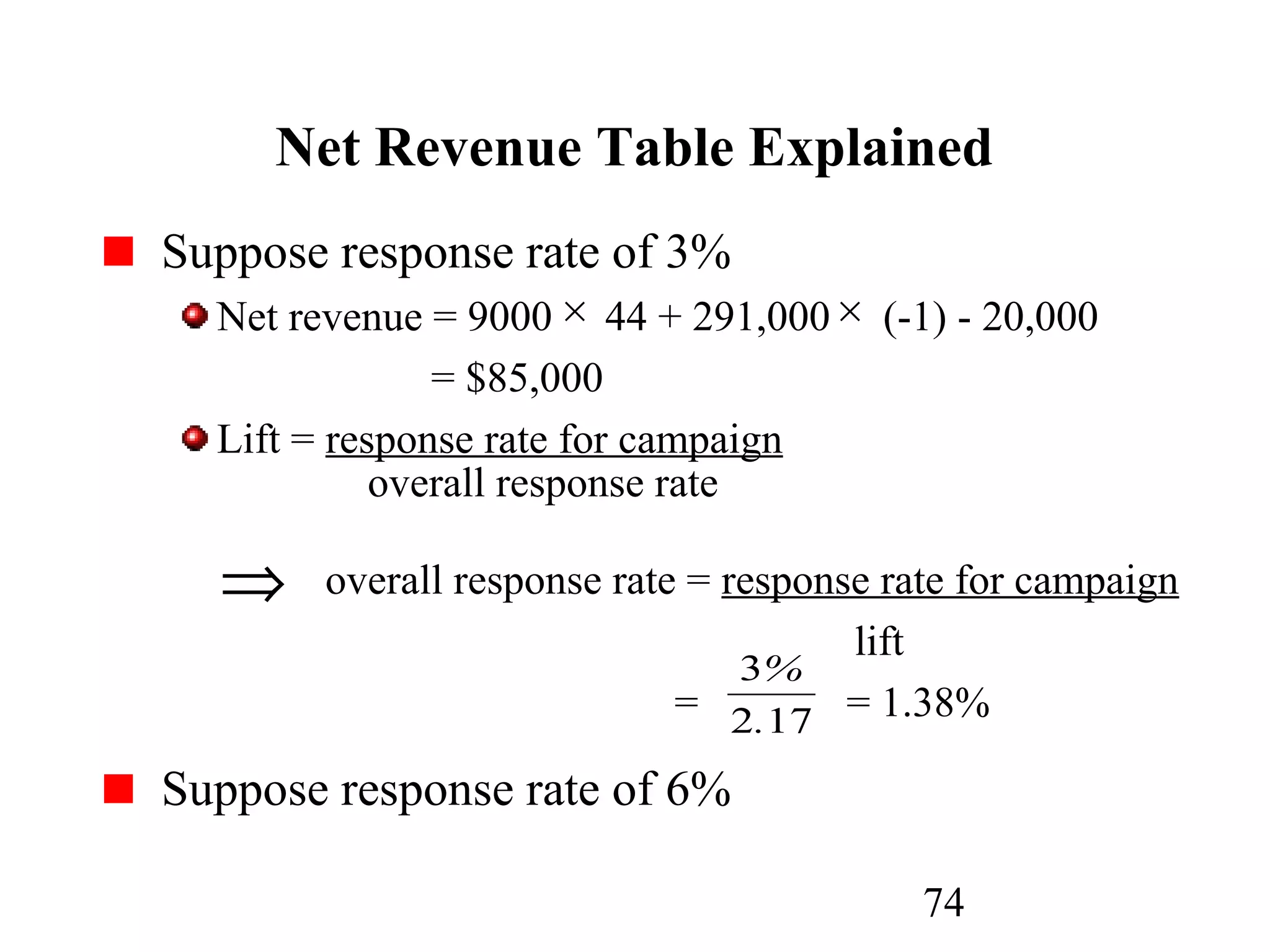


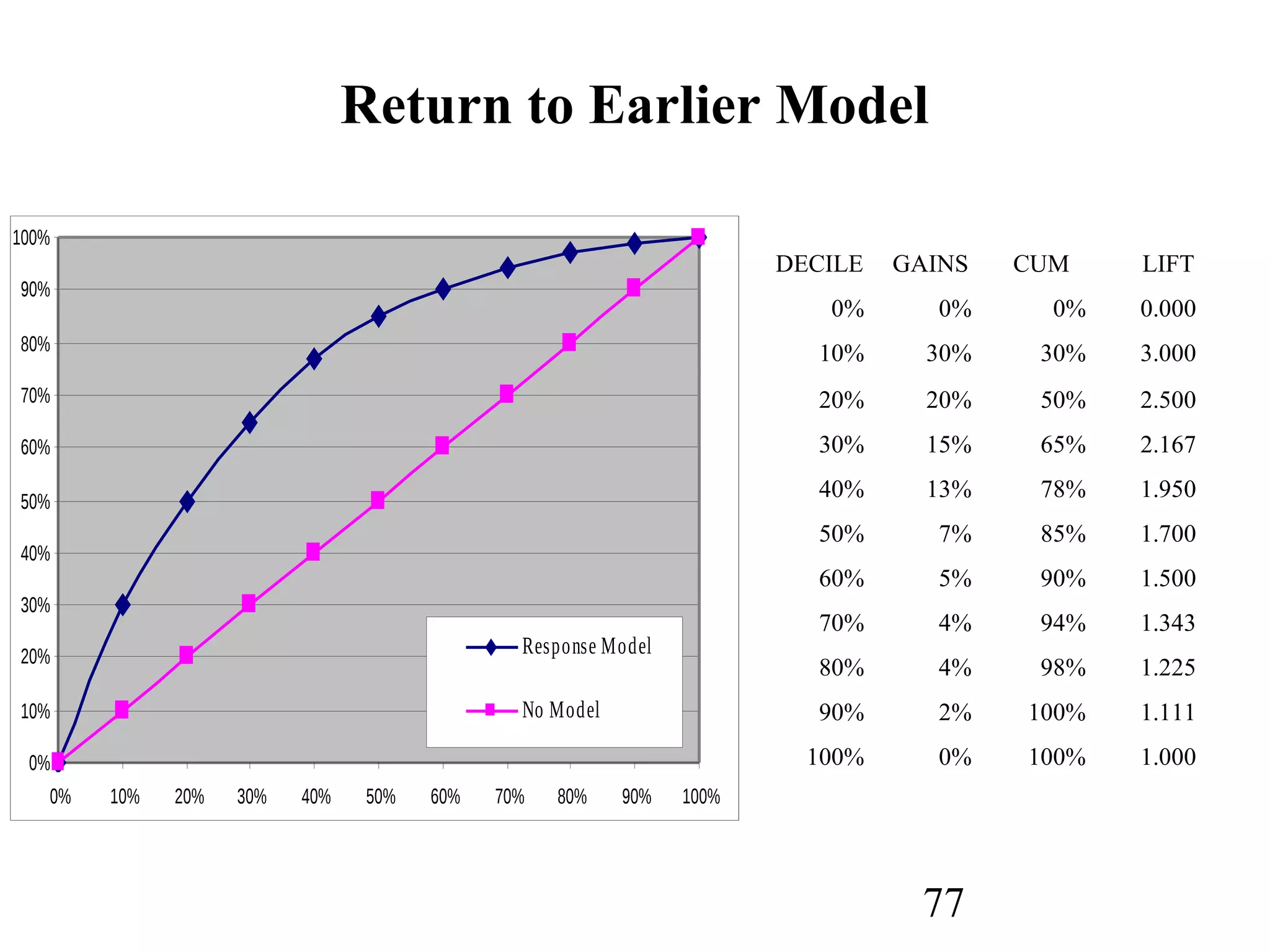
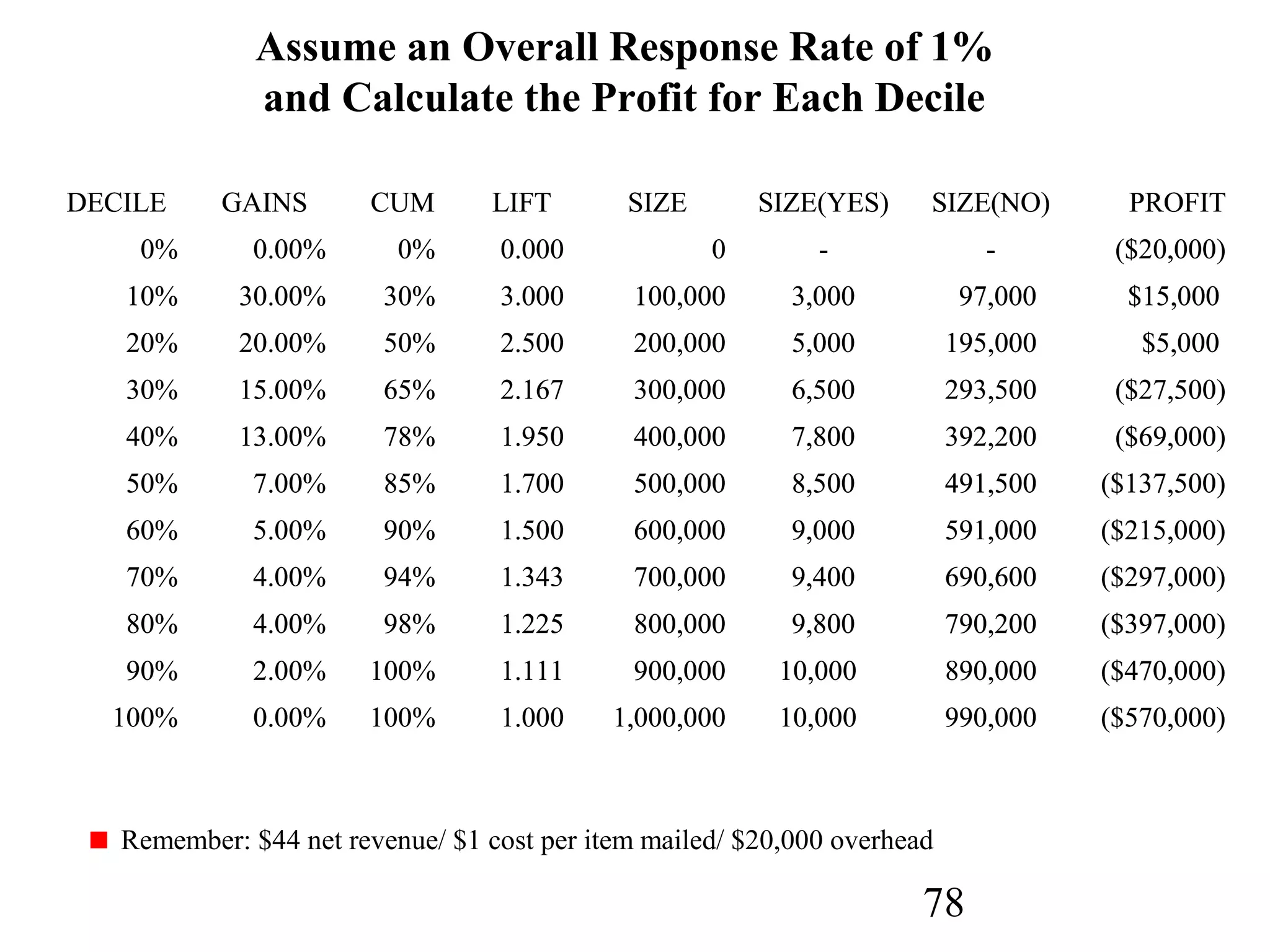

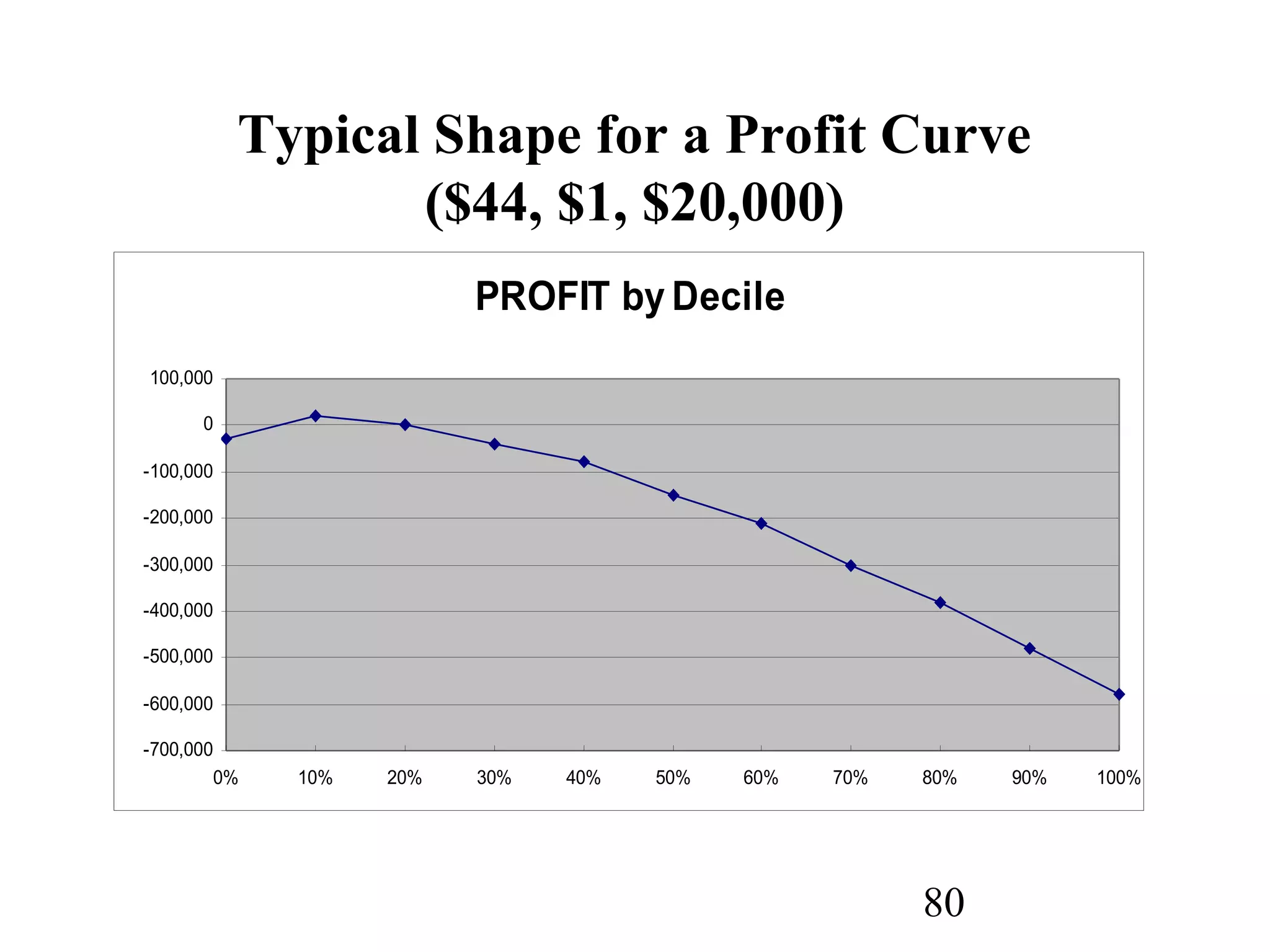


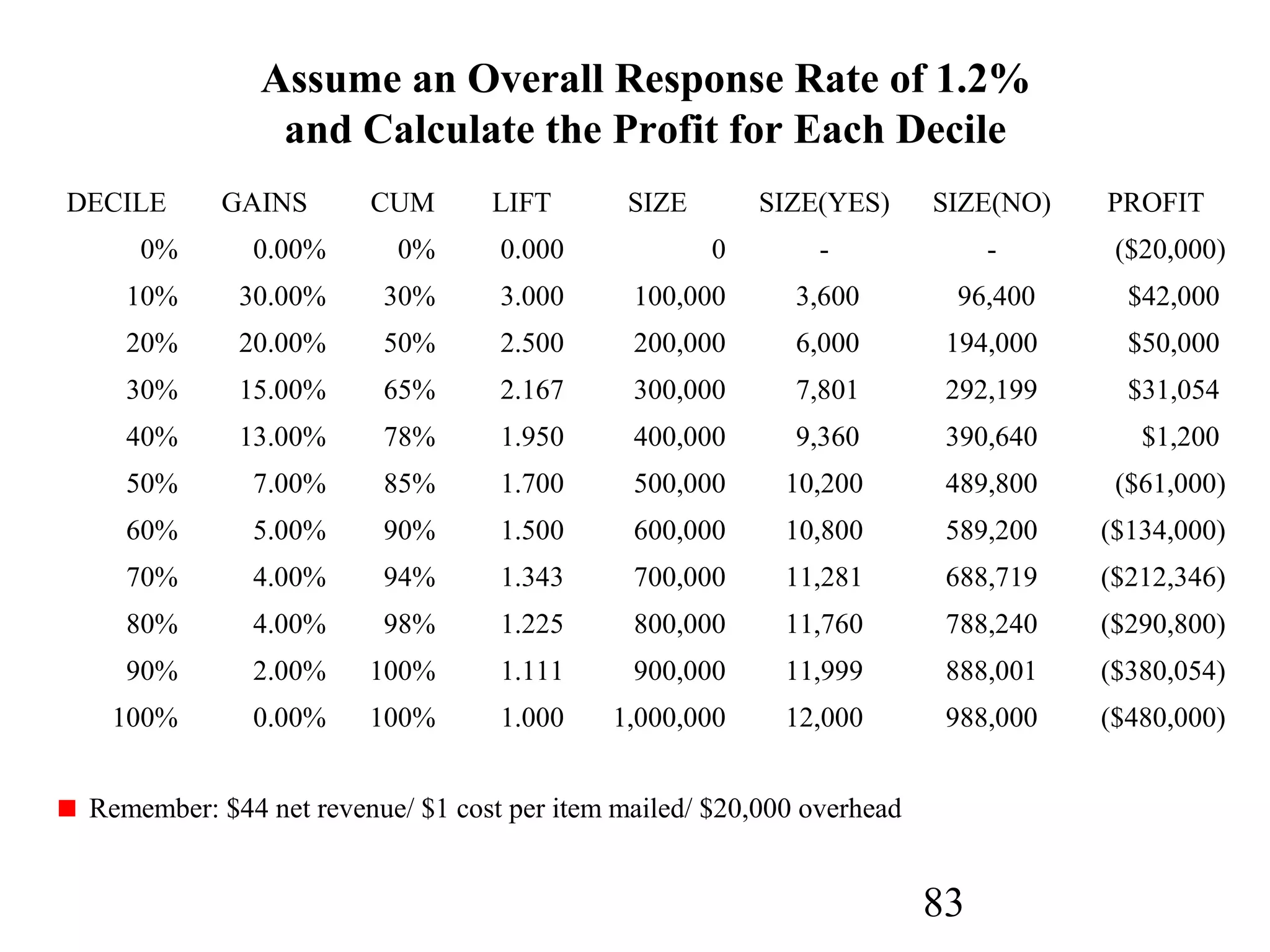
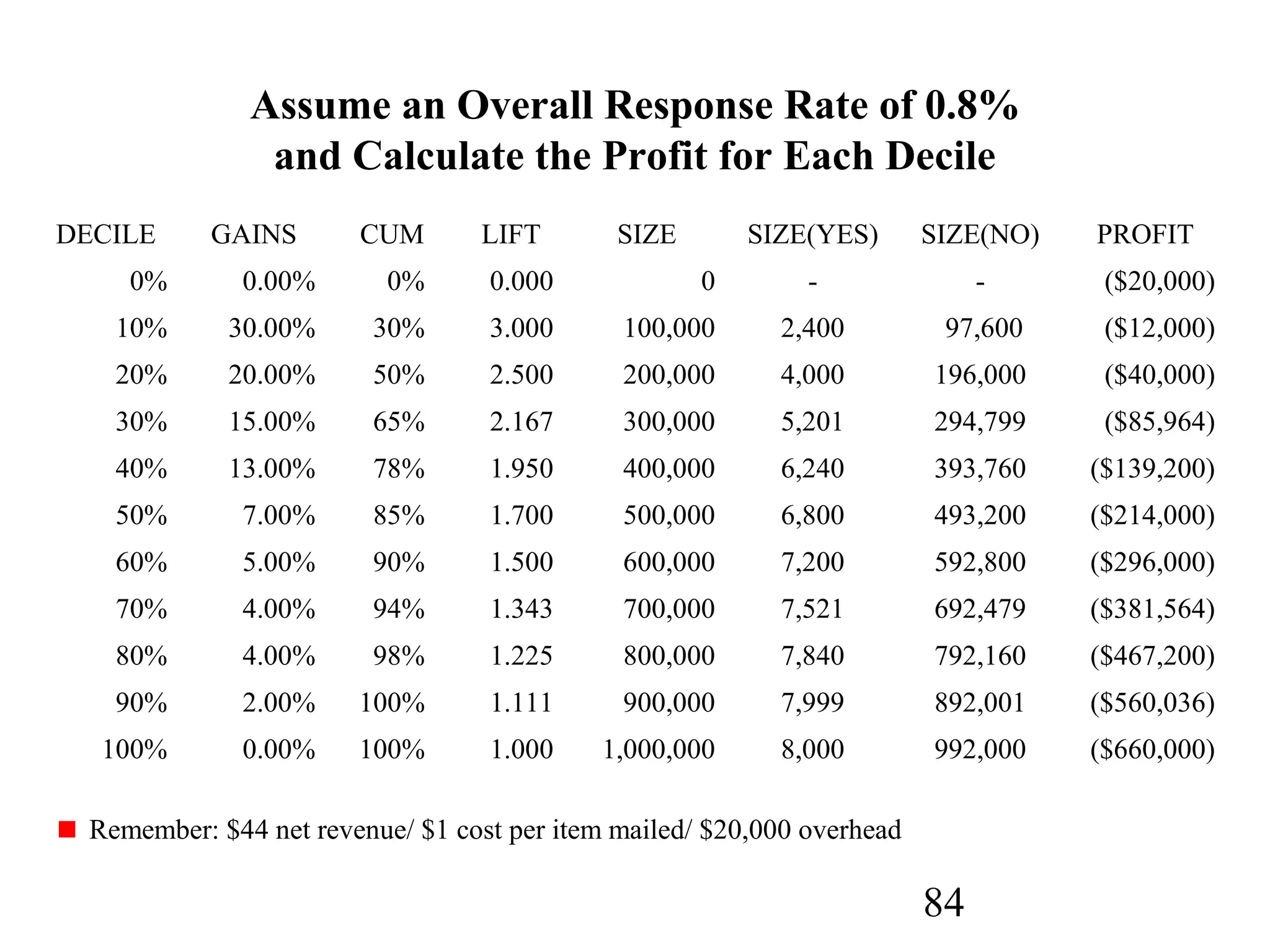
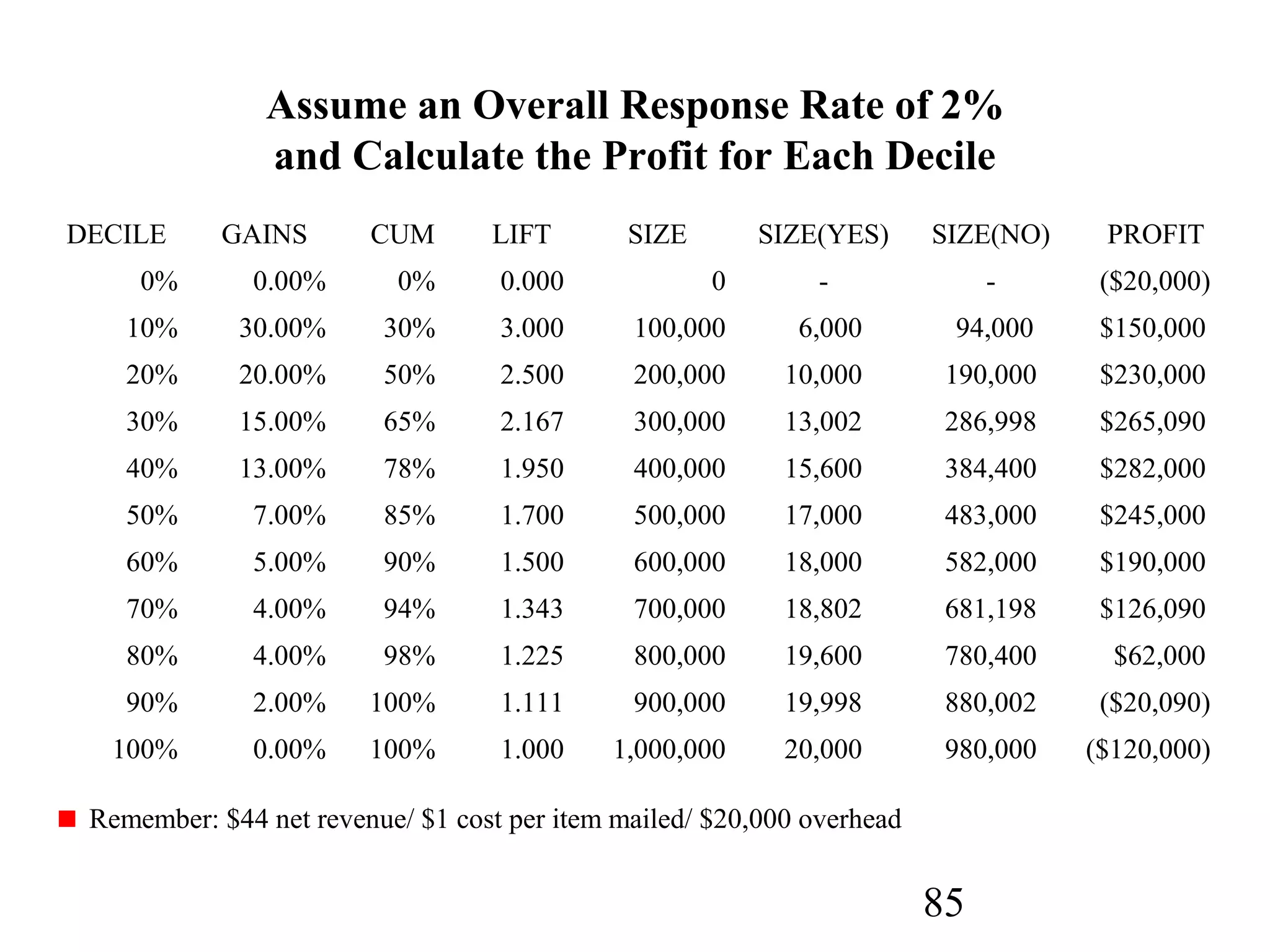
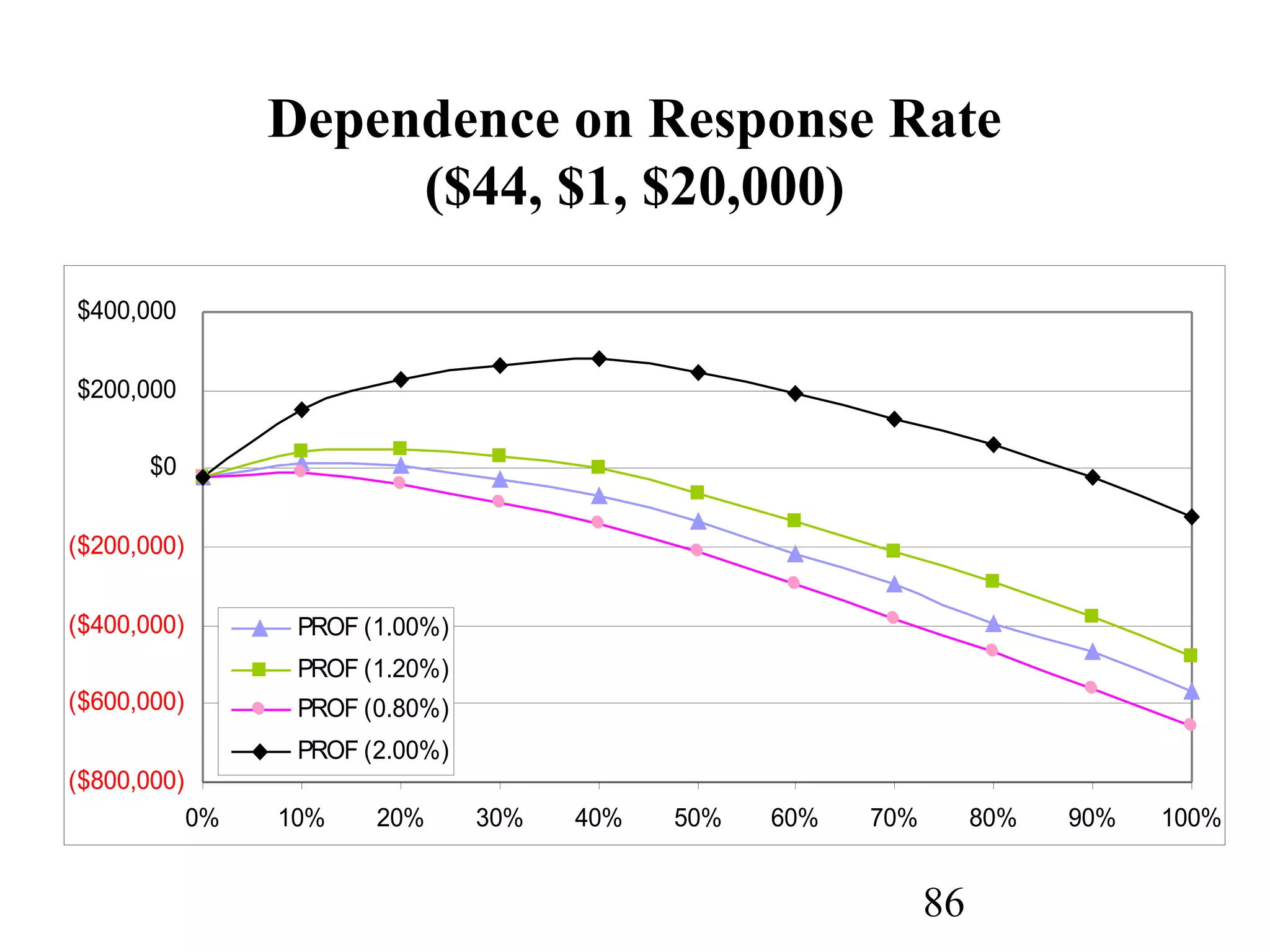
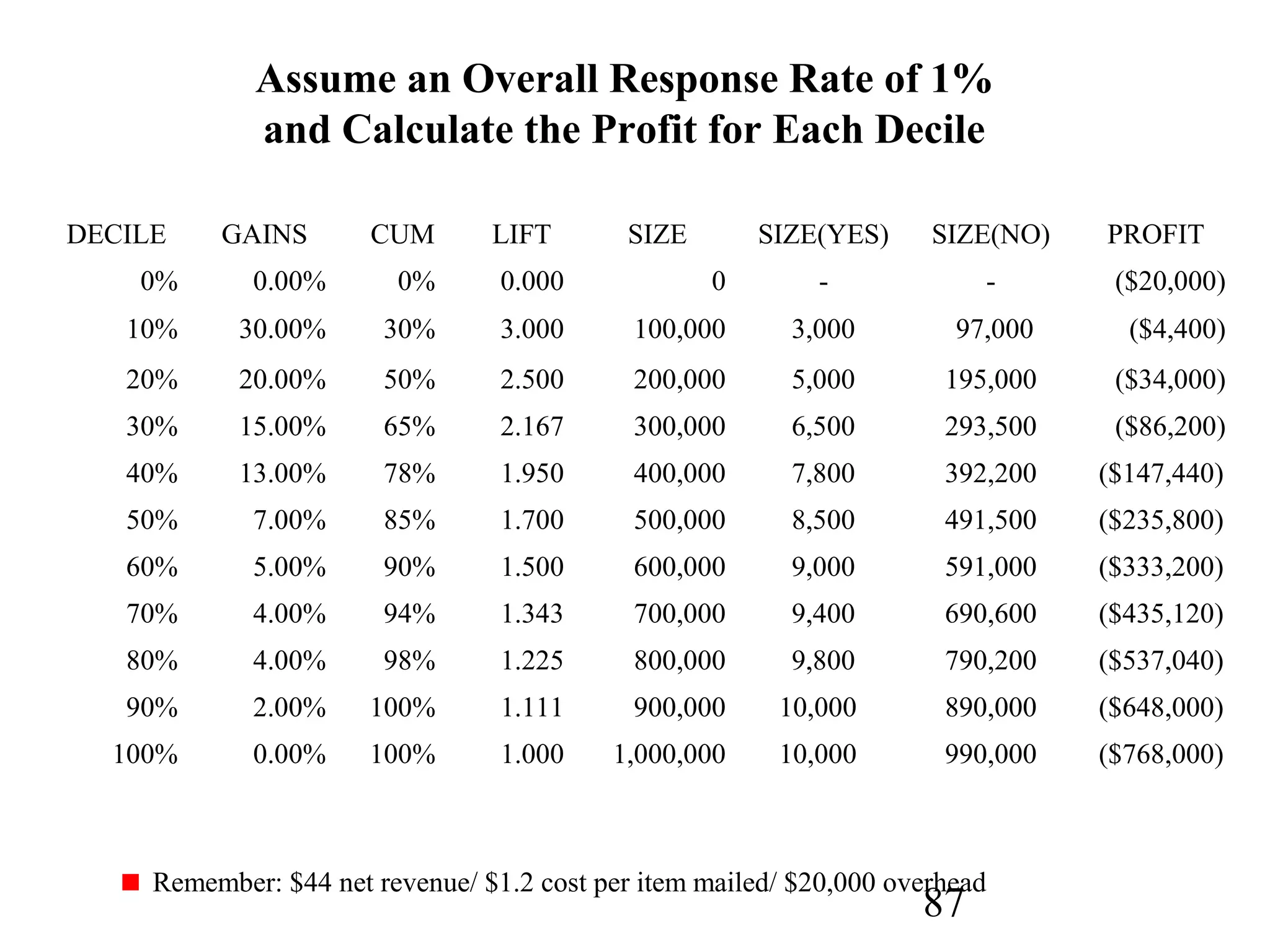
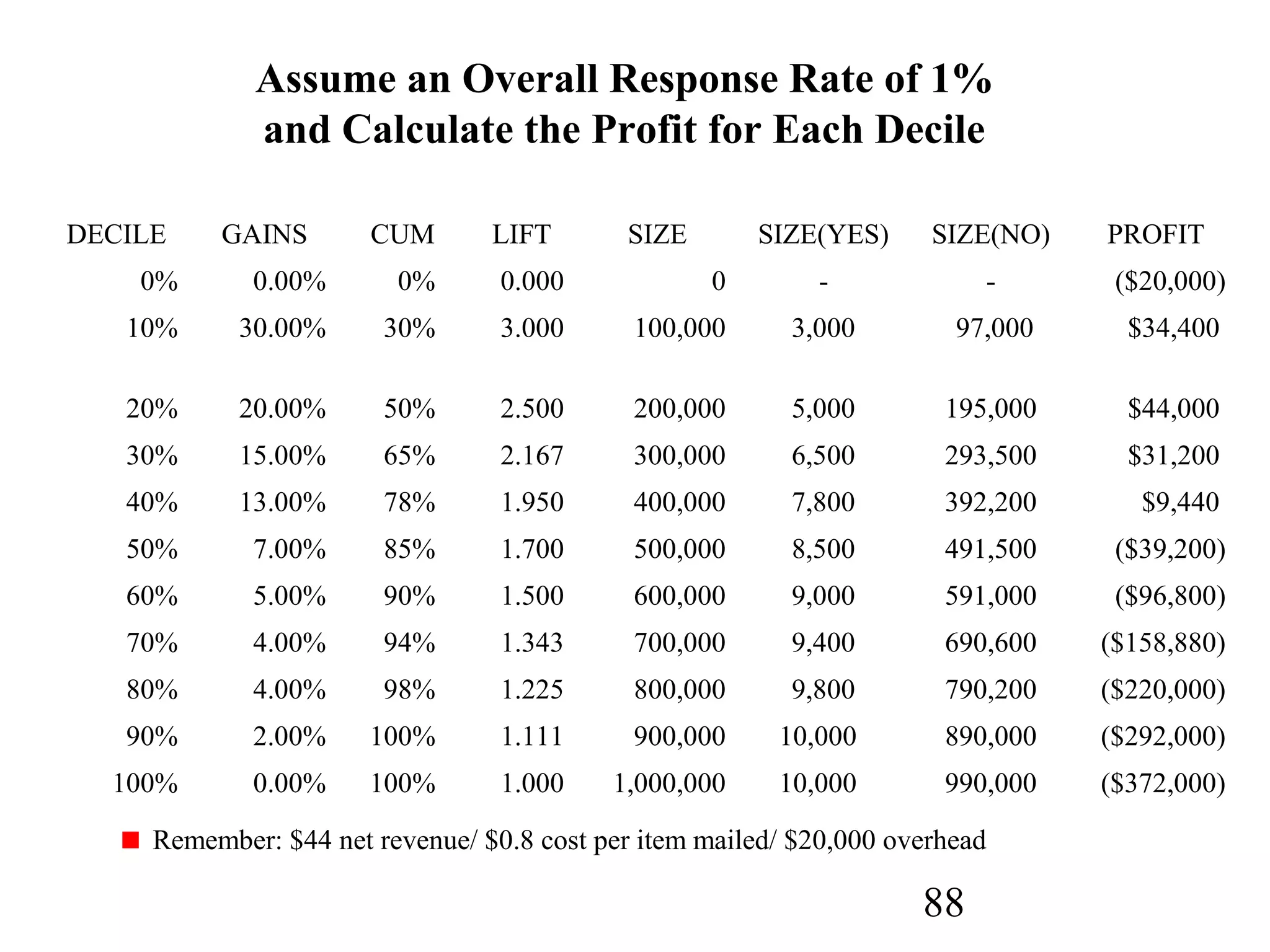
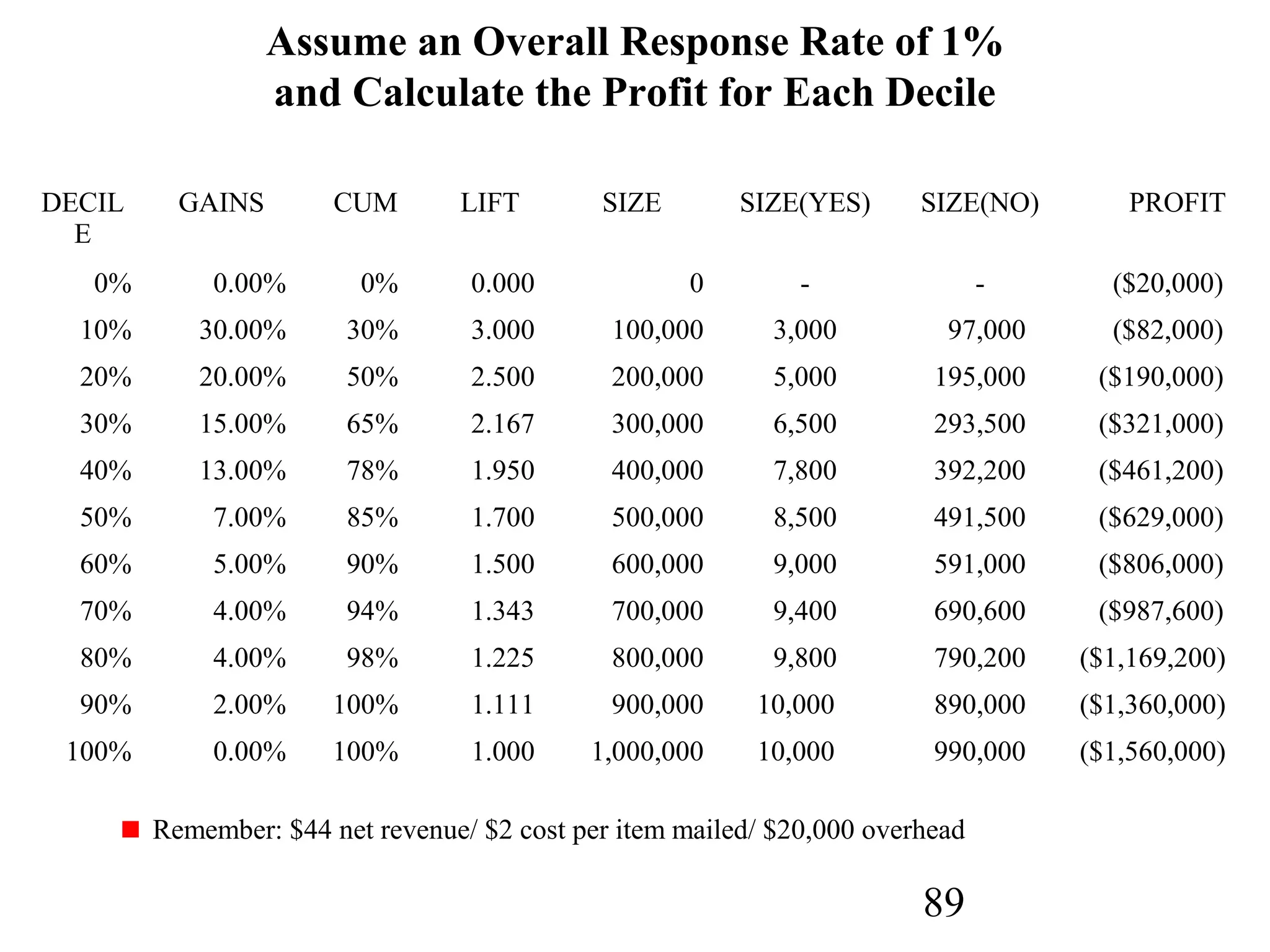
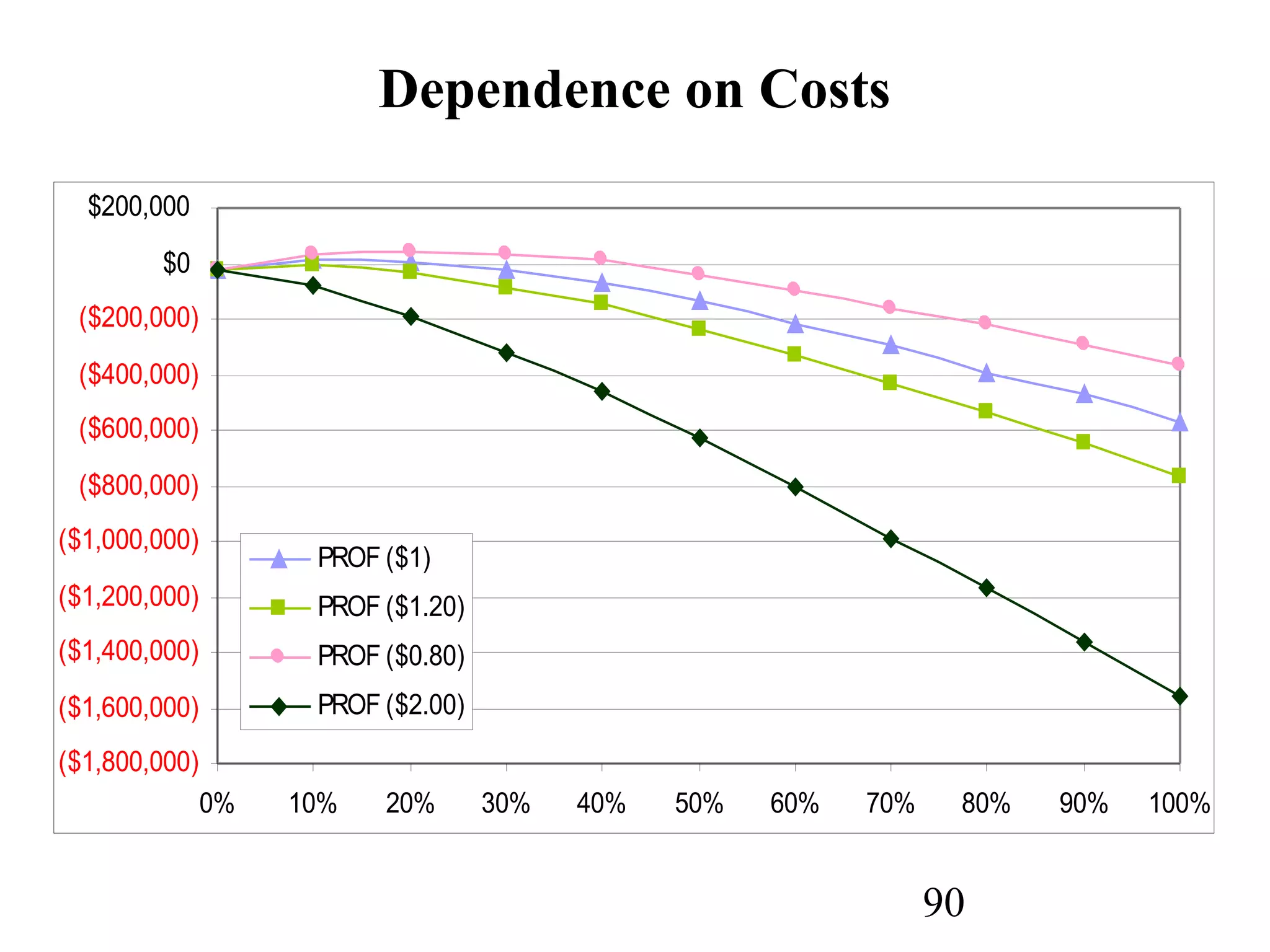
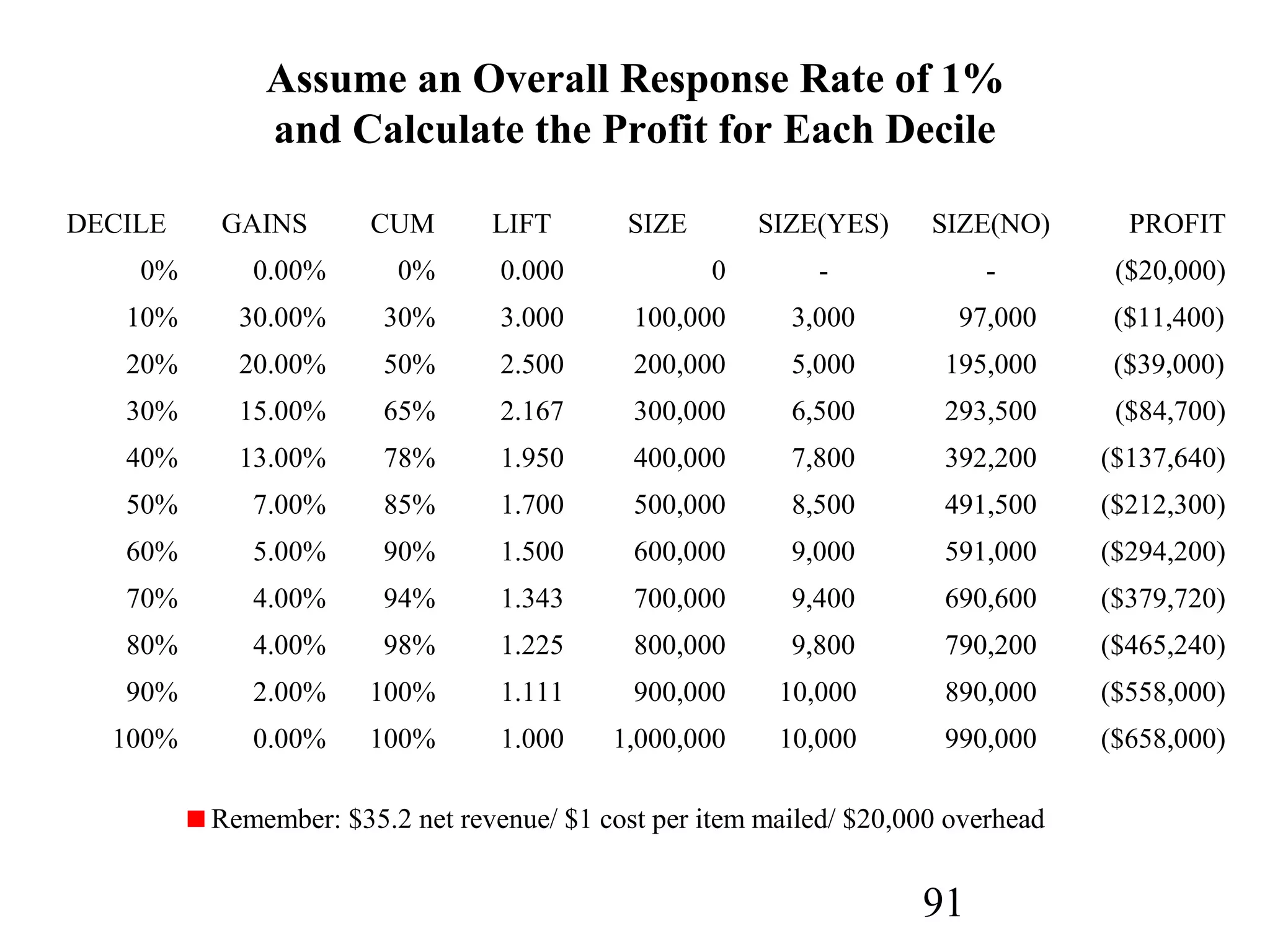
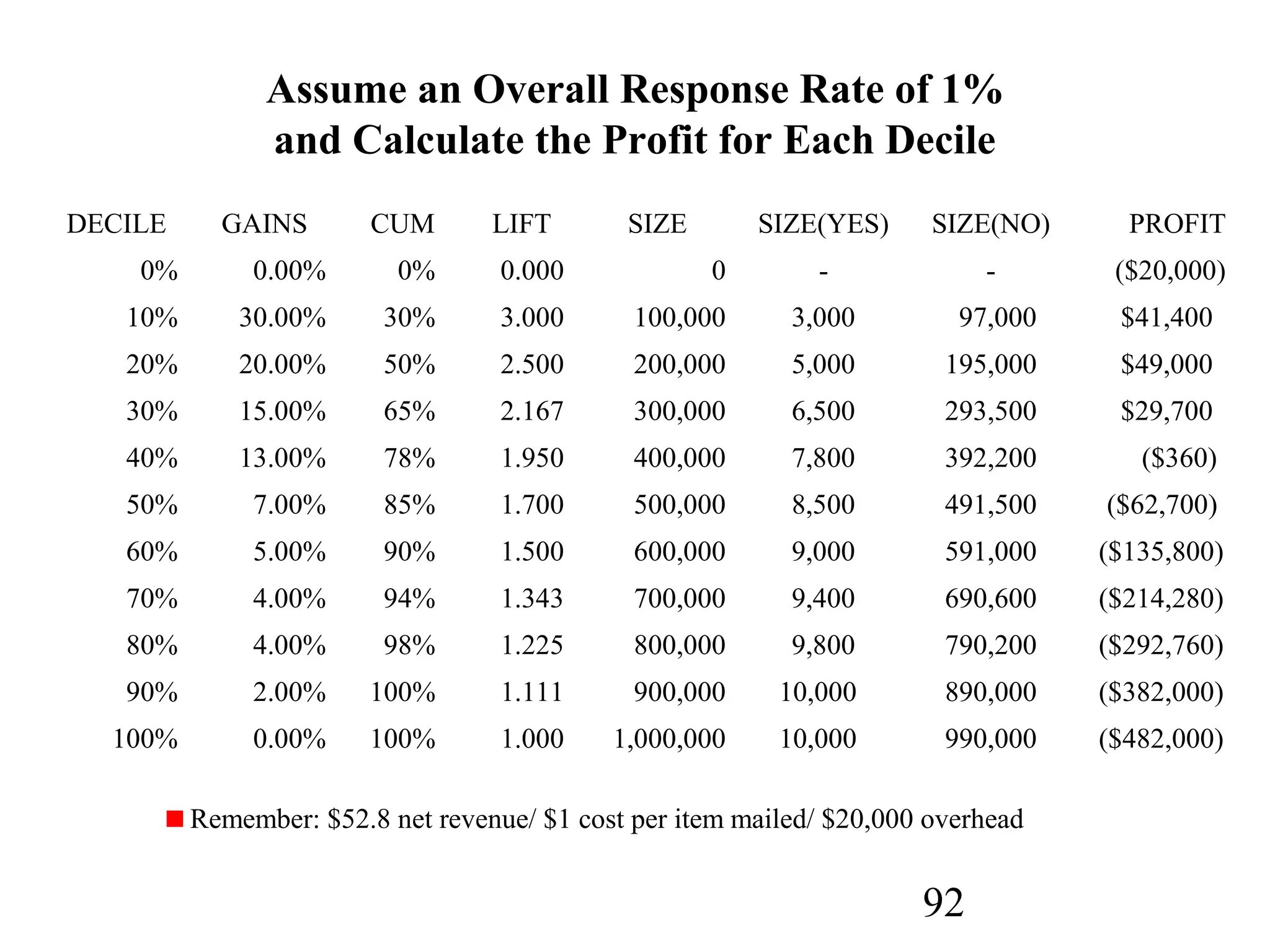
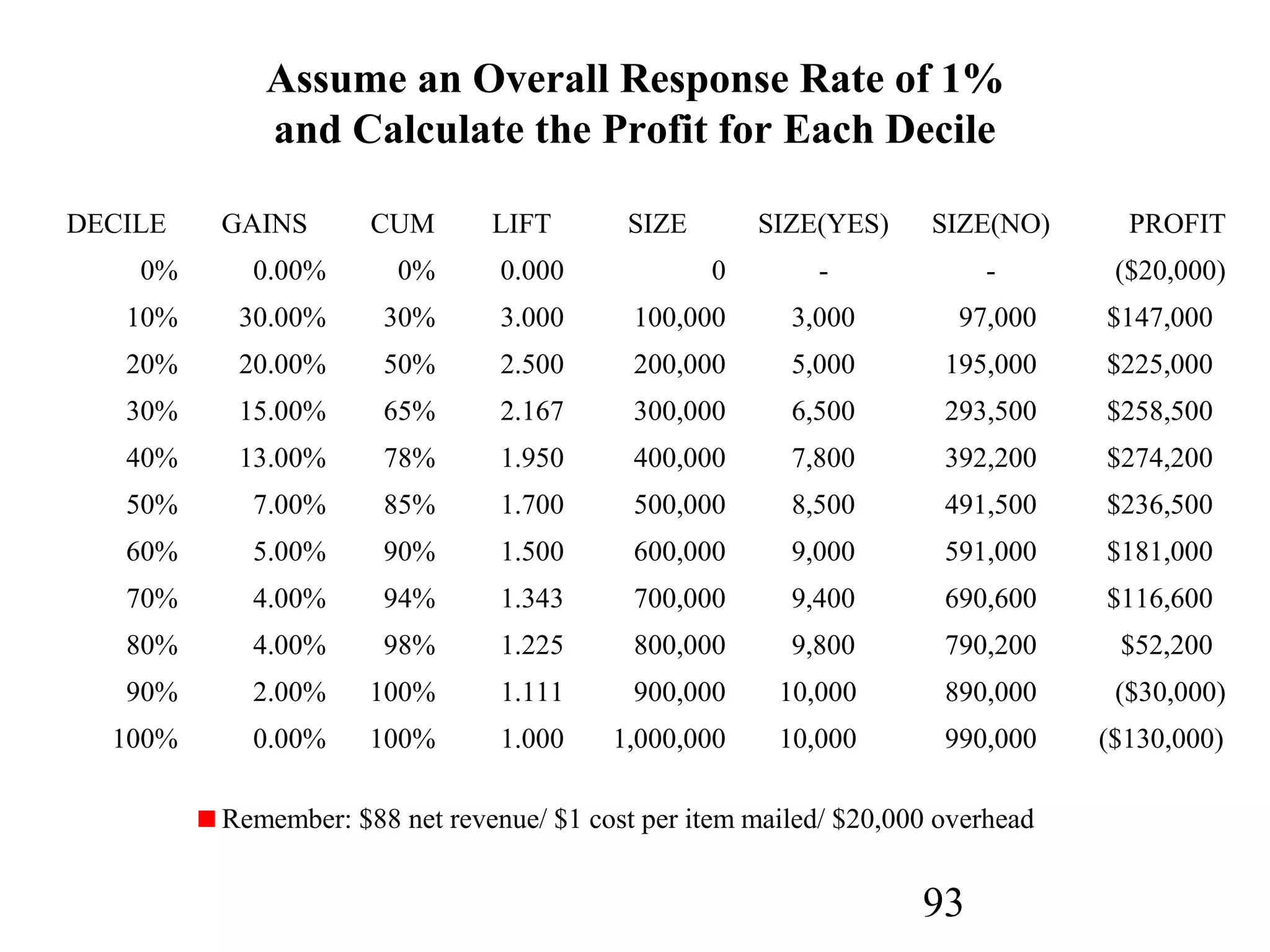
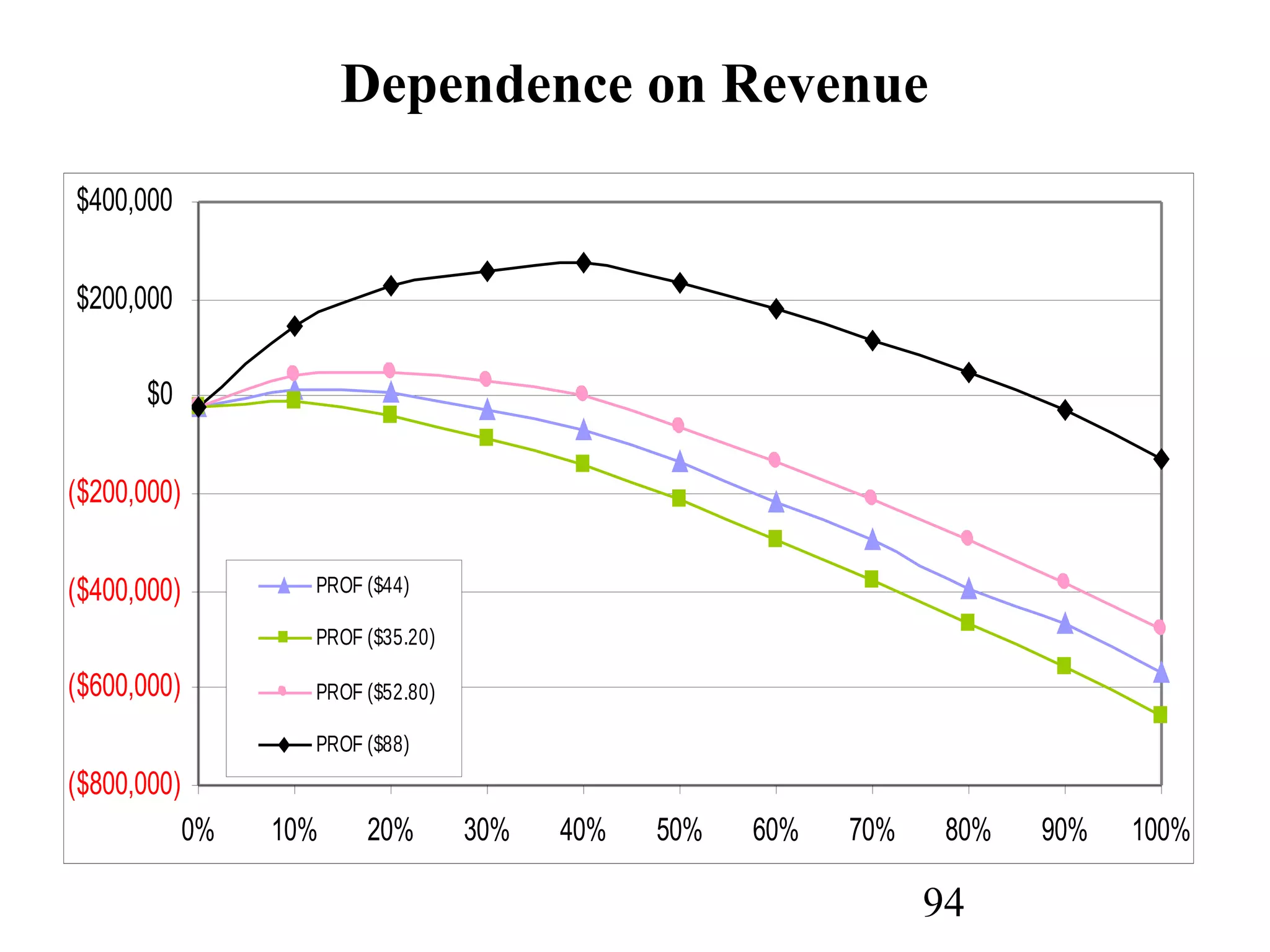




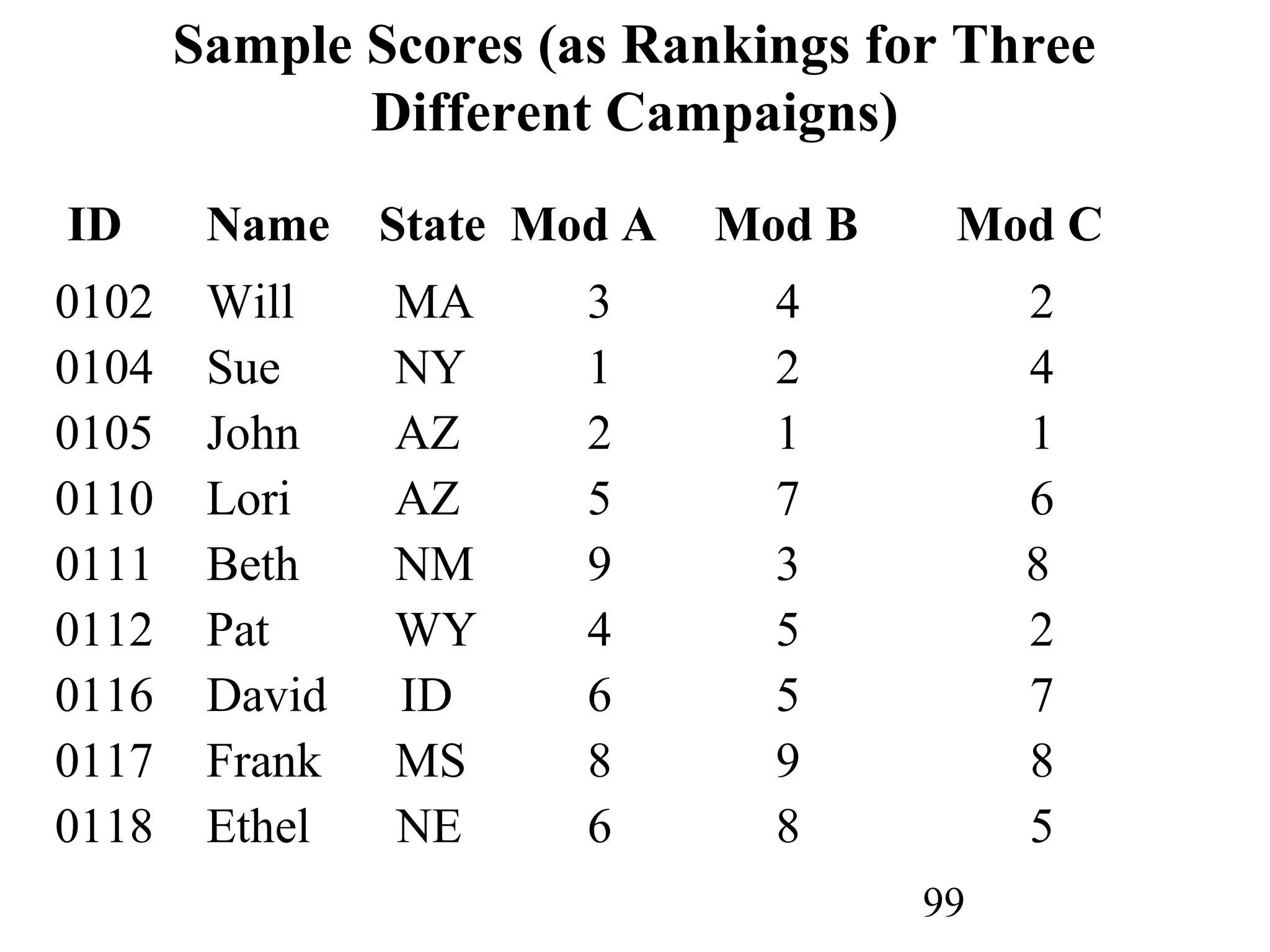
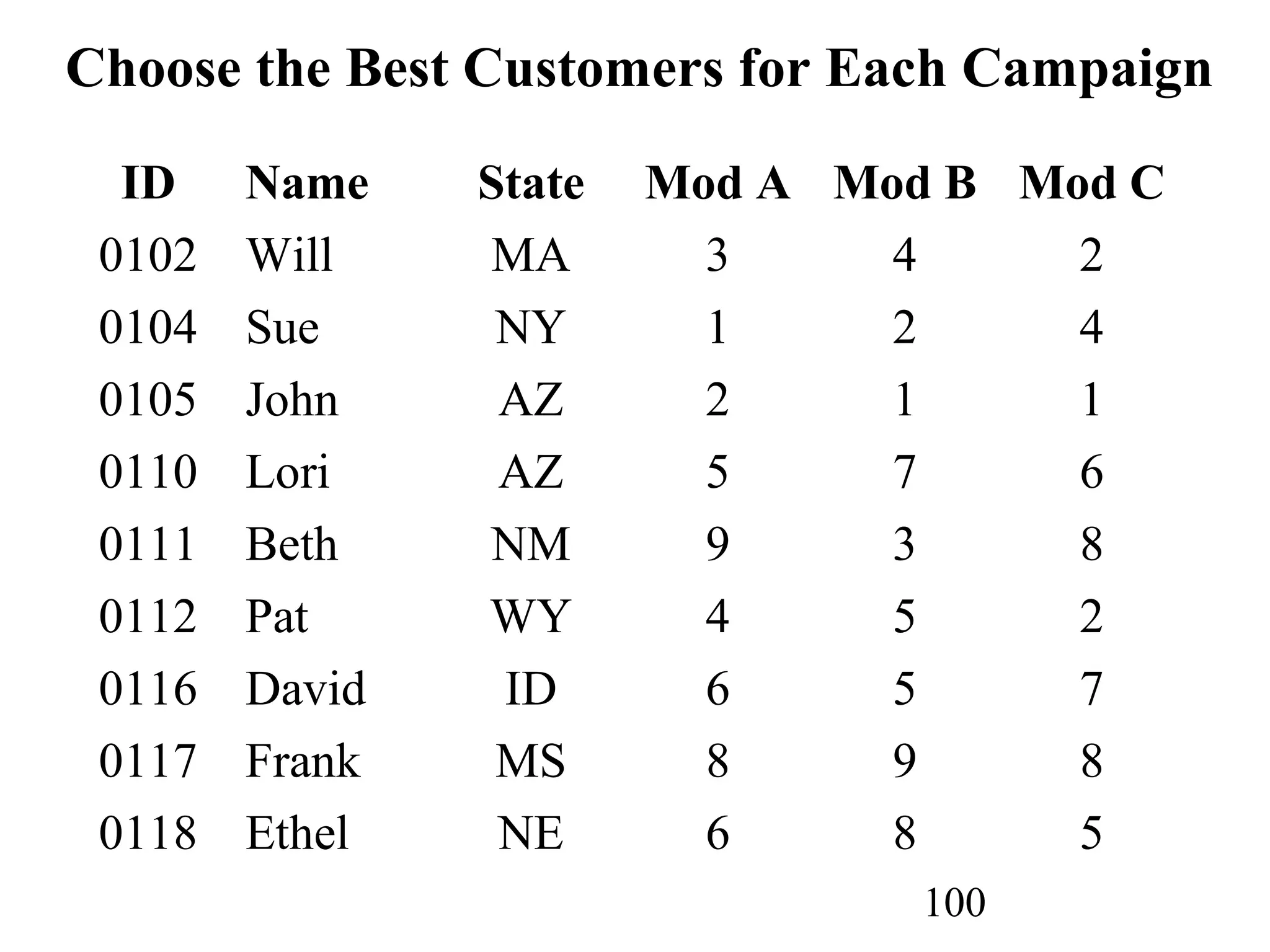

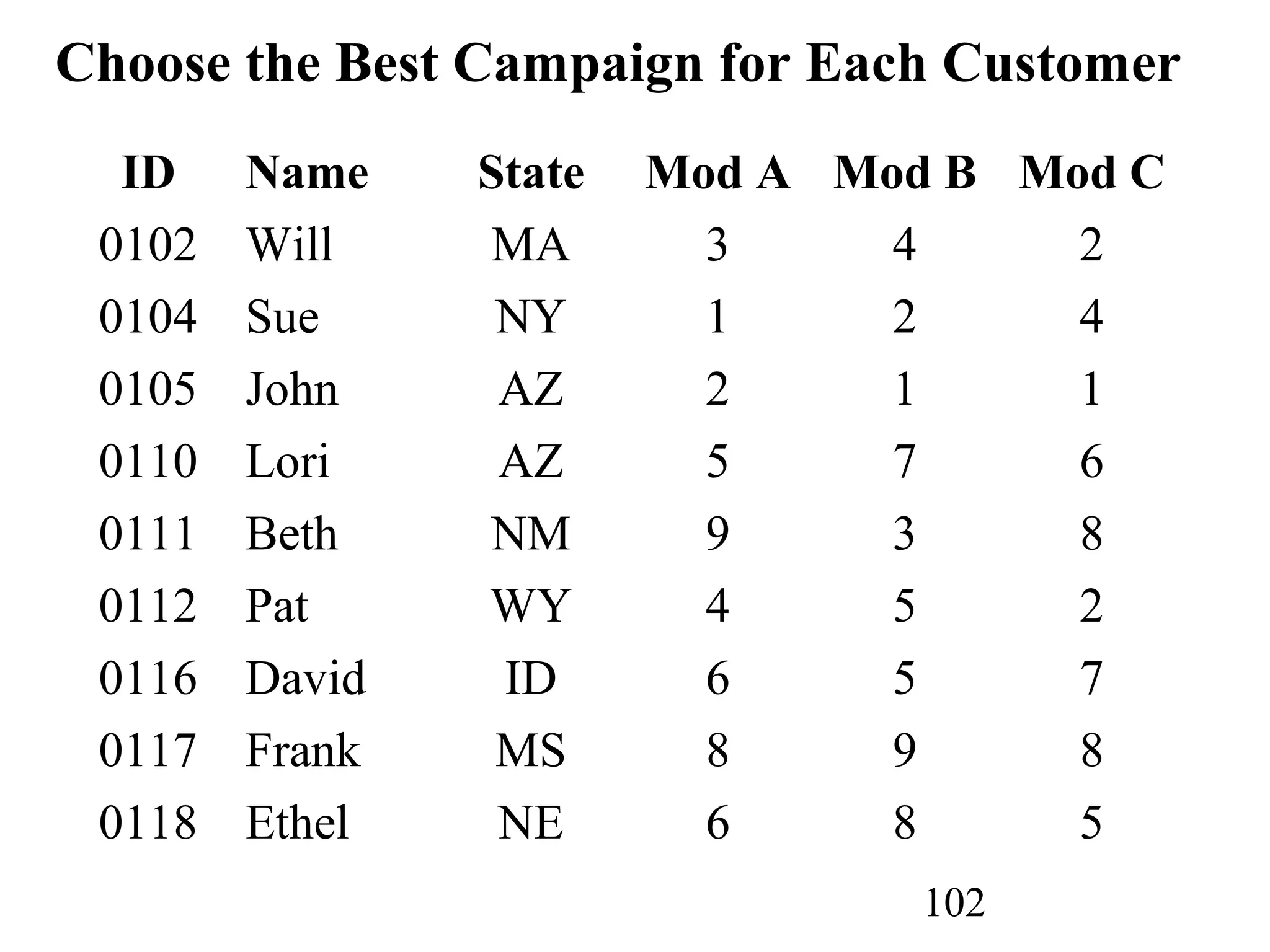

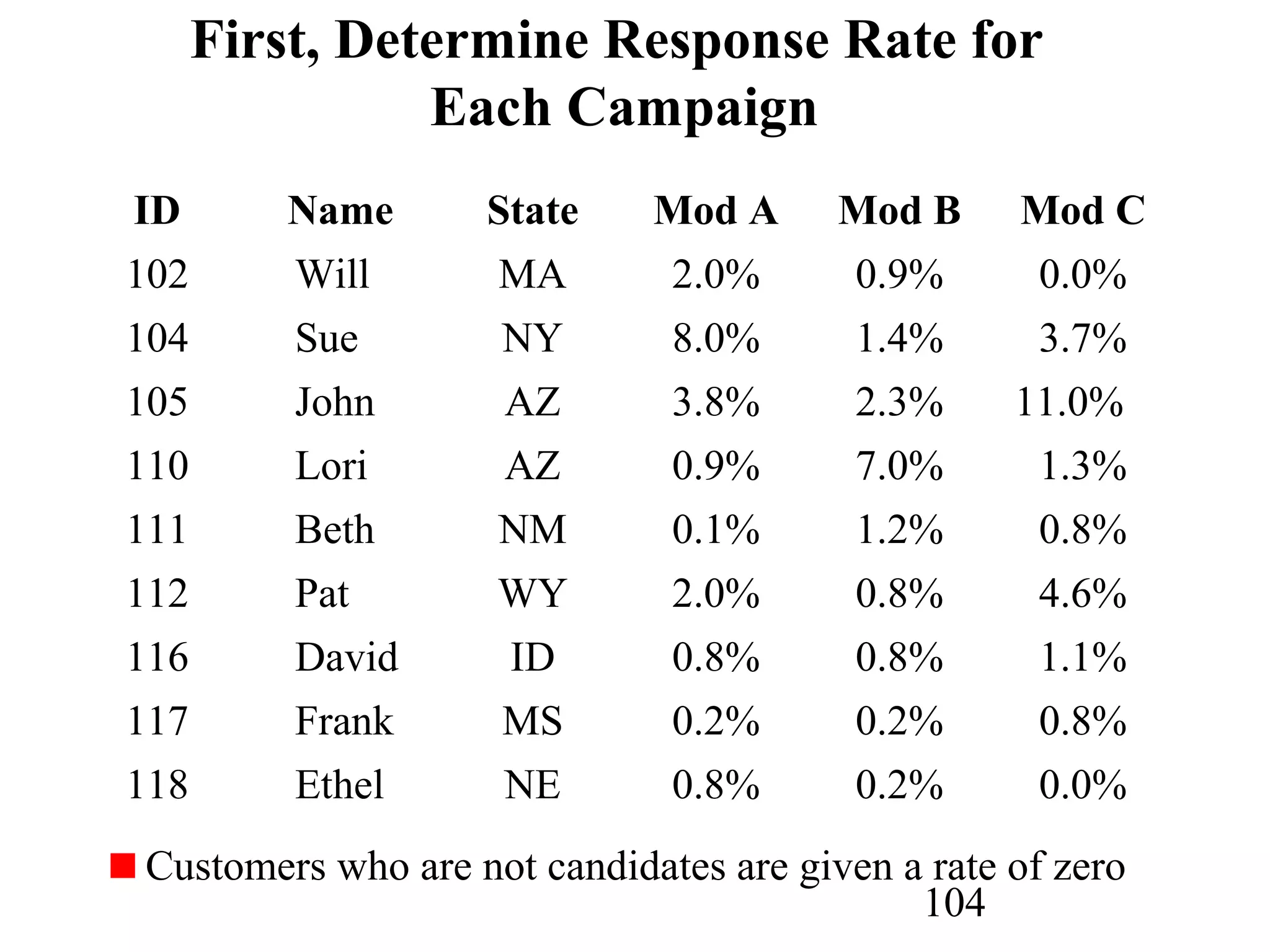
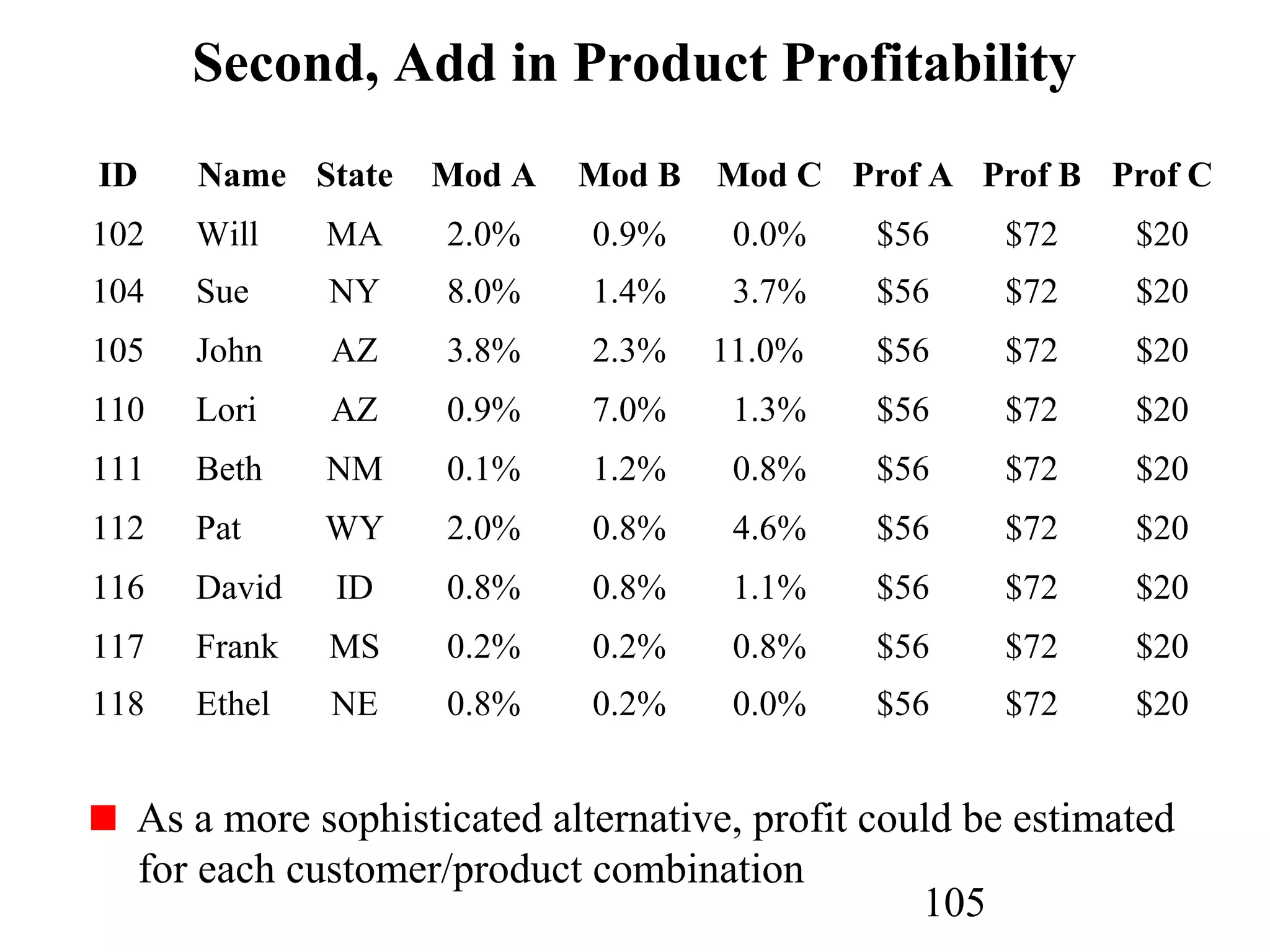
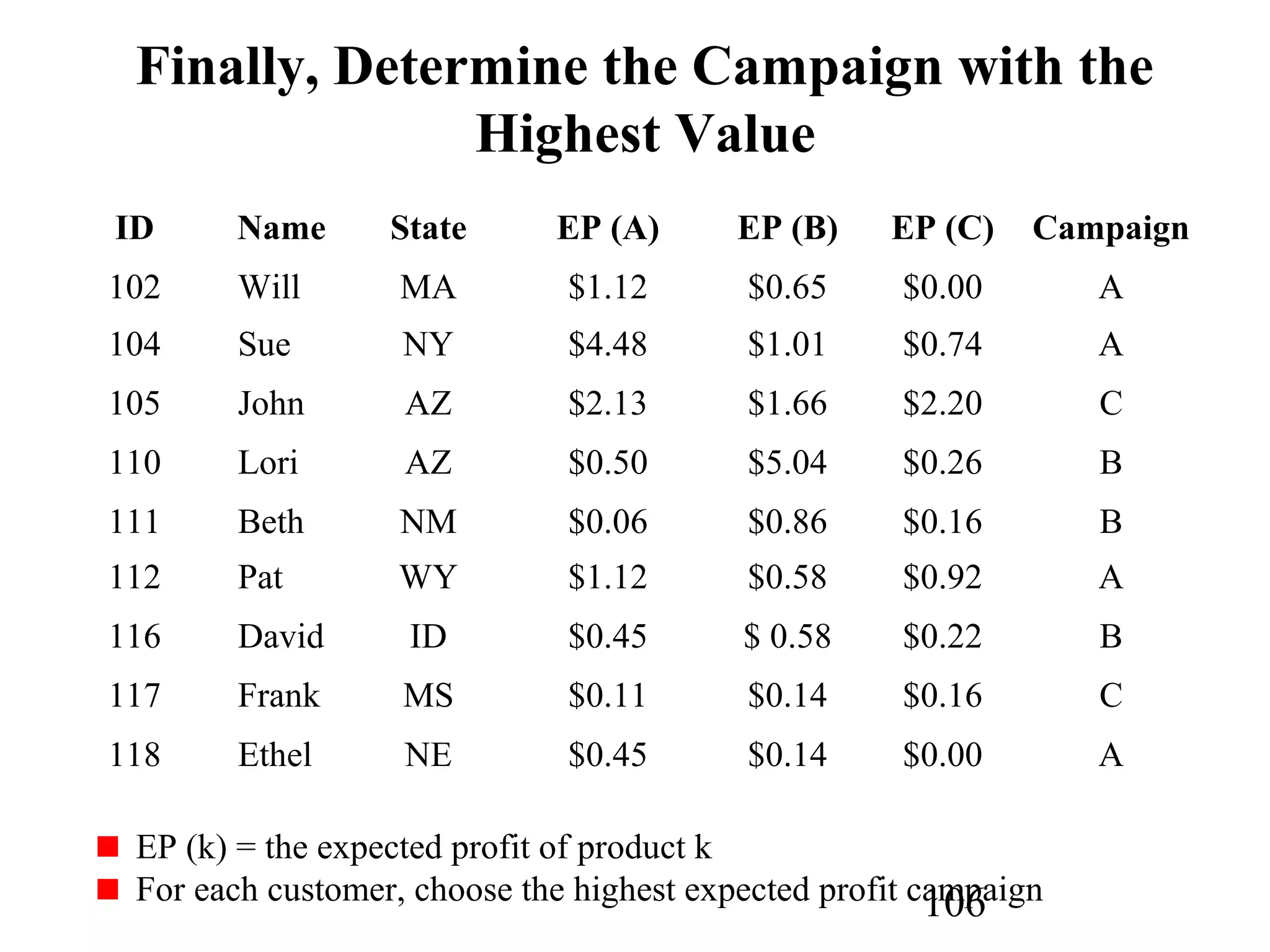













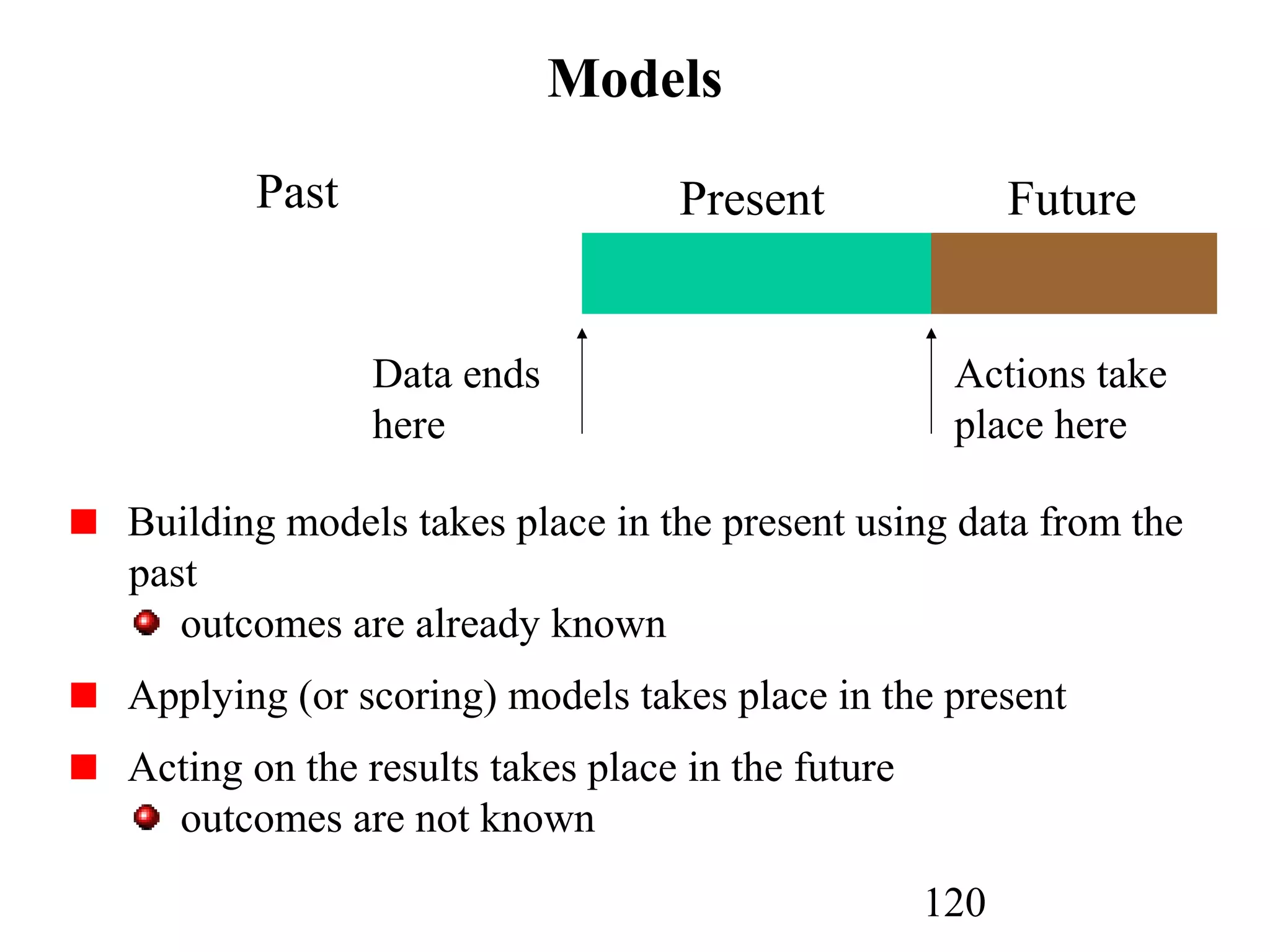
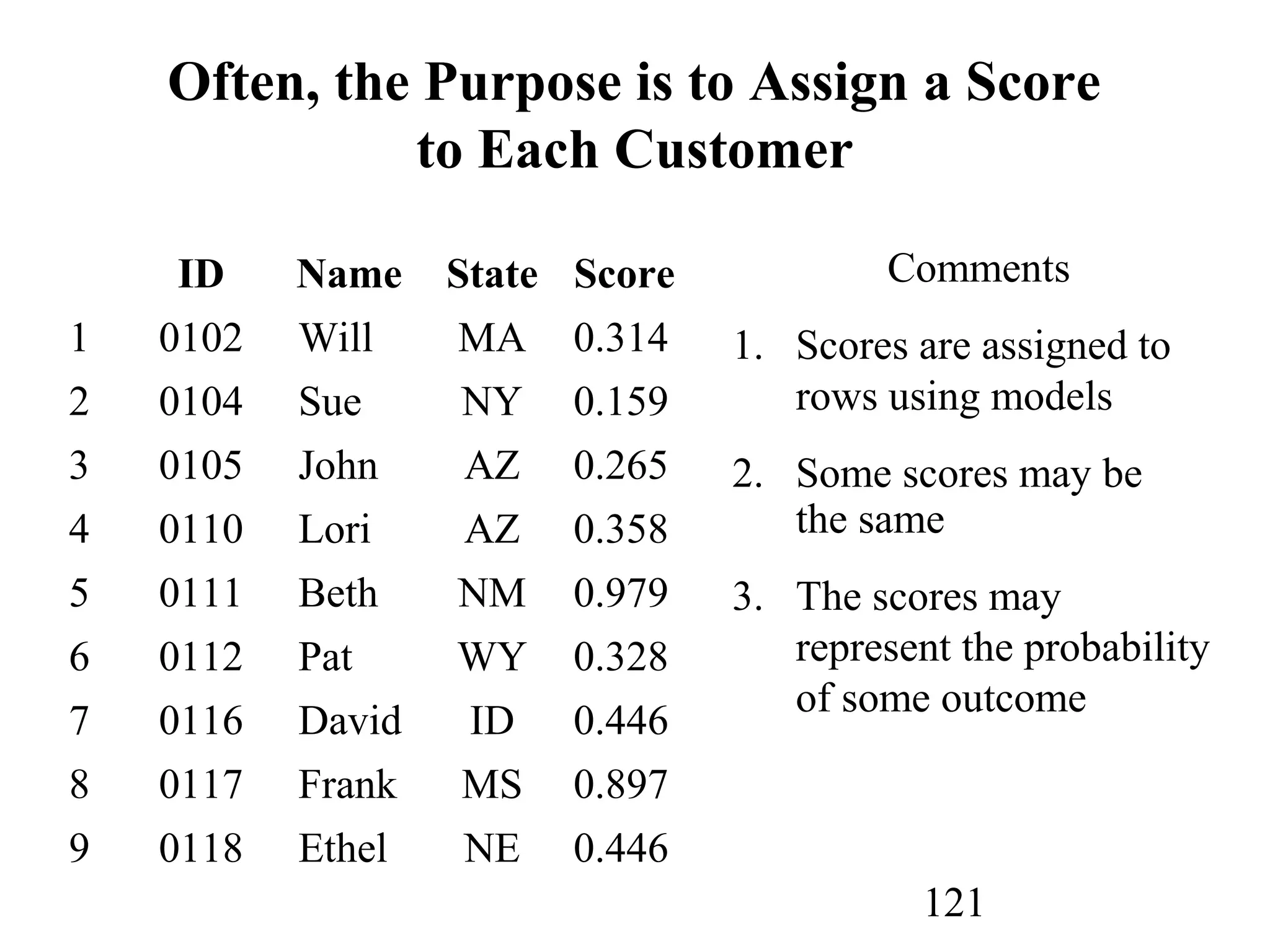

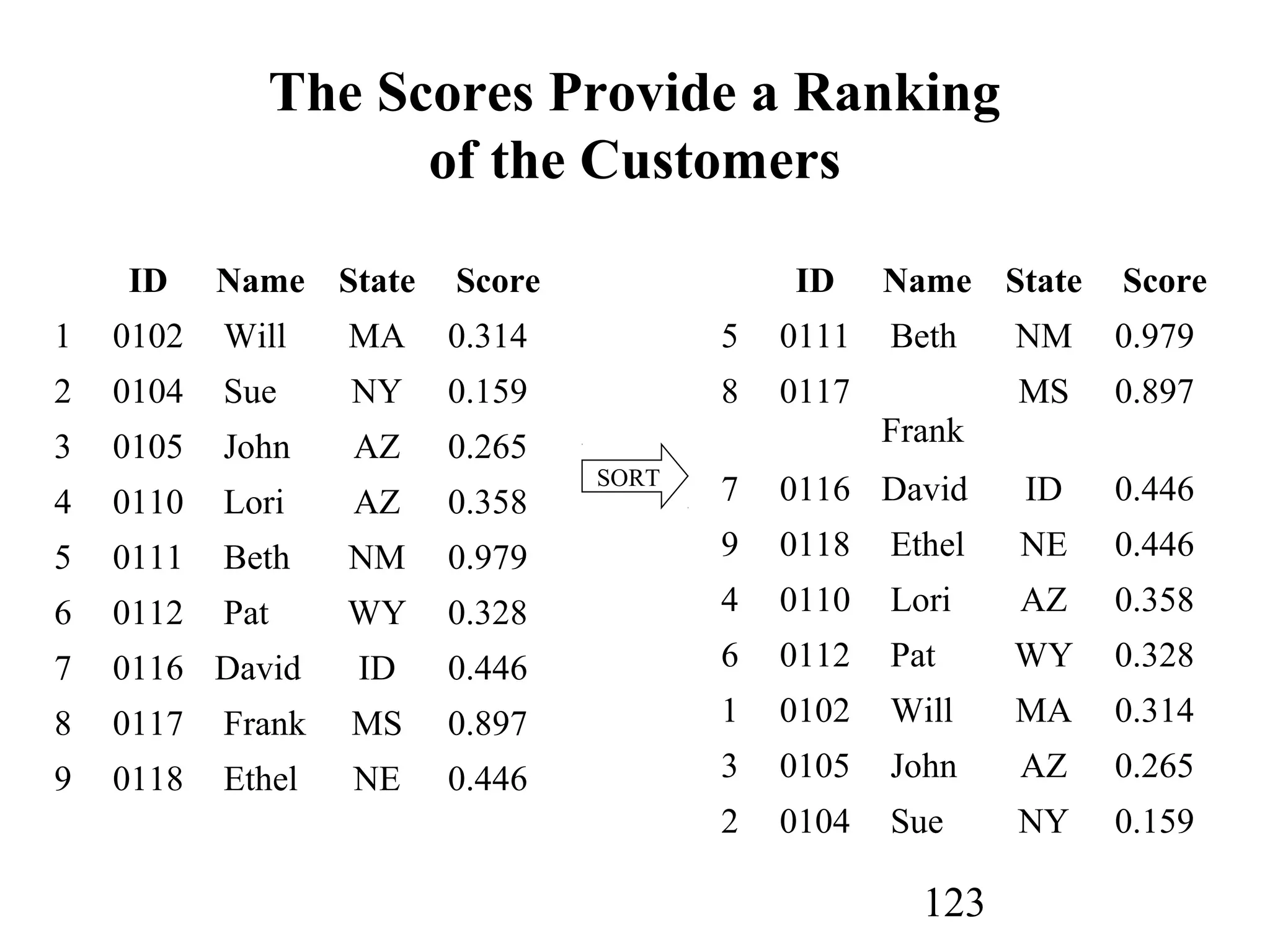




























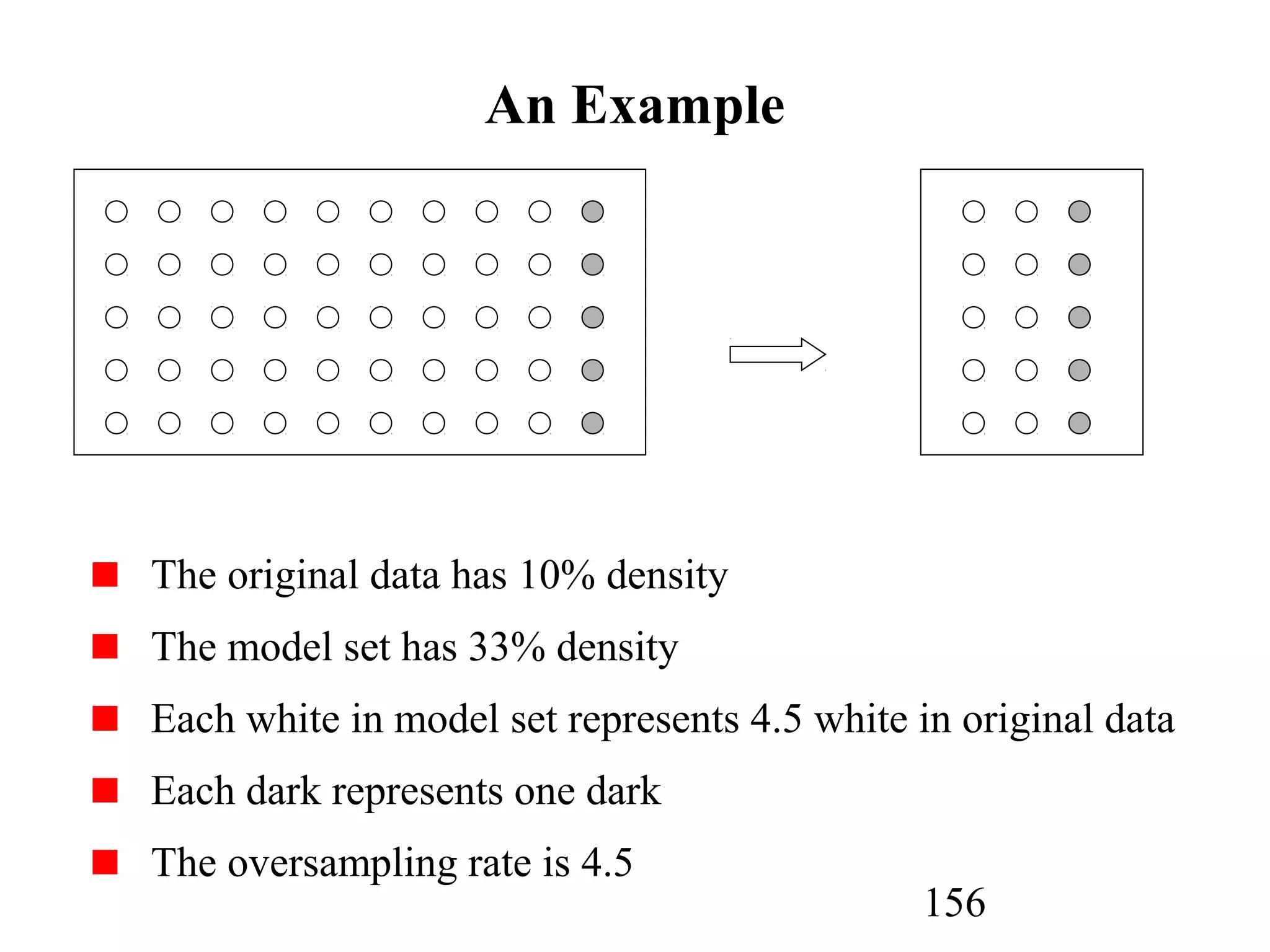

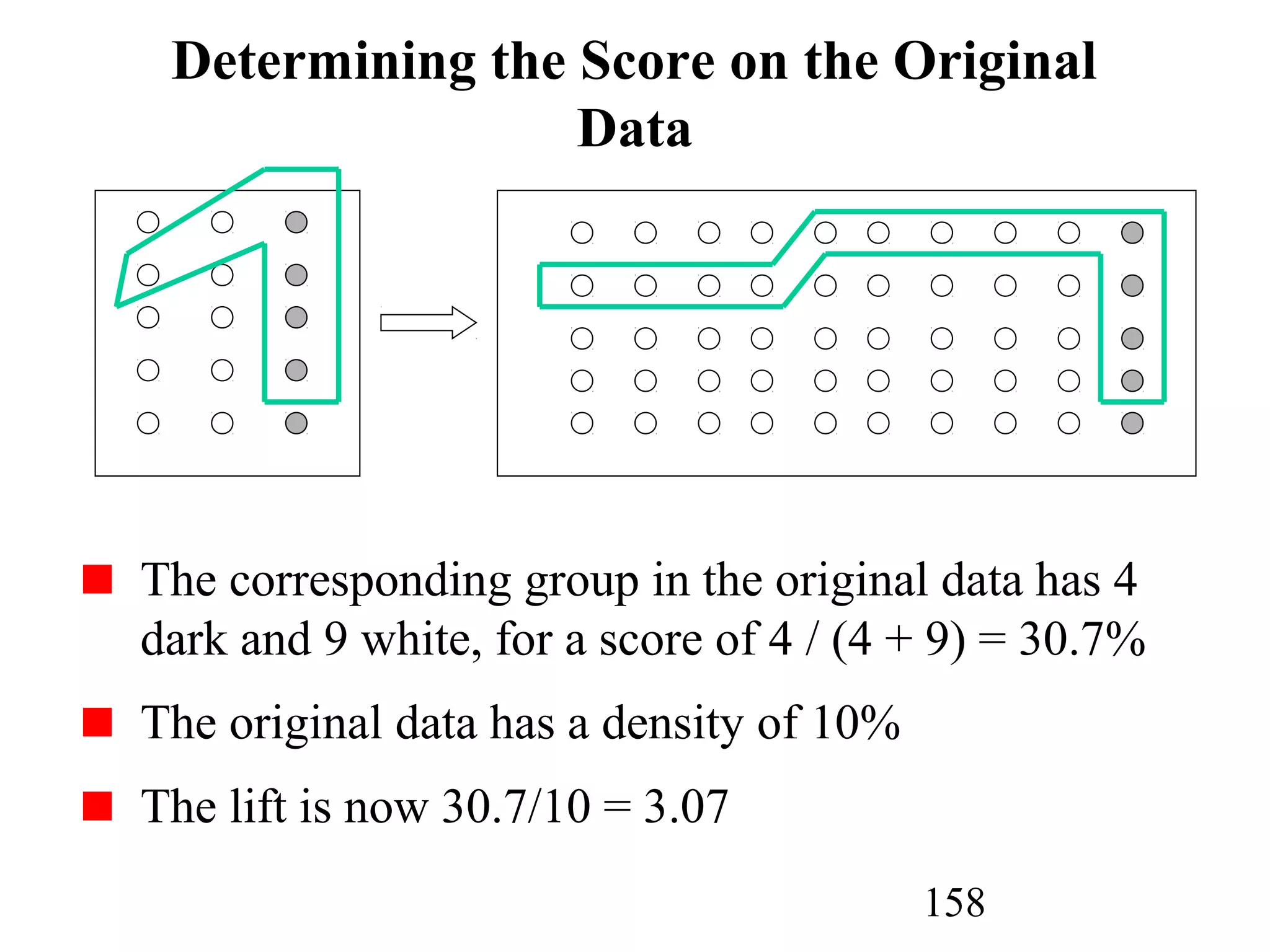



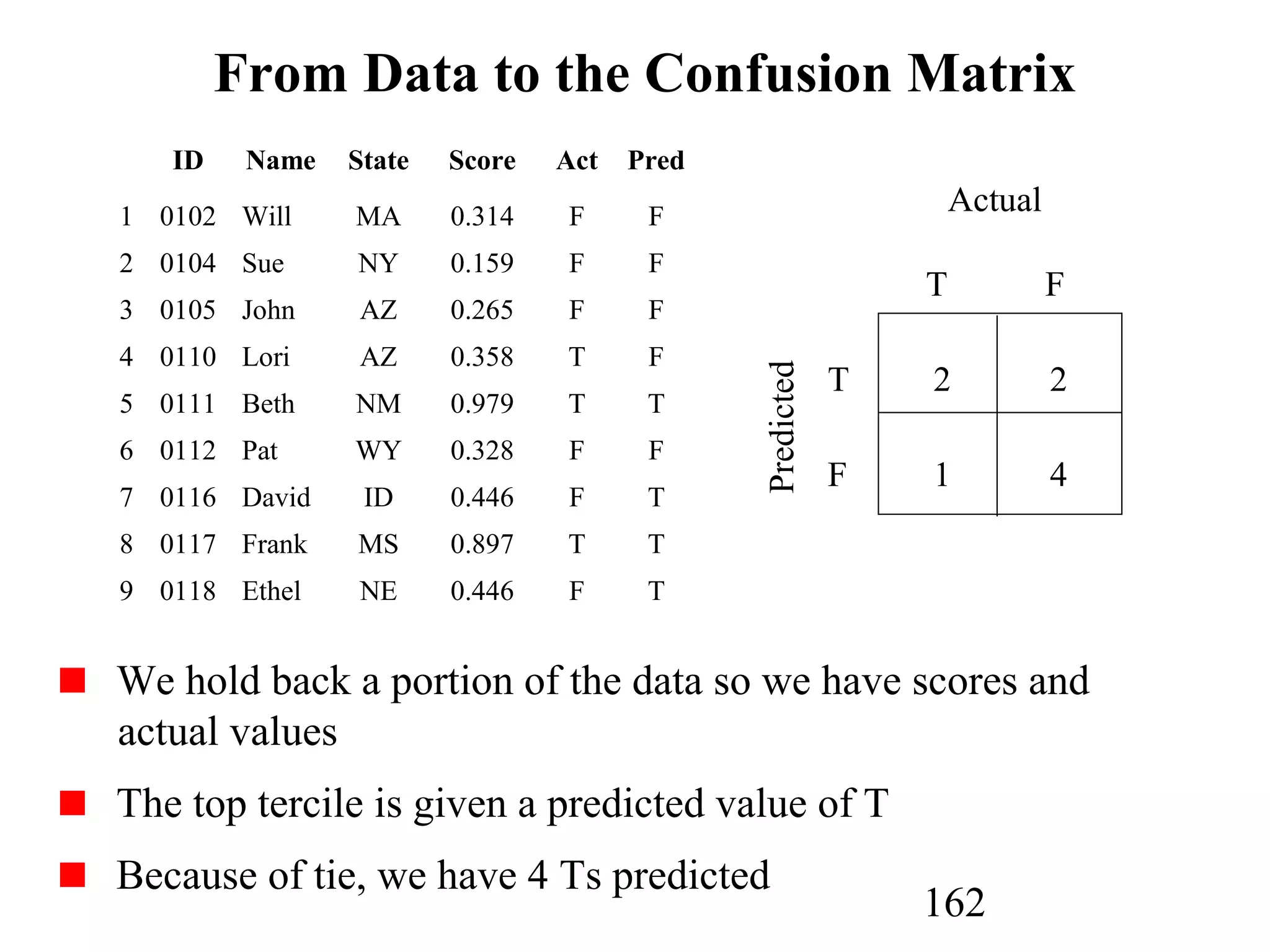



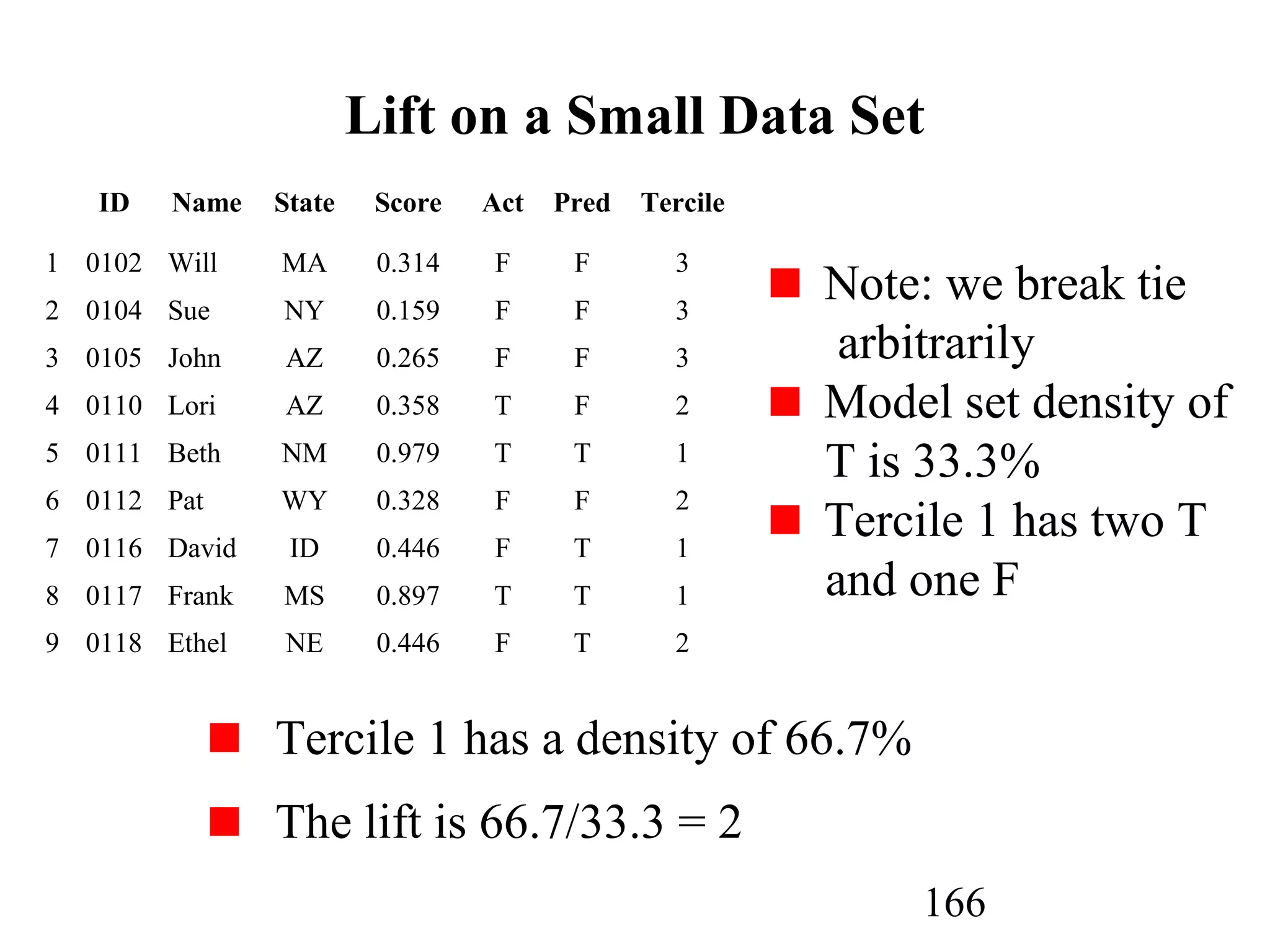
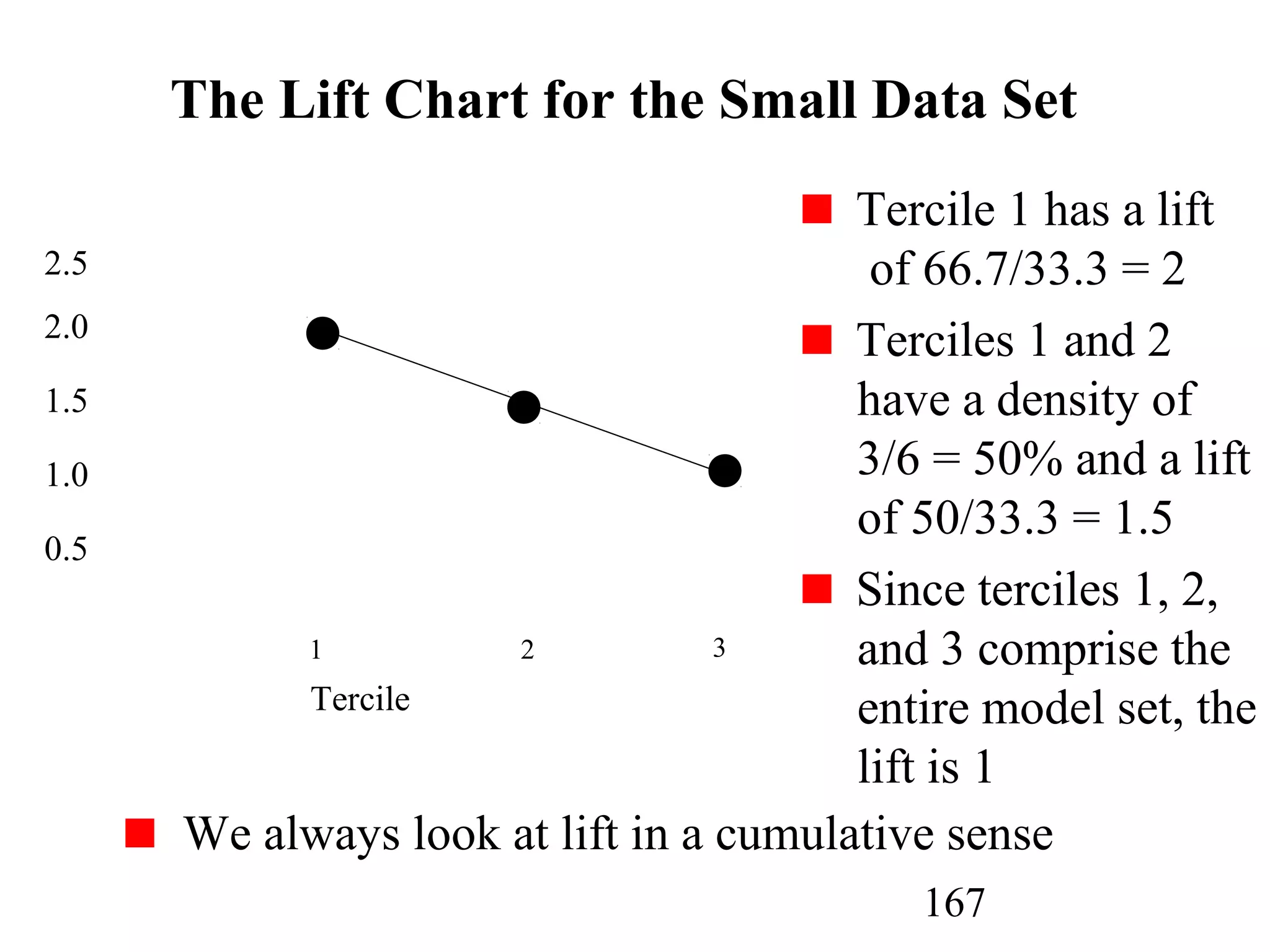
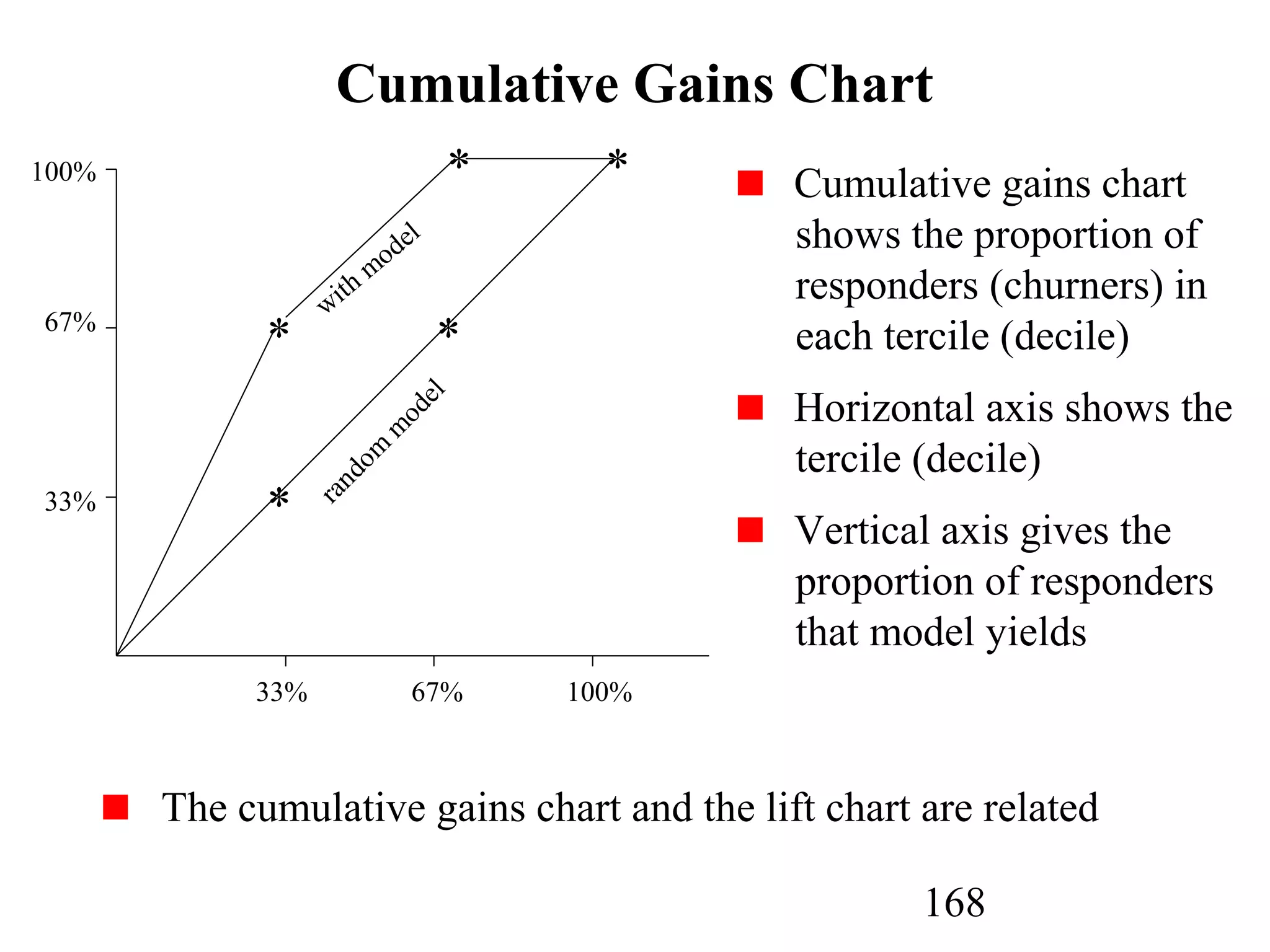






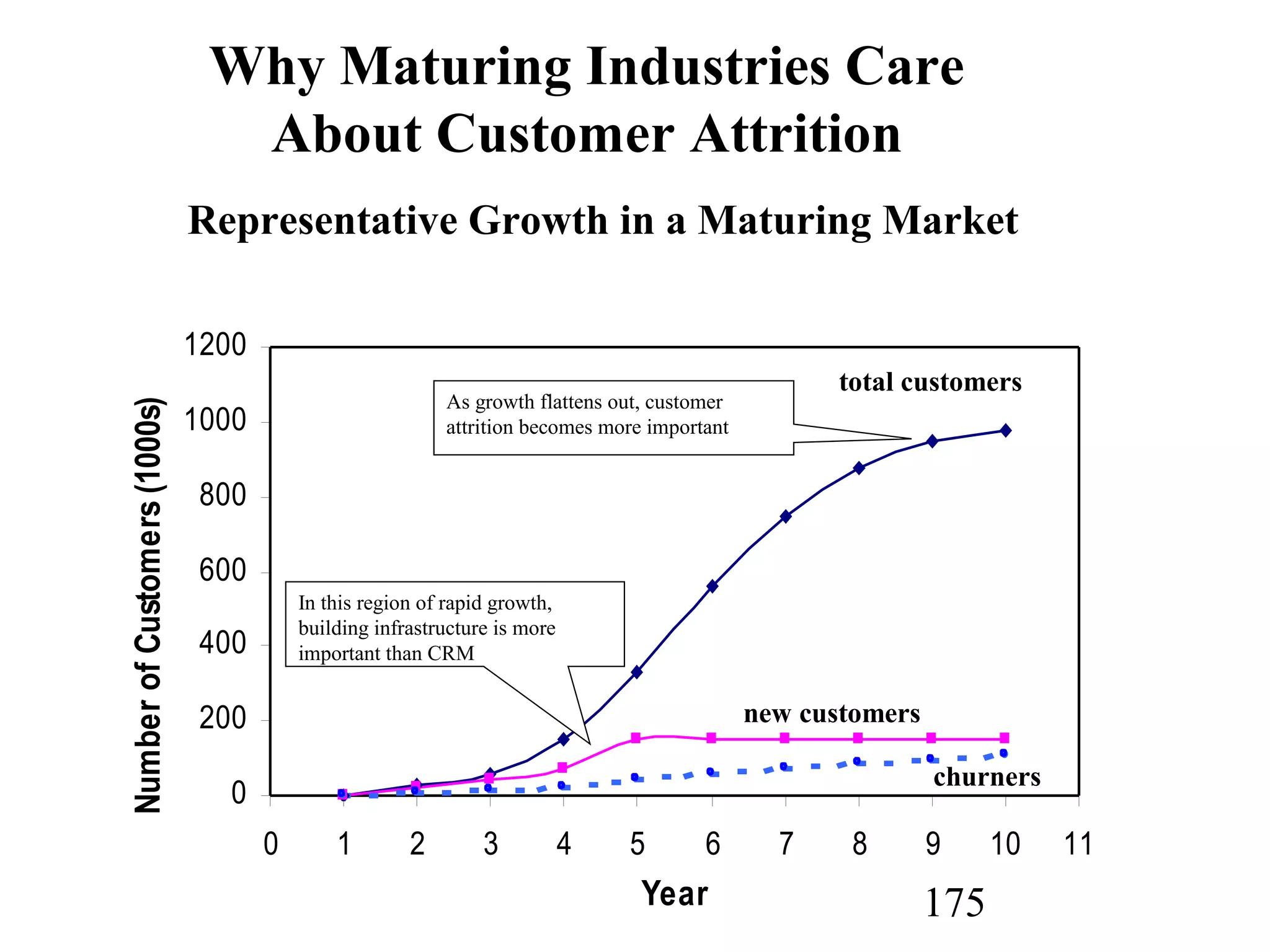
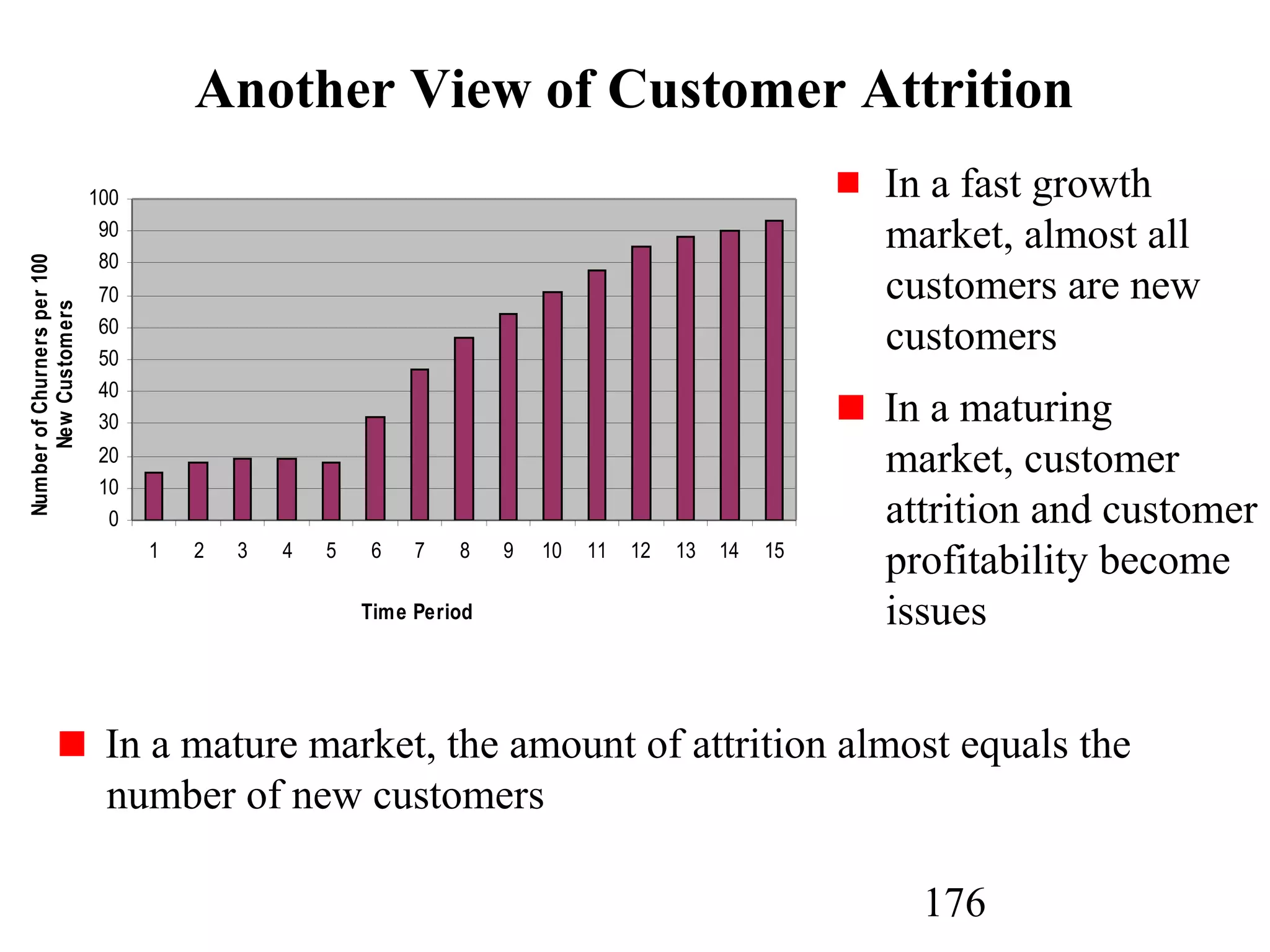

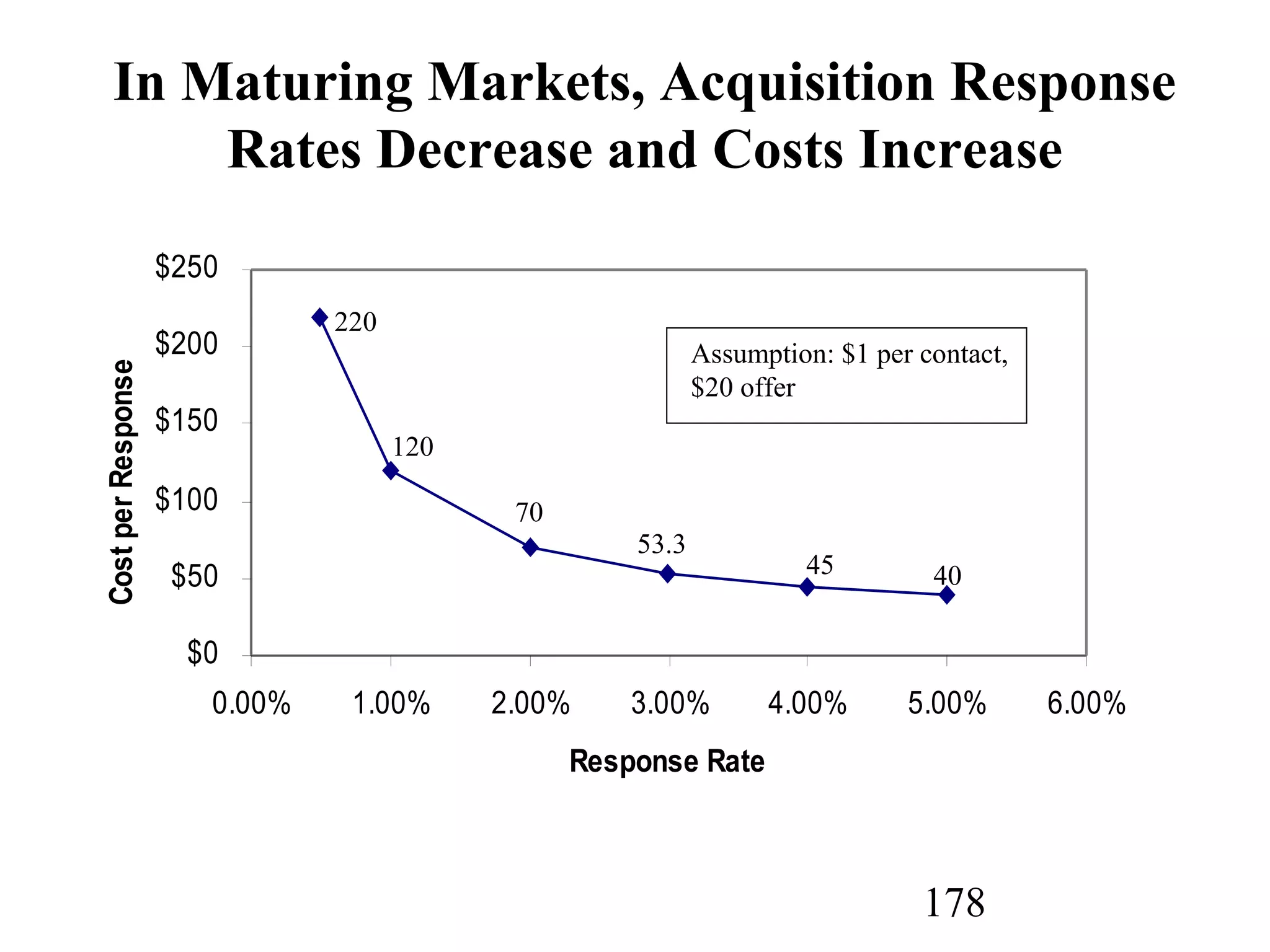
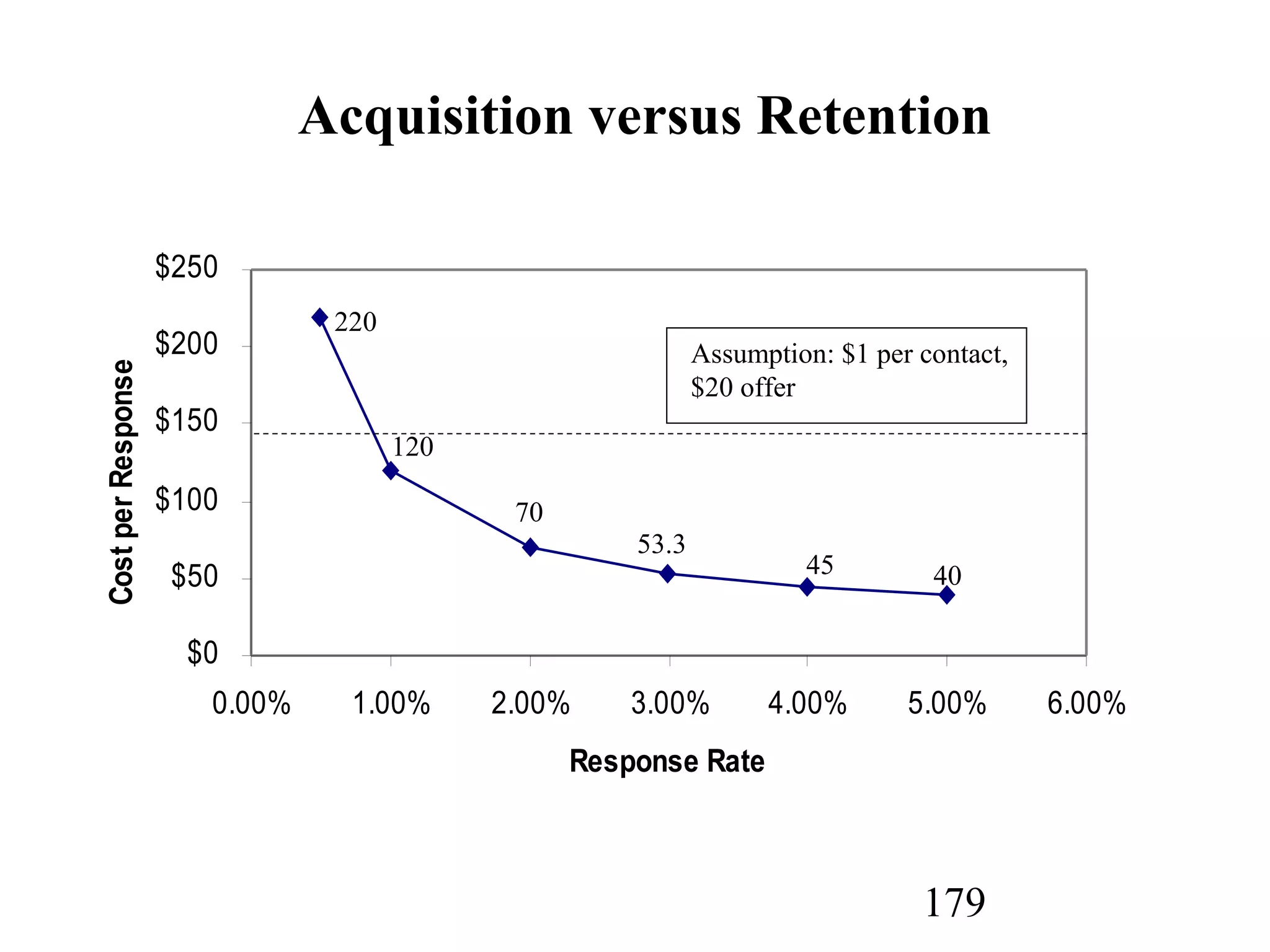



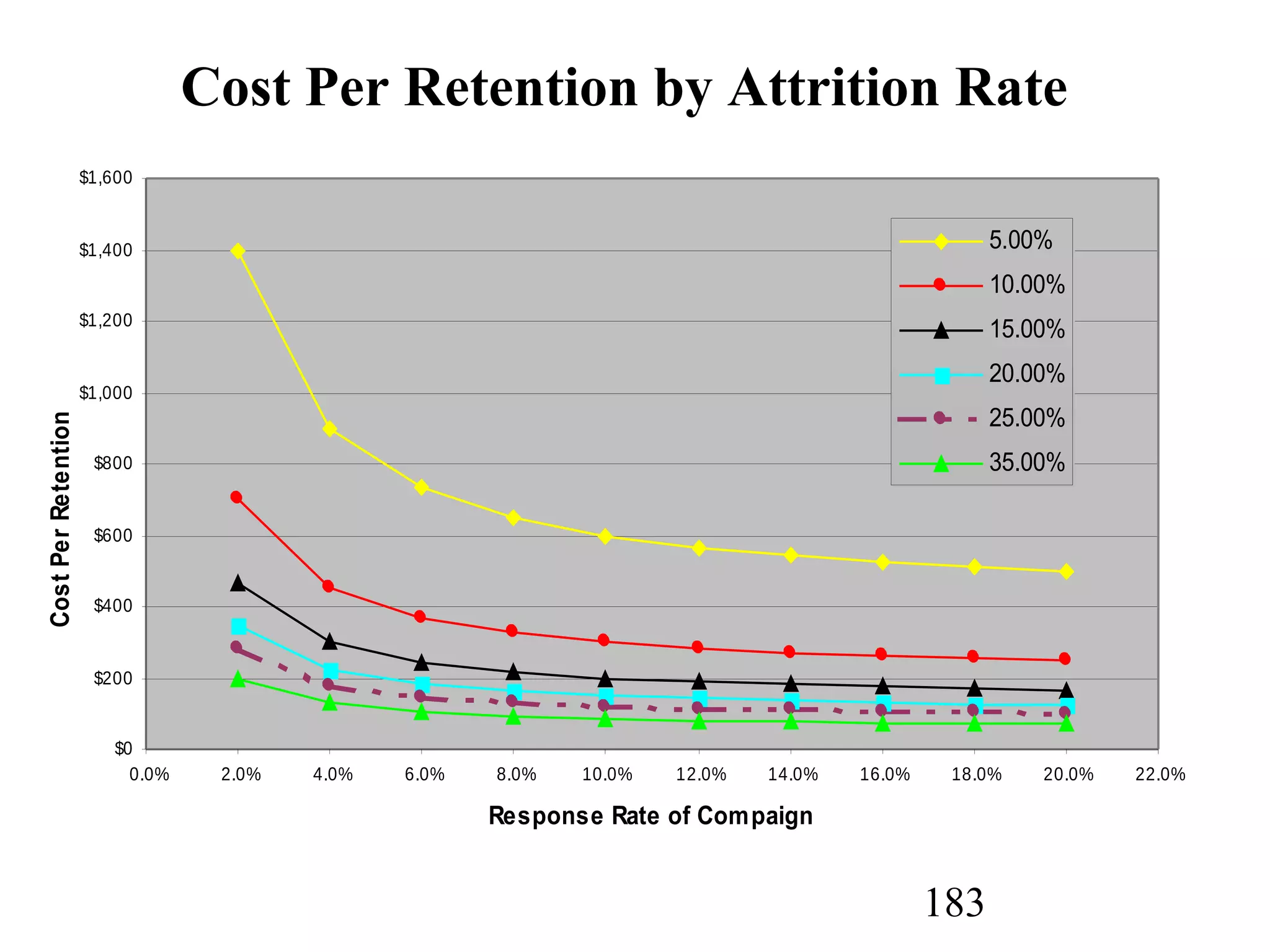

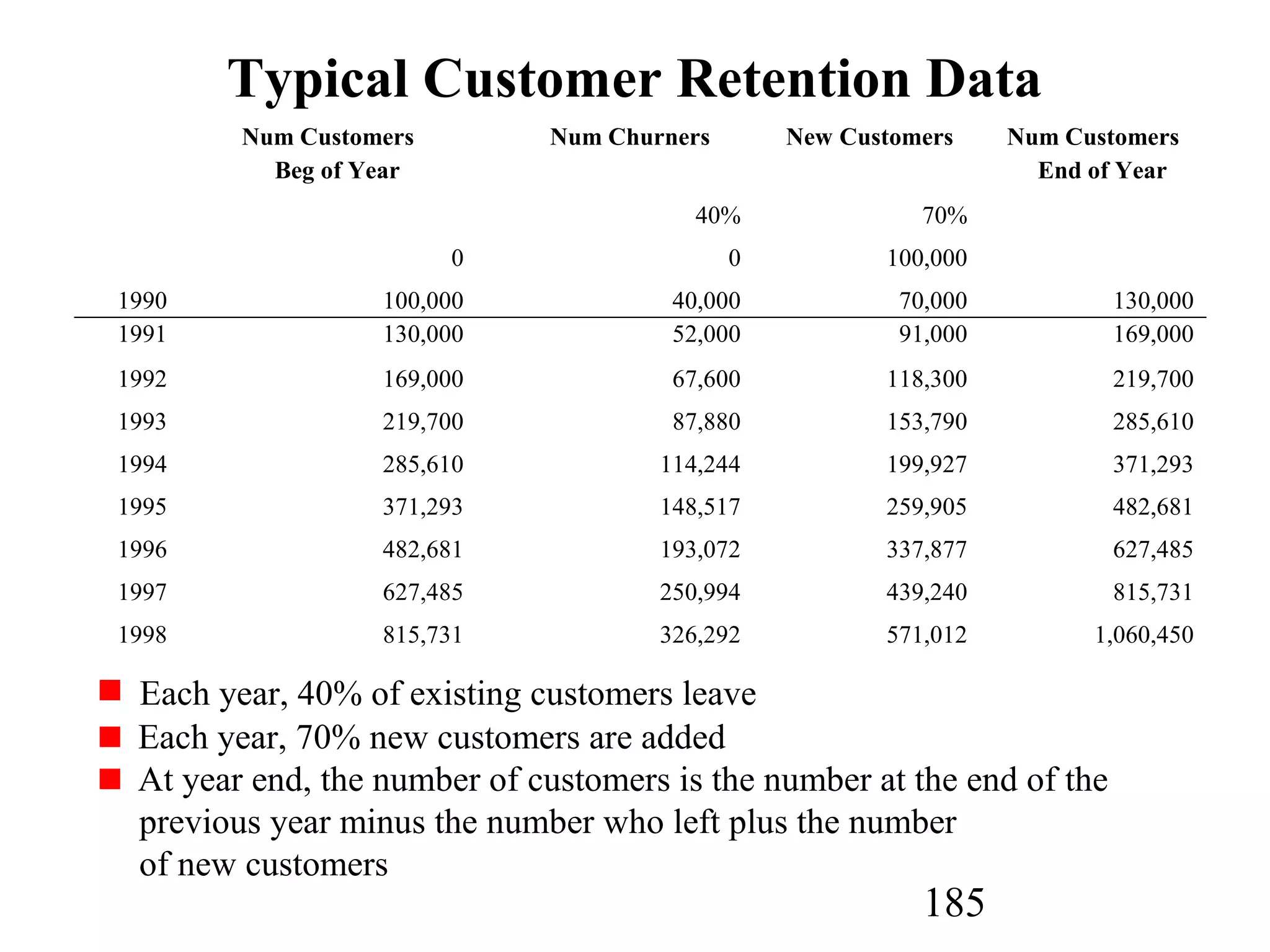
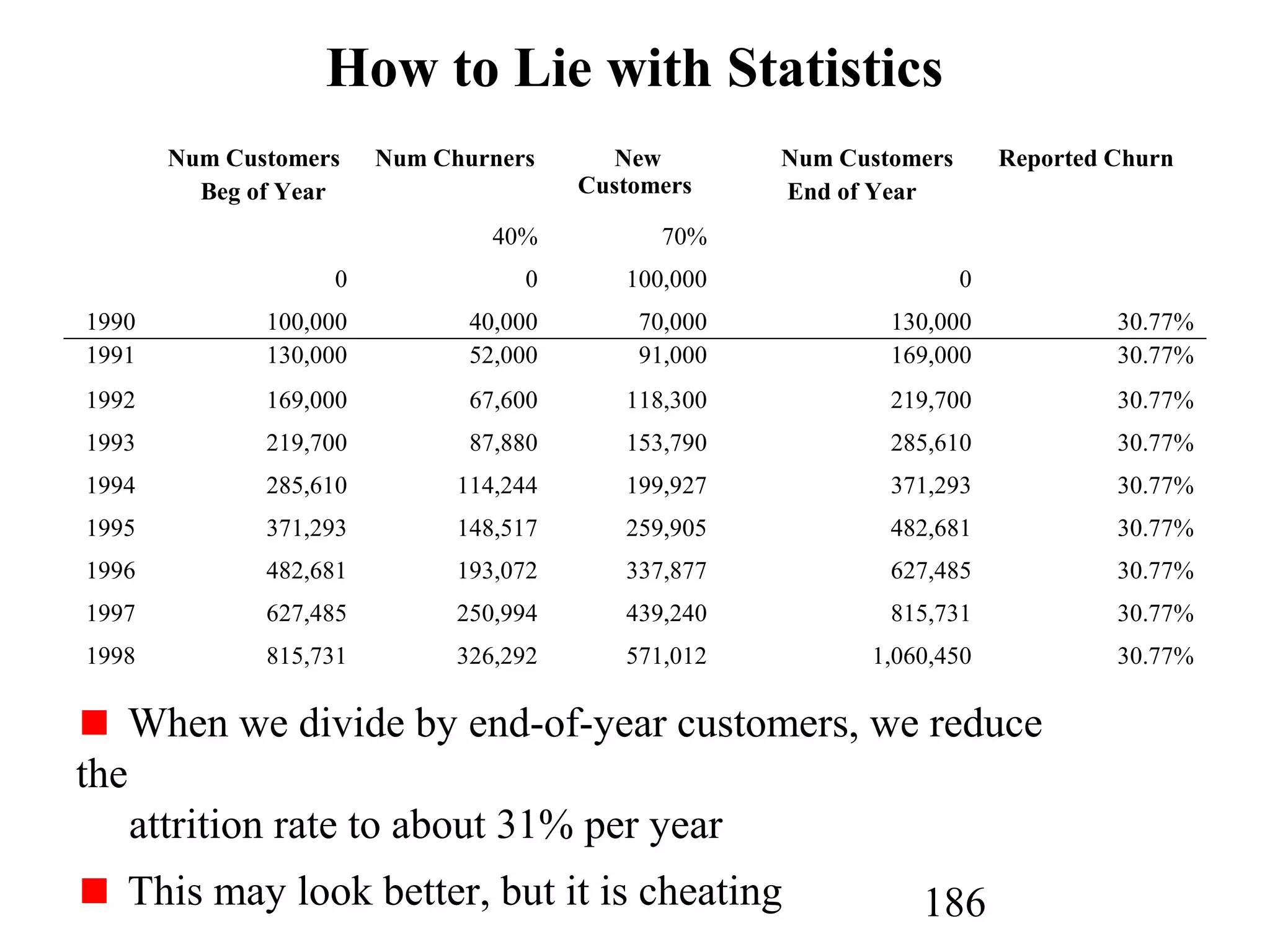
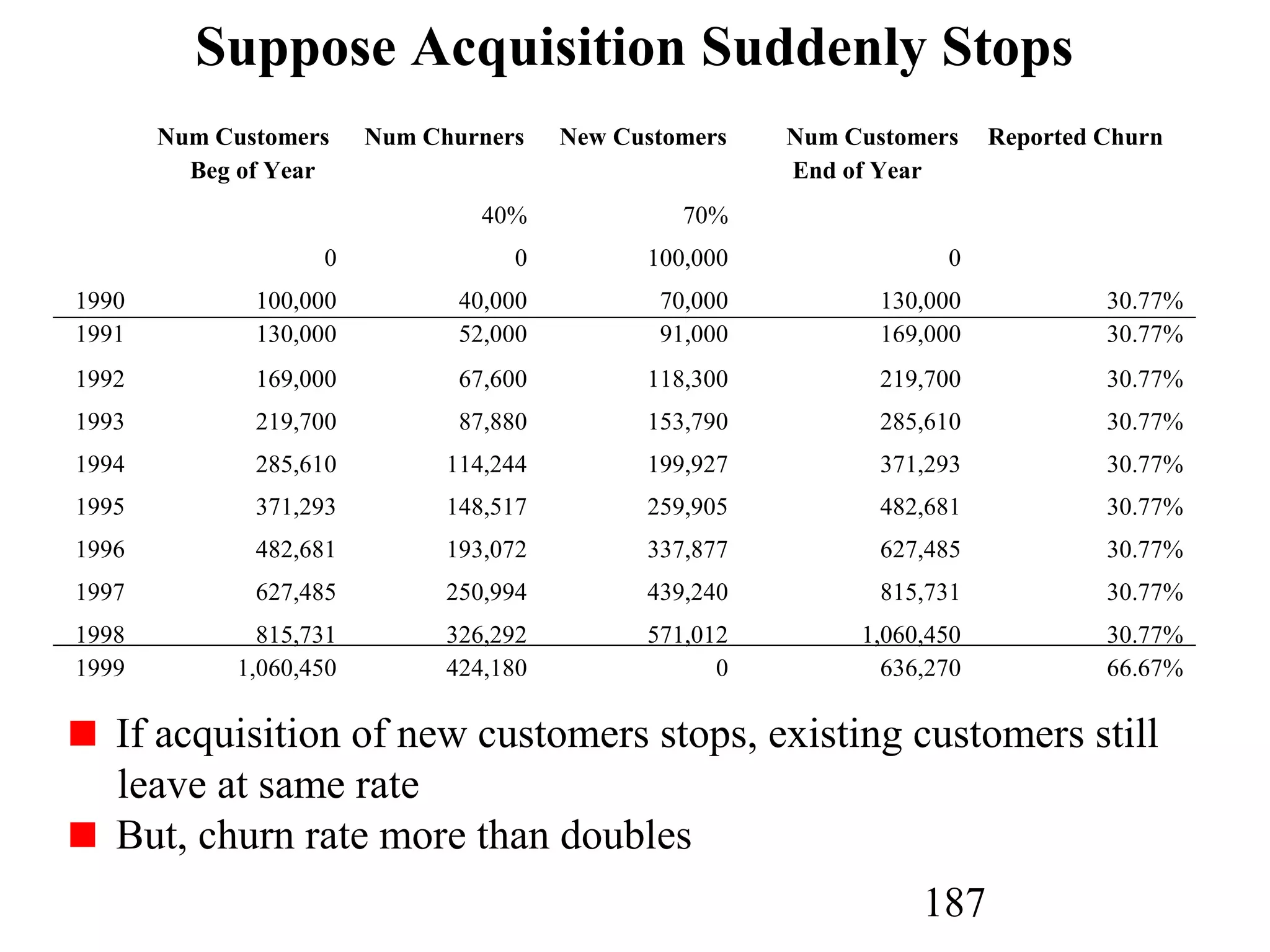

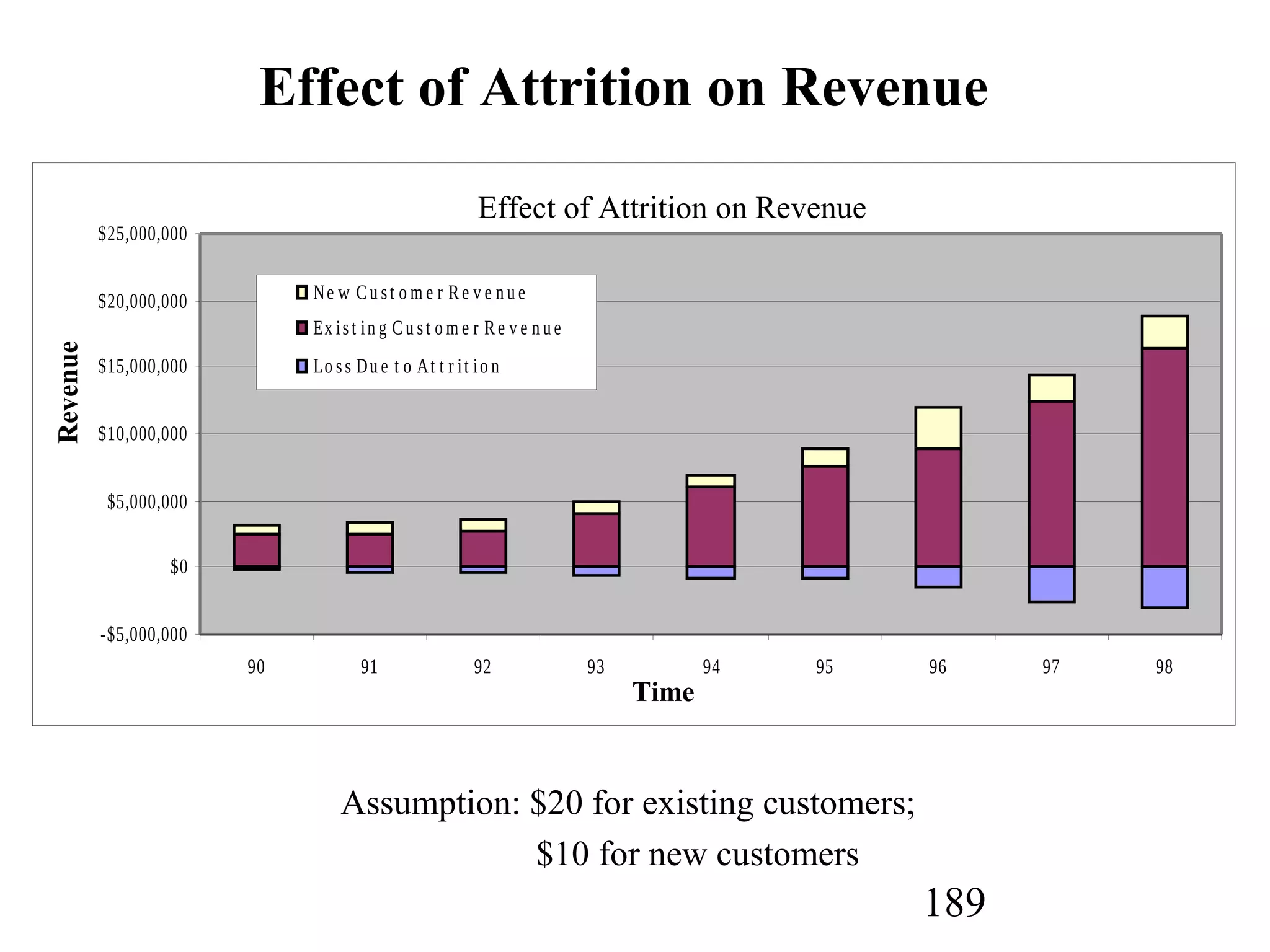

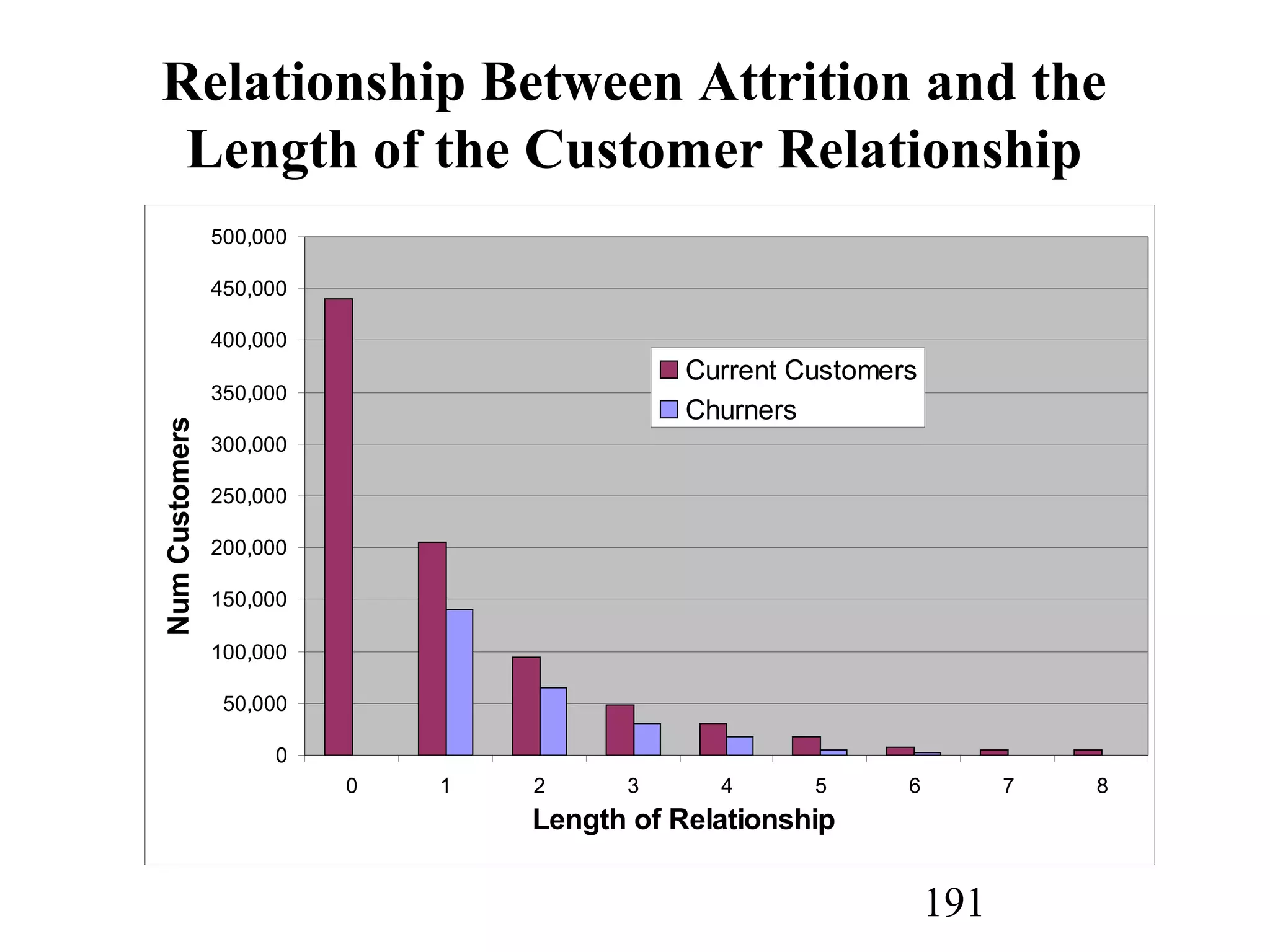







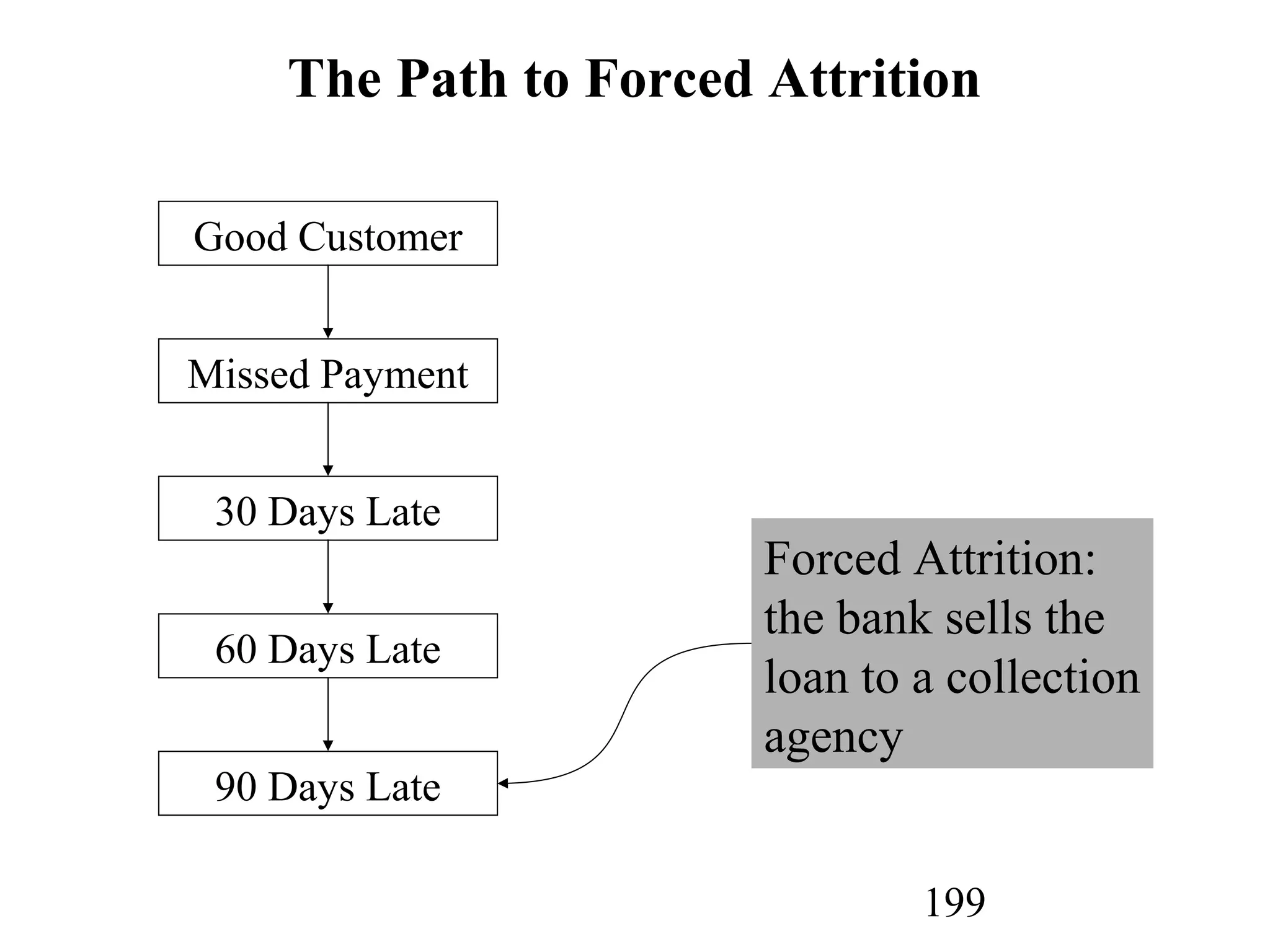














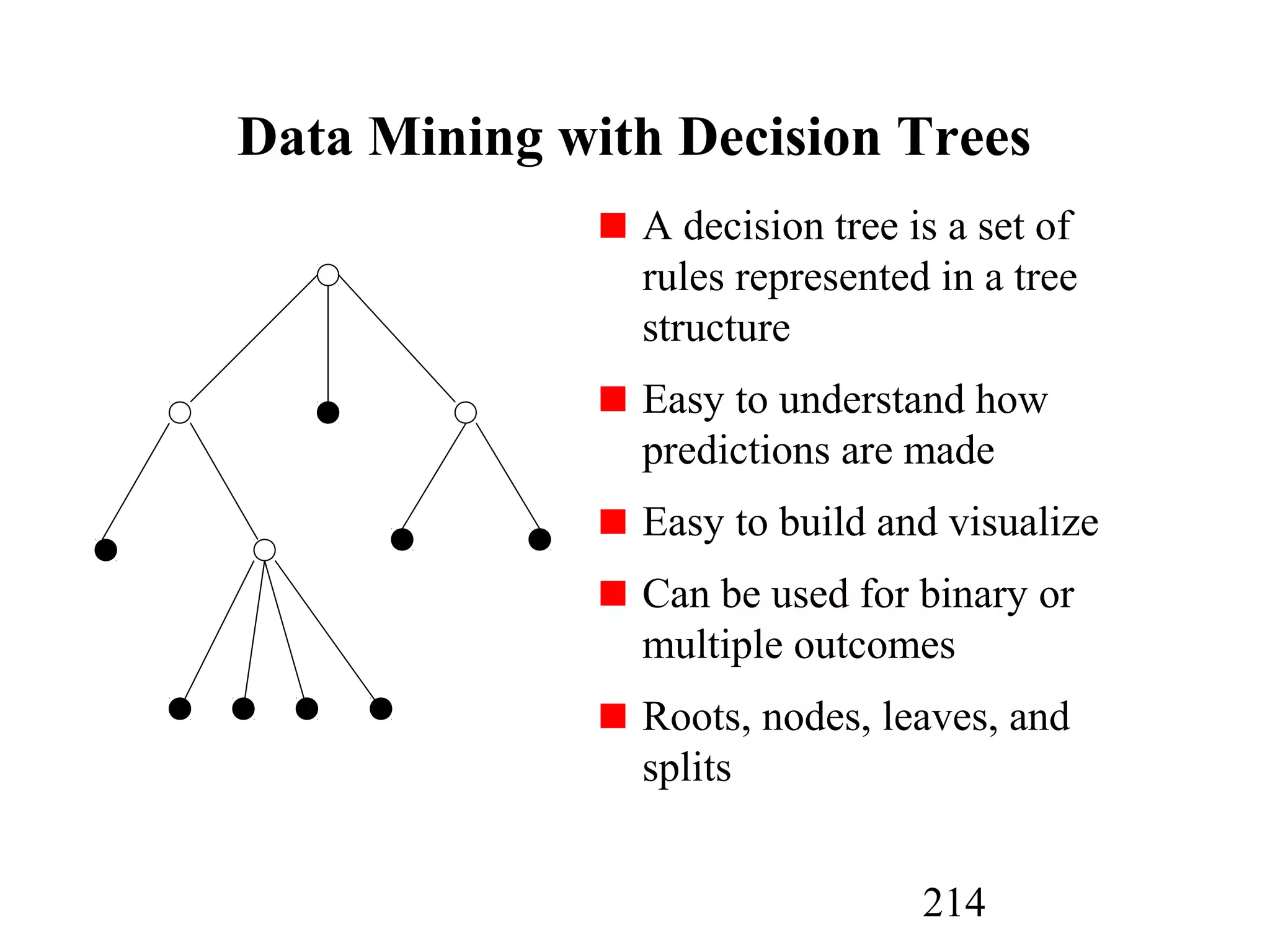

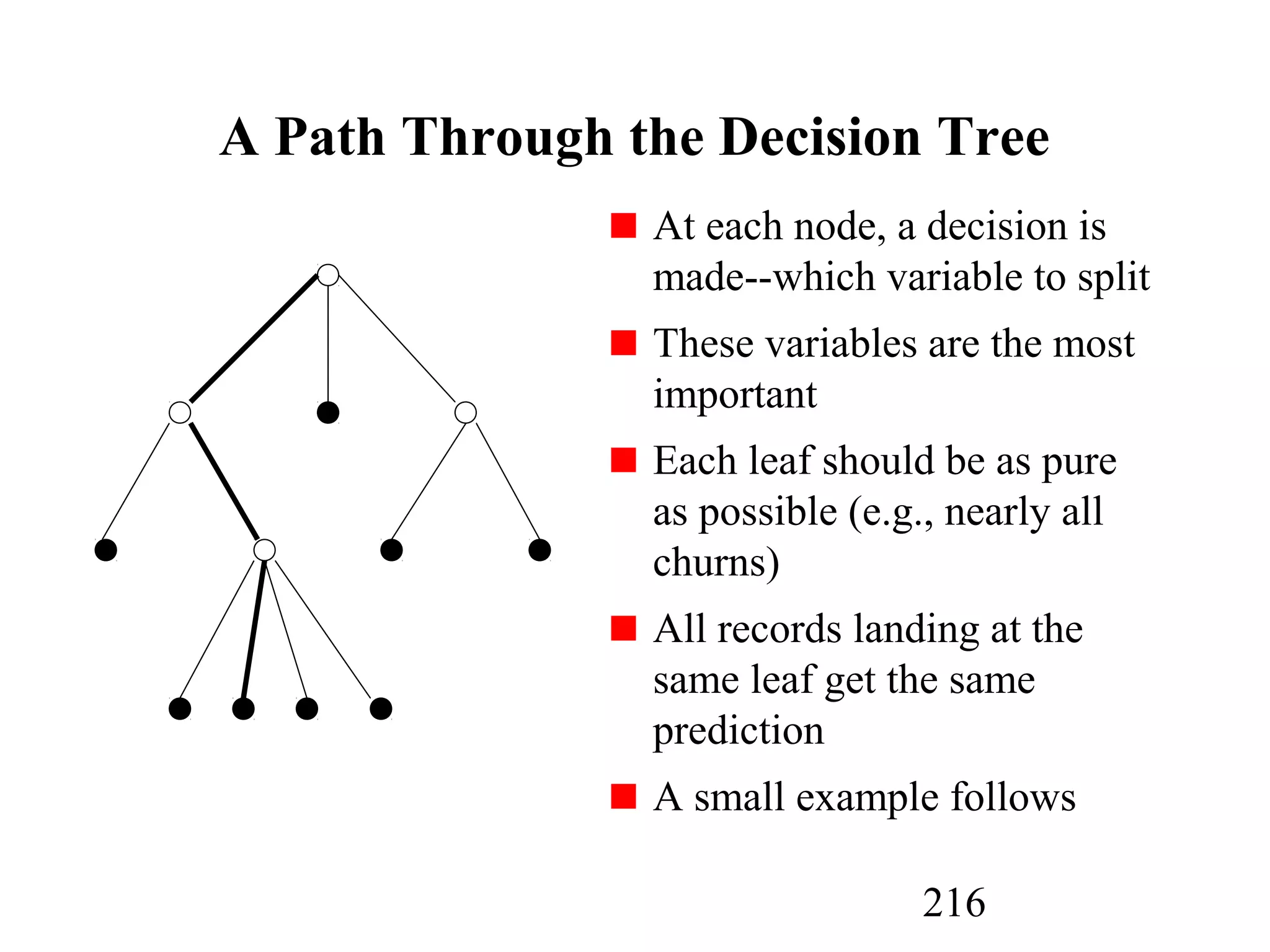
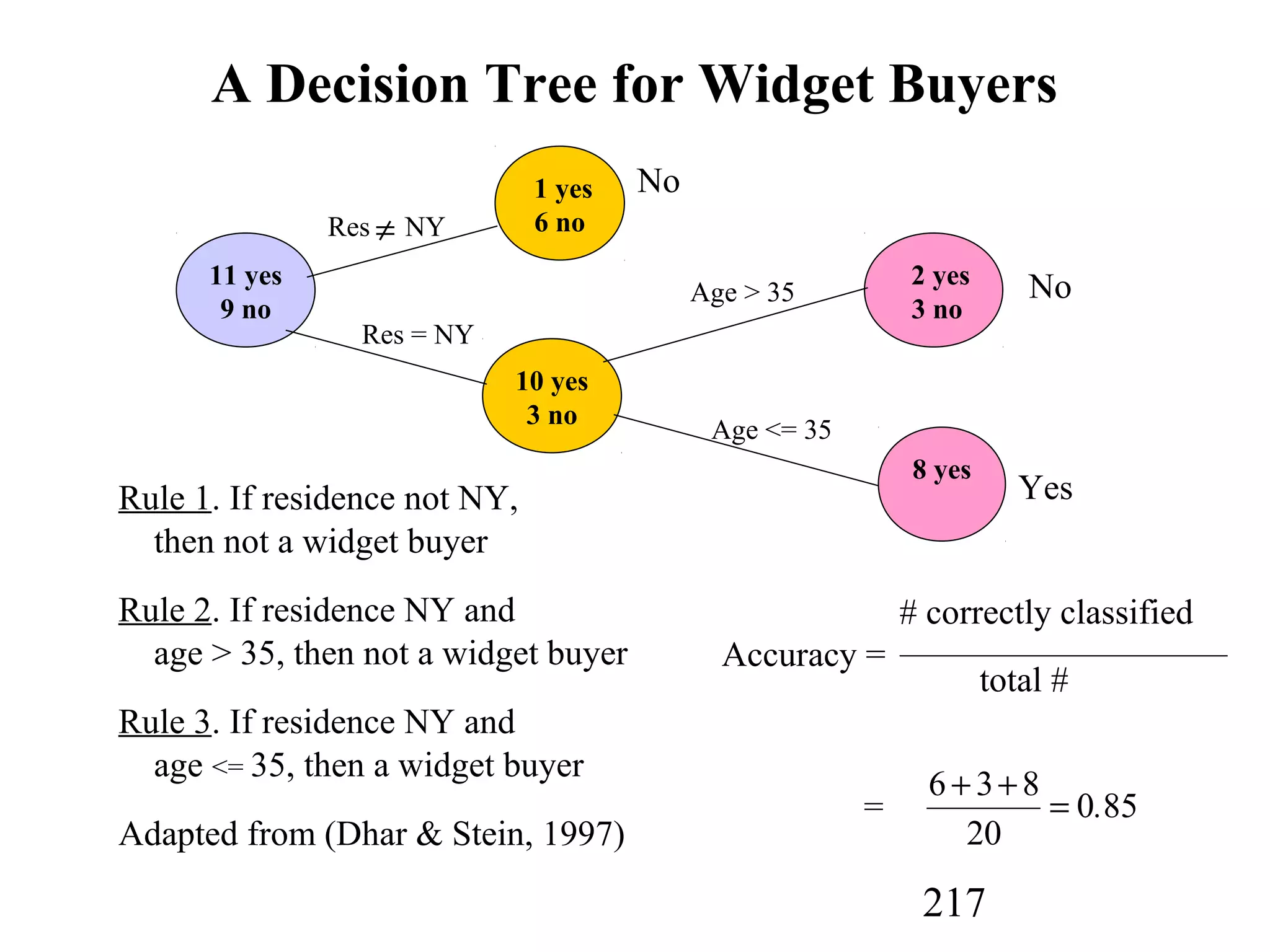


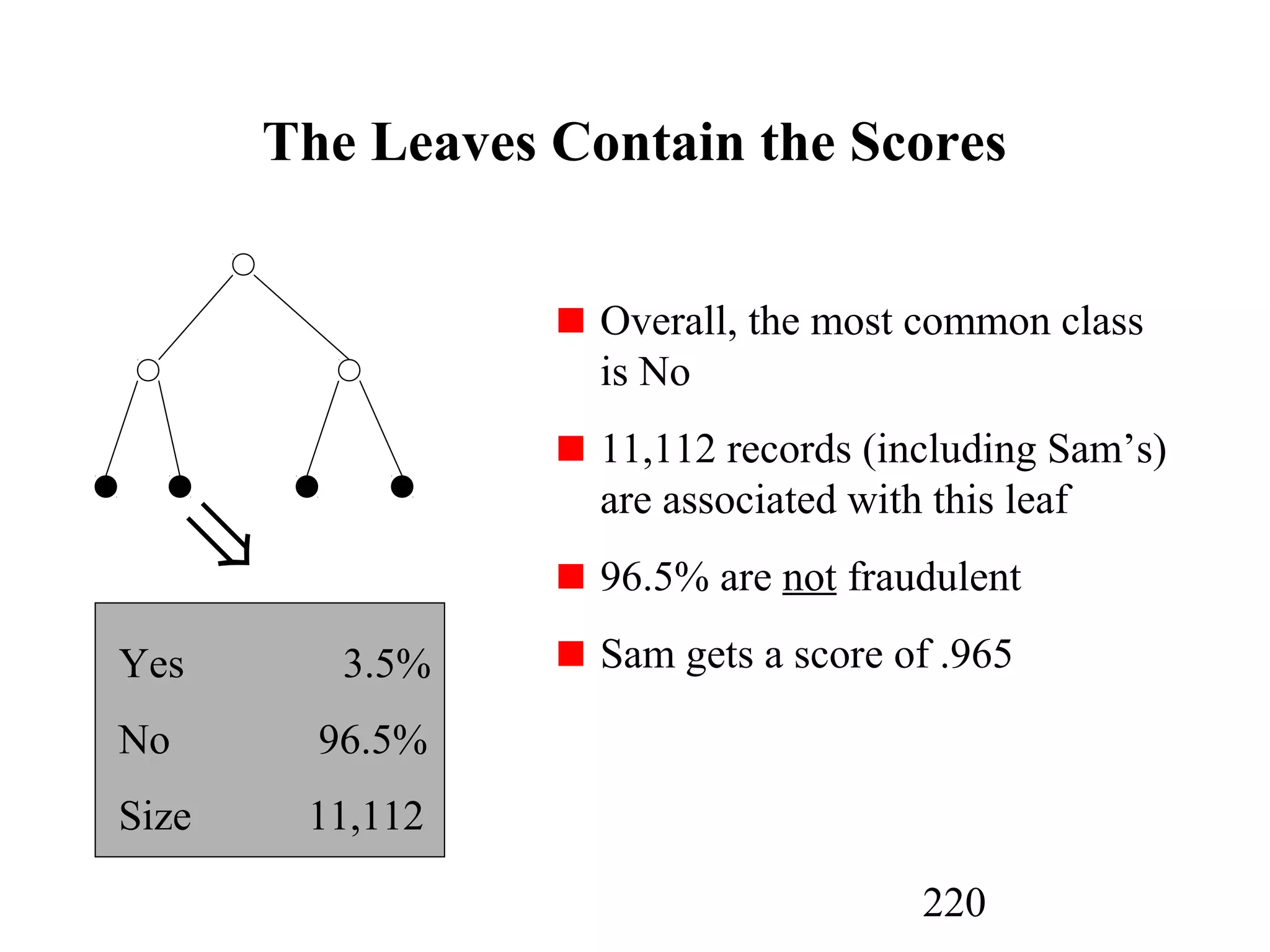
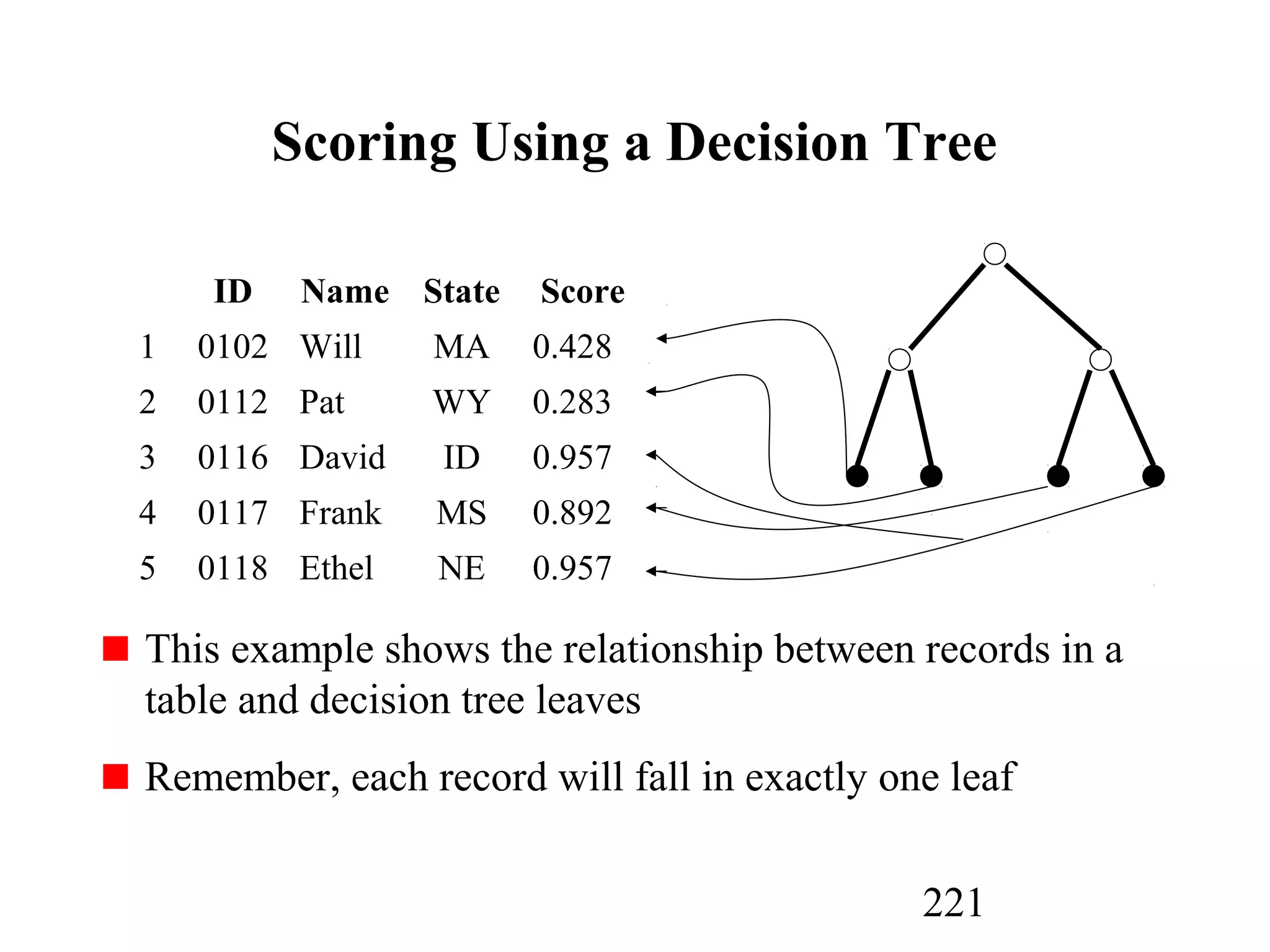
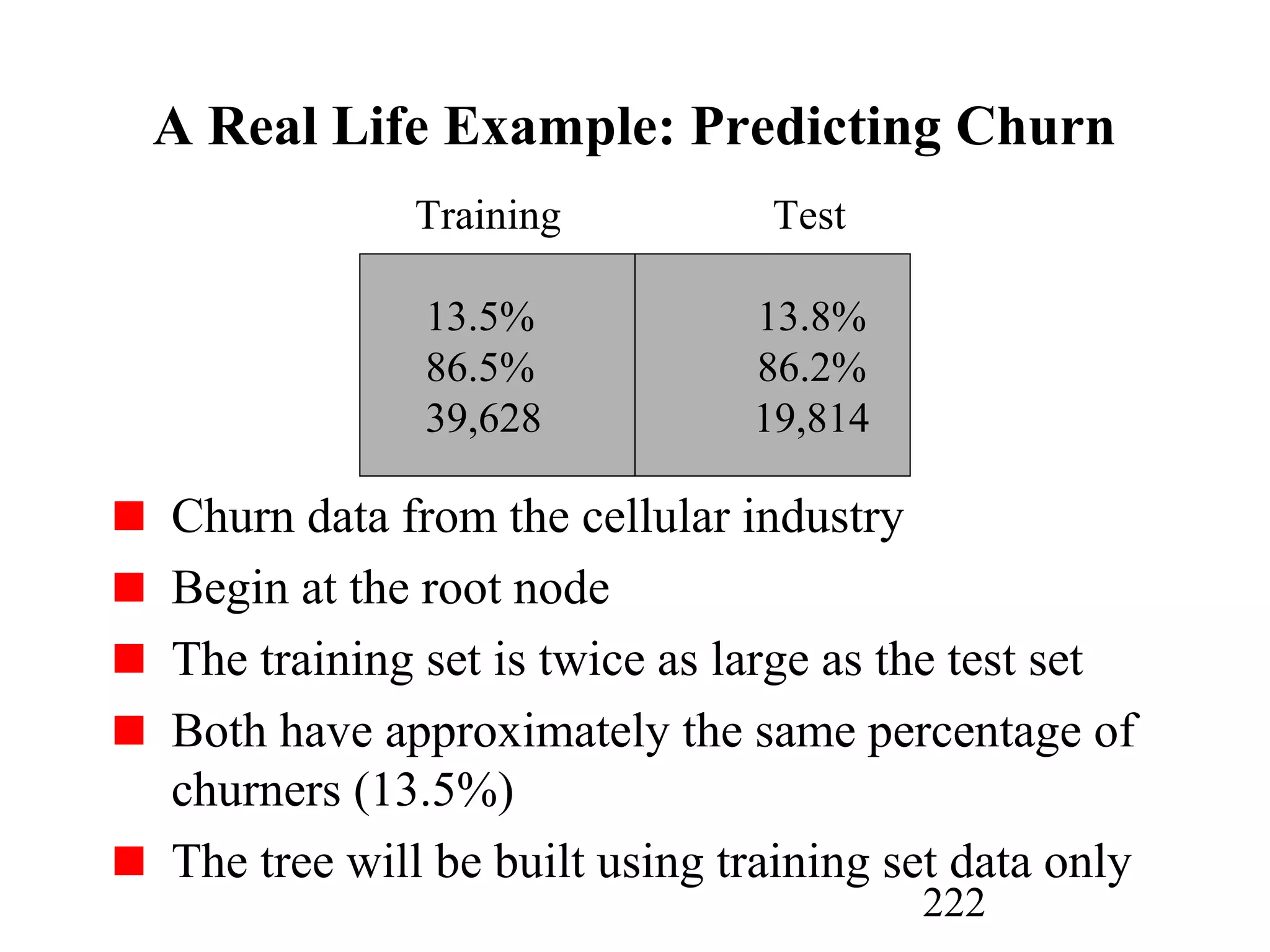









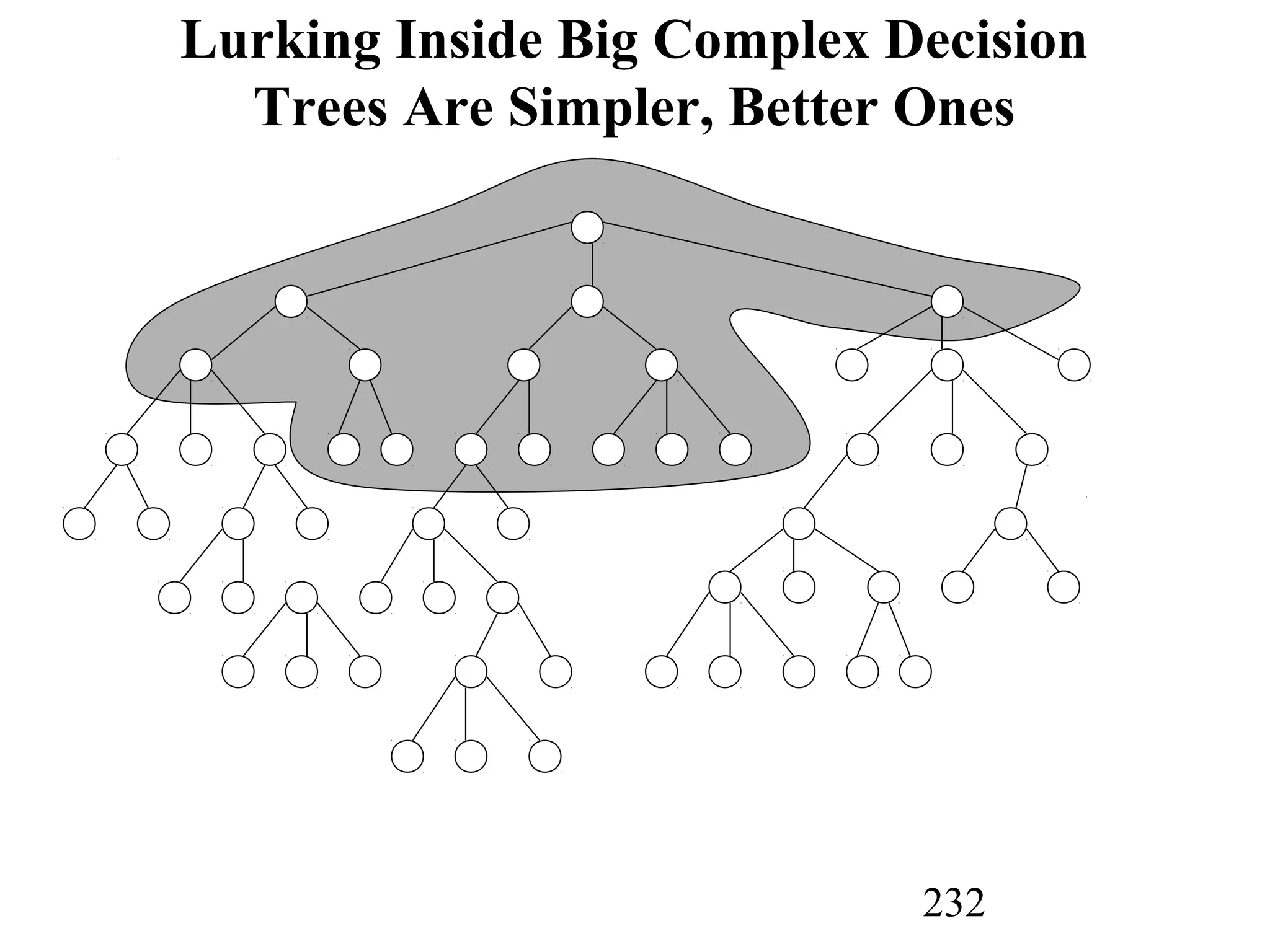







































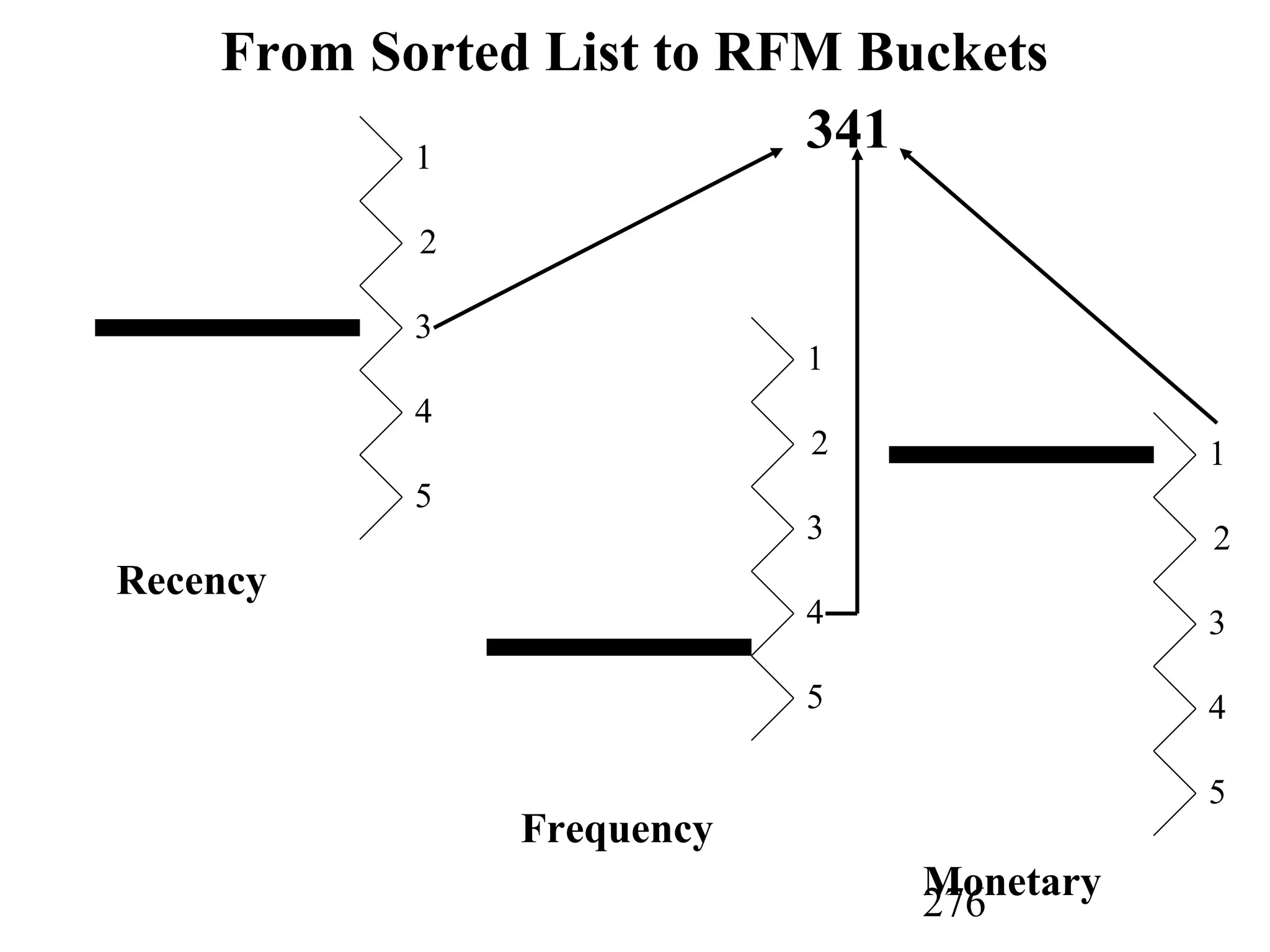
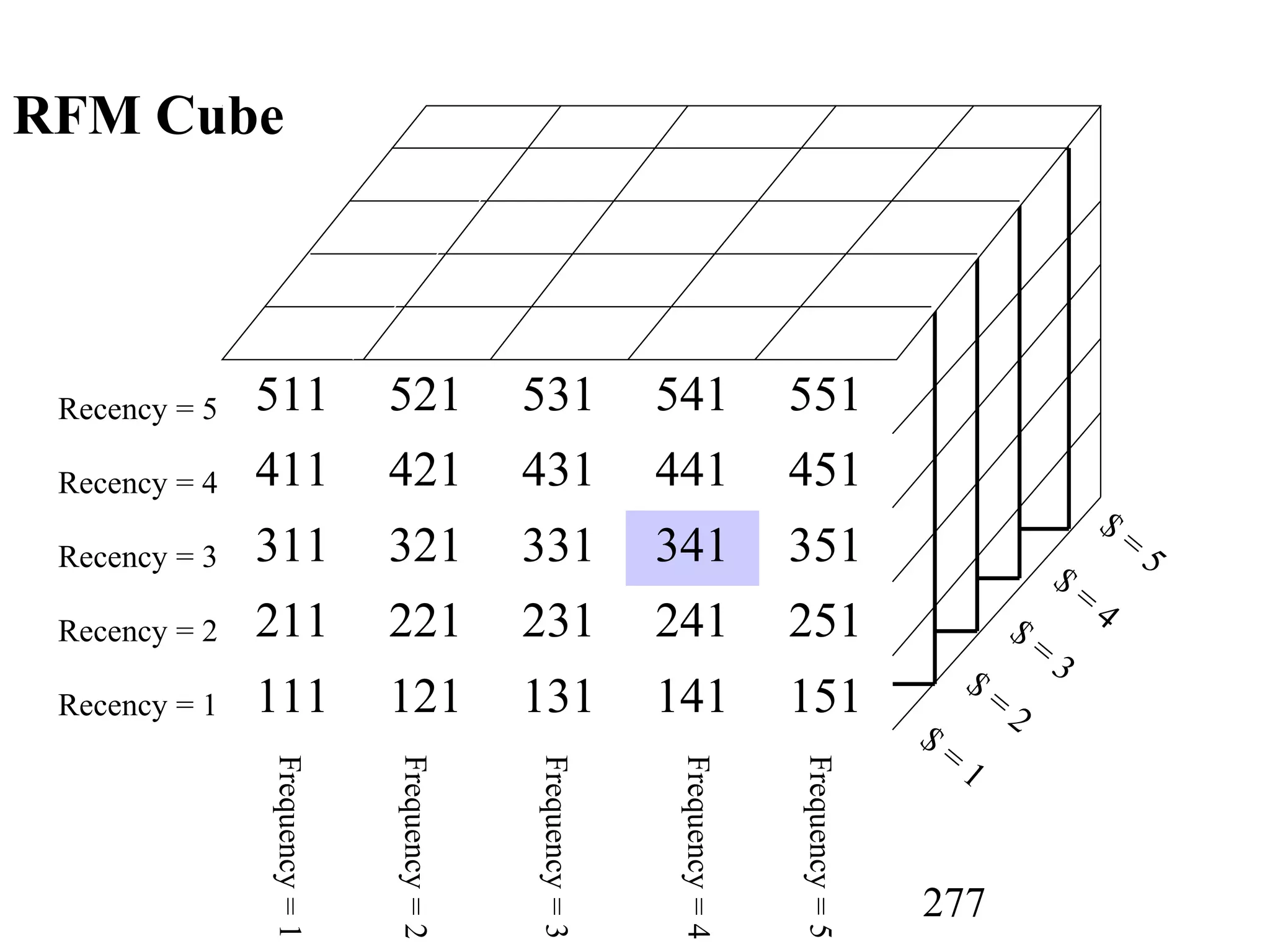





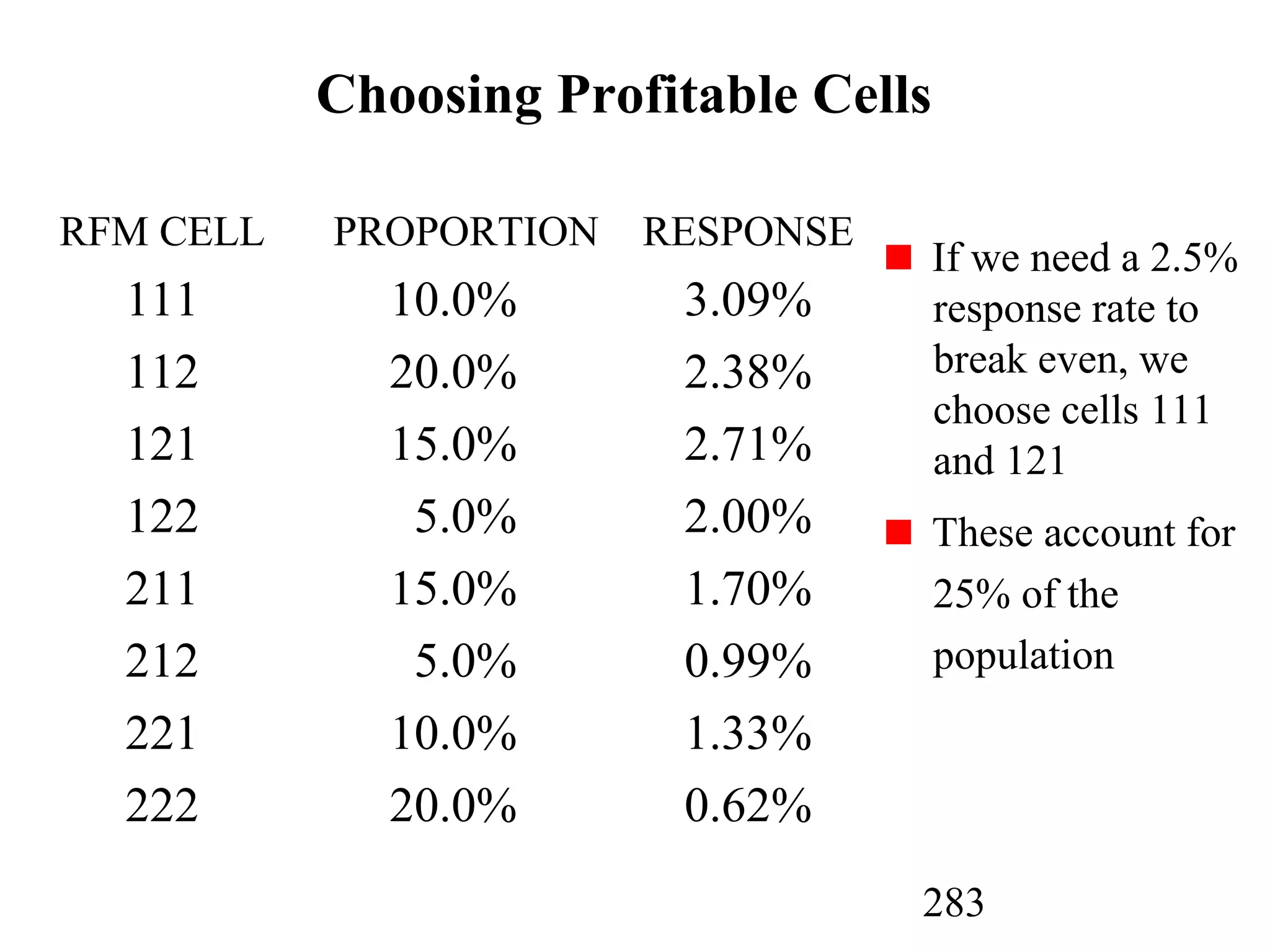











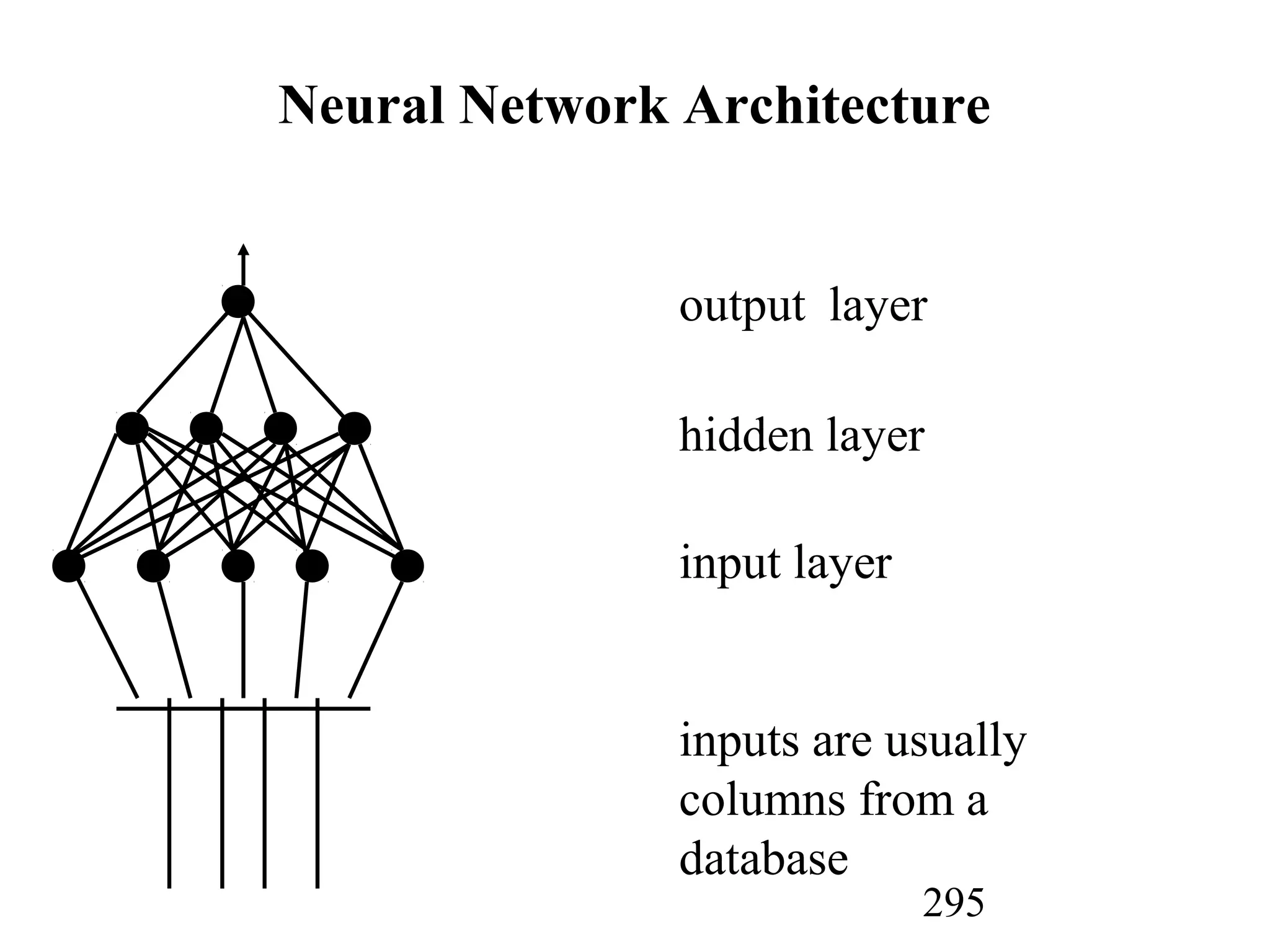
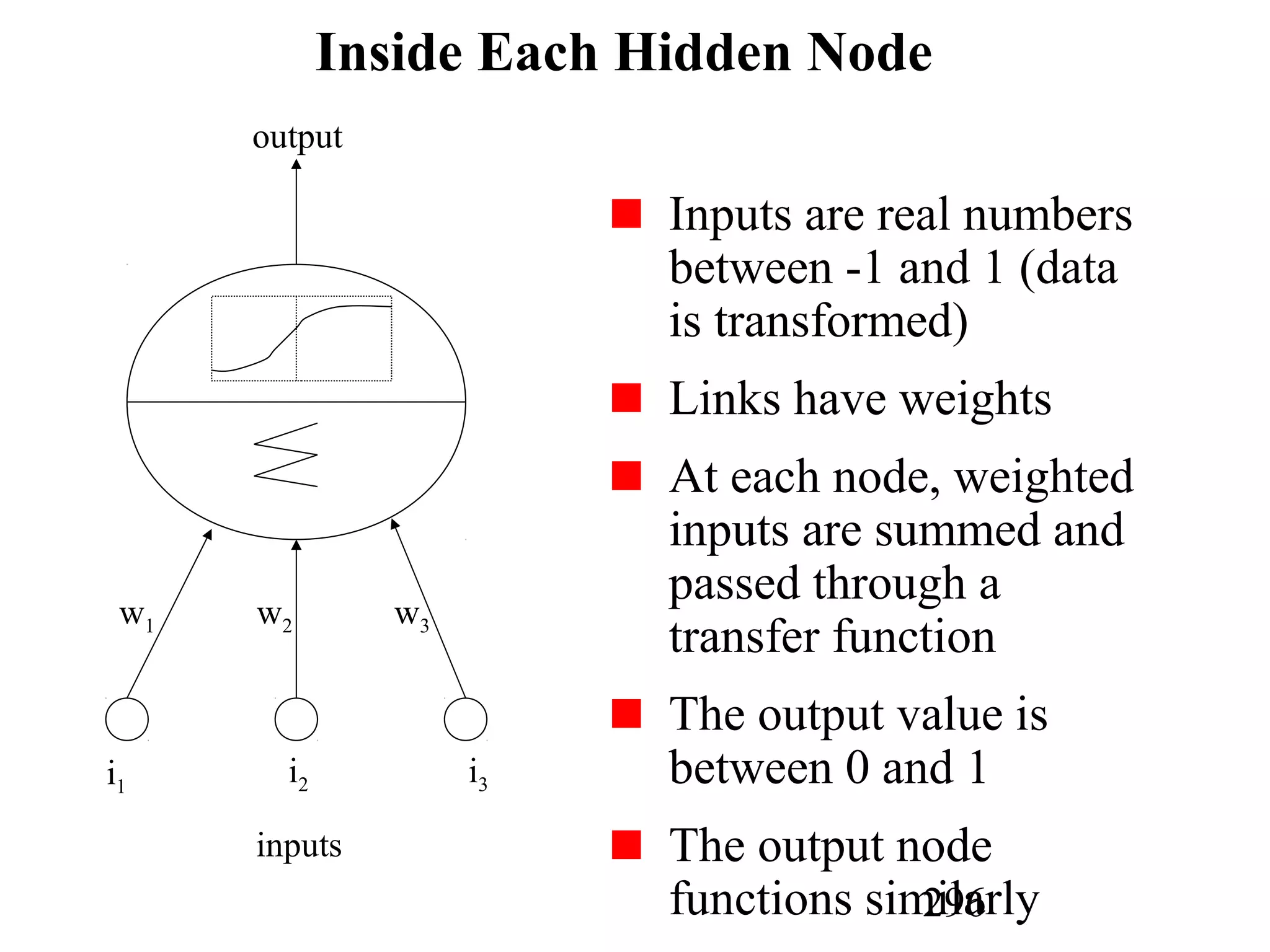






The document discusses customer relationship management (CRM) through data mining. It describes how CRM focuses on viewing customers as a company's primary asset and knowing customers across all business units and channels. CRM aims to learn from customer data generated through interactions over various channels to continuously improve the customer experience and identify opportunities. Data mining plays a key role in CRM by providing insights into customer behavior and needs to help companies better acquire, serve, and retain customers.





![09Feb2012ISOAgent[1]](https://cdn.slidesharecdn.com/ss_thumbnails/a4e880c8-1a17-4b11-8b81-58f39554ffe0-160726035046-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)