The document discusses three ways to serve machine learning models: AWS Fargate, AWS SageMaker endpoints and batch transforms, and AWS Lambda.
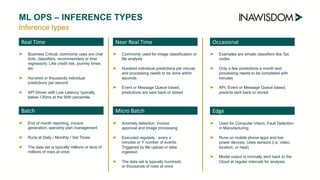
AWS Fargate supports batch and real-time inference, has low latency (<100ms), supports CPU but not GPU, charges per hour, and auto-scales applications. However, it does not integrate with SageMaker notebooks and does not support model monitoring.
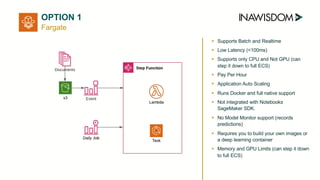
AWS SageMaker supports batch and real-time inference, has built-in algorithms and frameworks, low latency (<100ms), supports CPU and GPU, charges per hour with savings plans, integrates with SageMaker notebooks, and supports model monitoring.
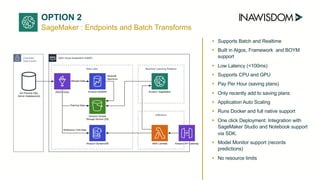
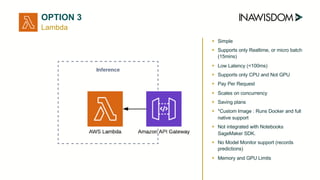
AWS Lambda supports only real-time or micro-batch