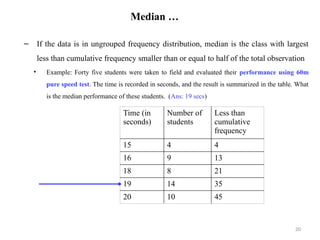
This document discusses measures of central tendency, which summarize data sets using values such as mean, median, and mode. It defines and illustrates the properties and calculations of these measures, including arithmetic, geometric, and harmonic means. Additionally, it touches on quantiles, and the importance of measures of dispersion to gauge the variability of data.



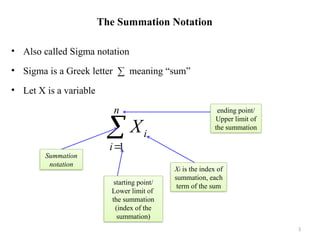






![Weighted Mean
• Weighted mean is calculated when certain values in a data set are more
important than the others.
• A weight wi is attached to each of the values xi to reflect this importance.
• The weighted mean is computed as
• Example: CGPA of a students (each result is weighted by credit of a course) [Ans:
2.88]
10
k
i
i
k
i
i
i
w
w
x
w
X
1
1](https://image.slidesharecdn.com/chapter221-241221112026-aca2dd03/85/Introduction-to-Measurement-CHAPTER-2-2-1-pptx-10-320.jpg)