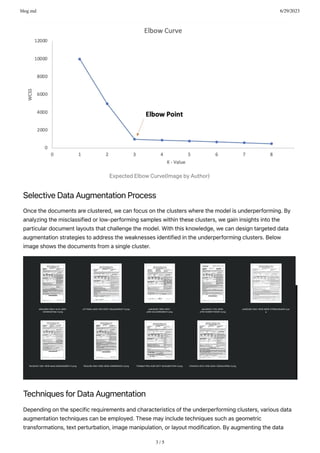
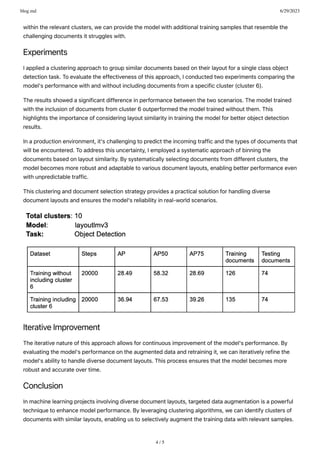
This document discusses leveraging clustering techniques for document layout analysis in machine learning projects. It describes how clustering can help group similar documents based on their layout characteristics in order to identify clusters of documents that challenge models. Targeted data augmentation can then selectively augment training data from underperforming clusters to improve model performance on diverse document layouts through iterative training. Experiments showed that including documents from a specific cluster improved model performance for an object detection task compared to excluding them.