Download to read offline









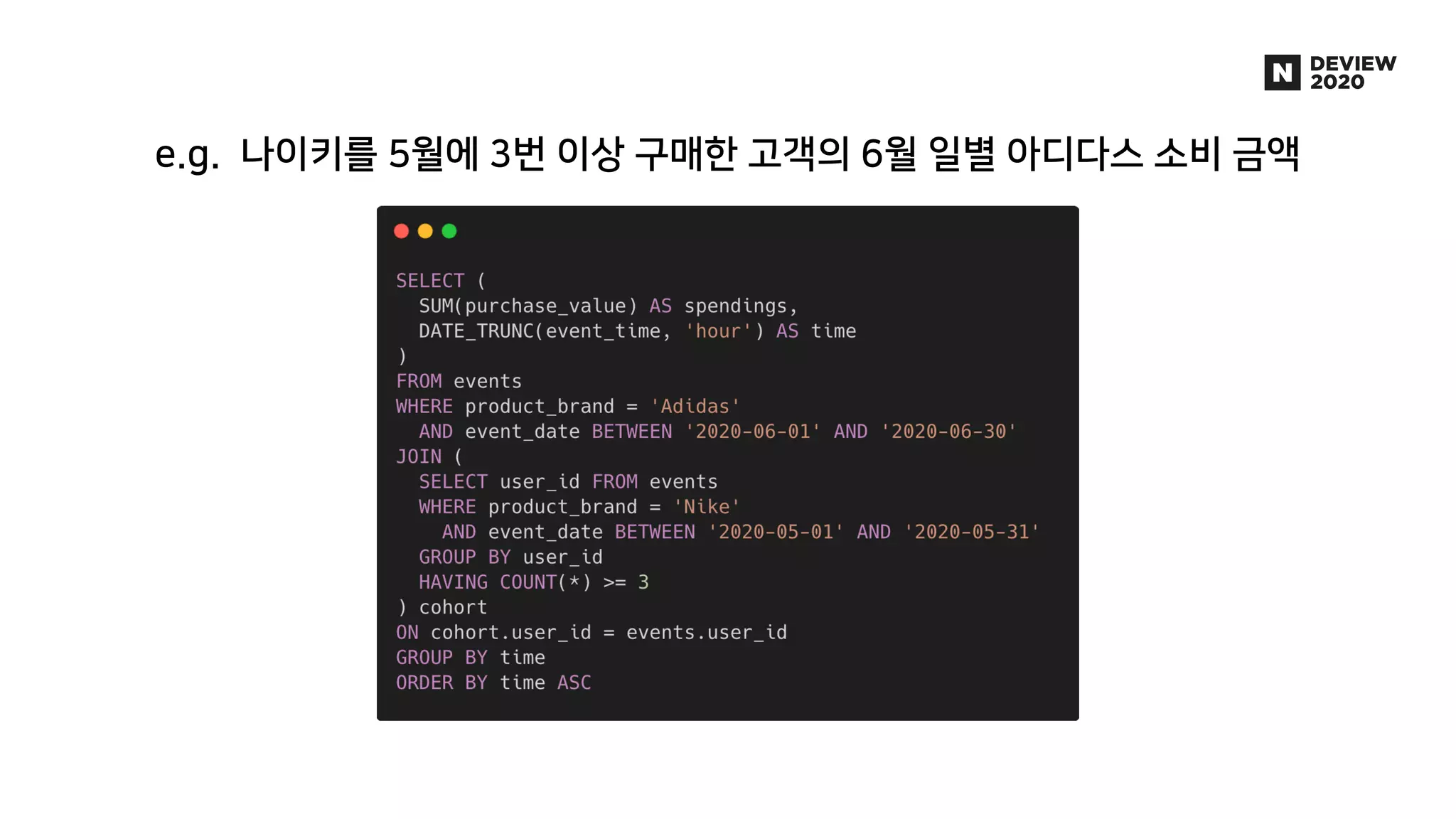









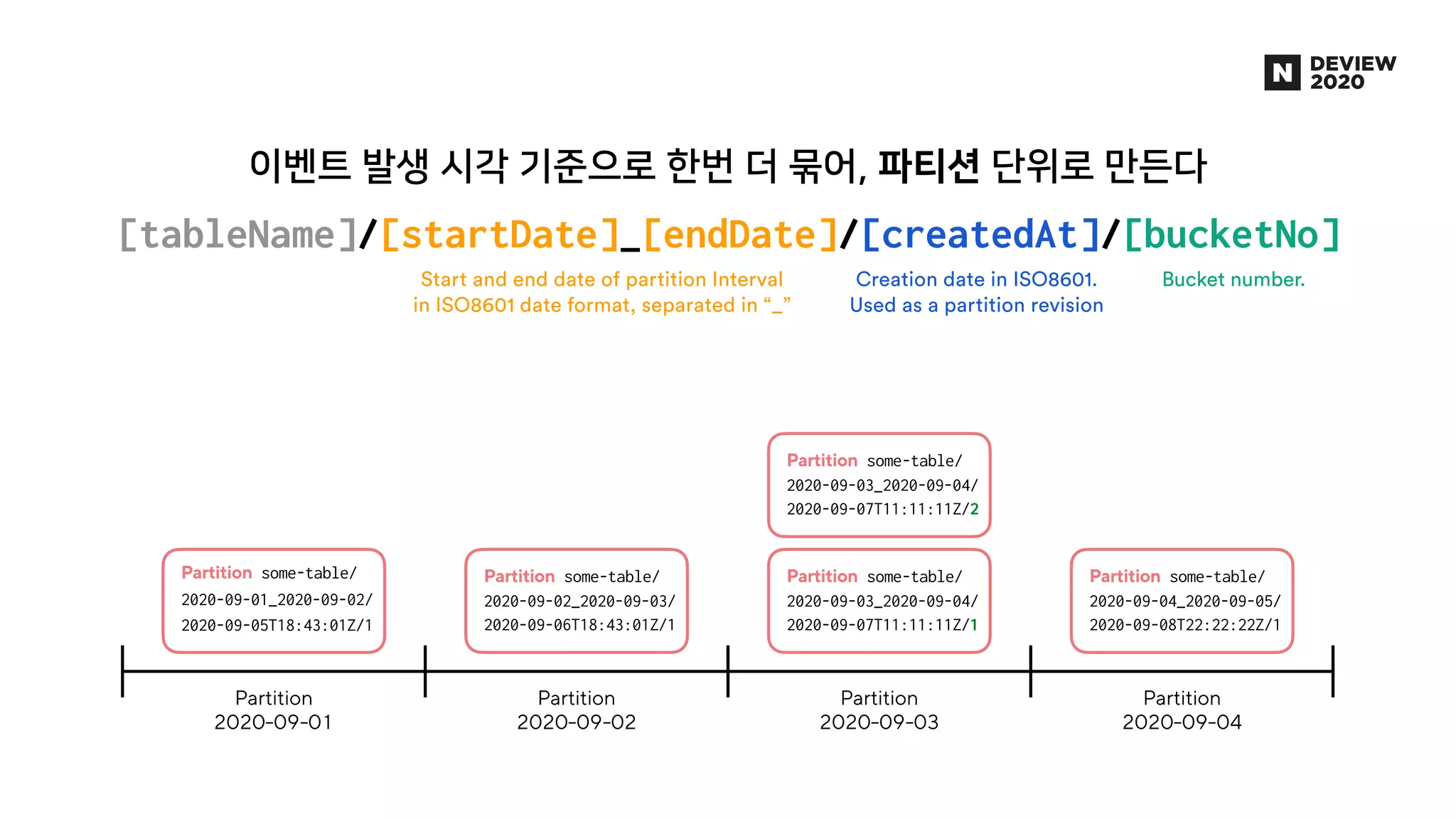
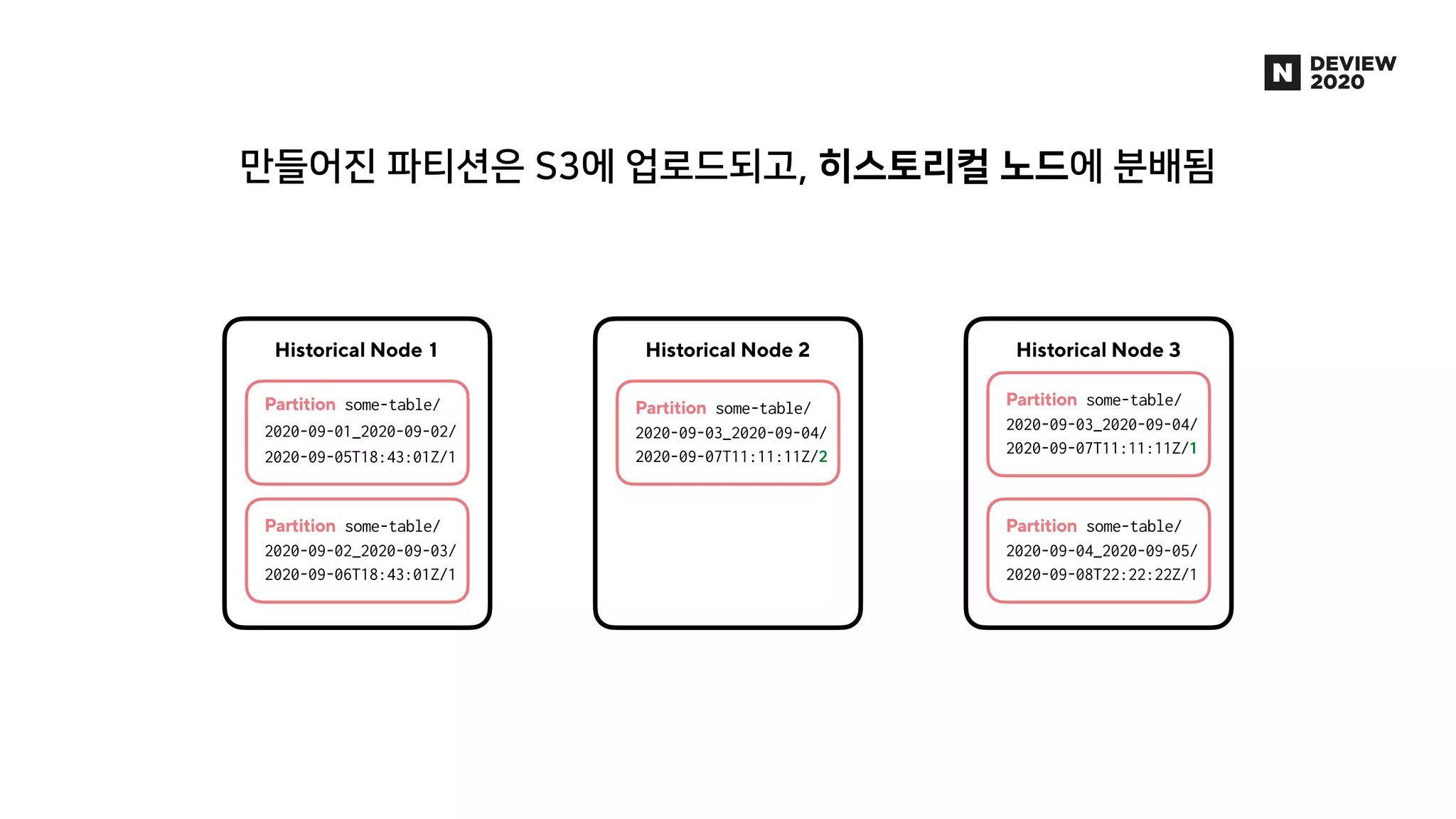






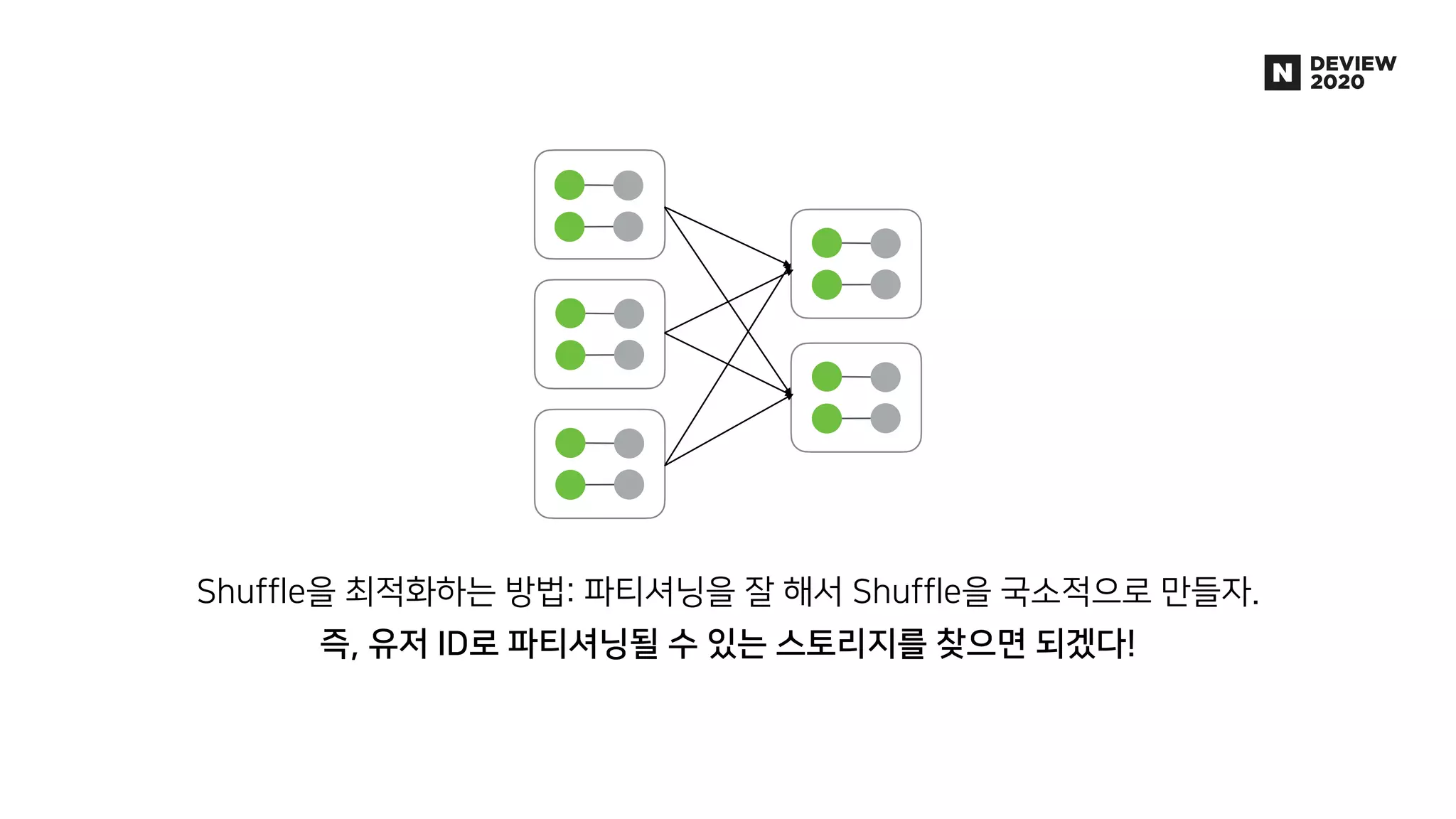





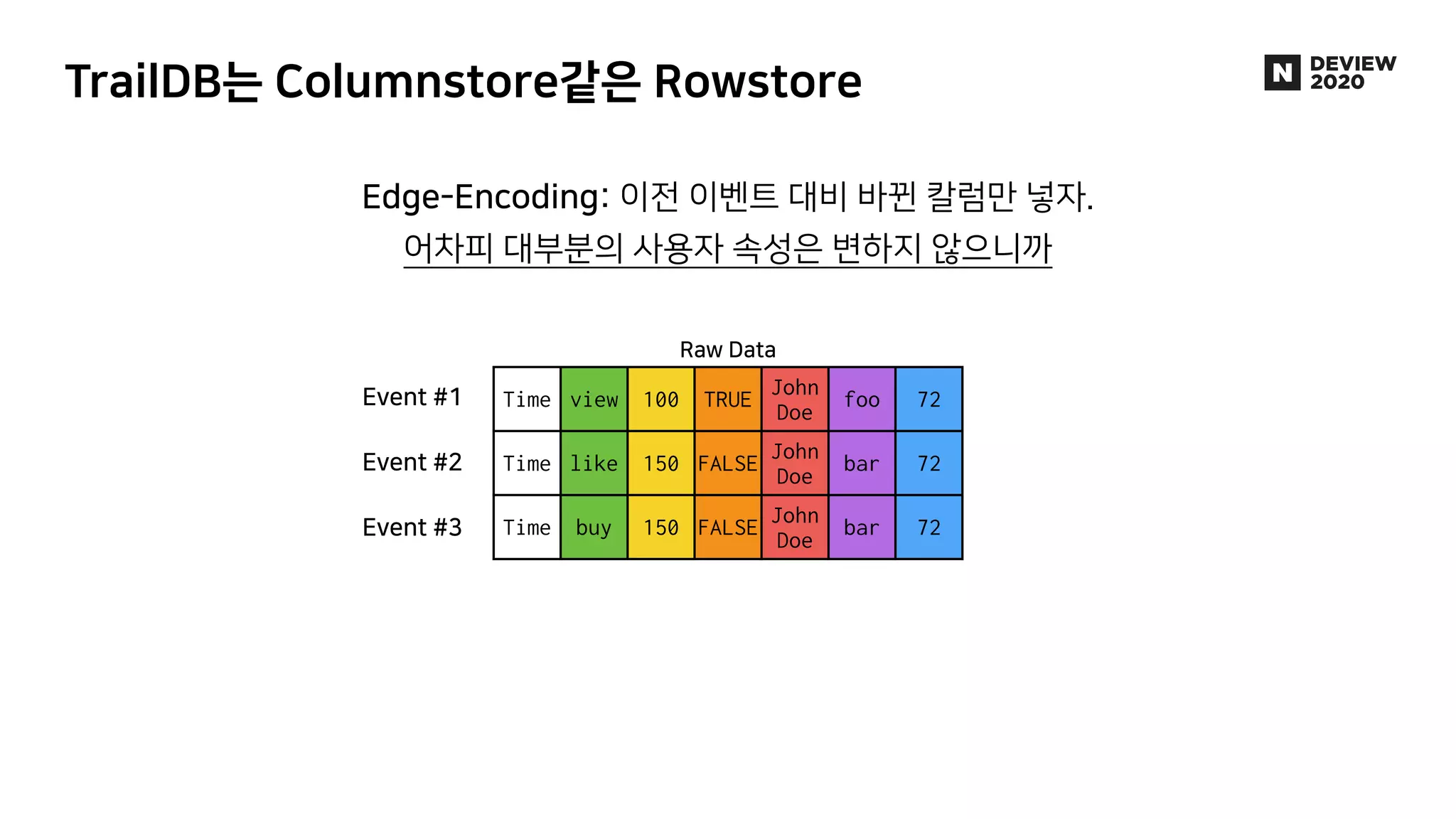















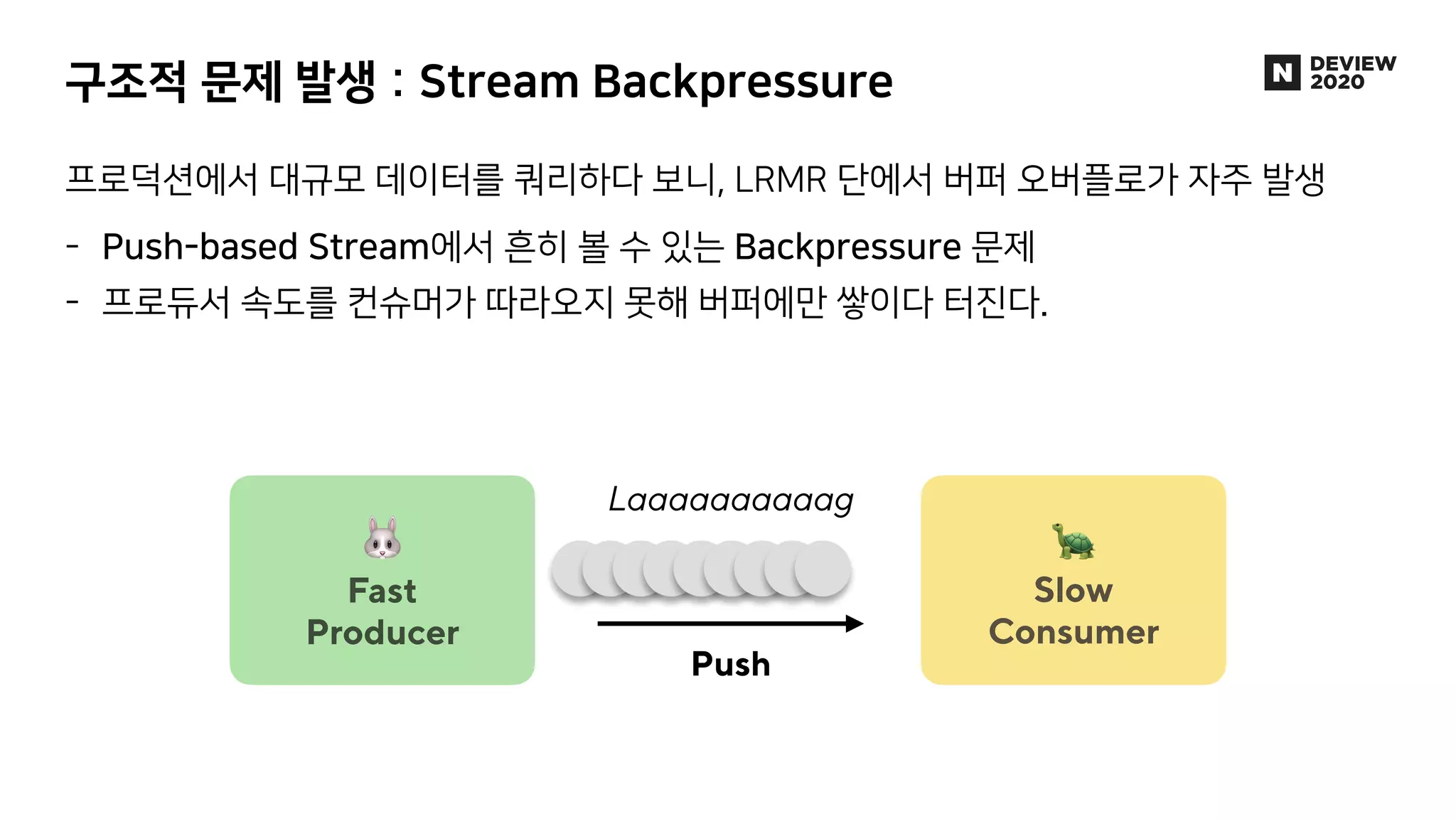















에어브릿지는 웹, 앱을 넘나드는 사용자의 유입과 행동을 파악하여 광고 성과를 측정, 분석하는 제품입니다. 월 2000만 유저로부터 들어오는 100억 건 이상의 데이터 속에서 유저 행동을 실시간으로 분석한 애널리틱스를 제공하기 위해, AB180에서는 Luft라는 행동 분석에 특화된 OLAP DB를 자체적으로 개발해 코호트 분석 기능 및 각종 애널리틱스 제공에 활용하고 있습니다. * 발표 영상: https://tv.naver.com/v/16969997 * 블로그 글: https://abit.ly/luft * 채용 페이지: https://abit.ly/recruit-database-engineer






![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)




![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[IGC 2017] 펄어비스 민경인 - Mmorpg를 위한 voxel 기반 네비게이션 라이브러리 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/mmorpgvoxel-170905061528-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] 스카우터 사용자 가이드 2020](https://cdn.slidesharecdn.com/ss_thumbnails/2020scouteruserguide-200122014357-thumbnail.jpg?width=640&height=640&fit=bounds)
![[야생의 땅: 듀랑고] 서버 아키텍처 Vol. 2 (자막)](https://cdn.slidesharecdn.com/ss_thumbnails/vol2-160427160825-thumbnail.jpg?width=640&height=640&fit=bounds)
