Download as PDF, PPTX






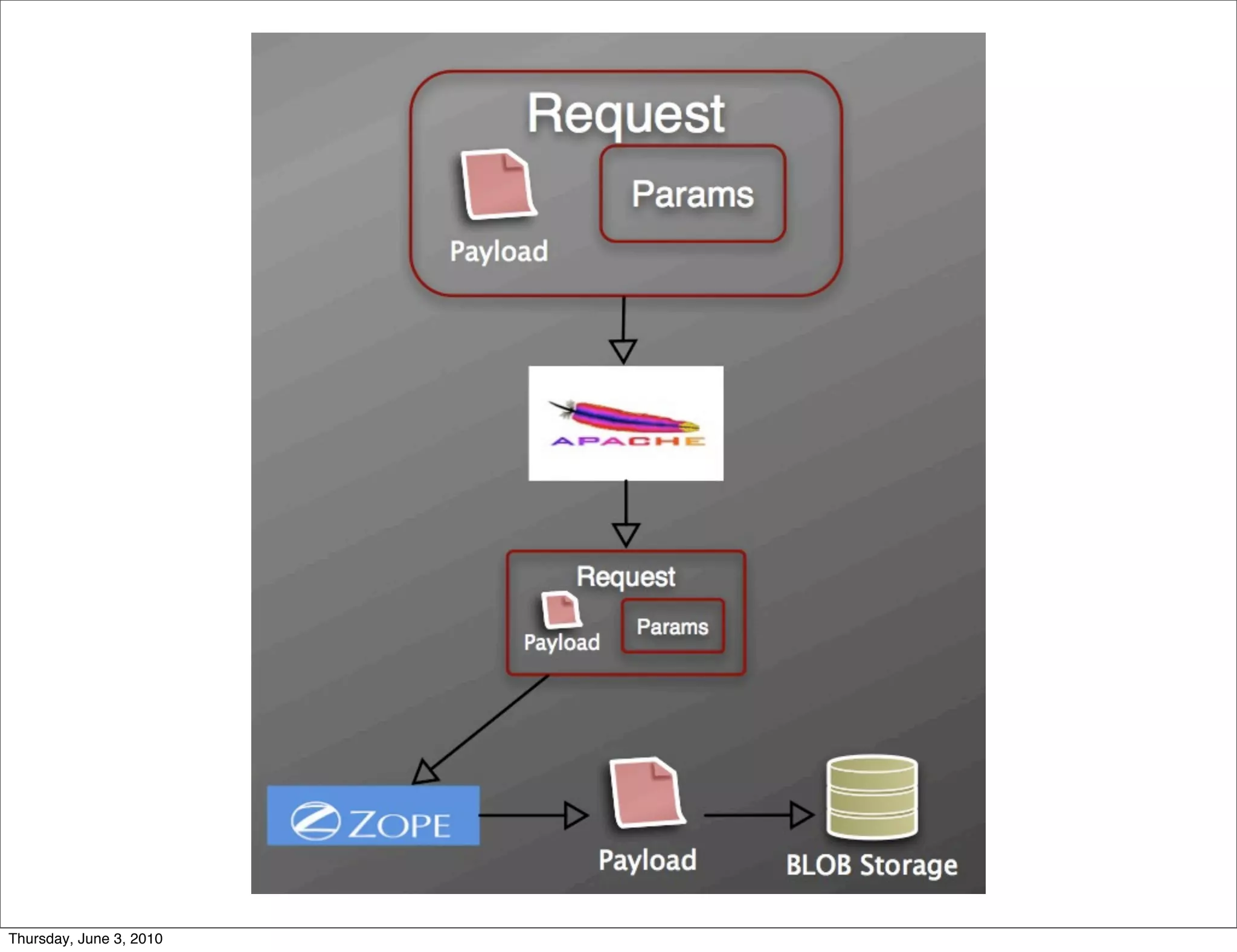





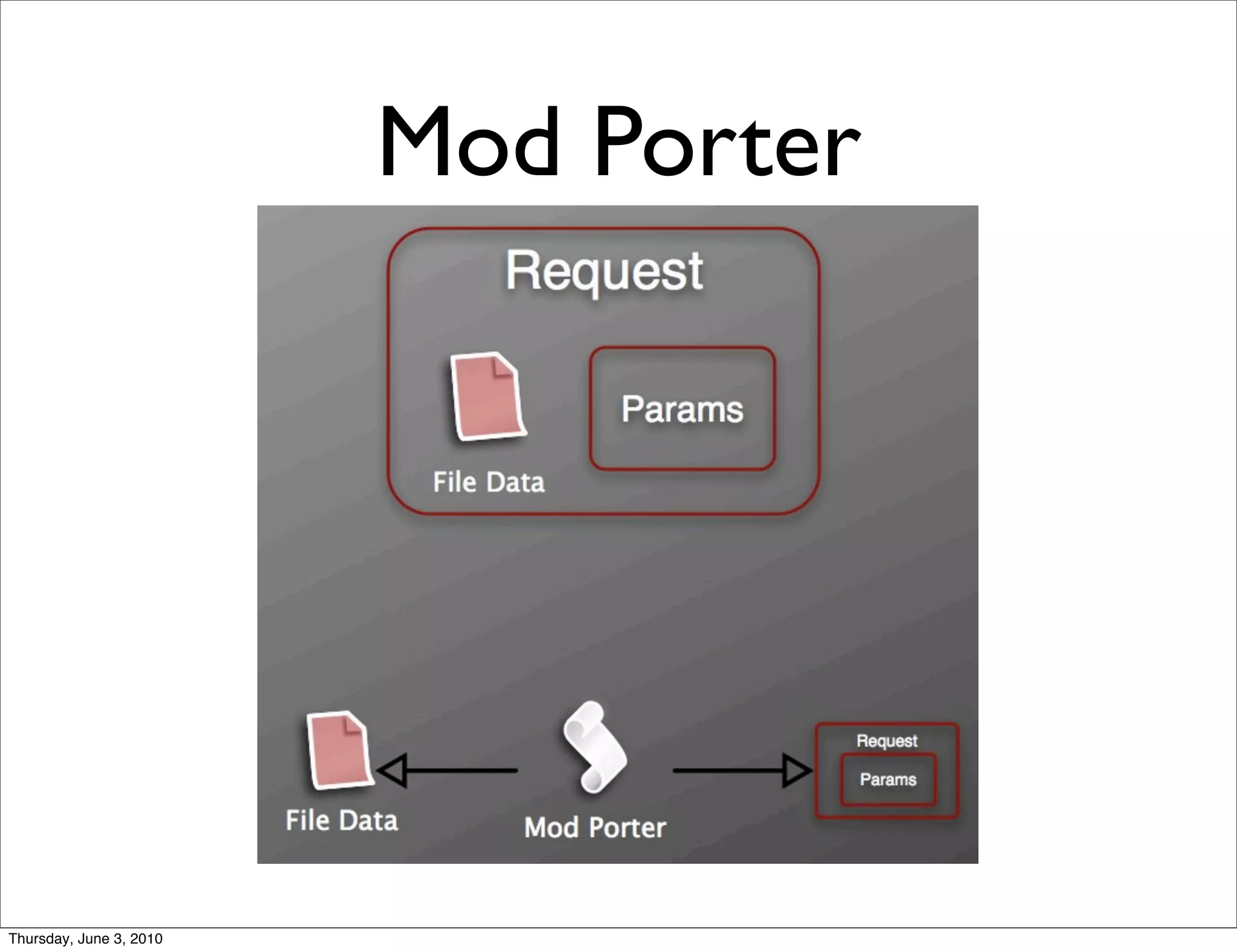





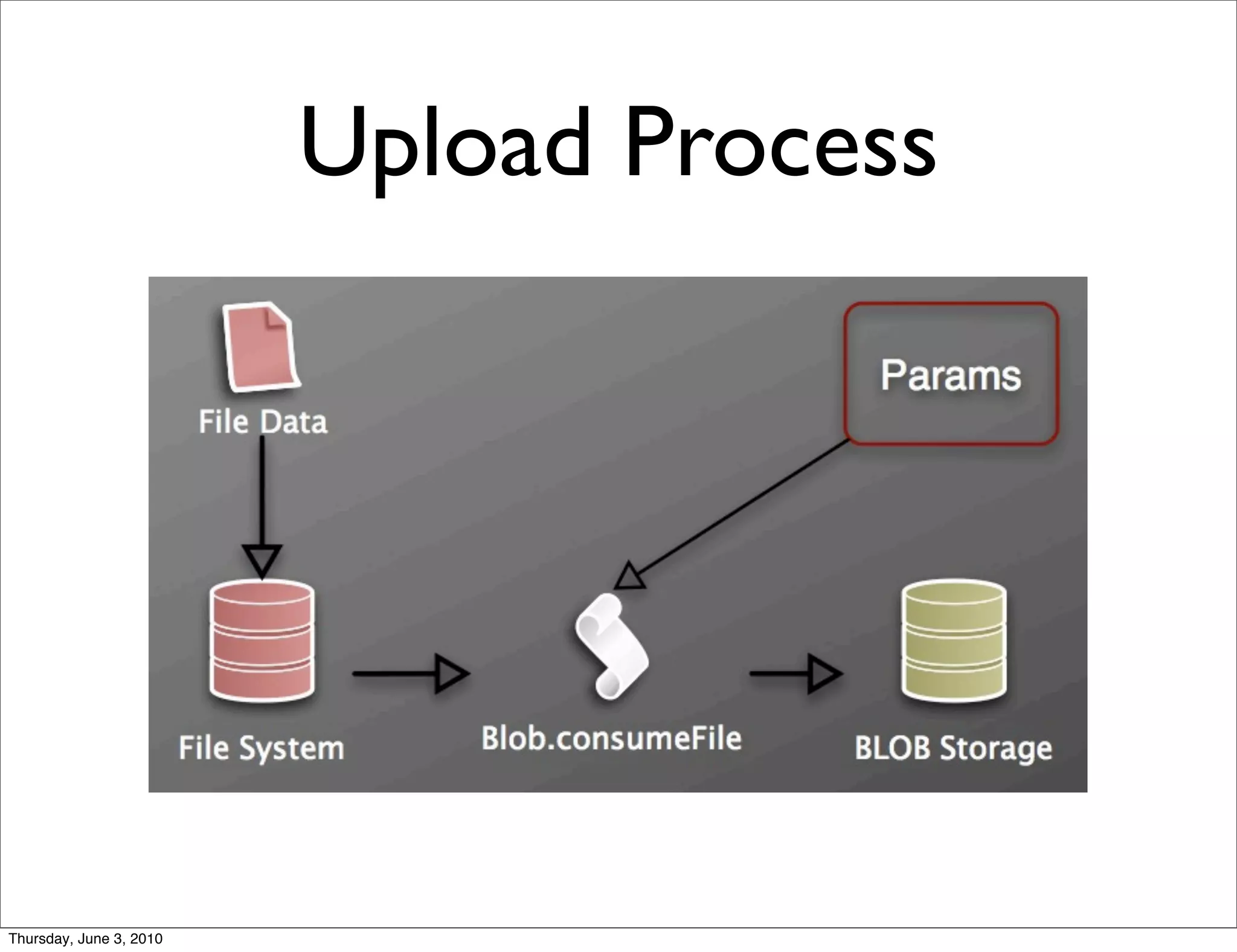

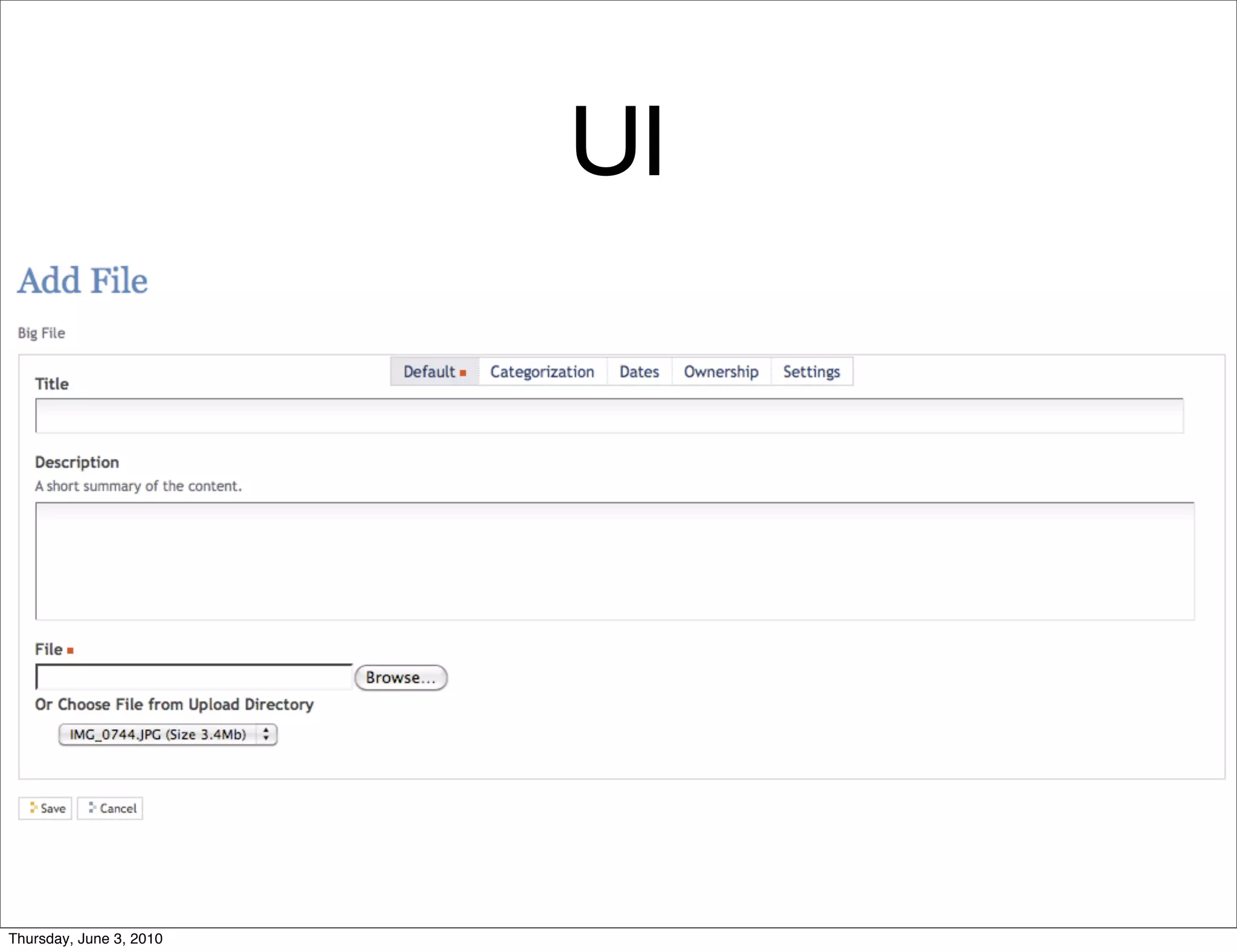
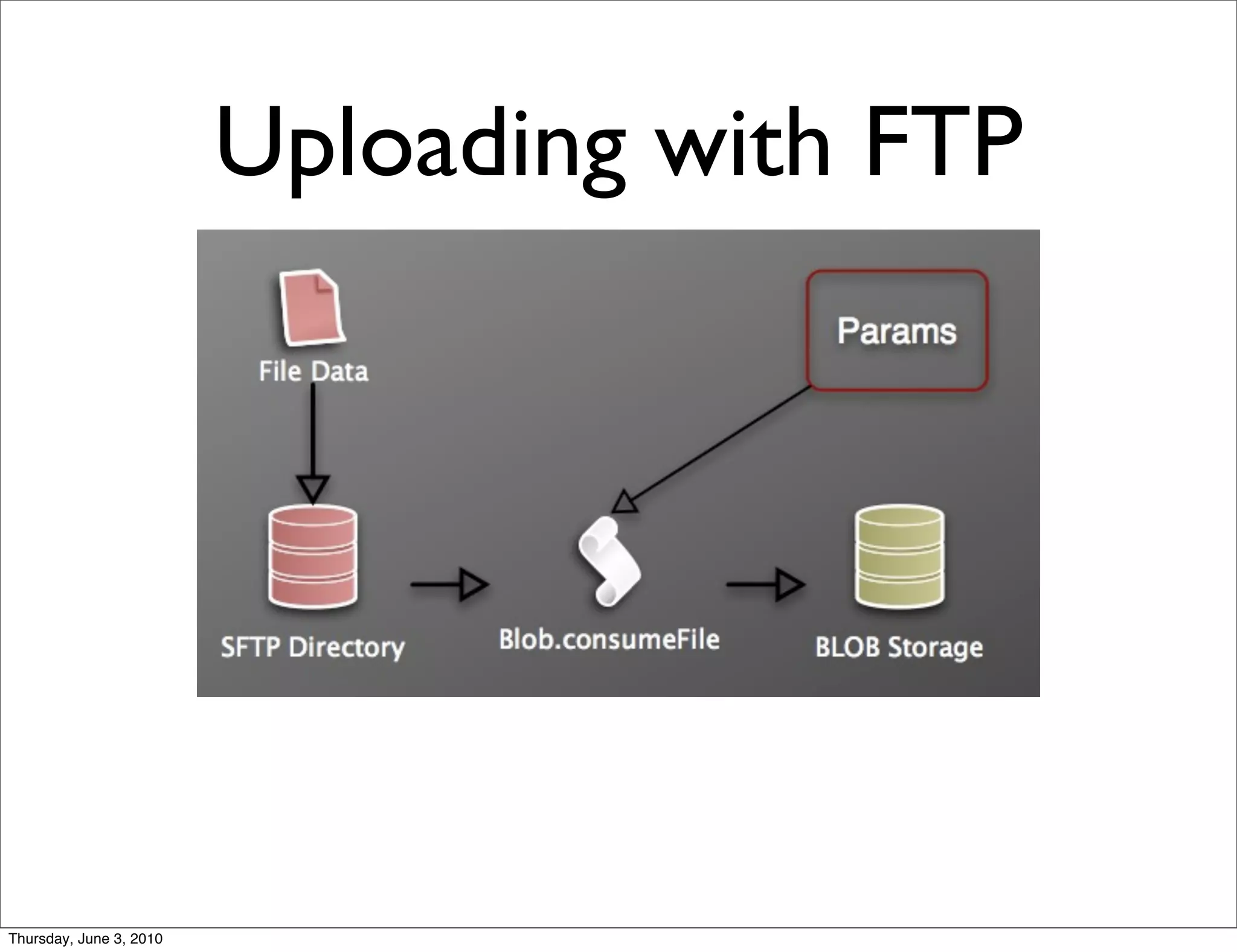




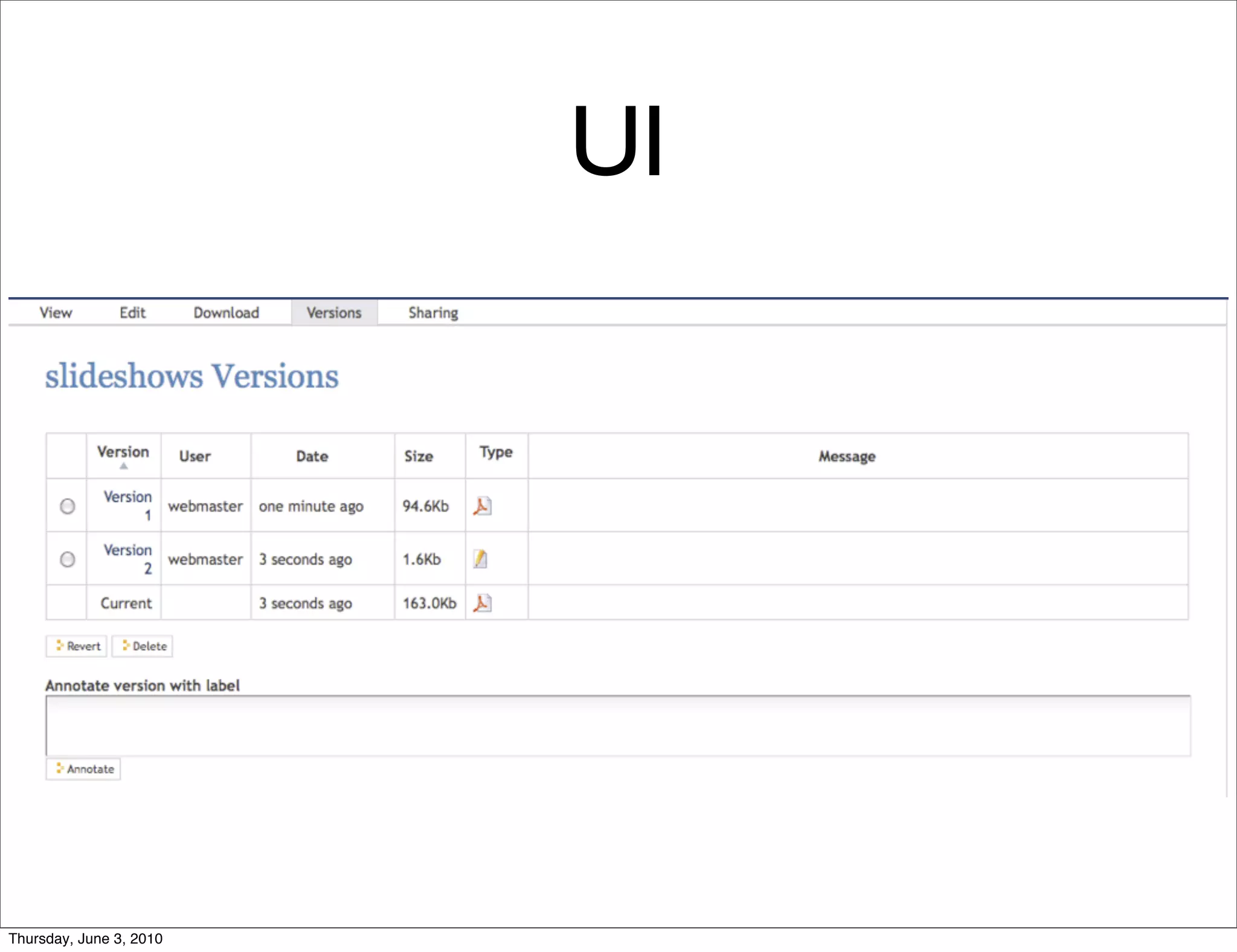



The document discusses the challenges of handling large files in Plone, highlighting issues with uploading, downloading, and versioning. It introduces solutions such as using Apache for file streaming and implementing the ore.bigfile content type to manage big files effectively. The conclusion emphasizes that while ore.bigfile addresses specific use cases, it leverages existing web server technology for improved performance.




















![Chef in the cloud [dbccg]](https://cdn.slidesharecdn.com/ss_thumbnails/chefinthecloud-dbccg-100927223008-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)





