该文档详细介绍了Lucene的功能和应用,包括Lucene和Lucene.net的背景、全文搜索处理流程以及在布啦中的应用实例。文档还分析了索引建立与查询的具体实现及中文分词组件的选择,最后讨论了改进搜索性能的方案和近实时搜索的解决方案。通过案例展示了Lucene在实际项目中的应用效果及其面临的问题。
![Lucene实践
[lu:si:n]
陈晓锋 / GT-0](https://image.slidesharecdn.com/lucene-120105214400-phpapp01/85/Lucene-1-320.jpg)







![建立索引
static void Main(string[] args)
{
var ramDir = new RAMDirectory(); //内存存储
var analyzer = new SimpleAnalyzer(); //分析器
var writer = new IndexWriter(ramDir, analyzer, true); //创建
IndexWrite类
//加入文档
var document = new Document();
document.Add(new Field("title", "建立索引测试
", Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("content", "测试
demo", Field.Store.NO, Field.Index.ANALYZED));
writer.AddDocument(document);
//关闭IndexWrite
writer.Close();
}](https://image.slidesharecdn.com/lucene-120105214400-phpapp01/85/Lucene-9-320.jpg)



![查询索引
static void Main(string[] args)
{
var ramDir = new RAMDirectory(); //这里假设是之前写入内容的内存对象
var analyzer = new SimpleAnalyzer(); //分析器
IndexReader reader = IndexReader.Open(ramDir);
IndexSearcher searcher = new IndexSearcher(reader); //创建IndexSearcher
QueryParser parser = new QueryParser(Version.LUCENE_29,
"title", analyzer);
Query query = parser.Parse("测试");
Hits hits = searcher.Search(query); //搜索
//输出结果
for (int i = 0; i < hits.Length(); i++)
{
Document doc = hits.Doc(i);
Console.WriteLine(string.Format("title:{0}", doc.Get("title")));
}
//关闭搜索
searcher.Close();](https://image.slidesharecdn.com/lucene-120105214400-phpapp01/85/Lucene-13-320.jpg)






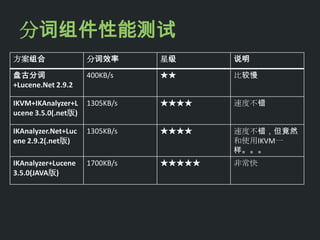
























































![Lucene 3[1] 0 原理与代码分析](https://cdn.slidesharecdn.com/ss_thumbnails/lucene31-0-100225194736-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





