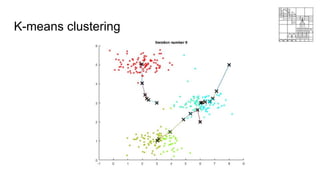
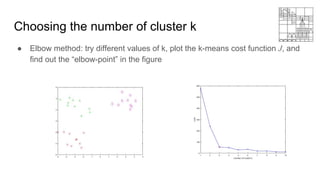
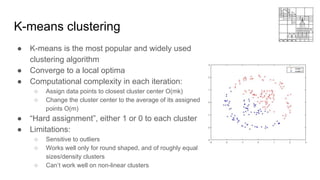
This document provides an overview of machine learning clustering techniques, including agglomerative clustering and k-means clustering. It discusses how agglomerative clustering successively merges the closest pair of clusters until one cluster remains, while k-means clustering initializes cluster centroids randomly and alternates between data point assignment and centroid updates. The document also introduces the bag-of-words model for representing documents or images as histograms of words or visual words.




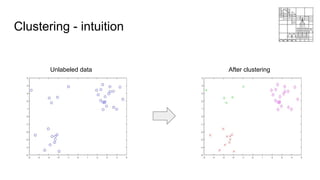





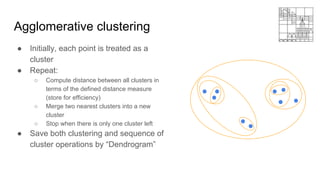


![Agglomerative clustering
Clustering gene expression data [Eisen et al 1998].](https://image.slidesharecdn.com/mlss-lec9-230119012121-ef3f1437/85/ML-using-MATLAB-13-320.jpg)






![Bag-of-Words model
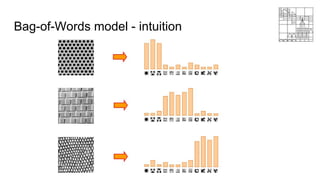
● Origins from Natural Language Process (NLP):
○ A text (such as a sentence or a document) is represented as the bag (multiset) of its words,
disregarding grammar and even word order but keeping multiplicity.
● Orderless document representation: frequencies of words from a dictionary
● A simple example:
○ Document 1: John likes to watch movies. One of his favorite movie is XXX
○ Document 2: John also likes to play football.
○ Document 3: Tom likes to watch movie as well.
○ Dictionary: {movie, football}
○ [2 0] [0 1] [1 0]](https://image.slidesharecdn.com/mlss-lec9-230119012121-ef3f1437/85/ML-using-MATLAB-24-320.jpg)
![Bag-of-Words model in computer vision
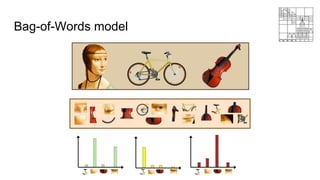
Algorithm:
● Extract scale-invariant features (SIFT [Lowe 2004], HOG [Dalal 2005], .etc)
from images
● Sample a subset of those features, construct a visual dictionary by k-means
(How many clusters k?)
● Quantize features using visual vocabulary
● Represent images by frequencies of “visual words”
The histogram representations of images can be used for classification using
some ML classification models.](https://image.slidesharecdn.com/mlss-lec9-230119012121-ef3f1437/85/ML-using-MATLAB-27-320.jpg)


















![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)






























