





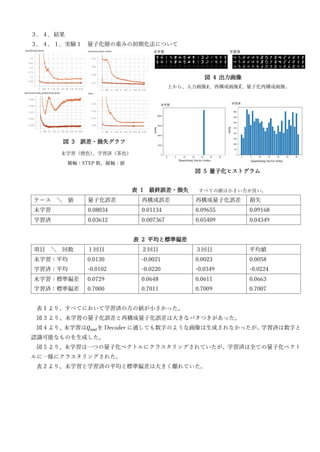
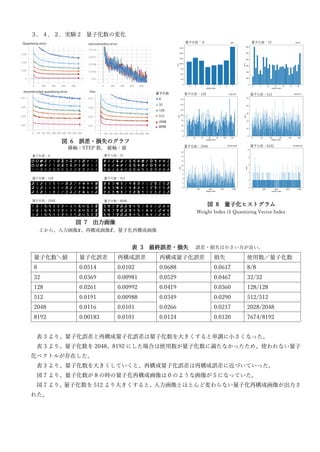
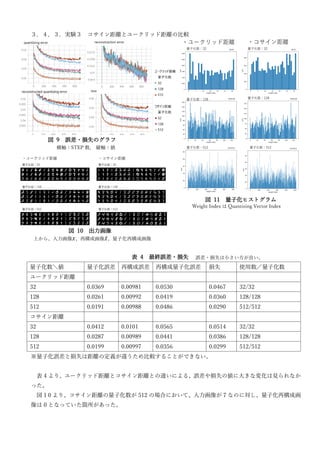


Vector Quantized AutoEncoder is proposed as an unsupervised clustering method. The document proposes the basic model, defines distance measurement, and shows a concrete example using the MNIST dataset. Source code for experiments is available online. Experiments are conducted to analyze different initialization methods for quantization weights, the effect of varying the number of quantization clusters, and comparing cosine distance and Euclidean distance metrics.


























![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)




















