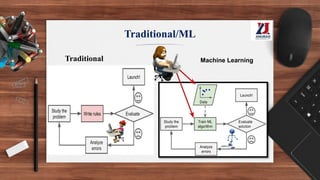
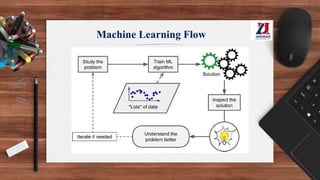
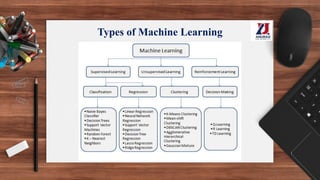
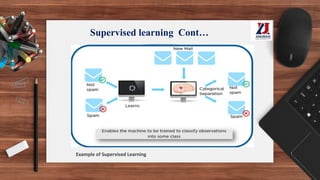
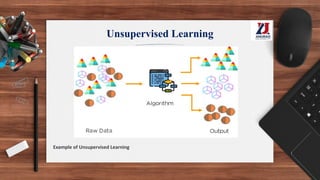
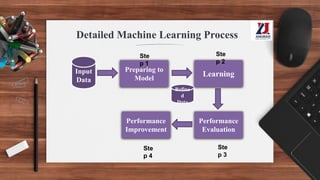
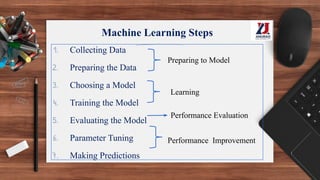
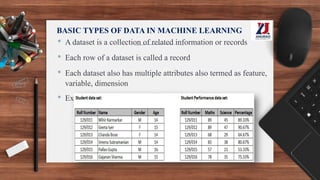
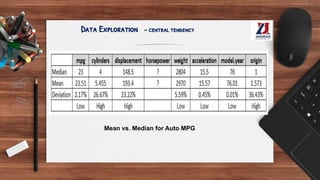
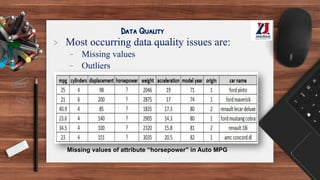
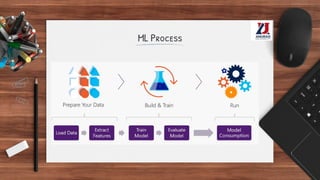
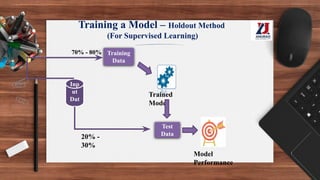
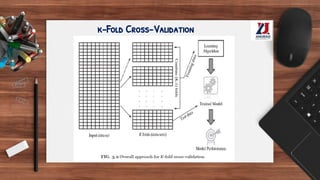
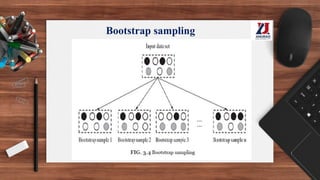
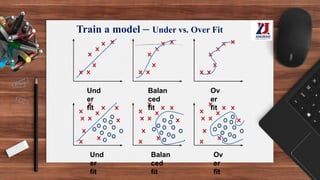
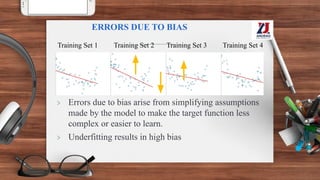
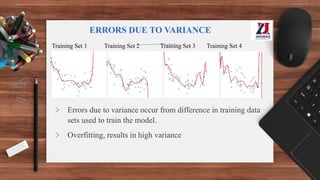
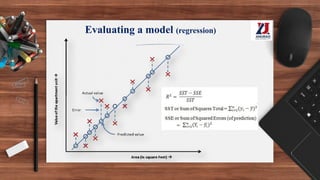
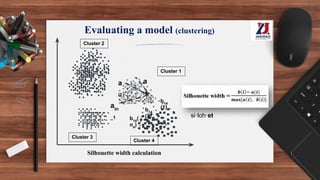
This document provides an overview of machine learning, defining it as the ability for computers to learn from experience without explicit programming. It details the evolution of machine learning from the 1950s to present, discussing various types of learning algorithms, including supervised, unsupervised, and reinforcement learning. Additionally, it outlines the machine learning process, key applications, and challenges such as overfitting and underfitting.