Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Masaru Oki
PDF, PPTX
2,443 views
Lagopus performance
About Lagopus openflow switch fast-speed lookup development. (in Japanese)
Technology
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 26
2
/ 26
3
/ 26
4
/ 26
5
/ 26
6
/ 26
7
/ 26
8
/ 26
9
/ 26
10
/ 26
11
/ 26
12
/ 26
13
/ 26
14
/ 26
15
/ 26
16
/ 26
17
/ 26
18
/ 26
19
/ 26
20
/ 26
21
/ 26
22
/ 26
23
/ 26
24
/ 26
25
/ 26
26
/ 26
More Related Content
PDF
Lagopus, raw socket build
by
Masaru Oki
PDF
Open stack+lagopus できるかな
by
Masaru Oki
PDF
Lagopus Switch Usecases
by
Sakiko Kawai
PDF
Ryu+Lagopusで OpenFlowの動きを見てみよう
by
Masaru Oki
PDF
Open flow tunnel extension on lagopus vswitch
by
Masaru Oki
PDF
Xeon dとlagopusと、pktgen dpdk
by
Masaru Oki
PDF
Lagopus どれだけ速いのか
by
Masaru Oki
PDF
SDNソフトウェアスイッチlagopus for FreeBSD
by
Masaru Oki
Lagopus, raw socket build
by
Masaru Oki
Open stack+lagopus できるかな
by
Masaru Oki
Lagopus Switch Usecases
by
Sakiko Kawai
Ryu+Lagopusで OpenFlowの動きを見てみよう
by
Masaru Oki
Open flow tunnel extension on lagopus vswitch
by
Masaru Oki
Xeon dとlagopusと、pktgen dpdk
by
Masaru Oki
Lagopus どれだけ速いのか
by
Masaru Oki
SDNソフトウェアスイッチlagopus for FreeBSD
by
Masaru Oki
What's hot
PDF
LagopusでPPPoEを使えるか考えてみた件
by
Masaru Oki
PDF
Lagopus as open flow hybrid switch 実践編
by
Masaru Oki
PDF
OpenFlowでいろんなプロトコルを 話そうとするとどうなるか
by
Masaru Oki
PDF
Lagopus 0.2.2
by
Masaru Oki
PDF
Lagopus as open flow hybrid switch
by
Masaru Oki
PDF
Lagopus 0.2
by
Masaru Oki
PDF
DPDK QoS
by
Masaru Oki
PDF
DPDKを用いたネットワークスタック,高性能通信基盤開発
by
slankdev
PDF
High Performance Networking with DPDK & Multi/Many Core
by
slankdev
PDF
hpingで作るパケット
by
Takaaki Hoyo
PDF
Rust-DPDK
by
Masaru Oki
PDF
Lagopus + DockerのDPDK接続
by
Tomoya Hibi
PDF
FreeBSD jail+vnetと戯れた話
by
Masaru Oki
PPTX
nftables: the Next Generation Firewall in Linux
by
Tomofumi Hayashi
PDF
Lagopus.confの書式(for lagopus 0.1.x)
by
Masaru Oki
PDF
Lagos running on small factor machine
by
Lagopus SDN/OpenFlow switch
PPTX
Wiresharkの解析プラグインを作る ssmjp 201409
by
稔 小林
PDF
Dpdk pmd
by
Masaru Oki
PDF
about Tcpreplay
by
@ otsuka752
ODP
tcpdumpとtcpreplayとtcprewriteと他。
by
(^-^) togakushi
LagopusでPPPoEを使えるか考えてみた件
by
Masaru Oki
Lagopus as open flow hybrid switch 実践編
by
Masaru Oki
OpenFlowでいろんなプロトコルを 話そうとするとどうなるか
by
Masaru Oki
Lagopus 0.2.2
by
Masaru Oki
Lagopus as open flow hybrid switch
by
Masaru Oki
Lagopus 0.2
by
Masaru Oki
DPDK QoS
by
Masaru Oki
DPDKを用いたネットワークスタック,高性能通信基盤開発
by
slankdev
High Performance Networking with DPDK & Multi/Many Core
by
slankdev
hpingで作るパケット
by
Takaaki Hoyo
Rust-DPDK
by
Masaru Oki
Lagopus + DockerのDPDK接続
by
Tomoya Hibi
FreeBSD jail+vnetと戯れた話
by
Masaru Oki
nftables: the Next Generation Firewall in Linux
by
Tomofumi Hayashi
Lagopus.confの書式(for lagopus 0.1.x)
by
Masaru Oki
Lagos running on small factor machine
by
Lagopus SDN/OpenFlow switch
Wiresharkの解析プラグインを作る ssmjp 201409
by
稔 小林
Dpdk pmd
by
Masaru Oki
about Tcpreplay
by
@ otsuka752
tcpdumpとtcpreplayとtcprewriteと他。
by
(^-^) togakushi
Similar to Lagopus performance
PPTX
Lagopus workshop@Internet weekのそば
by
Yoshihiro Nakajima
PPTX
ネットワークプログラマビリティ勉強会
by
Tomoya Hibi
PDF
Bird in show_net
by
Tomoya Hibi
PDF
Lagopus Router v19.07.1
by
Tomoya Hibi
PDF
Osc2018tokyo spring-20180224
by
Tomoya Hibi
PDF
[D20] 高速Software Switch/Router 開発から得られた高性能ソフトウェアルータ・スイッチ活用の知見 (July Tech Fest...
by
Tomoya Hibi
PDF
FPGAで作るOpenFlow Switch (FPGAエクストリーム・コンピューティング 第6回) FPGAX#6
by
Kentaro Ebisawa
PDF
Lagopusで試すFirewall
by
Tomoya Hibi
PDF
RouterBOARD with OpenFlow
by
Toshiki Tsuboi
PDF
Lagopus & NFV with Vhost (Tremaday#9)
by
Tomoya Hibi
PDF
Lagopus Router
by
Tomoya Hibi
PDF
仮想ネットワークを実現するOpenVNet
by
Akira Yokokawa
PDF
話題のOpenFlowをフル活用! OpenVNetで仮想ネットワークを実現しよう!
by
Akira Yokokawa
PDF
Lagopus Project (Open Source Conference)
by
Tomoya Hibi
PDF
Lagopusで試すFW
by
Tomoya Hibi
PPTX
OpenFlow OAM ツール - OKINAWA Open Days 2014 Day1
by
Satoshi KOBAYASHI
PDF
新生Lagopus2017(仮称)
by
Masaru Oki
PDF
SDN Japan: ovs-hw
by
ykuga
PDF
Lagopusで試すL3ルーティング + α (Lagopusの設定方法いろいろ)
by
Tomoya Hibi
PDF
OpenFlow in Raspberry Pi
by
Toshiki Tsuboi
Lagopus workshop@Internet weekのそば
by
Yoshihiro Nakajima
ネットワークプログラマビリティ勉強会
by
Tomoya Hibi
Bird in show_net
by
Tomoya Hibi
Lagopus Router v19.07.1
by
Tomoya Hibi
Osc2018tokyo spring-20180224
by
Tomoya Hibi
[D20] 高速Software Switch/Router 開発から得られた高性能ソフトウェアルータ・スイッチ活用の知見 (July Tech Fest...
by
Tomoya Hibi
FPGAで作るOpenFlow Switch (FPGAエクストリーム・コンピューティング 第6回) FPGAX#6
by
Kentaro Ebisawa
Lagopusで試すFirewall
by
Tomoya Hibi
RouterBOARD with OpenFlow
by
Toshiki Tsuboi
Lagopus & NFV with Vhost (Tremaday#9)
by
Tomoya Hibi
Lagopus Router
by
Tomoya Hibi
仮想ネットワークを実現するOpenVNet
by
Akira Yokokawa
話題のOpenFlowをフル活用! OpenVNetで仮想ネットワークを実現しよう!
by
Akira Yokokawa
Lagopus Project (Open Source Conference)
by
Tomoya Hibi
Lagopusで試すFW
by
Tomoya Hibi
OpenFlow OAM ツール - OKINAWA Open Days 2014 Day1
by
Satoshi KOBAYASHI
新生Lagopus2017(仮称)
by
Masaru Oki
SDN Japan: ovs-hw
by
ykuga
Lagopusで試すL3ルーティング + α (Lagopusの設定方法いろいろ)
by
Tomoya Hibi
OpenFlow in Raspberry Pi
by
Toshiki Tsuboi
More from Masaru Oki
PDF
NetBSD移植の昔話
by
Masaru Oki
PDF
Rust-DPDK
by
Masaru Oki
PDF
Lagopusとvagrant
by
Masaru Oki
PDF
今よりも少し(?)昔、 Windowsを作ろうとした話
by
Masaru Oki
PDF
Onieで遊んでみようとした話
by
Masaru Oki
PDF
GPD WINが来た!
by
Masaru Oki
PDF
Lagopus 0.2.7
by
Masaru Oki
PDF
Lagopus match improvements
by
Masaru Oki
PDF
Lagopus 0.2.4
by
Masaru Oki
PDF
Net bsd advent calendar 2015 bpf
by
Masaru Oki
PDF
Using rump on NetBSD 7.0
by
Masaru Oki
PDF
Rumpを使ってみる
by
Masaru Oki
PDF
Running lagopus on Xeon D
by
Masaru Oki
PDF
Using Xeon D 10GBase-T
by
Masaru Oki
NetBSD移植の昔話
by
Masaru Oki
Rust-DPDK
by
Masaru Oki
Lagopusとvagrant
by
Masaru Oki
今よりも少し(?)昔、 Windowsを作ろうとした話
by
Masaru Oki
Onieで遊んでみようとした話
by
Masaru Oki
GPD WINが来た!
by
Masaru Oki
Lagopus 0.2.7
by
Masaru Oki
Lagopus match improvements
by
Masaru Oki
Lagopus 0.2.4
by
Masaru Oki
Net bsd advent calendar 2015 bpf
by
Masaru Oki
Using rump on NetBSD 7.0
by
Masaru Oki
Rumpを使ってみる
by
Masaru Oki
Running lagopus on Xeon D
by
Masaru Oki
Using Xeon D 10GBase-T
by
Masaru Oki
Lagopus performance
1.
Lagopusの性能の話 Apr 25, 2015 Masaru
OKI @masaru0714
2.
● OpenFlow対応ソフトウェアスイッチです ● (もちろん)オープンソースです ○
http://lagopus.github.io ● よく言われている特徴 ○ x86 Linuxで動きます ○ DPDKを使っていて、内部の工夫もあり速いです ○ マルチコア・マルチスレッドで動作します ○ OpenFlowの仕様のカバー範囲が大きいです Lagopusとは(おさらい)
3.
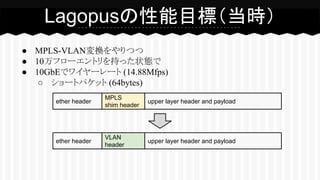
● MPLS-VLAN変換をやりつつ ● 10万フローエントリを持った状態で ●
10GbEでワイヤーレート (14.88Mfps) ○ ショートパケット (64bytes) Lagopusの性能目標(当時) ether header MPLS shim header upper layer header and payload ether header VLAN header upper layer header and payload
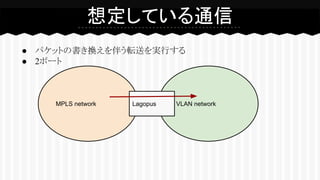
4.
● パケットの書き換えを伴う転送を実行する ● 2ポート 想定している通信 MPLS
network VLAN networkLagopus
5.
ざっくり一言でいえば、ユーザスペースでパケット読み書きするライブラリ ● コピーを(なるべく)しない ● コンテキストスイッチさせない ●
メモリフォールトを起こさない ● 割り込み駆動させない ● キャッシュ活用、SSE命令活用 ● マルチコア活用、NUMAアーキテクチャを意識 予備調査 サンプルプログラム example/l2fwd にてショートパケット転送 →10GbEワイヤーレート出ました I/O性能: DPDK
6.
● ソフトウェアで処理する以上、基本的に ○ なるだけメモリアクセスしない ○
メモリコピーもなるだけ避ける ○ コードも小さく実行ステップ数を少なく ○ 余計な処理を削る ● などすれば、それらをしない場合と比較して、速くなる。 ● もちろん、本当に必要な処理を省いて速くしても意味はない。 OpenFlow処理性能
7.
● OpenFlowでは特定の通信1本を「フロー」と呼んでいる ○ たとえばPC-AがServer-Bに80/tcpの通信をするパケット ○
たとえば任意ホストがServer-Cに53/udpの通信をするパケット ○ 折り返し(たとえば上記パケットの応答)も別フローという勘定 ● OpenFlowスイッチは、パケットヘッダを見てフローを選別し処理する ○ 処理: パケットヘッダの書き換え、指定ポートへのパケット送信 ● ひとつのフローを選別(match)する設定をフローエントリと呼ぶ ○ これらが登録された塊をフローテーブルと呼ぶ ● OpenFlow処理対象のパケットは、一つのフローエントリにのみmatch フローエントリ・フローテーブル
8.
● 10万フローエントリ=10万種類のmatch ○ 今回の想定では1方向(折り返し方向のパケットは考えない) 10万フローエントリ entry
# 優先順位 match action counter 1 1 マッチ条件1 処理1 2 1 マッチ条件2 処理2 : 100,000 1 マッチ条件100,000 処理100,000
9.
matchの部分だけ抜粋したもの ※実際のOpenFlowプロトコルは下記をバイナリエンコードしている in_port=1,eth_dst=00:00:00:00:00:00,eth_type=0x8847,mpls_label=0, in_port=1,eth_dst=00:00:00:00:00:00,eth_type=0x8847,mpls_label=1, in_port=1,eth_dst=00:00:00:00:00:00,eth_type=0x8847,mpls_label=2, : : in_port=1,eth_dst=00:00:00:00:00:00,eth_type=0x8847,mpls_label=99999, 使用したフローエントリ MPLSの eth_type label指定を 10万種類
10.
● 1秒間に1488万パケットを転送 ● 1パケットあたりの所要時間:
1/14.88M=67.2nsec ● 2GHz CPUでは134クロック ● 3GHz CPUでは201クロック 14.88Mfps
11.
● Intel DPDKという速いパケットI/Oライブラリがある ●
Lookup(match)とactionがどのくらいの速さか測ってみて考える ● まず愚直にエントリ1にmatch?→エントリ2に…というものを作る ○ 末尾のエントリでは遅くなるという予想は簡単にできる ● 1コアで、受信-OpenFlow処理-送信を連続実行(1スレッド) Lagopusプロトタイプ1st 受信 match action 送信コア1 10万エントリを リニアサーチする
12.
● 測ってみないとどのくらい理想と現実に差があるかわからない ● 測ってみた
(Xeon 2.2GHz) ● 先頭のエントリにmatchするトラフィックのみ: 14.88Mfps ● 末尾のエントリにmatchするトラフィックのみ: 22Kbps (42fps) 笑えるくらいひどい数字を見た。 ● 末尾エントリに当たる場合、ほとんど流れないに等しい。 ● 末尾エントリに当たるパケットで速くする必要がある。 Lagopusプロトタイプ1st測定
13.
● Lookup アルゴリズム ○
さすがに愚直に10万エントリをリニアサーチするのはないだろう ○ どうにかリニアサーチせずに済ませられないかのアイデア出し ● 対象エントリをどれだけ絞り込めるか? ○ リニアサーチでいえば、エントリ数が半分ならかかる時間も半分 ○ Lookupにかかるメモリアクセス量が少ないほど速くなる ● データ構造 ○ サーチに適したデータ構造をとることで速度向上できるか? ● 複数コアの利用 ○ 複数コアで並列処理させればその分速くなる ○ 処理をパイプライン化させればコアごとの処理が局所化できる 速度向上案
14.
● https://www.openmp.org/ ● 繰り返し処理が記述されたプログラムを並列化する ●
C言語では#pragmaディレクティブを埋め込むだけ ● 例 #pragma omp parallel for for (i = 0; i < max_entry; i++) { 並列化したい処理; } ● どのコアを使うなどの細かい制御は要求されず自動的に処理される ● 探索対象フローエントリを等分してそれぞれのコアで処理 ● 処理済みのエントリを持ち寄って、もっともpriorityの高いエントリを採用 OpenMPを使ってみた
15.
● 試作して動かしてみた ● かえって遅くなった ●
なぜか ○ 10コアでばらしても1コアあたり1万エントリの探索 ○ コアごとの選出エントリが出揃わないと比較できない ○ 比較して最終的に選ぶときには1コアでの処理 ○ 1パケットごとにスレッドをバラして止めてを繰り返しすぎる ○ DPDKのコア・スレッド管理との相性も良くない ● OpenMPによる高速化の試みは失敗。 ● 書いた試作コードは非公開のまま闇に消えていただいた OpenMPを使ってみた: 結果
16.
● ルーティングテーブルではPatricia Treeが使われる ●
OpenFlowでは単純にPatricia Treeを適用することができない ● OpenFlowのmatchは複雑 ○ パケットヘッダの特定のフィールド40種類 (OpenFlow 1.3) ■ eth_src, eth_dst, eth_type, vlan_id, ip_src, ip_dst, ip_proto,... ○ 任意のフィールド複数をAND指定できる ○ 省いたフィールドはワイルドカード ○ 値の比較の際にビットマスクを指定できる ○ エントリにpriorityがあり、順序に基づきmatch結果が決まる ● OpenFlow仕様を逸脱する実装は行わない ● option指定となっている機能も実装を省かない前提 Lookupの難しさ
17.
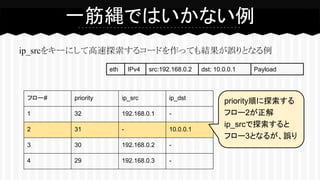
ip_srcをキーにして高速探索するコードを作っても結果が誤りとなる例 一筋縄ではいかない例 フロー# priority ip_src
ip_dst 1 32 192.168.0.1 - 2 31 - 10.0.0.1 3 30 192.168.0.2 - 4 29 192.168.0.3 - priority順に探索する フロー2が正解 ip_srcで探索すると フロー3となるが、誤り eth IPv4 src:192.168.0.2 dst: 10.0.0.1 Payload
18.
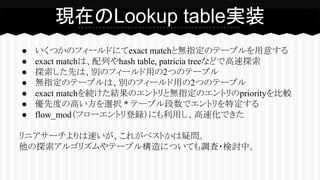
● いくつかのフィールドにてexact matchと無指定のテーブルを用意する ●
exact matchは、配列やhash table, patricia treeなどで高速探索 ● 探索した先は、別のフィールド用の2つのテーブル ● 無指定のテーブルは、別のフィールド用の2つのテーブル ● exact matchを続けた結果のエントリと無指定のエントリのpriorityを比較 ● 優先度の高い方を選択 * テーブル段数でエントリを特定する ● flow_mod(フローエントリ登録)にも利用し、高速化できた リニアサーチよりは速いが、これがベストかは疑問。 他の探索アルゴリズムやテーブル構造についても調査・検討中。 現在のLookup table実装
19.
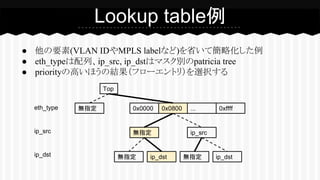
● 他の要素(VLAN IDやMPLS
labelなど)を省いて簡略化した例 ● eth_typeは配列、ip_src, ip_dstはマスク別のpatricia tree ● priorityの高いほうの結果(フローエントリ)を選択する Lookup table例 Top 0x0000 0x0800 0xffff無指定 無指定 ip_src 無指定 ip_dst無指定 ip_dst ...eth_type ip_src ip_dst
20.
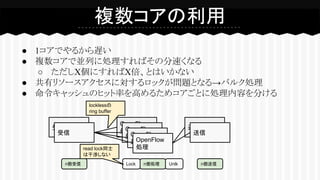
● 1コアでやるから遅い ● 複数コアで並列に処理すればその分速くなる ○
ただしX個にすればX倍、とはいかない ● 共有リソースアクセスに対するロックが問題となる→バルク処理 ● 命令キャッシュのヒット率を高めるためコアごとに処理内容を分ける 複数コアの利用 受信 OpenFlow 処理 送信OpenFlow 処理OpenFlow 処理OpenFlow 処理 受信 送信 Lock n個処理 Unlkn個受信 n個送信 read lock同士 は干渉しない locklessの ring buffer
21.
● テーブル探索で速くなったが8コア、12コアでも14.88Mfpsに届かず ● 8Mfps程度 ●
Linuxに用意されているperfコマンドを用いて遅い個所を調査 ● Lagopusを動かしておき、別ターミナルでsudo perf topを実行 ● 実行時間の長いfunctionが上位に表示される ○ 処理が軽くても空回り(busy loop)しているfunctionは上位に表示 ● 調査結果、まだまだLookupが遅いことが判明 まだ遅い。
22.
1. 最初のパケットは通常のマッチ処理を行う 2. マッチ完了→パケットヘッダの情報とフローエントリが関連付けられる 3.
関連付けをキャッシュテーブルに登録する 4. 次のパケットはパケットヘッダの情報でキャッシュを引く 5. 見つかればフローエントリは確定しているのでマッチ処理完了 6. 見つからなければ通常マッチ処理してキャッシュ登録 これにより12コアを使ってMPLS-VLAN転送14.88Mfpsを達成。 (2014年3月) Lookup軽量化: flow cache
23.
● OpenFlow処理スレッドでは、1パケットをmatch-action完了まで実行する ● 毎回やる必要のない処理があれば、省くことで速くなる ●
たとえば、特定処理の時のみ使われる変数の初期化 ○ OpenFlowのactionには、2種類がある ■ 即時実行するapply-action ■ 書き溜めておき、最後に実行するwrite-actions ○ write-actions用変数の初期化は毎回必要とはならないことが多い ○ これを必要な時のみ実行するよう変更 もっと速く
24.
● OpenFlow処理スレッドでは、1パケットをmatch-action完了まで実行する ● 細かく見ると、パケットヘッダの情報収集、match、actionにわけられる ●
パケットヘッダの情報収集をn個まとめて処理するよう変更 ● 命令キャッシュの利用効率が向上 ● Intel Performance Counter Monitor (Intel PCM)で調査できる ○ CPUが持つカウンタを参照するのでXeonが必要 ● 2015年4月現在、前出と同ハードにて、4コアを使って13Mfpsの性能 ○ 開発版 ○ 近日リリース予定とのことです もっともっと速く
25.
アイデア段階のものがいくつかある。 ● matchとactionをスレッド(コア)分離させる ● matchをバルク処理させる ●
action処理を見直す ● RSSである程度処理を分散させ、一部の探索を省く ● ポートごとに独立した処理とし、ポート数が増えても速度を維持させる ● Intel NICのflow director機能を使い、ハードウェアflow cacheを実現 ● flow cacheに使っているhash tableを高性能なものに置き換える ● バルク処理パケット数の調整(レイテンシ・揺らぎが増える) ● フローテーブルの内容によりダイナミックに探索テーブル生成 ● and, more! 提案、実装、大歓迎! さらなる性能向上に向けて
26.
Lagopus http://lagopus.github.io ONF (OpenFlowの総本山) http://www.opennetworking.org/ Lagopus User
Community http://www.lagopus.community/cms/ DPDK http://dpdk.org/ Reference
Download























































![[D20] 高速Software Switch/Router 開発から得られた高性能ソフトウェアルータ・スイッチ活用の知見 (July Tech Fest...](https://cdn.slidesharecdn.com/ss_thumbnails/jtf20182-180803022253-thumbnail.jpg?width=640&height=640&fit=bounds)



























