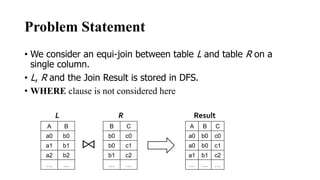
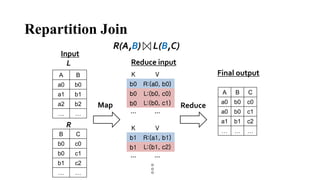
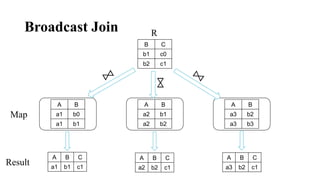
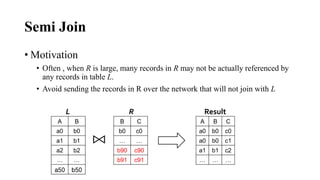
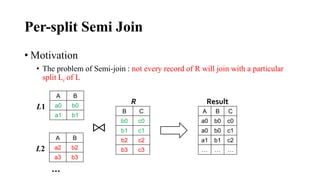
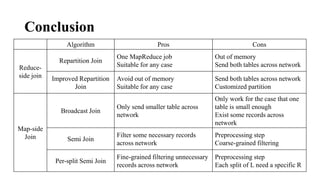
The document discusses different join algorithms in MapReduce including repartition join, improved repartition join, broadcast join, semi join, and per-split semi join. Repartition join performs the join during the reduce phase but may cause out of memory issues if the data is skewed or the key cardinality is small. Improved repartition join addresses this by outputting a composite key and buffering only the smaller table. Broadcast join avoids network overhead by broadcasting the smaller table to each mapper. Semi join and per-split semi join further optimize this by only sending joining records to reduce network costs.