The document provides an introduction to parallel and distributed computation using Scala and Apache Spark, covering the Scala programming language's functional paradigm and its suitability for big data analytics and machine learning. It discusses key concepts such as the MapReduce model, Scala's data types and collections, and higher-order functions while emphasizing the advantages of pure functional programming. Additionally, it mentions the historical context of MapReduce and its implementation in Hadoop, concluding with an overview of Apache Spark as a concurrent data processing engine.






![Scala: a strongly typed language
● Scala is a strongly typed language
● implements a hierarchical type system
● the type inference allows to omit the data type in declarations
like in python but with safety of a strong static type system
● Runtime type casting (asInstanceOf[T]) trigger the type
systems which will raise exceptions for incompatible casts](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-7-2048.jpg)

![Scala: overview of the main types and collections 2/2
● Set -> iterable set without duplicates
● Maps -> iterable associative maps
● Array -> corresponds 1:1 to java arrays e.g. Array[Int] are java
int[]
● Vector -> collection with constant time random access
● Stream -> like a list but with lazy elements](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-9-2048.jpg)


![Scala, overview of the main functions: Map.getOrElse
scala> val m = Map(1 -> "a", 2 -> "b", 3 -> "c")
m: scala.collection.immutable.Map[Int,String] = Map(1 -> a, 2 ->
b, 3 -> c)
scala> m.getOrElse(100, "NOT FOUND")
res0: String = NOT FOUND
scala> m.getOrElse(1, "NOT FOUND")
res1: String = a](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-12-2048.jpg)
![filter -> produce a new iterable filtering out elements
scala> val m = Map(1 -> "1", 2 -> "2", 3 -> "33")
m: scala.collection.immutable.Map[Int,String] = Map(1 -> 1, 2 -> 2, 3 -> 33)
scala> m.filter(_._2 != "2")
res1: scala.collection.immutable.Map[Int,String] = Map(1 -> 1, 3 -> 33)
scala> m.filter(_._1 != 3)
res2: scala.collection.immutable.Map[Int,String] = Map(1 -> 1, 2 -> 2)
Scala, overview of the main functions: filter](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-13-2048.jpg)
![Scala, overview of the main functions: map
map -> execute a function to every element of an iterable
scala> val m = Map(1 -> "1", 2 -> "2", 3 -> "33")
m: scala.collection.immutable.Map[Int,String] = Map(1 -> 1, 2 -> 2, 3 -> 33)
scala> m.map(x => (x._1, (2 * x._2.toInt).toString))
res3: scala.collection.immutable.Map[Int,String] = Map(1 -> 2, 2 -> 4, 3 -> 66)
scala> m.keys
res4: Iterable[Int] = Set(1, 2, 3)
scala> m.values
res5: Iterable[String] = MapLike(1, 2, 33)](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-14-2048.jpg)
![reduce -> reduce elements by specifying an associative binary operations, no
deterministic order of evaluation
scala> val m = Map(1 -> "1", 2 -> "2", 3 -> "33")
m: scala.collection.immutable.Map[Int,String] = Map(1 -> 1, 2 -> 2, 3 -> 33)
scala> m.reduce((a, b) => { (a._1 + b._1, a._2 + b._2) })
res10: (Int, String) = (6,1233)
Scala, overview of the main functions: reduce](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-15-2048.jpg)
![reduceLeft / reduceRight -> reduction is done from left to right / right to left
scala> val l = List("a", "b", "c", "d")
l: List[String] = List(a, b, c, d)
scala> l.reduce((a,b) => {a + b})
res6: String = abcd
scala> l.reduceLeft((a,b) => {a + b}) // (((a + b) + c) + d)
res7: String = abcd
scala> l.reduceRight((a,b) => {a + b}) // (a + (b + (c + d)))
res8: String = abcd
Scala, overview of the main functions: reduceLeft/Right](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-16-2048.jpg)
![fold, foldLeft, foldRight -> like reduce but first element must be passed
scala> val l = List("a", "b", "c", "d", "e", "f")
l: List[String] = List(a, b, c, d, e, f)
scala> l.fold("#")((a,b) => {a + b})
res12: String = #abcdef
scala> l.foldLeft("#")((a,b) => {a + b})
res13: String = #abcdef
scala> l.foldRight("#")((a,b) => {a + b})
res14: String = abcdef#
Scala, overview of the main functions: fold](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-17-2048.jpg)
![zip / unzip -> merge two iterables / split an iterable
scala> val s0 = Seq(1,2,3,4,5,6)
s0: Seq[Int] = List(1, 2, 3, 4, 5, 6)
scala> val s1 = Seq(6,5,4,3,2,1)
s1: Seq[Int] = List(6, 5, 4, 3, 2, 1)
scala> val z = s0 zip s1 // same of val z = s0.zip(s1)
z: Seq[(Int, Int)] = List((1,6), (2,5), (3,4), (4,3), (5,2), (6,1))
scala> z.unzip
res5: (Seq[Int], Seq[Int]) = (List(1, 2, 3, 4, 5, 6),List(6, 5, 4, 3, 2, 1))
Scala, overview of the main functions: zip/unzip](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-18-2048.jpg)
![zipWithIndex -> merge an iterable with an index
scala> val l = List("a", "b", "c", "d", "e", "f")
l: List[String] = List(a, b, c, d, e, f)
scala> l.zipWithIndex
res5: List[(String, Int)] = List((a,0), (b,1), (c,2), (d,3), (e,4), (f,5))
Scala, overview of the main functions: zipWithIndex](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-19-2048.jpg)
![Create a single list from an iterable of iterables (e.g. list of lists)
scala> val m = Map("A" -> List(1, 2, 3), "B" -> List(3, 4, 5), "C" -> List(6, 7, 8))
m: scala.collection.immutable.Map[String,List[Int]] = Map(A -> List(1, 2, 3), B ->
List(3, 4, 5), C -> List(6, 7, 8))
scala> m.values.flatten
res34: Iterable[Int] = List(1, 2, 3, 3, 4, 5, 6, 7, 8)
Scala, some useful methods on Lists: flatten](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-20-2048.jpg)
![group a list of items
scala> val l = List(("a", 1), ("b", 2), ("a", 2), ("a", 3), ("c", 1))
l: List[(String, Int)] = List((a,1), (b,2), (a,2), (a,3), (c,1))
scala> l.groupBy(_._1)
res5: scala.collection.immutable.Map[String,List[(String, Int)]] = Map(b ->
List((b,2)), a -> List((a,1), (a,2), (a,3)), c -> List((c,1)))
scala> l.groupBy(_._2)
res6: scala.collection.immutable.Map[Int,List[(String, Int)]] = Map(2 -> List((b,2),
(a,2)), 1 -> List((a,1), (c,1)), 3 -> List((a,3)))
Scala, some useful methods of iterables: groupBy](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-21-2048.jpg)
![generate a new map modifying the values
scala> val m = Map(1 -> "a", 2 -> "b", 3 -> "c")
m: scala.collection.immutable.Map[Int,String] = Map(1 -> a, 2 -> b, 3 -> c)
scala> m.mapValues(_ + "#")
res13: scala.collection.immutable.Map[Int,String] = Map(1 -> a#, 2 -> b#, 3 -> c#)
Scala, some useful methods of maps: mapValues](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-22-2048.jpg)
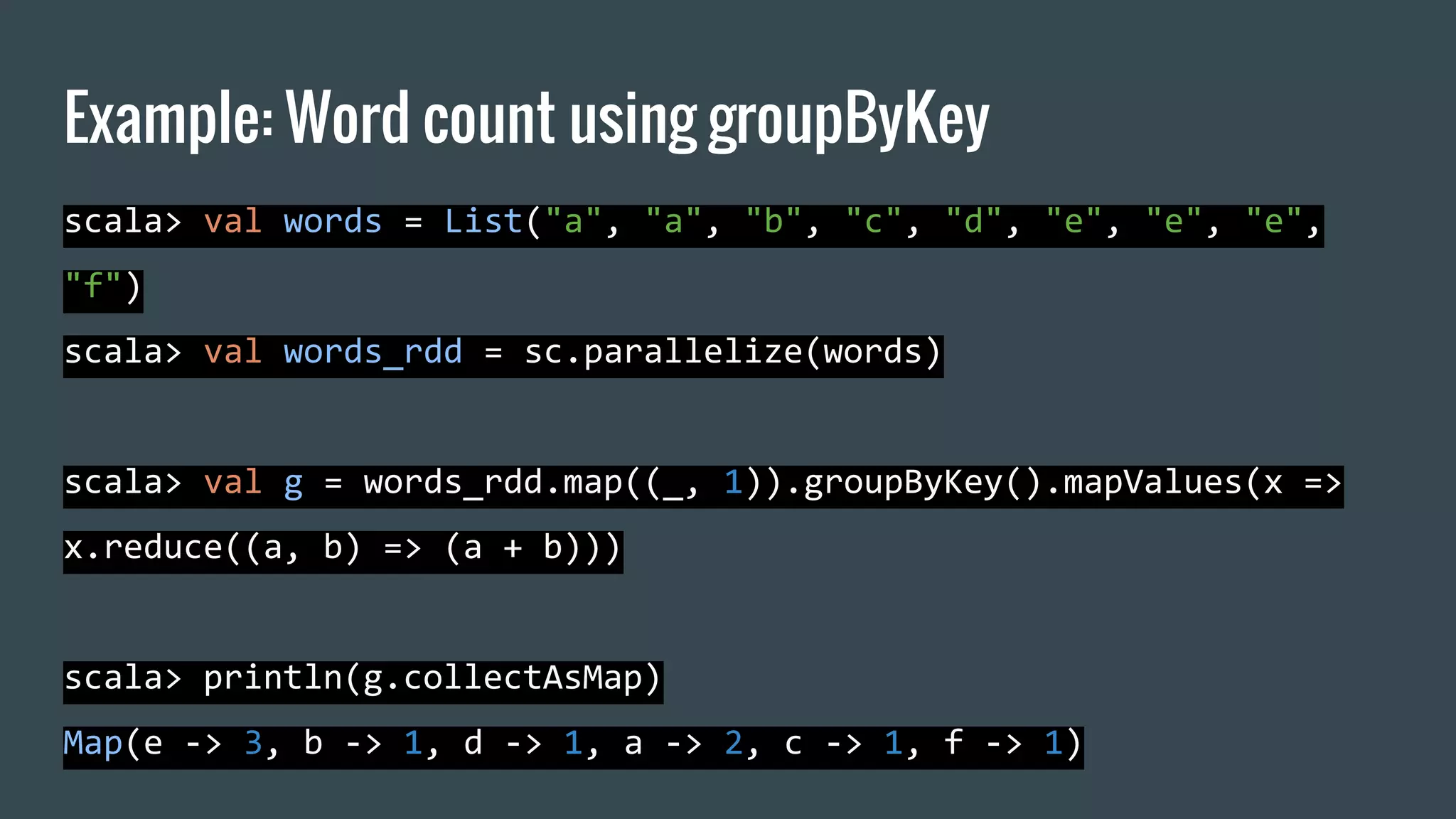
![scala> val l = List("a", "b", "c", "d", "a").groupBy(identity)
l: scala.collection.immutable.Map[String,List[String]] = Map(b -> List(b), d ->
List(d), a -> List(a, a), c -> List(c))
scala> l.mapValues(_.length)
res17: scala.collection.immutable.Map[String,Int] = Map(b -> 1, d -> 1, a -> 2, c ->
1)
Scala, an example: word count](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-23-2048.jpg)
![scala> for(i <- 1 to 10) { print(i*2 + " ") }
2 4 6 8 10 12 14 16 18 20
scala> for(i <- (1 to 10)) yield i * 2
res7: scala.collection.immutable.IndexedSeq[Int] = Vector(2, 4, 6,
8, 10, 12, 14, 16, 18, 20)
Scala, for loops](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-24-2048.jpg)



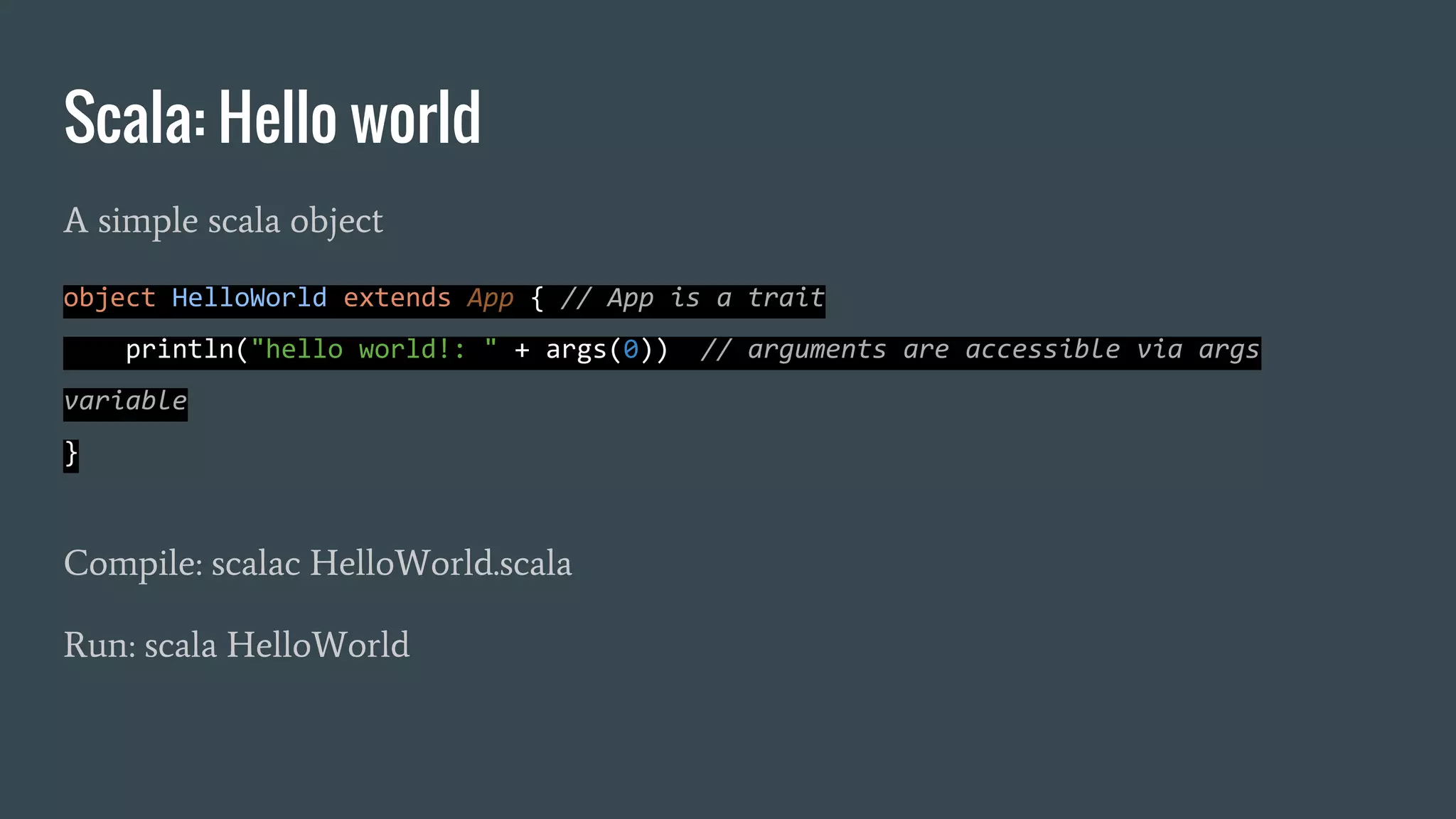
![Scala: high order functions
higher-order functions: takes other functions as parameters or whose result is a
function
object HighOrderFunctions extends App {
def f(v: Int) : Int = v*2 // defining a function
// Int => Int is the type of a function from Int to Int
def apply(f: Int => Int, l: List[Int]) = l.map(f(_)) //declaration of apply
function
val res = apply(f,List(1,2,3,4,5)) // function execution
println(res)
}](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-29-2048.jpg)
 = left + x.toString() + right
}
object HighOrderFunctions_2 extends App {
def apply[A](f: A => String, v: A) = f(v)
val decorator = new Decorator("[", "]")
println(apply(decorator.layout, 100))
println(apply(decorator.layout, "100"))
}](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-30-2048.jpg)

 = {
lazy val y = x //memoization
val ret = if (c) {
(y, y)
} else {
(x, x) // evaluated twice
}
ret
}
val v0 = evaluateif(false, {println("evaluate0") ; 100})
println(v0)
println("--------------------")
val v1 = evaluateif(true, {println("evaluate1") ; 100})
println(v1)
}
$> scala CallByNeedCallByName
evaluate0
evaluate0
(100,100)
--------------------
evaluate1
(100,100)](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-32-2048.jpg)

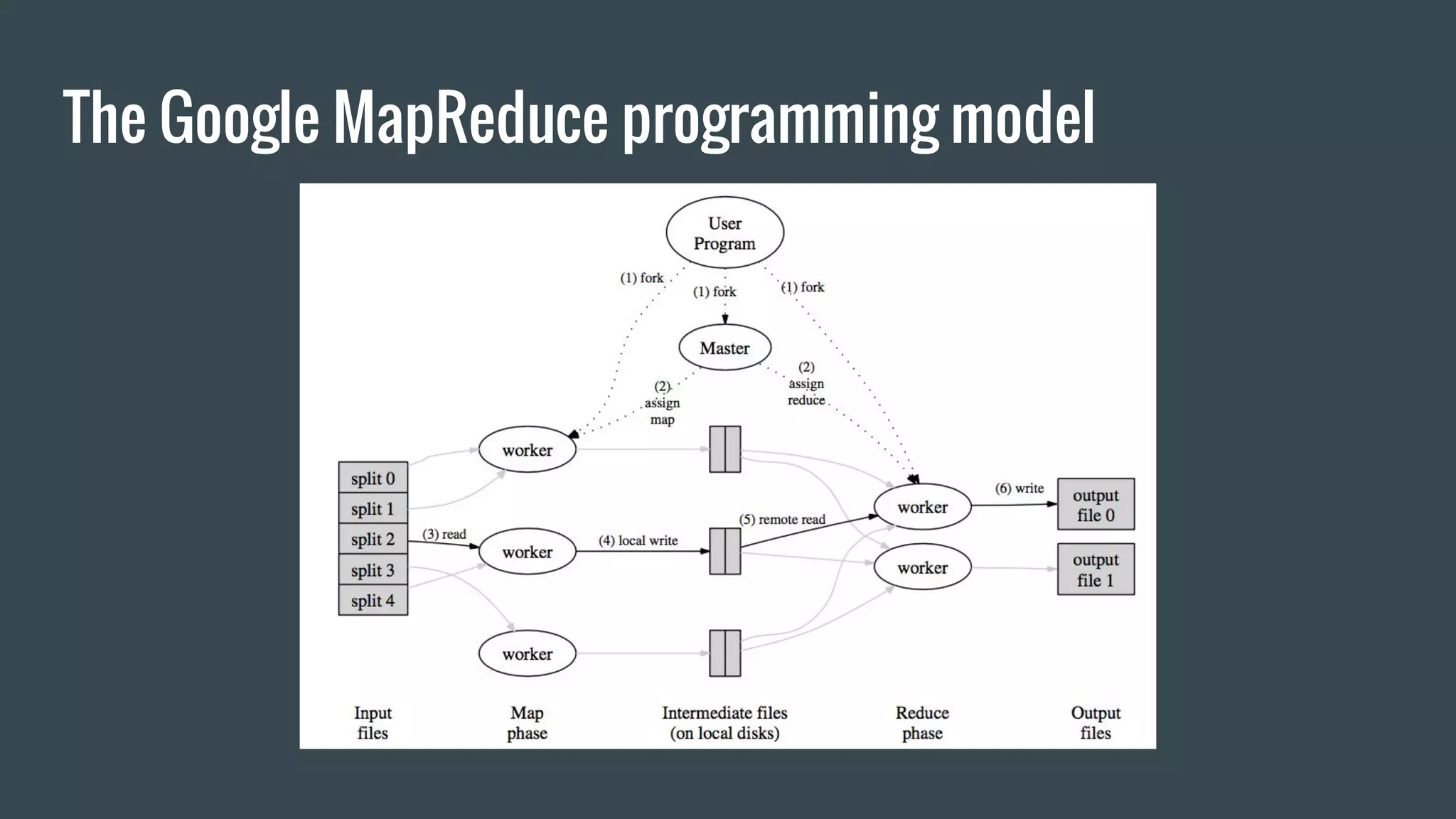
![MapReduce: the origins of spark computational model
● Google published in 2004 the paper: “MapReduce: Simplified
Data Processing on Large Clusters” [Dean , Ghemawat]
● The paper present the MapReduce programming abstraction
(and a proprietary implementation) to solve three main
aspects of parallel computation:
○ fault tolerance
○ distribution and balancing of the computing task
○ distribution of the data](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-34-2048.jpg)










![Spark: the spark shell
angelo$ spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/11/20 18:25:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using
builtin-java classes where applicable
16/11/20 18:25:04 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.11.132:4040
Spark context available as 'sc' (master = local[*], app id = local-1479662703790).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 2.0.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_45)
Type in expressions to have them evaluated.
Type :help for more information.
scala>](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-46-2048.jpg)
![Spark: SparkContext.parallelize
● The parallelize function provided by SparkContext transform
a collection (i.e. a scala Seq, or Array) into an RDD which can
be operated in parallel:
scala> val collection = List(1,2,3,4)
collection: List[Int] = List(1, 2, 3, 4)
scala> val rdd = sc.parallelize(collection)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at
parallelize at <console>:31](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-47-2048.jpg)
![Spark: persist
● RDD provide a persist functions to store partitions in order
to reuse them in other actions with benefits for the
performance
● Caching functions are key tool for iterative algorithms
scala> rdd.persist(StorageLevel.MEMORY_ONLY)
res12: rdd.type = ParallelCollectionRDD[2] at parallelize at
<console>:26](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-48-2048.jpg)
![Spark: SparkContext.broadcast
● Broadcast variable are read only variables cached in memory
on each node, they can be used to minimize communication
costs when multiple stages need the same data
scala> sc.broadcast(Map(1->"a", 2-> "b"))
res13:
org.apache.spark.broadcast.Broadcast[scala.collection.immutable.Ma
p[Int,String]] = Broadcast(0)](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-49-2048.jpg)



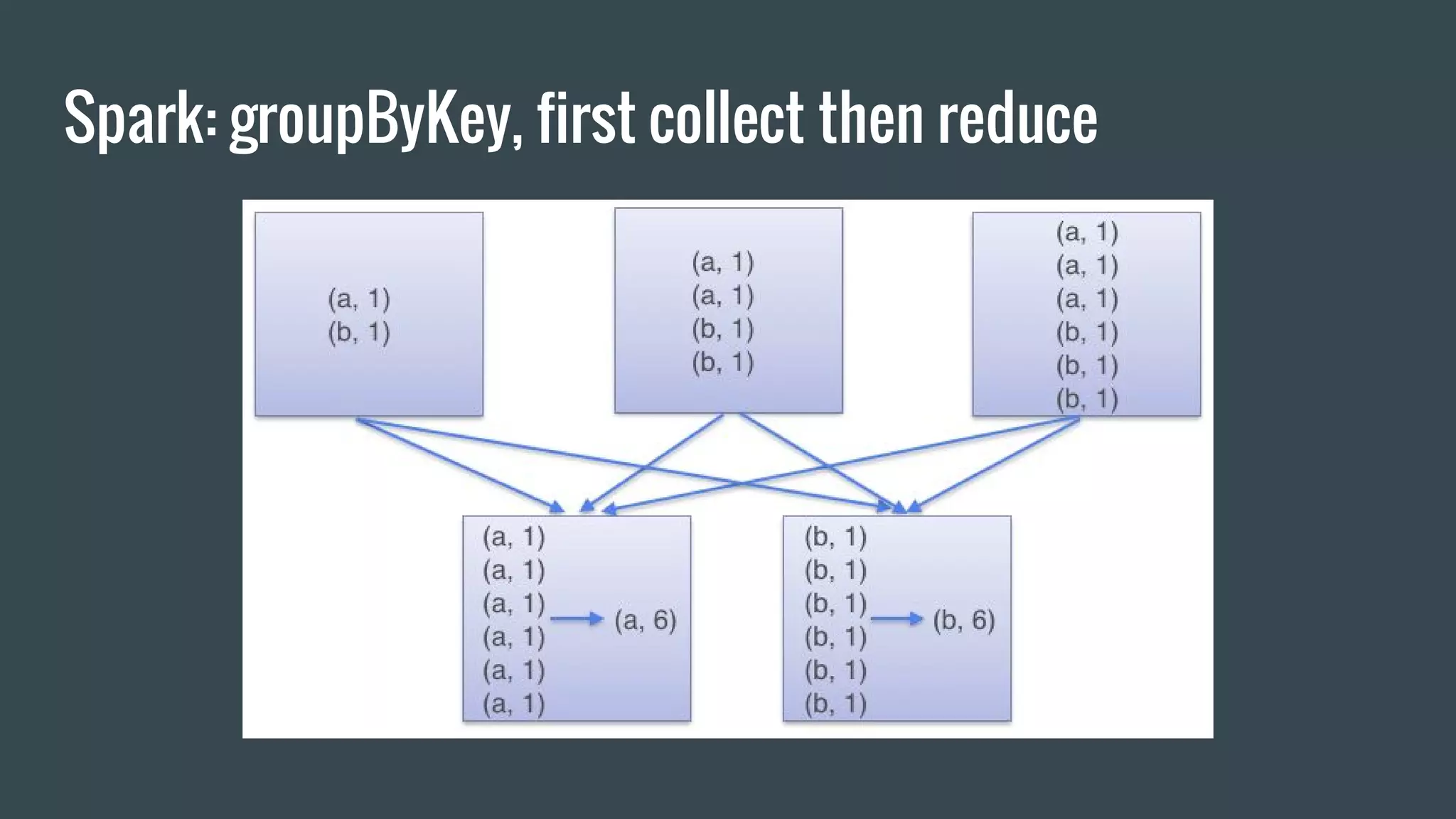
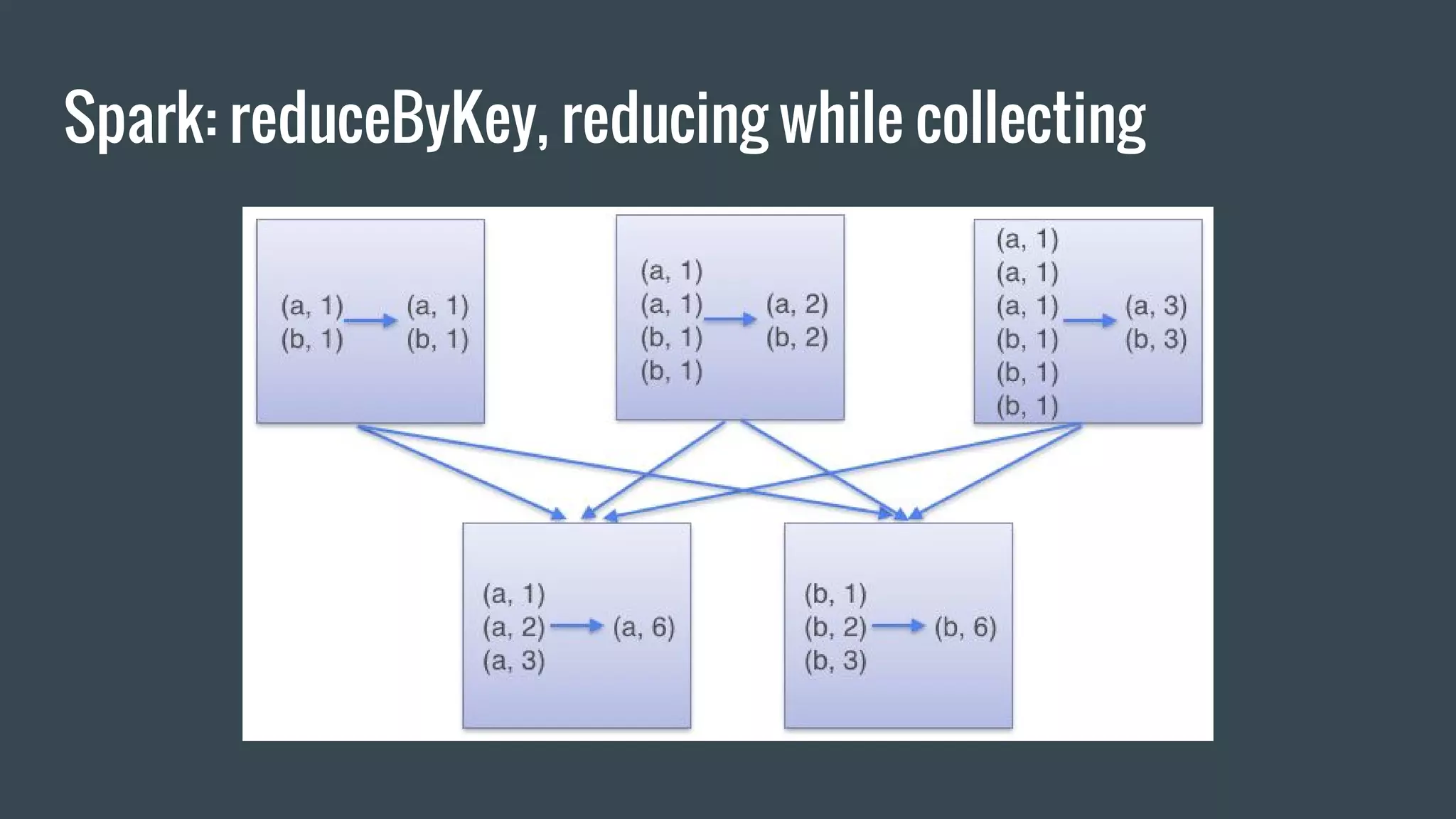


![Spark: Job submission
To submit jobs to Spark we will use the spark-submit
executable:
./bin/spark-submit --class <main-class> --master <master-url> --deploy-mode
<deploy-mode>
--conf <key>=<value>
... # other options
<application-jar>
[application-arguments]](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-58-2048.jpg)










![Exercise #2: weight terms by TF-IDF, specification
● The program will create and serialize an RDD with the dictionary of terms
occurring in the corpus, the output format will be:
○ RDD[(String, (Long, Long)] which is RDD[(<term>, (<term_id>,
<overall_occurrence>))]
● The program will create and serialize an RDD with the sentences annotated
with TF-IDF, the output format will be:
○ RDD[(Long, Map[String, (Long, Long, Long, Double)])] which is:
RDD[(<doc_id>, Map[<term>, (<term_raw_freq>, <term_id>,
<overall_occurrence>, <tf-idf>)])]
● The program will support a boolean flag which specify whether to serialize in
text format or in binary format](https://image.slidesharecdn.com/introductiontostreamingcomputationwithspark-161202223332/75/Introduction-to-parallel-and-distributed-computation-with-spark-69-2048.jpg)































































![[Start] Scala](https://cdn.slidesharecdn.com/ss_thumbnails/start-scala-121223013244-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

