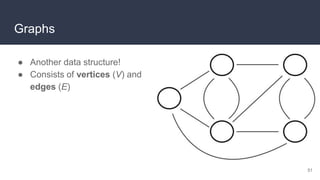
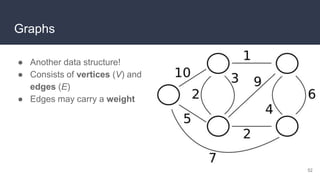
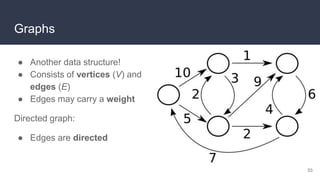
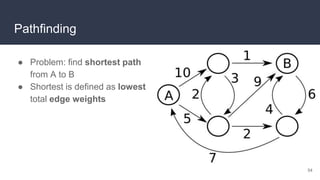
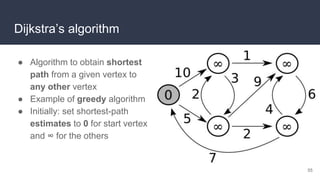
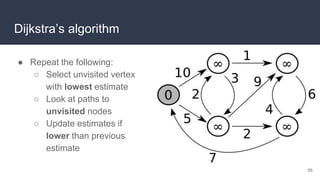
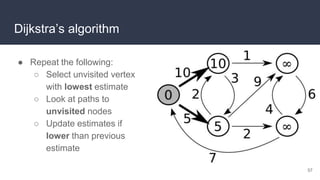
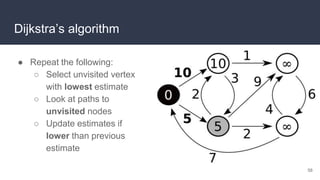
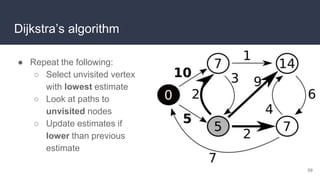
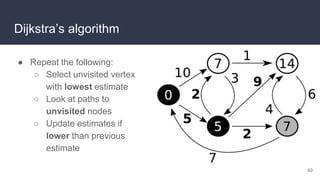
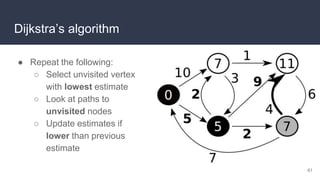
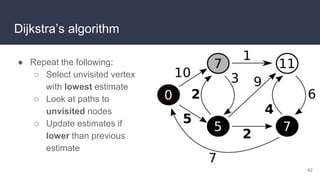
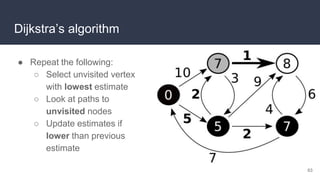
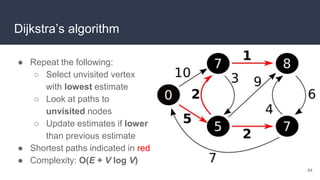
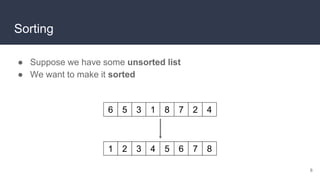
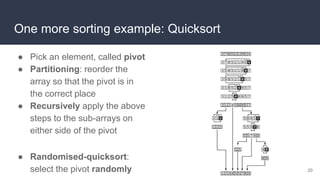
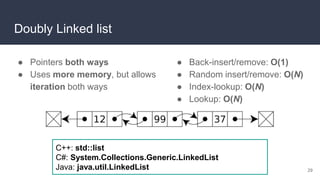
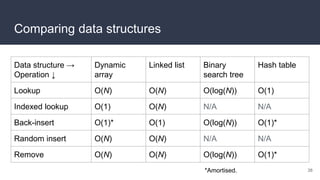
This document provides an overview of algorithms and data structures. It covers sorting algorithms like insertion sort, bubble sort, merge sort, and quicksort. It discusses complexity analysis using Big O notation and compares the time complexities of different sorting and searching algorithms. Common linear and nonlinear data structures are explained like arrays, linked lists, stacks, queues, trees, and hash tables. Abstract data types like maps, sets, queues and stacks are also introduced. Dijkstra's algorithm for finding shortest paths in graphs is described.







![N steps
N steps
● In pseudocode:
i ← 1
while i < length(A)
j ← i
while j > 0 and A[j-1] > A[j]
swap A[j] and A[j-1]
j ← j - 1
end while
i ← i + 1
end while
Insertion sort
● “Naive” sorting algorithm
● One-by-one, take each
element and move it
● When all elements have been
moved, list is sorted!
9
● In pseudocode:
i ← 1
while i < length(A)
j ← i
while j > 0 and A[j-1] > A[j]
swap A[j] and A[j-1]
j ← j - 1
end while
i ← i + 1
end while
Total: N² steps
By Swfung8 (Own work) [CC BY-SA
3.0], via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-9-320.jpg)
![Bubble sort
● Traverse the list, taking pairs
of elements
● Swap if order incorrect
● Repeat N times
● Now it’s sorted!
10
Total: N² steps
By Swfung8 (Own work) [CC BY-SA 3.0],
via Wikimedia Commons
N steps
N steps](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-10-320.jpg)

![Merge sort
● Much smarter sort
○ Split the dataset into chunks
○ Sort each chunk
○ Merge the chunks back together
● Example of divide-and-conquer
● Splitting & sorting takes log₂(N) steps
● Merging takes N steps
12
By Swfung8 (Own work) [CC BY-SA 3.0],
via Wikimedia Commons
Total: N log(N) steps](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-12-320.jpg)


![Complexity – O
● Roughly three categories, in decreasing
order:
○ Exponential – O(kN)
○ Polynomial – O(Nk)
○ Polylogarithmic – O(log(N)k)
● This is an abstraction!
○ Does not directly relate to runtimes
○ A good O(N²) algorithm may be faster than
a bad O(log(N)) one
○ Depends on your input data! 15
By Cmglee (Own work) [CC BY-SA 4.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-15-320.jpg)

![Complexity – O
● Formal definition:
f(N) = O(g(N)) ↔
∃ N₀, M : ∀ N > N₀ : f(N) ≤ M g(N)
● In words: starting from N₀, f is bounded
from above by g (up to some constant M)
17
By Cmglee (Own work) [CC BY-SA 4.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-17-320.jpg)
![Complexity – Ω
● Ω: lower bound
○ Formal definition:
f(N) = Ω(g(N)) ↔
∃ N₀, M : ∀ N > N₀ : f(N) ≥ M g(N)
○ In words: starting from N₀, f is bounded
from below by g (up to some constant M)
● Examples:
○ N = Ω(log(N))
○ N² = Ω(N)
18
By Cmglee (Own work) [CC BY-SA 4.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-18-320.jpg)
![Complexity – Θ
● Θ: exact bound
○ Formal definition:
f(N) = Θ(g(N)) ↔
f(N) = O(g(N)) and f(N) = Ω(g(N))
● Examples:
○ N = Θ(N)
○ 2N = Θ(N)
○ 3N²+5N+1 = Θ(N²)
○ N ≠ Θ(N²) (even though N = O(N²))
19
By Cmglee (Own work) [CC BY-SA 4.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-19-320.jpg)






![Pointers
27
By Sven (Own work) [CC BY-SA
3.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-27-320.jpg)

![Binary search
● Searches a sorted linear data structure
● Takes Θ(log(N))
● Example of divide and conquer
30
By AlwaysAngry (Own work) [CC BY-SA 4.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-30-320.jpg)


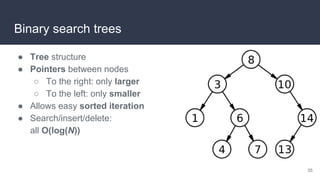
![Recall: Binary search
● Searches a sorted linear data structure
● Takes Θ(log(N))
● … let’s use this as inspiration for a data structure!
34
By AlwaysAngry (Own work) [CC BY-SA 4.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-34-320.jpg)
![Hash tables
● Idea: create buckets
numbered 1 to B
● For each item, compute in
which bucket it belongs
● Put the item in that bucket
● Search/insert/delete:
all O(1)
36
By Jorge Stolfi (Own work) [CC BY-SA 3.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-36-320.jpg)
![Hash tables
● Problem: clashing hashes!
● Solution: replace entry with
linked list (chaining)
● New problem: load factor
can become too high!
● Solution: copy to new table
with more buckets
37
By Jorge Stolfi (Own work) [CC BY-SA 3.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-37-320.jpg)


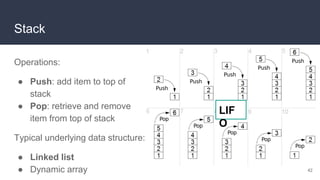
![Operations:
● Enqueue: add item to beginning
of queue
● Dequeue: retrieve and remove
item from end of queue
Typical underlying data structure:
● Linked list
● Dynamic array
Queue
41
By Vegpuff (Own work) [CC BY-SA 3.0],
via Wikimedia Commons
FIF
O](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-41-320.jpg)
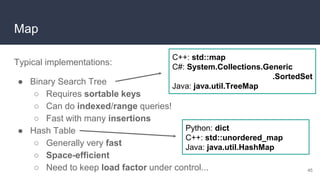
![Map
● Map: dataset that maps
(associates) keys to values
● Keys are unique
(values need not be)
● Values can be retrieved by
key
● Not indexed…
○ ...although an array could
be seen as a map with
integer keys! 43
By Jorge Stolfi (Own work) [CC BY-SA 3.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-43-320.jpg)
![Map
Operations:
● Lookup: retrieve value for a
key
● Insert: add key-value pair
● Replace: replace value for a
specified key
● Remove: remove key-value
pair
44
By Jorge Stolfi (Own work) [CC BY-SA 3.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-44-320.jpg)
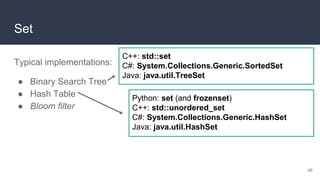
![Set
● Set: dataset that contains
certain values
● No ordering, no
multiplicity
● A value is either present
or not
46
Adapted by L.J. Bel from Jorge Stolfi (Own work) [CC BY-SA 3.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-46-320.jpg)
![Set
Operations:
● Contains: check whether a
value is present
● Add: add a value
● Remove: remove a value
47
Adapted by L.J. Bel from Jorge Stolfi (Own work) [CC BY-SA 3.0],
via Wikimedia Commons](https://image.slidesharecdn.com/algorithmsdatastructures-icsc2018-230313011031-9e35c00a/85/Algorithms__Data_Structures_-_iCSC_2018-pptx-47-320.jpg)