Download as PDF, PPTX









![IoT and Digital Twin with Apache Kafka and InfluxDB – @KaiWaehner - www.kai-waehner.de
Improve
Customer
Experience
(CX)
Increase
Revenue
(make money)
Business
Value
Decrease
Costs
(save money)
Core Business
Platform
Increase
Operational
Efficiency
Migrate to
Cloud
Mitigate Risk
(protect money)
Key Drivers
Strategic Objectives
(sample)
Fraud
Detection
IoT sensor
ingestion
Digital
replatforming/
Mainframe Offload
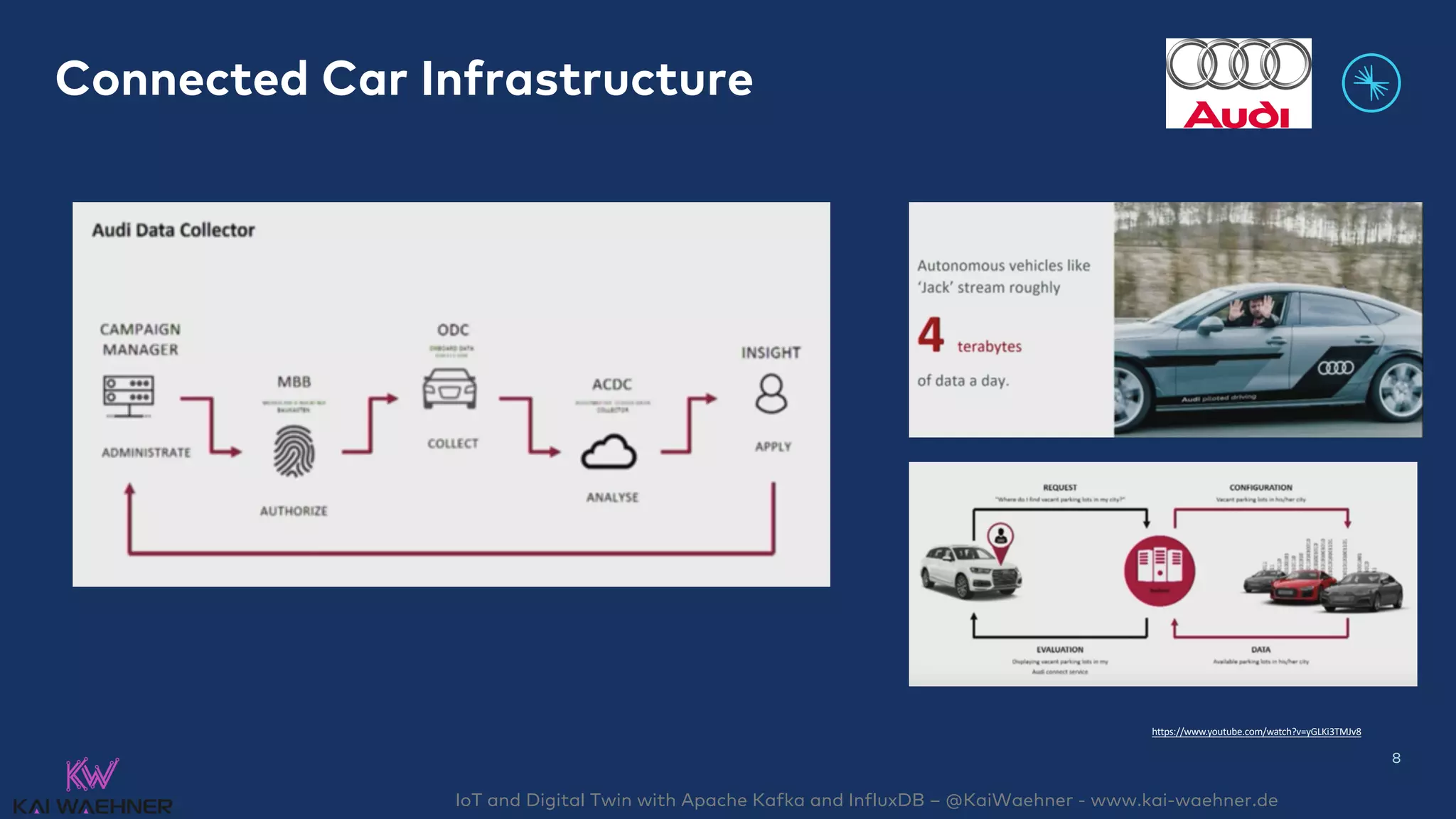
Connected Car: Navigation & improved in-
car experience: Audi
Customer 360
Simplifying Omni-channel Retail at Scale:
Target
Faster transactional
processing / analysis
incl. Machine Learning / AI
Mainframe Offload: RBC
Microservices
Architecture
Online Fraud Detection
Online Security
(syslog, log aggregation,
Splunk replacement)
Middleware
replacement
Regulatory
Digital
Transformation
Application Modernization: Multiple
Examples
Website / Core
Operations
(Central Nervous System)
The [Silicon Valley] Digital Natives;
LinkedIn, Netflix, Uber, Yelp...
Predictive Maintenance: Audi
Streaming Platform in a regulated
environment (e.g. Electronic Medical
Records): Celmatix
Real-time app
updates
Real Time Streaming Platform for
Communications and Beyond: Capital One
Developer Velocity - Building Stateful
Financial Applications with Kafka Streams:
Funding Circle
Detect Fraud & Prevent Fraud in Real Time:
PayPal
Kafka as a Service - A Tale of Security and
Multi-Tenancy: Apple
Example Use Cases
$↑
$↓
$↔
Example Case Studies
(of many)
Confluent - Business Value per Use Case
20](https://image.slidesharecdn.com/202006digitaltwinkafkainfluxdb-200624103300/75/Kai-Waehner-Confluent-Real-Time-Streaming-Analytics-with-100-000-Cars-Using-MQTT-Kafka-and-InfluxDB-2-0-on-Kubernetes-InfluxDays-Virtual-Experience-London-2020-19-2048.jpg)




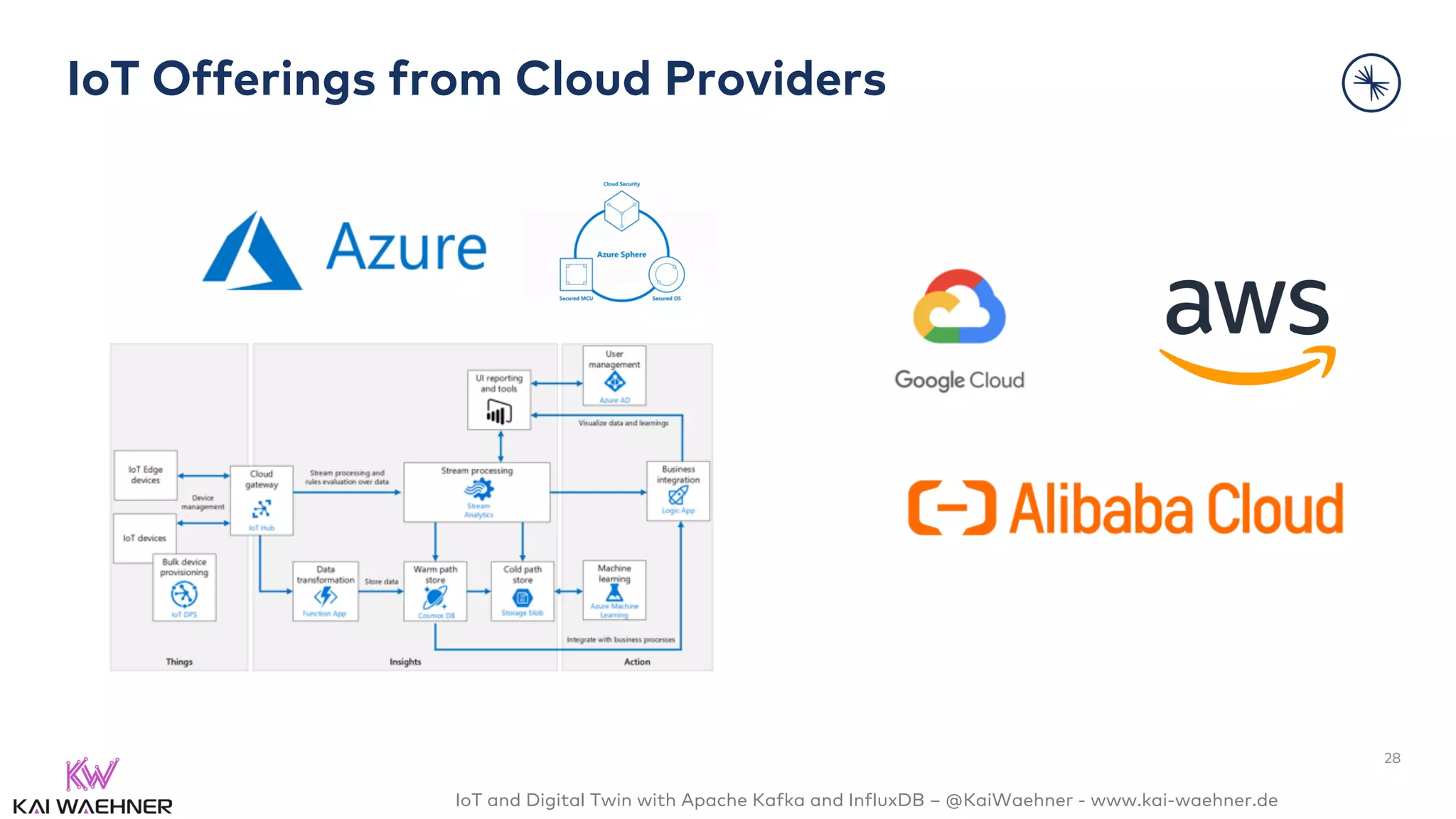

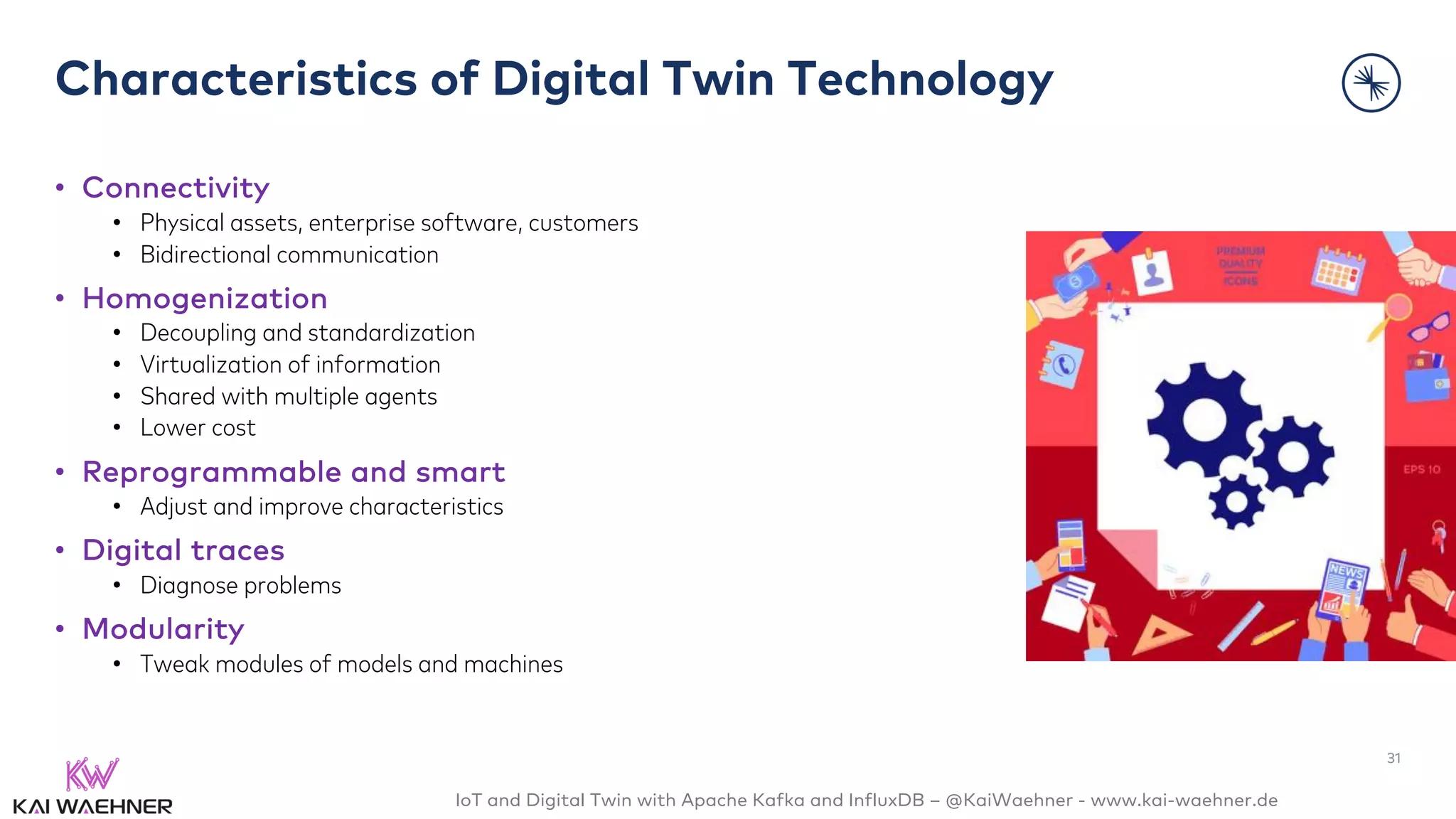
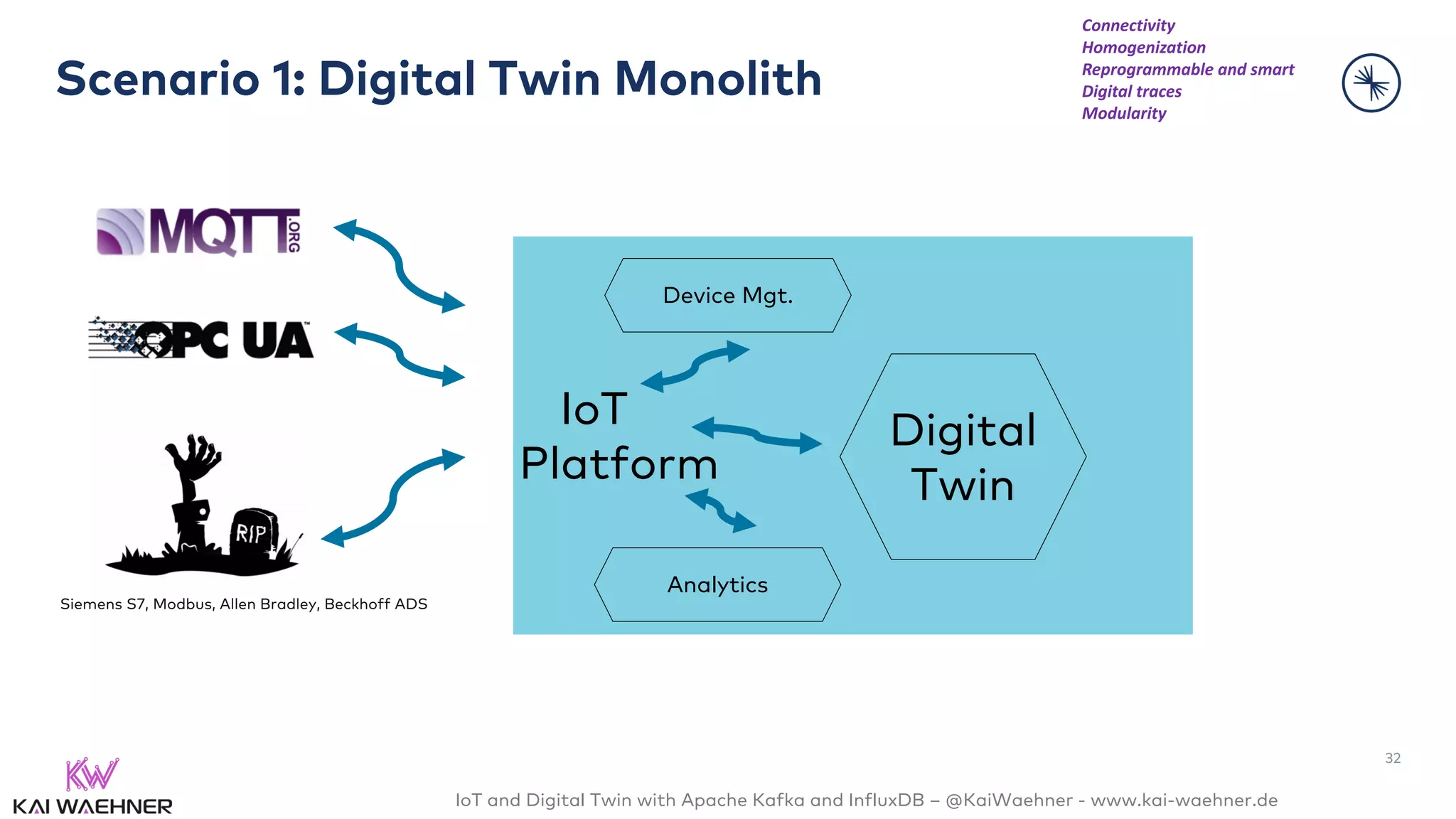
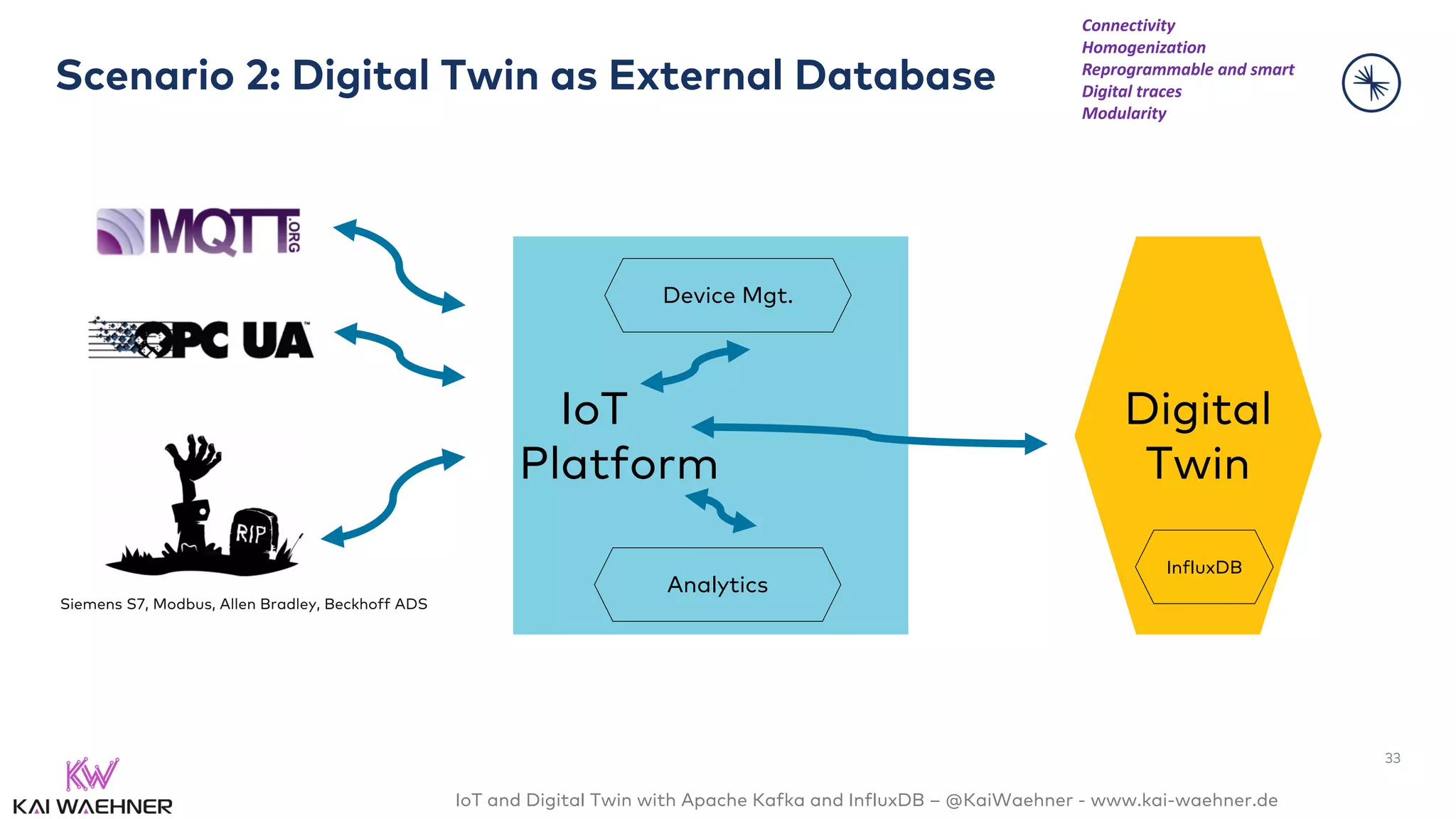
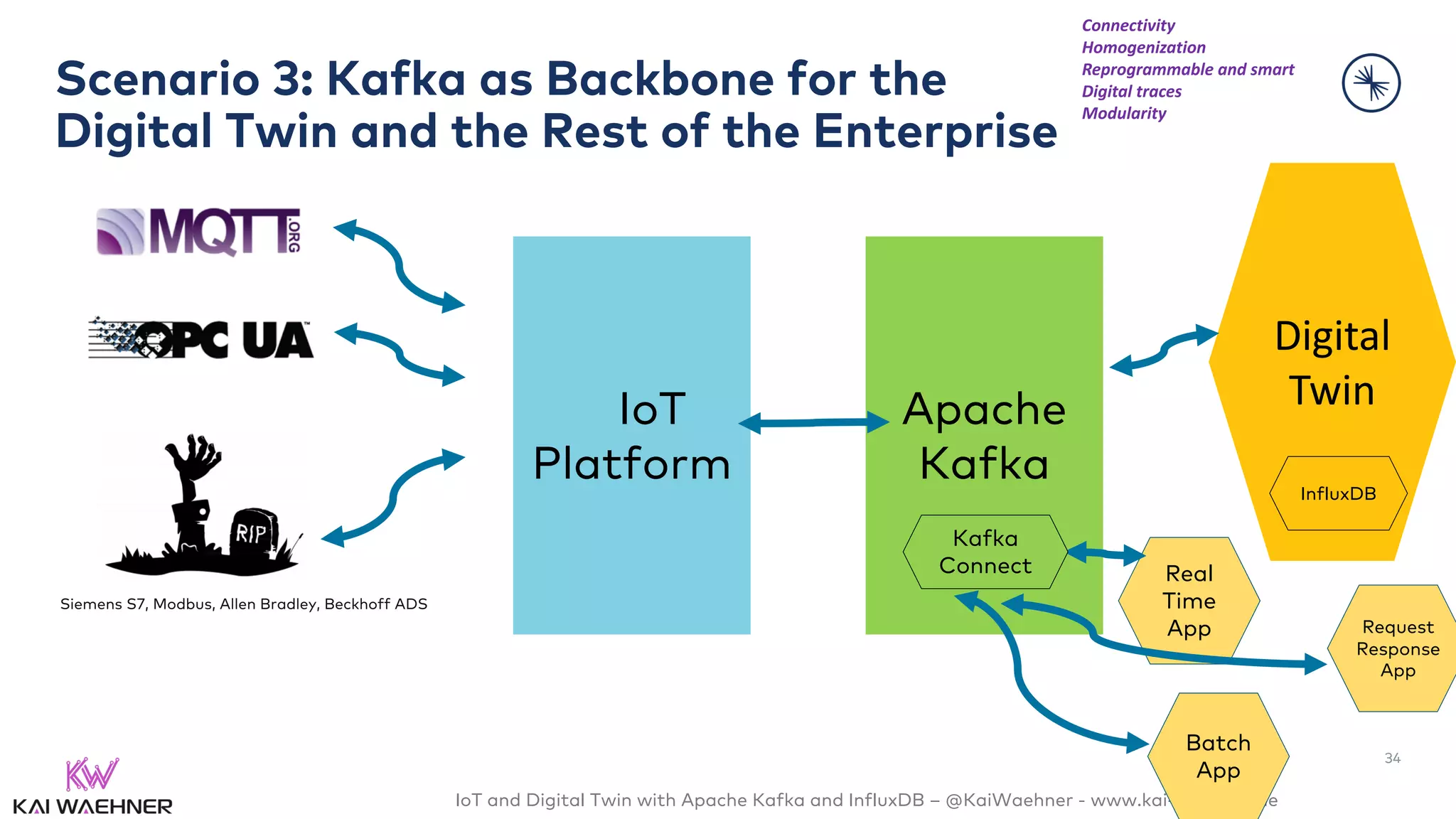
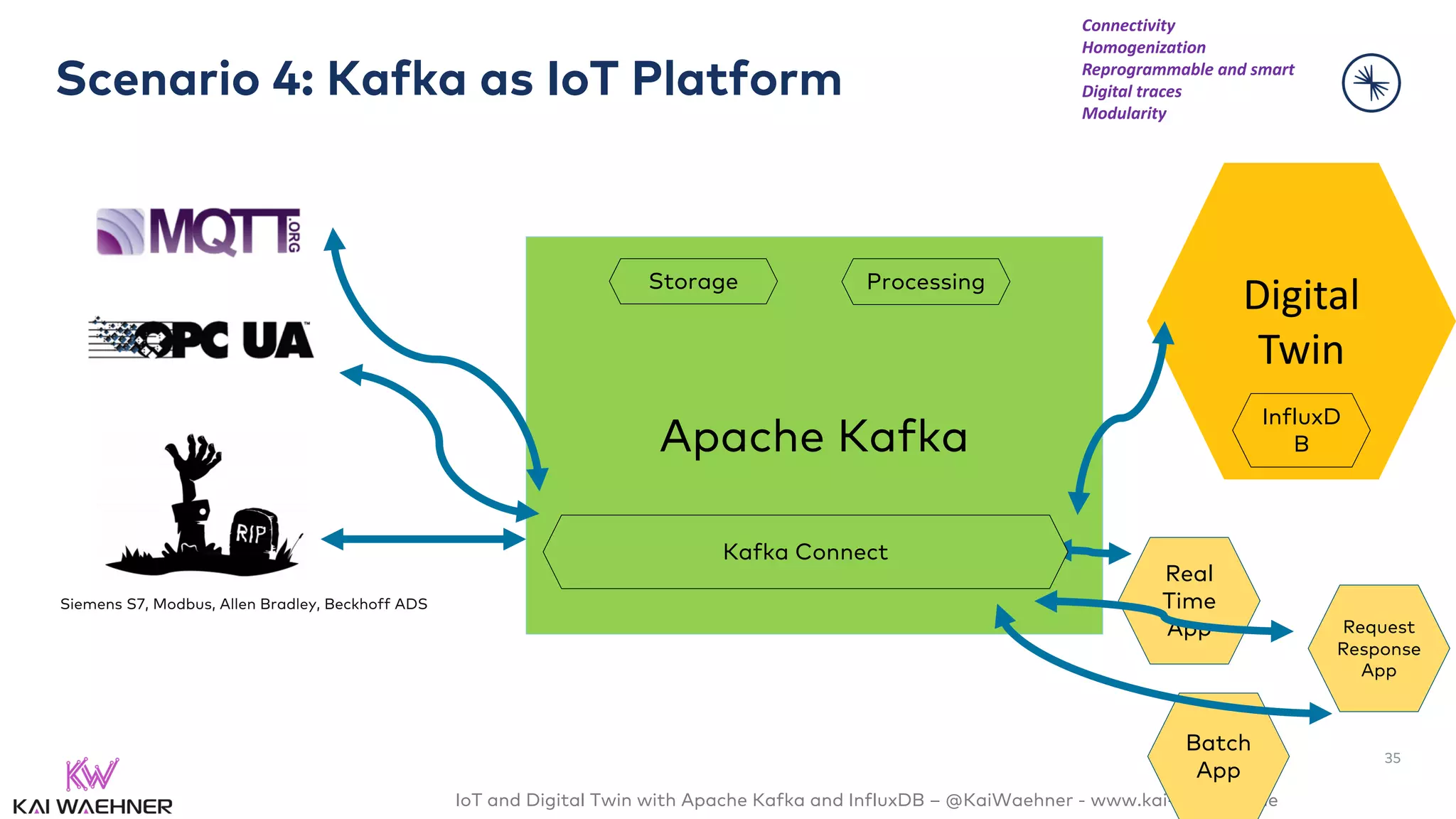

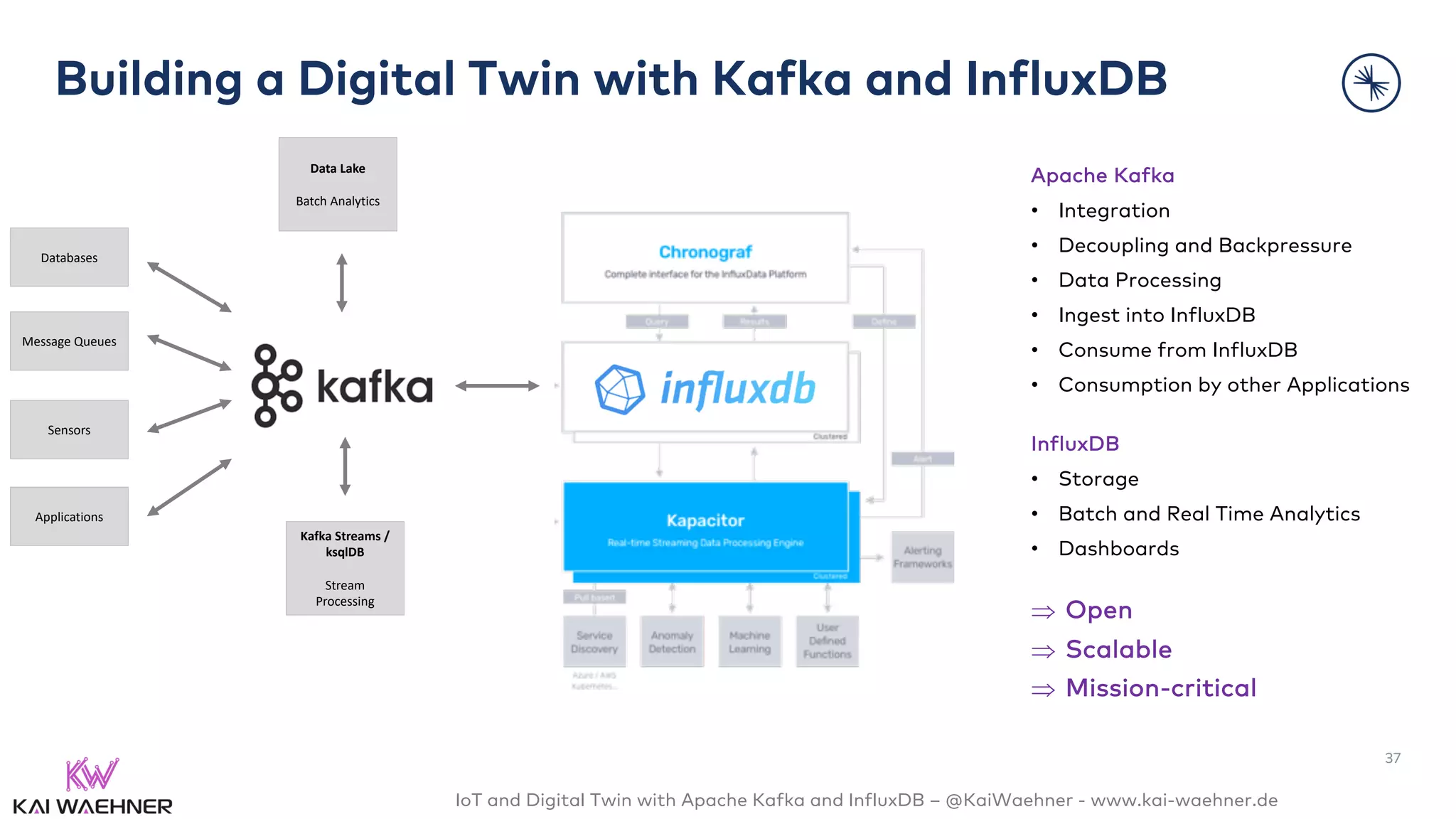
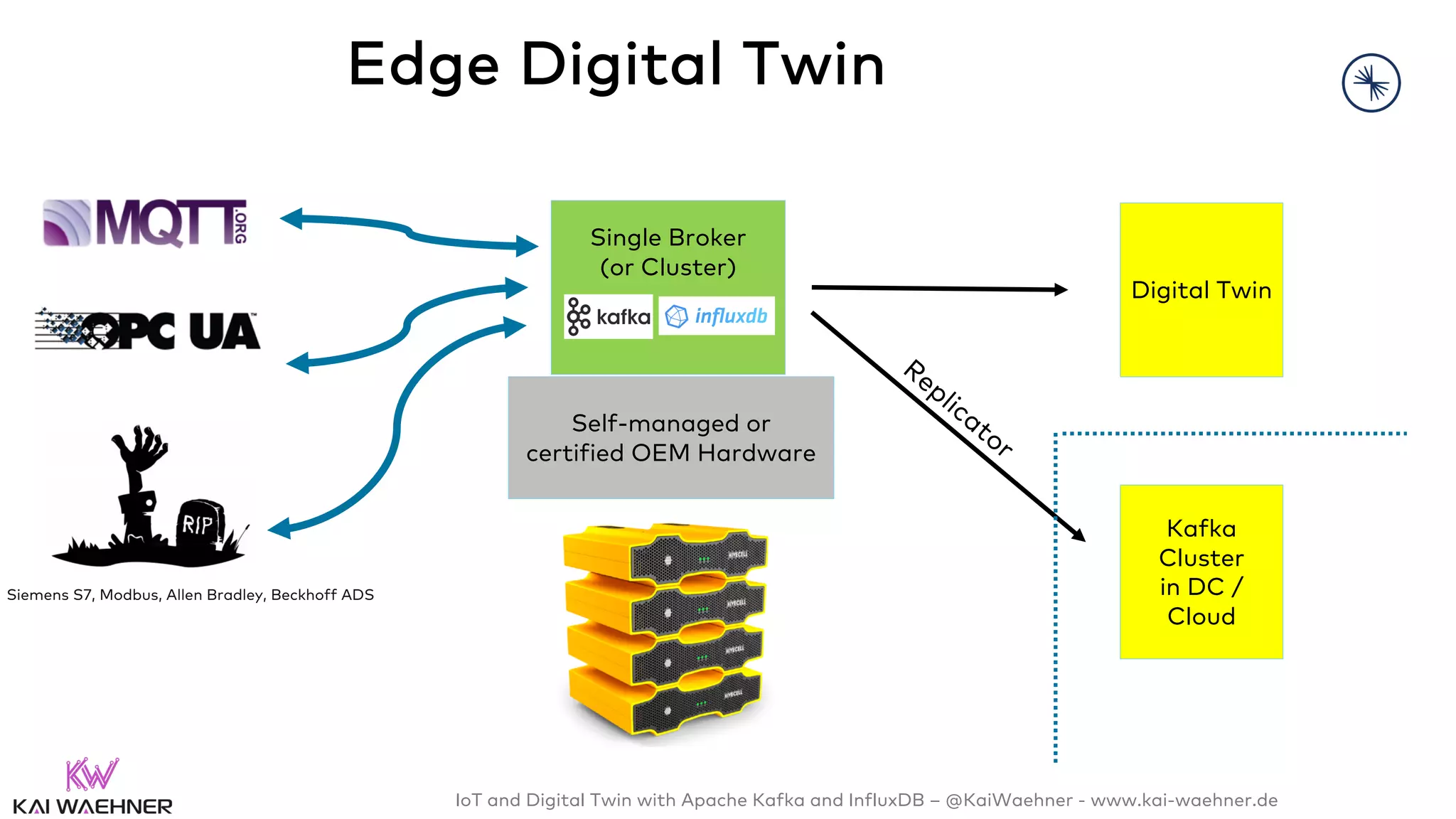
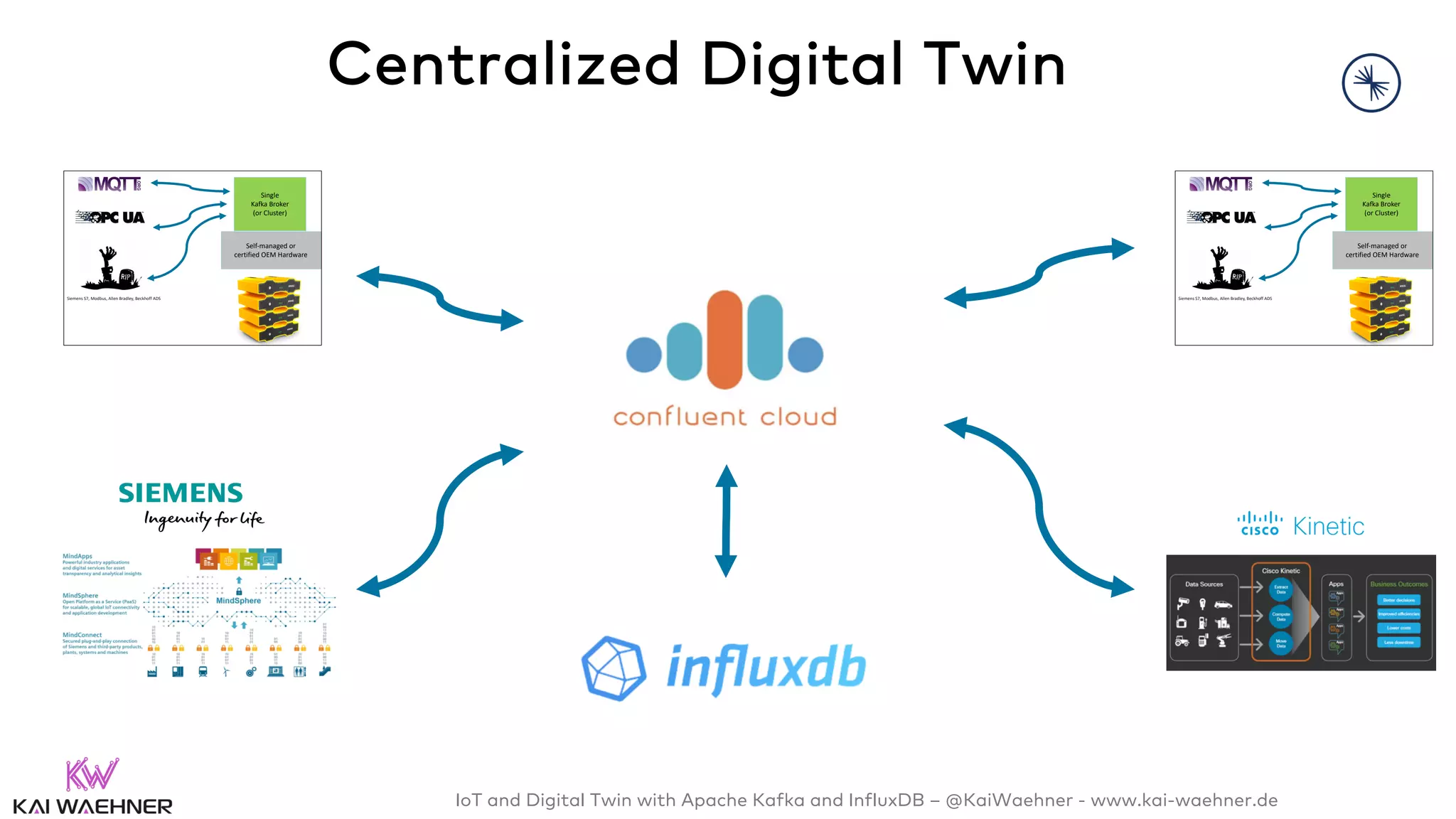
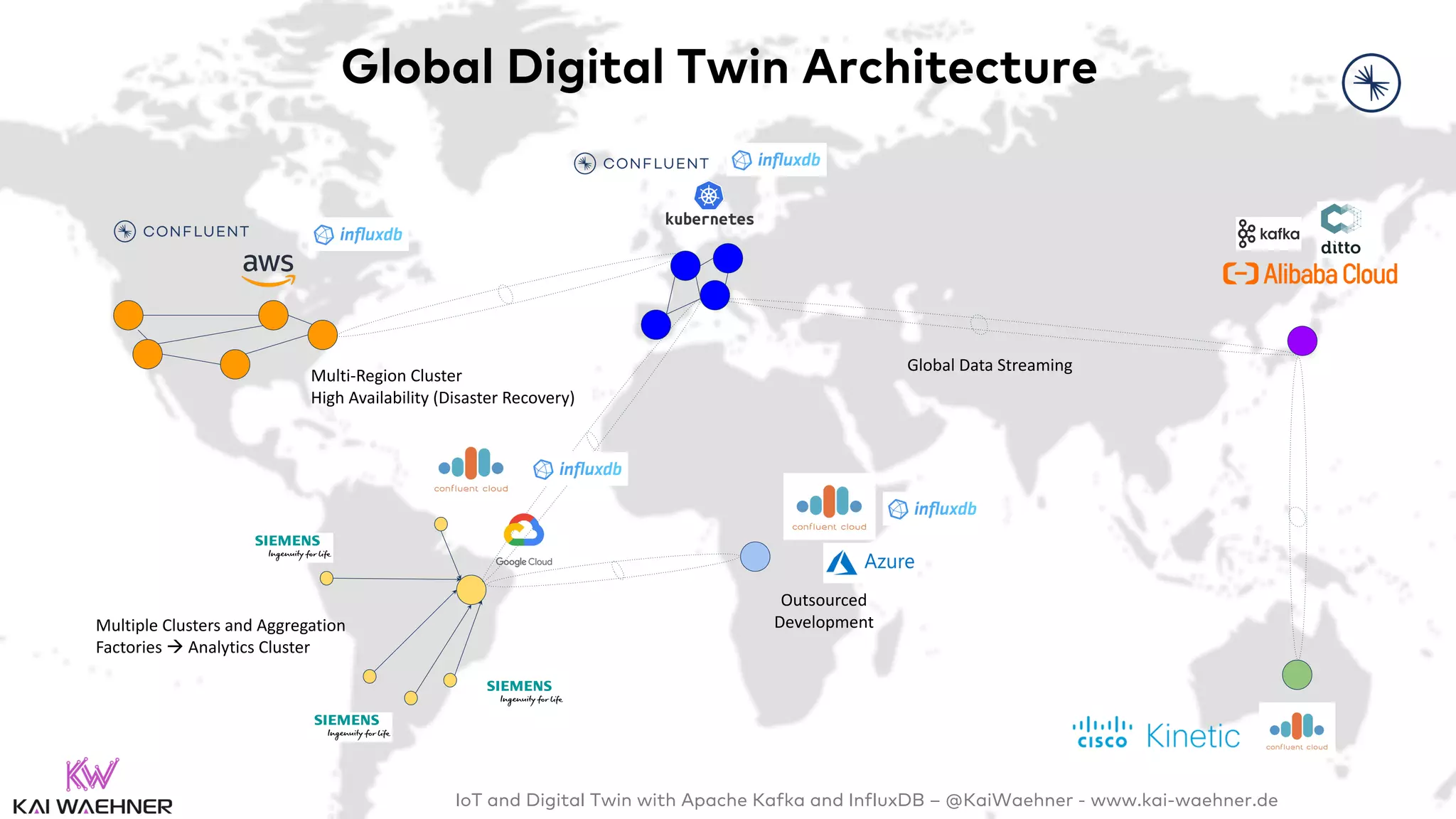

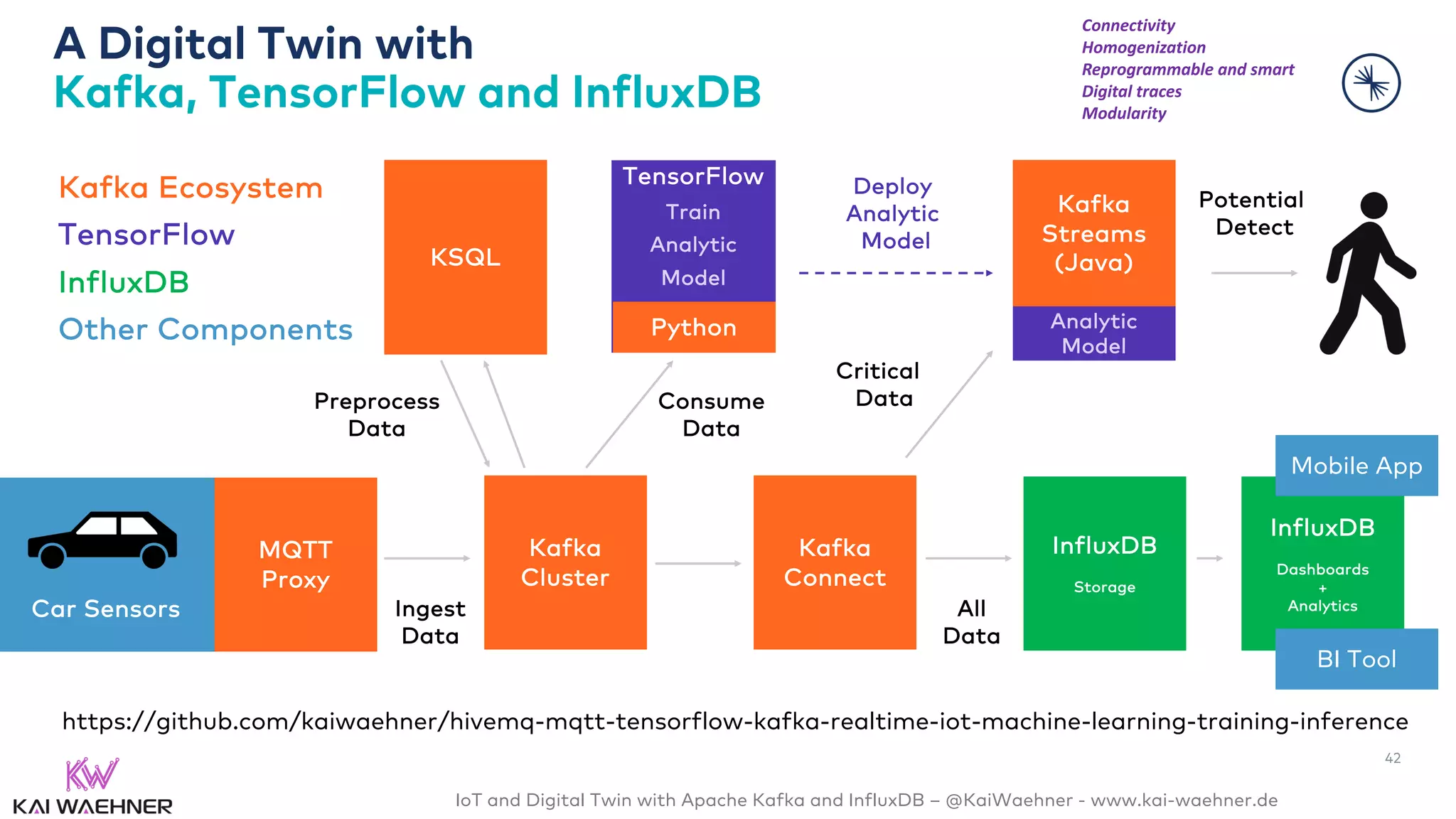
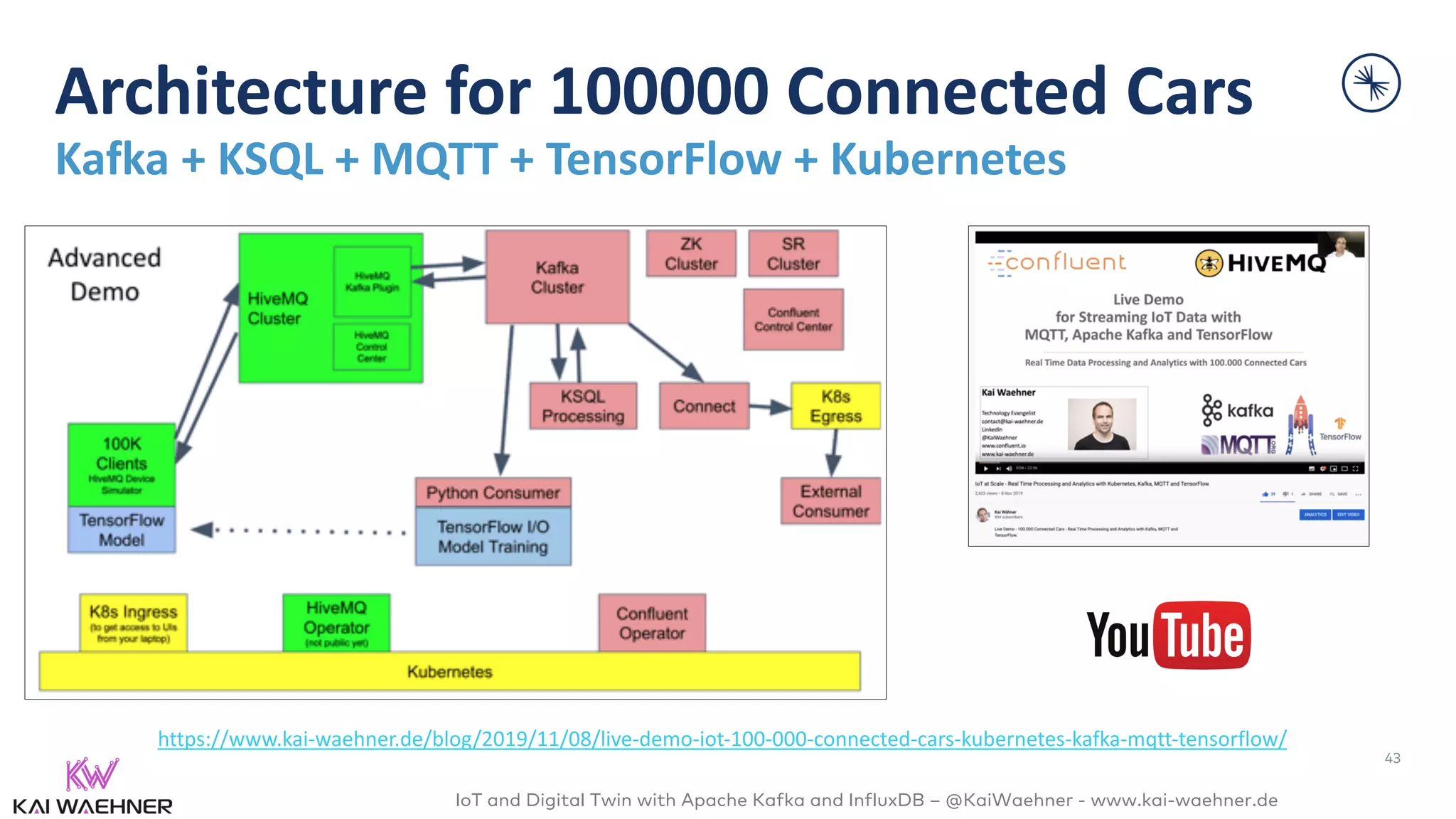



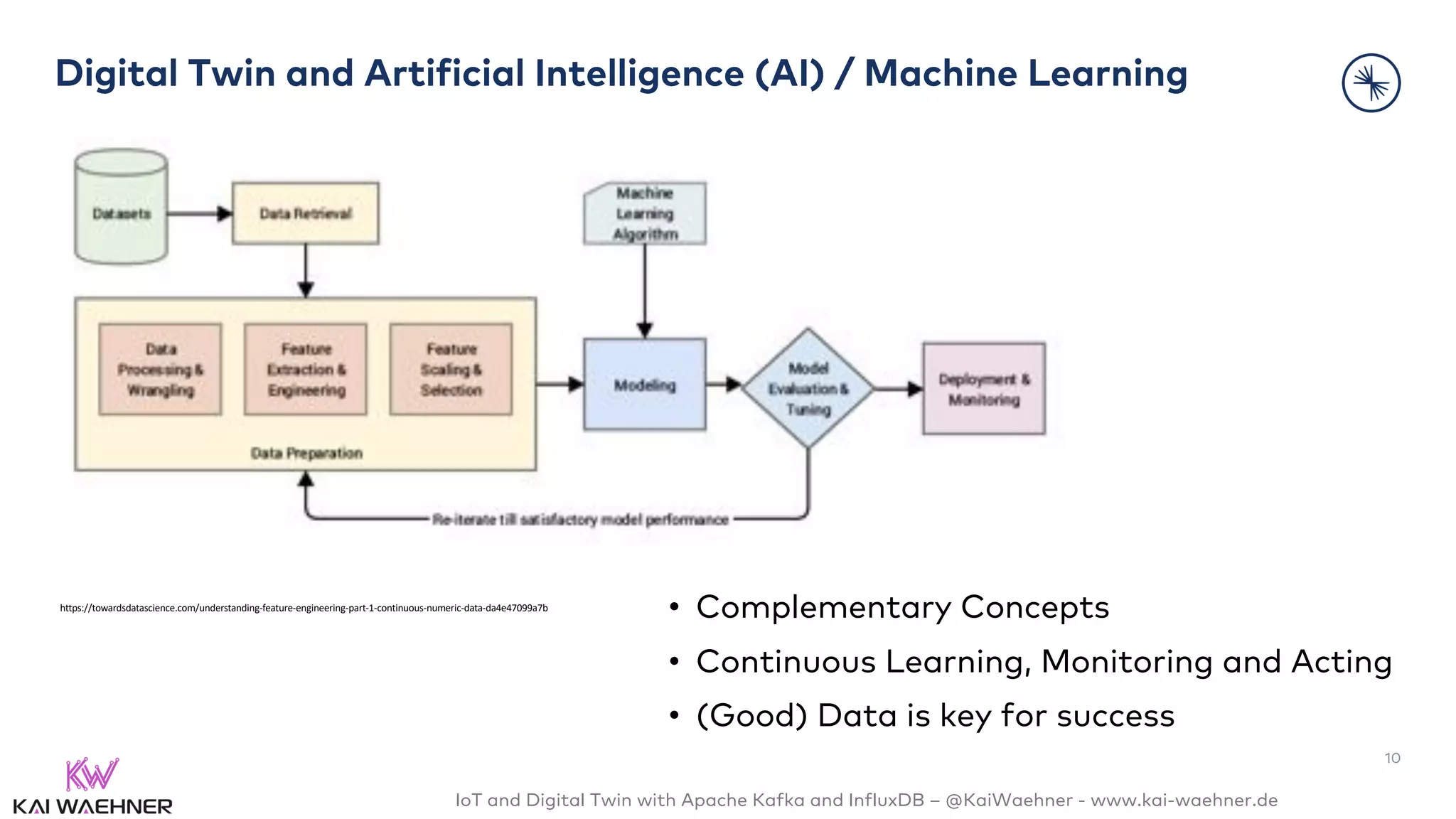
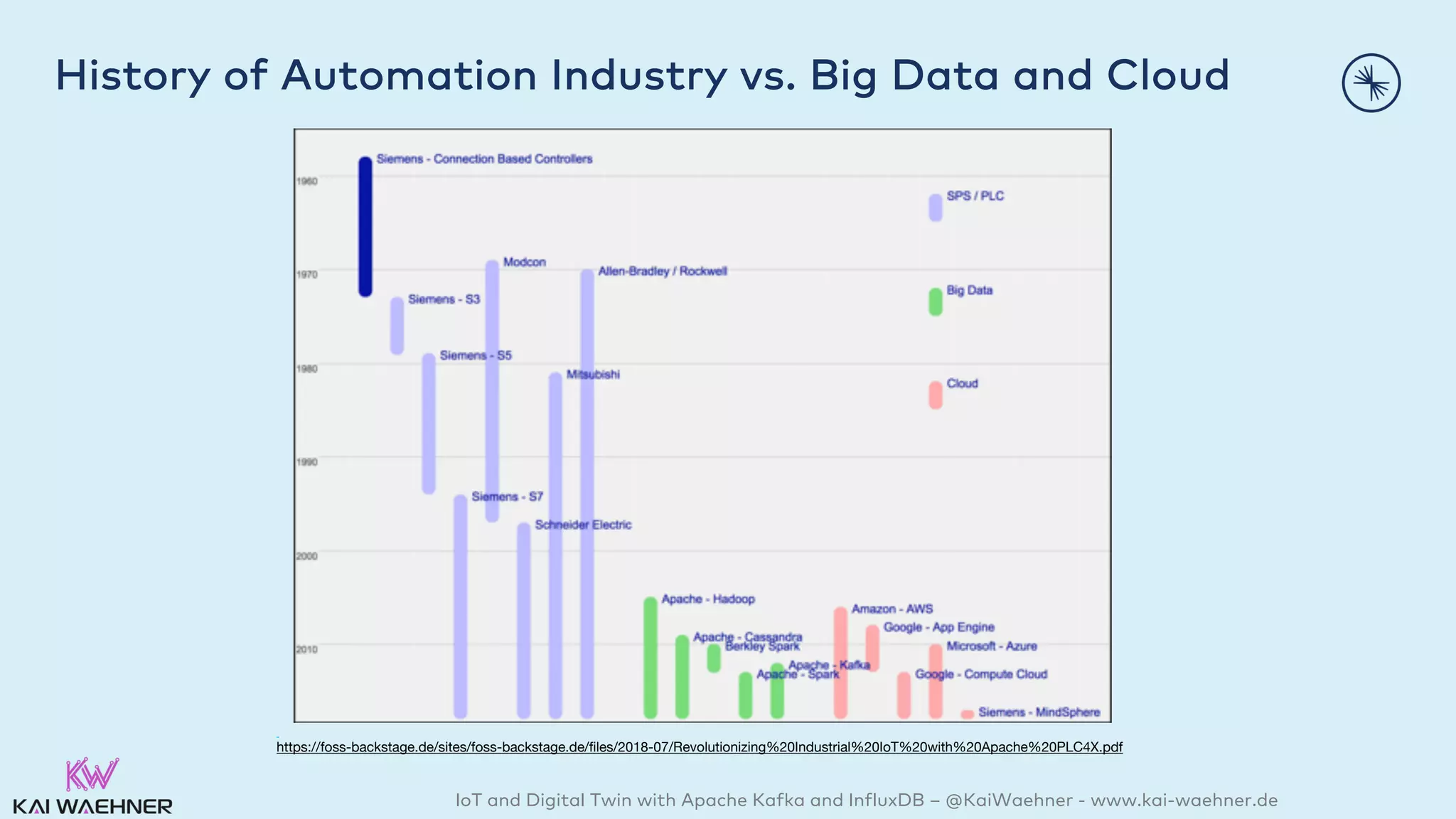
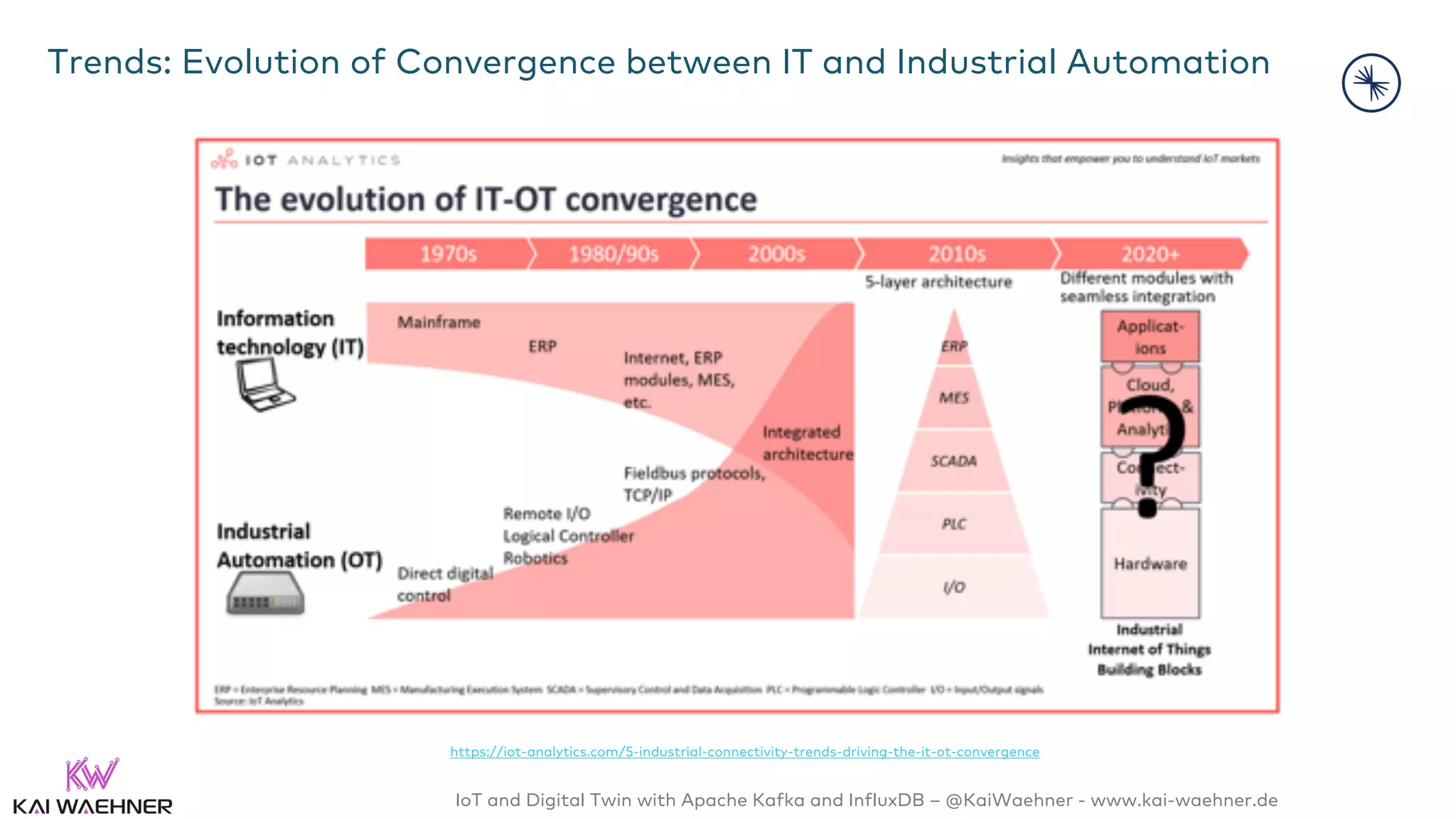
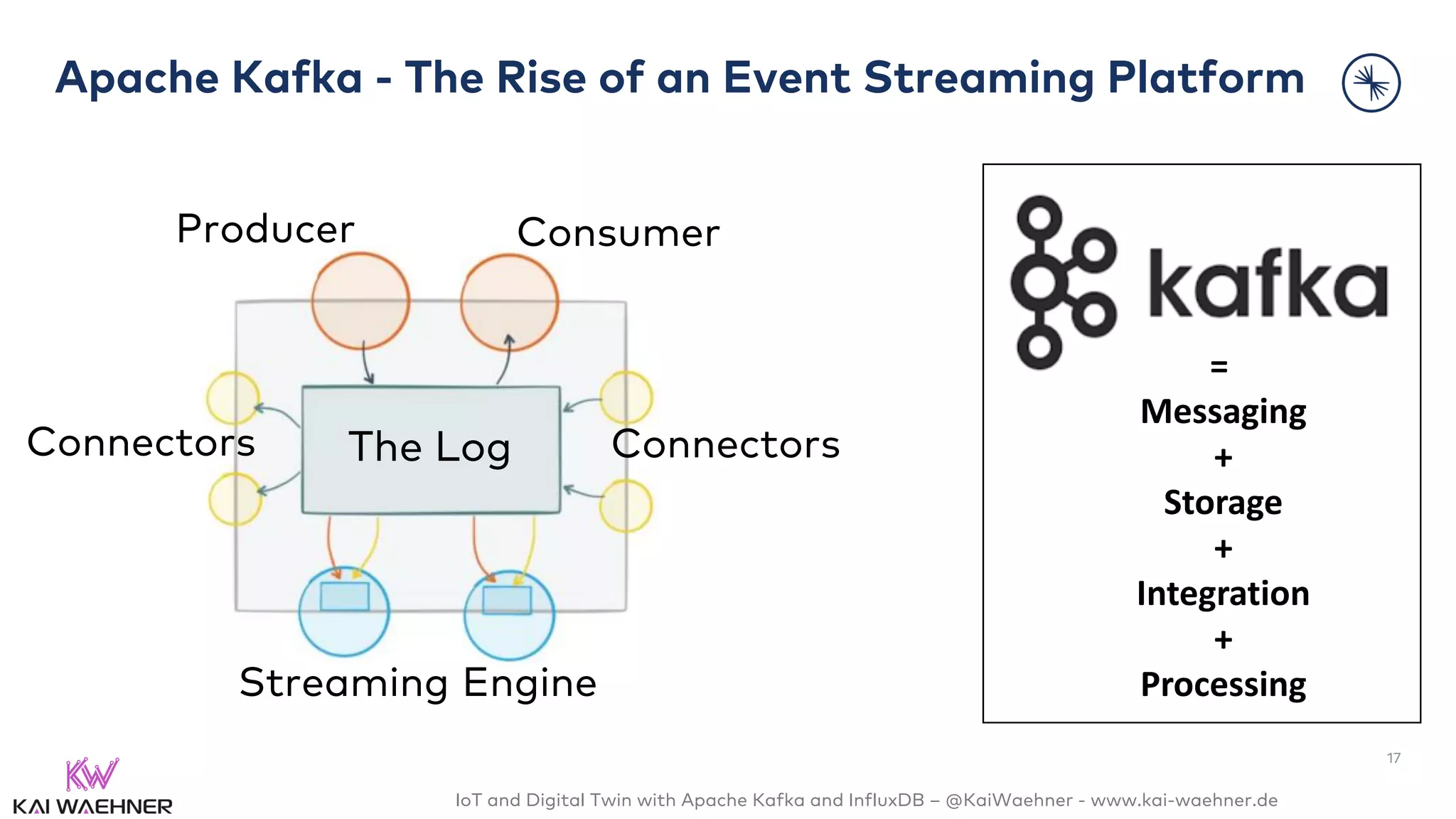
The document discusses the integration of Internet of Things (IoT) and digital twin technology using Apache Kafka and InfluxDB, emphasizing the merging of physical and digital environments. It outlines real-world challenges, the role of event streaming solutions, and the architecture of a digital twin for scenarios like connected cars. Key takeaways highlight the benefits of an open, scalable, and reliable infrastructure for digital twins and the complementary nature of event streaming with IoT platforms.































































![Ward Bowman [PTC] | ThingWorx Long-Term Data Storage with InfluxDB | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays-221027185325-5d2f430b-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | New & Upcoming Flux Features | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022-fluxupdates-scott-221021210238-9d323cba-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday2-221020220104-abde55ea-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Welcome to InfluxDays 2022 - Day 2 | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022welcometoday2-221020215815-c8463942-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts Day 1 | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday1-221020215301-f8040e1f-thumbnail.jpg?width=640&height=640&fit=bounds)



















