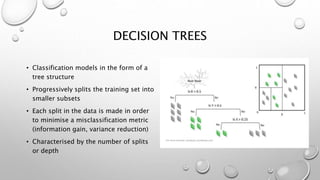
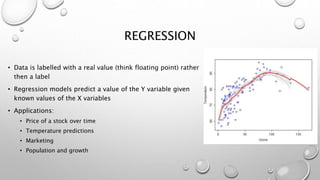
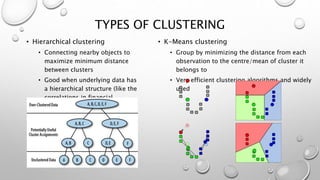
This document outlines the topics that will be covered in a machine learning algorithms workshop. The workshop sessions will cover various machine learning algorithms including classification algorithms like decision trees, random forests, and support vector machines. Regression techniques like linear regression and ridge regression will also be discussed. Additional topics that will be covered include clustering, dimensionality reduction, neural networks, and model selection and evaluation. Today's session will focus on pre-processing techniques for importing and processing data.