Download to read offline







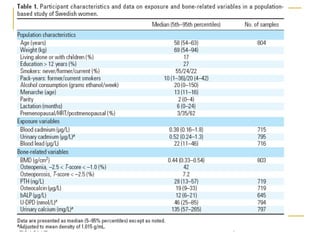
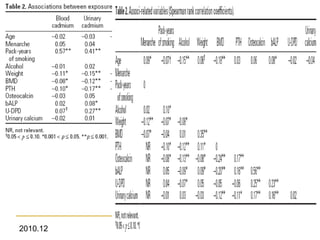
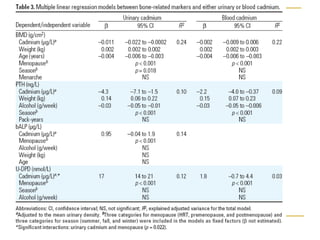


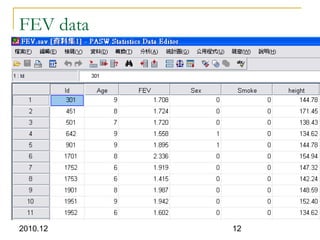

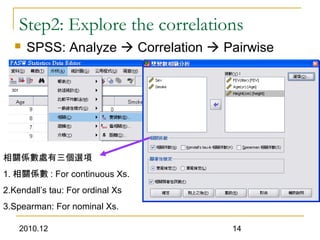

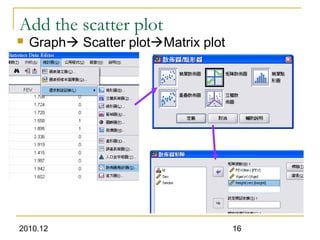



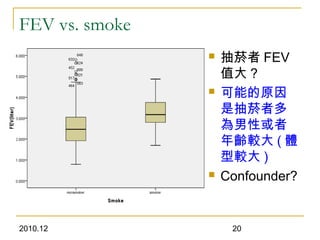



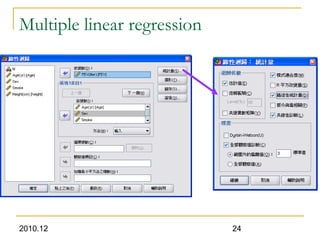




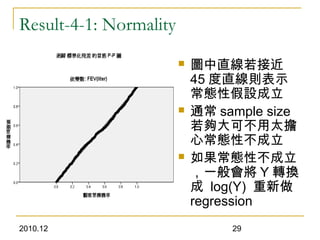
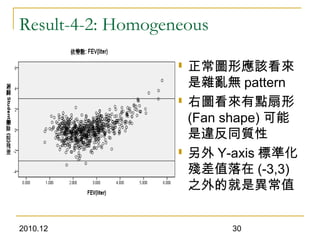


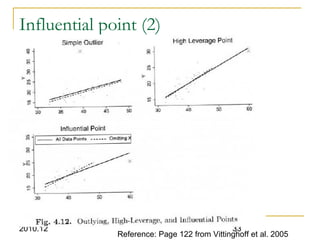








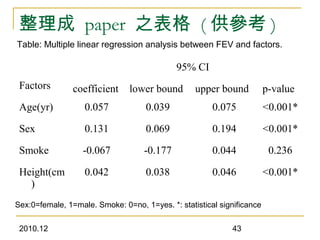

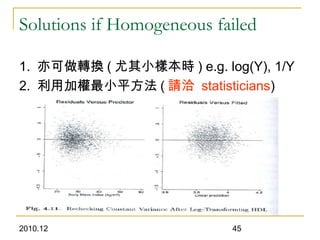

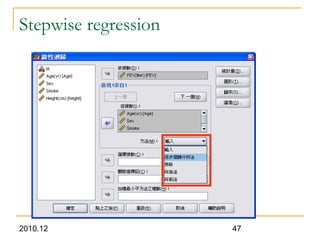



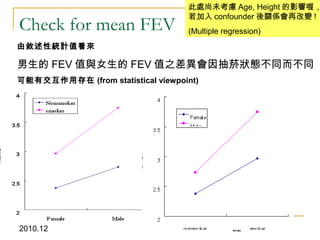

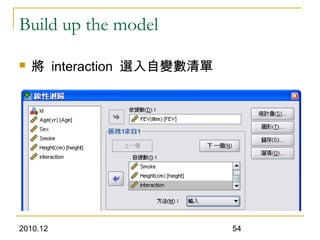

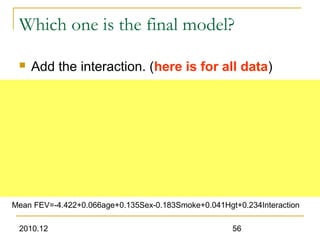





This document discusses using linear regression analysis to explore relationships between variables. It provides an example of using regression to study the relationship between bone mineral density (BMD) and risk factors like menopause and diet. Multiple linear regression allows considering relationships while adjusting for potential confounding factors. The document outlines steps for correlation analysis, building regression models, and checking assumptions. It provides an example analysis of factors related to lung function (FEV) using these steps.


































