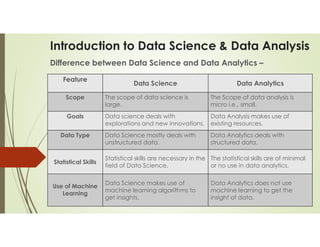
Data science and data analytics are related fields focused on extracting knowledge from data, but they have distinct focuses. Data science is a broader, interdisciplinary field that encompasses data analytics and includes activities like machine learning, algorithm development, and predictive modeling. Data analytics, on the other hand, is more focused on analyzing past data to understand trends and inform business decisions. Essentially, data science can be seen as the overarching field, while data analytics is a specific task within it.





























































![Introduction to Datascience [R20DS501].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontodatasciencer20ds501-251019152941-d61074d9-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

