Download as PDF, PPTX






















![Analytics
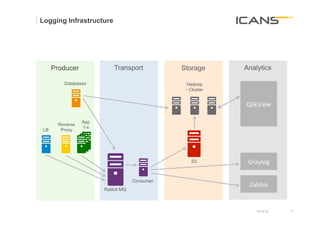
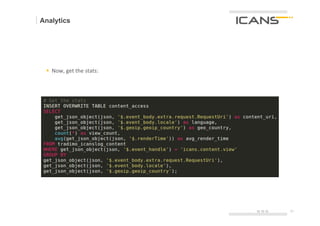
§ Cascalog is Clojure, Clojure is Lisp
(?<- (stdout) [?person] (age ?person ?age) … (< ?age 30))
Query Cascading Columns of „Generator“ „Predicate“
Operator Output Tap the dataset
generated
by the query
§ as many as you want
§ both can be any clojure function
§ clojure can call anything that is
available within a JVM
15.10.12 25
25](https://image.slidesharecdn.com/log-everything-stefan-schadwinkel-mike-lohmann-121016043619-phpapp02/85/Log-everything-25-320.jpg)
![Analytics
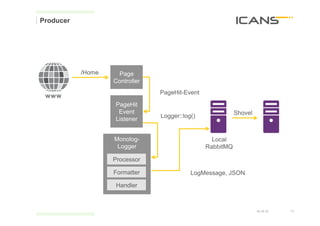
§ Let‘s run the Cascalog processing on Amazon EMR:
./elastic-mapreduce --create --name „Log Message Compaction"
--bootstrap-action s3://[BUCKET]/mapreduce/configure-daemons
--num-instances $NUM
--slave-instance-type m1.large
--master-instance-type m1.large
--jar s3://[BUCKET]/mapreduce/compaction/icans-cascalog.jar
--step-action TERMINATE_JOB_FLOW
--step-name "Cascalog"
--main-class icans.cascalogjobs.processing.compaction
--args "s3://[BUCKET]/incoming/*/*/*/","s3://[BUCKET]/icanslog","s3://[BUCKET]/icanslog-error
15.10.12 27
27](https://image.slidesharecdn.com/log-everything-stefan-schadwinkel-mike-lohmann-121016043619-phpapp02/85/Log-everything-27-320.jpg)
![Analytics
§ After the Cascalog Query we have:
s3://[BUCKET]/icanslog/[WEBSITE]/icans.content/year=2012/month=10/day=01/part-00000.lzo
Hive
ParSSoning!
15.10.12 28
28](https://image.slidesharecdn.com/log-everything-stefan-schadwinkel-mike-lohmann-121016043619-phpapp02/85/Log-everything-28-320.jpg)
![Analytics
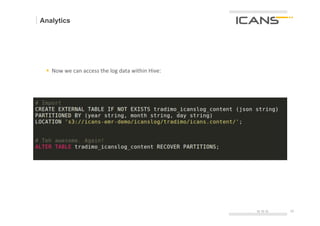
§ Now
we
can
run
Hive
queries
on
the
[WEBSITE]_icanslog_content
table!
§ But
we
also
want
to
store
the
result
to
S3.
15.10.12 30
30](https://image.slidesharecdn.com/log-everything-stefan-schadwinkel-mike-lohmann-121016043619-phpapp02/85/Log-everything-30-320.jpg)






The document outlines the logging framework developed by icans GmbH, led by Dr. Stefan Schadwinkel and Mike Lohmann, which focuses on gathering and analyzing data from educational web applications, particularly in the context of poker teaching. It discusses the infrastructure, technologies, and strategies employed to log vast amounts of data, employing tools like Amazon S3 and Hadoop for scalable storage and analytics. The goal is to enhance business decision-making driven by complex data analytics and ensure user satisfaction by providing timely answers to their queries.



























