Download to read offline











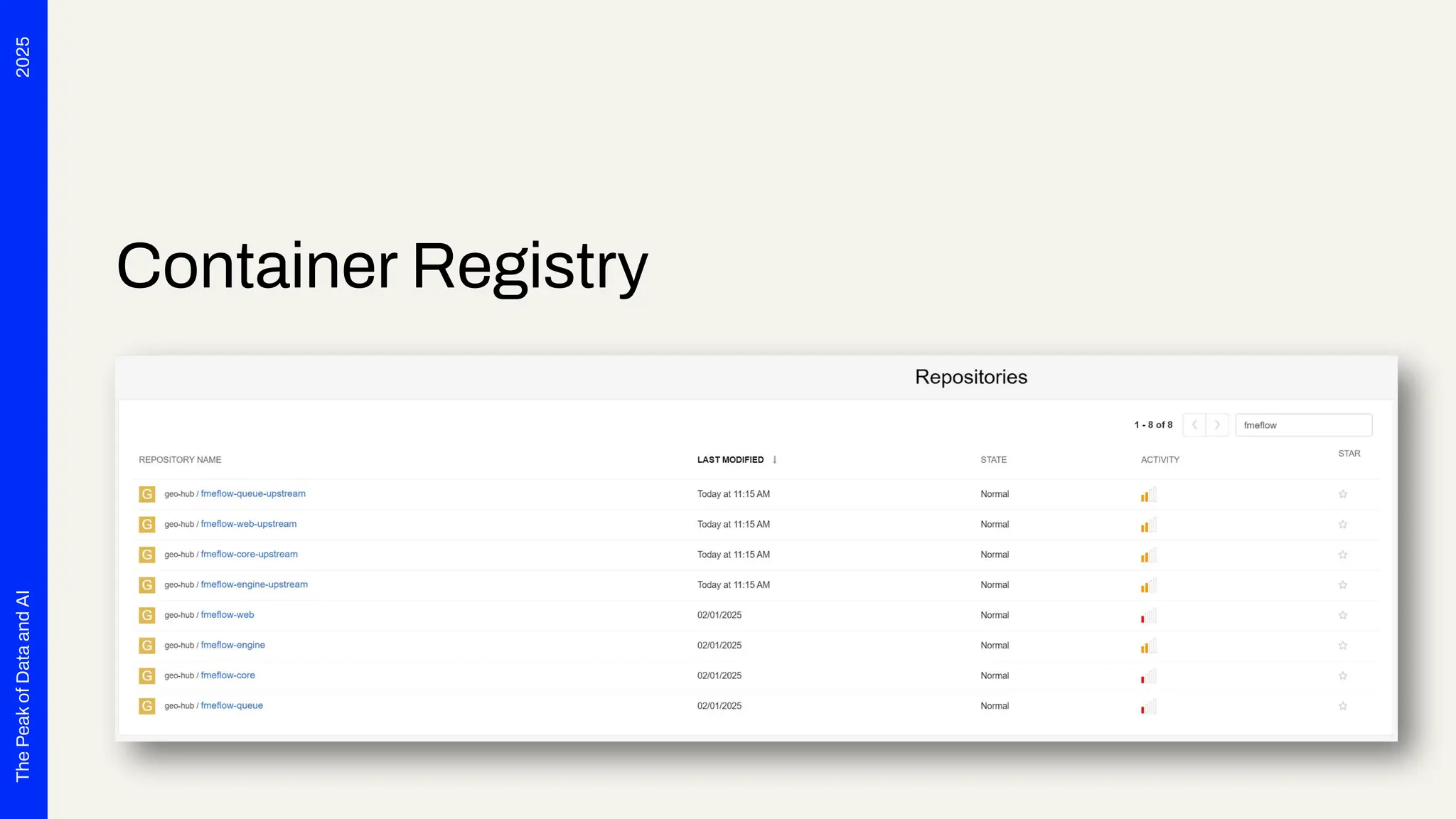


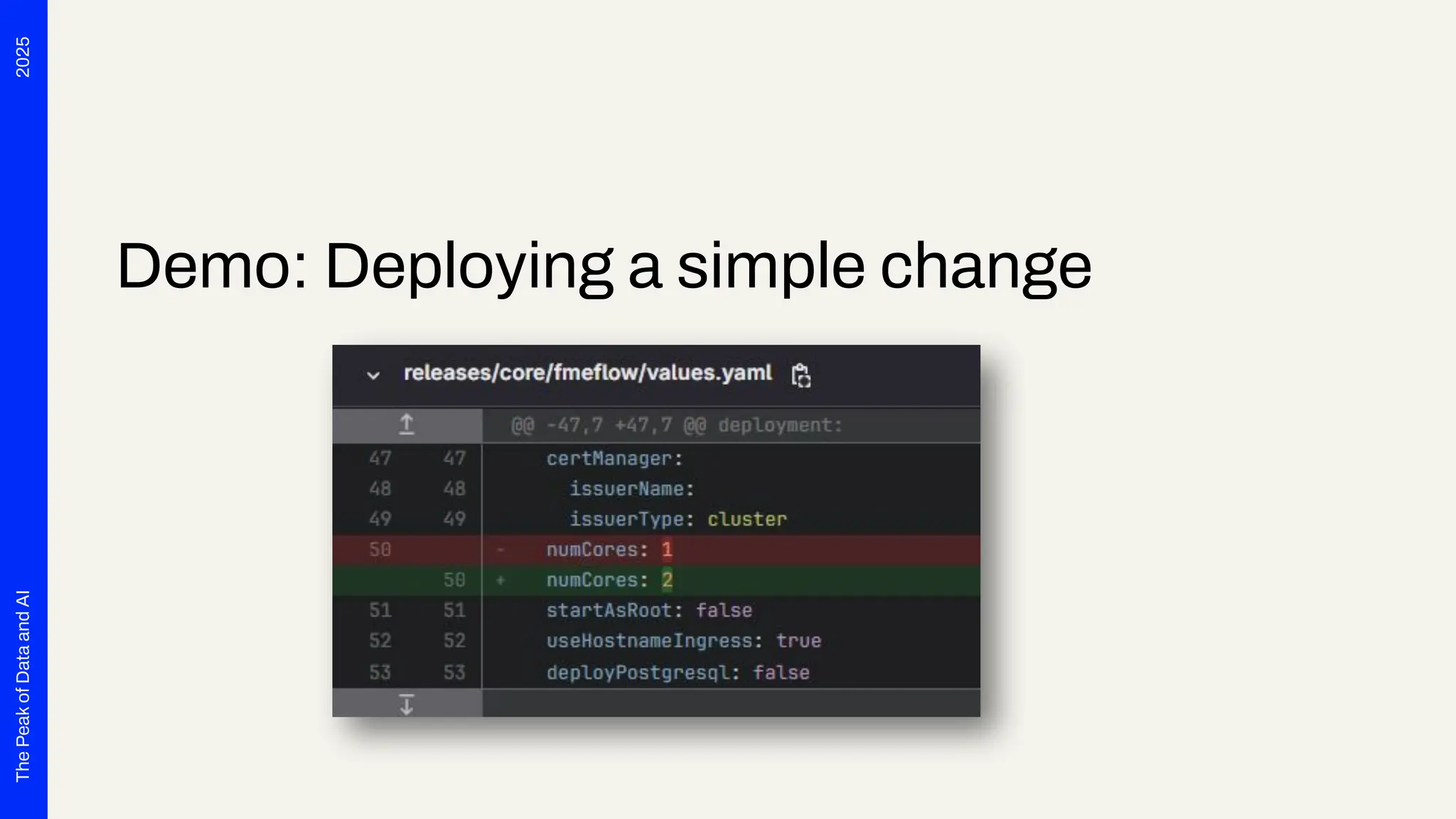
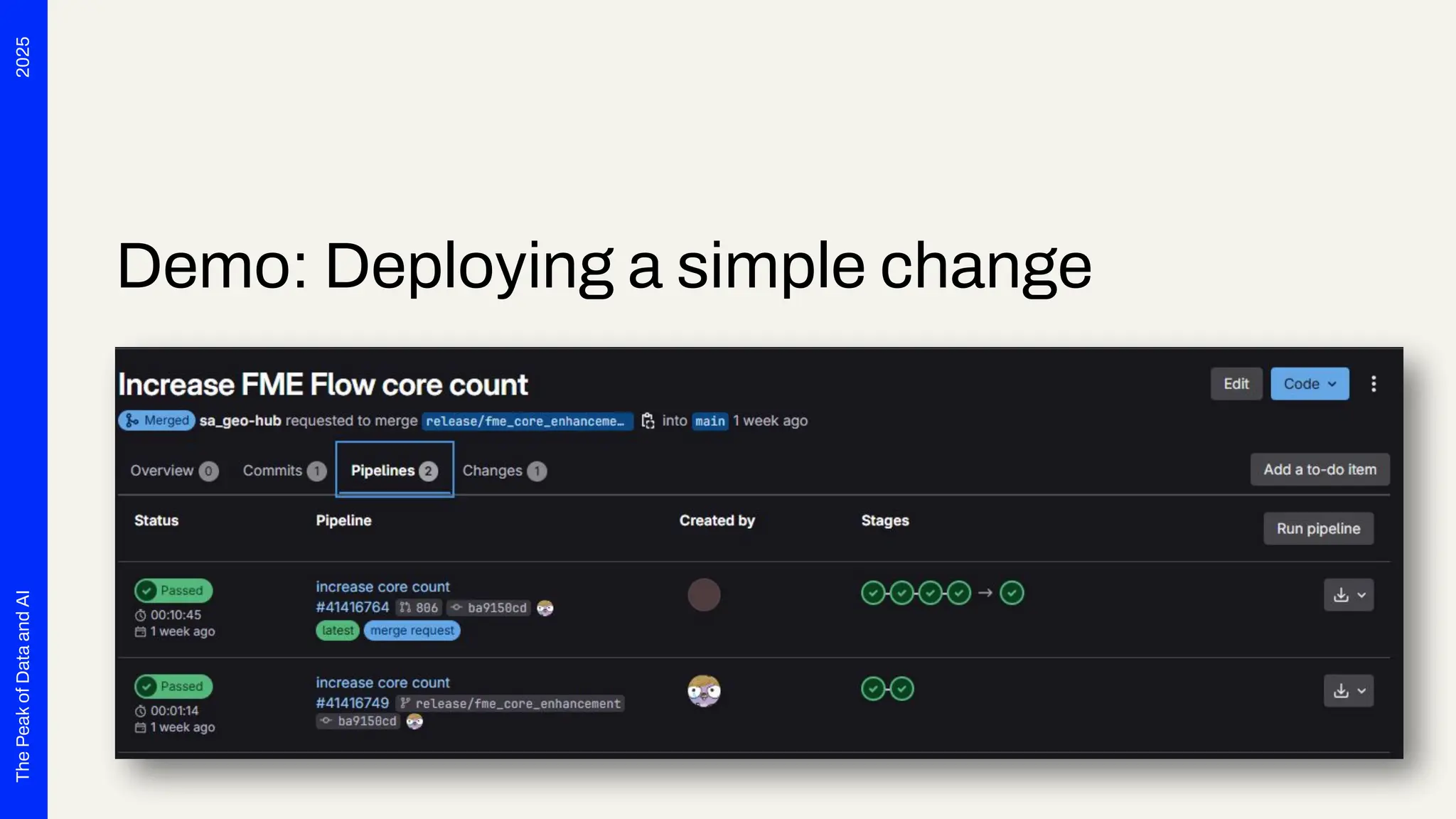
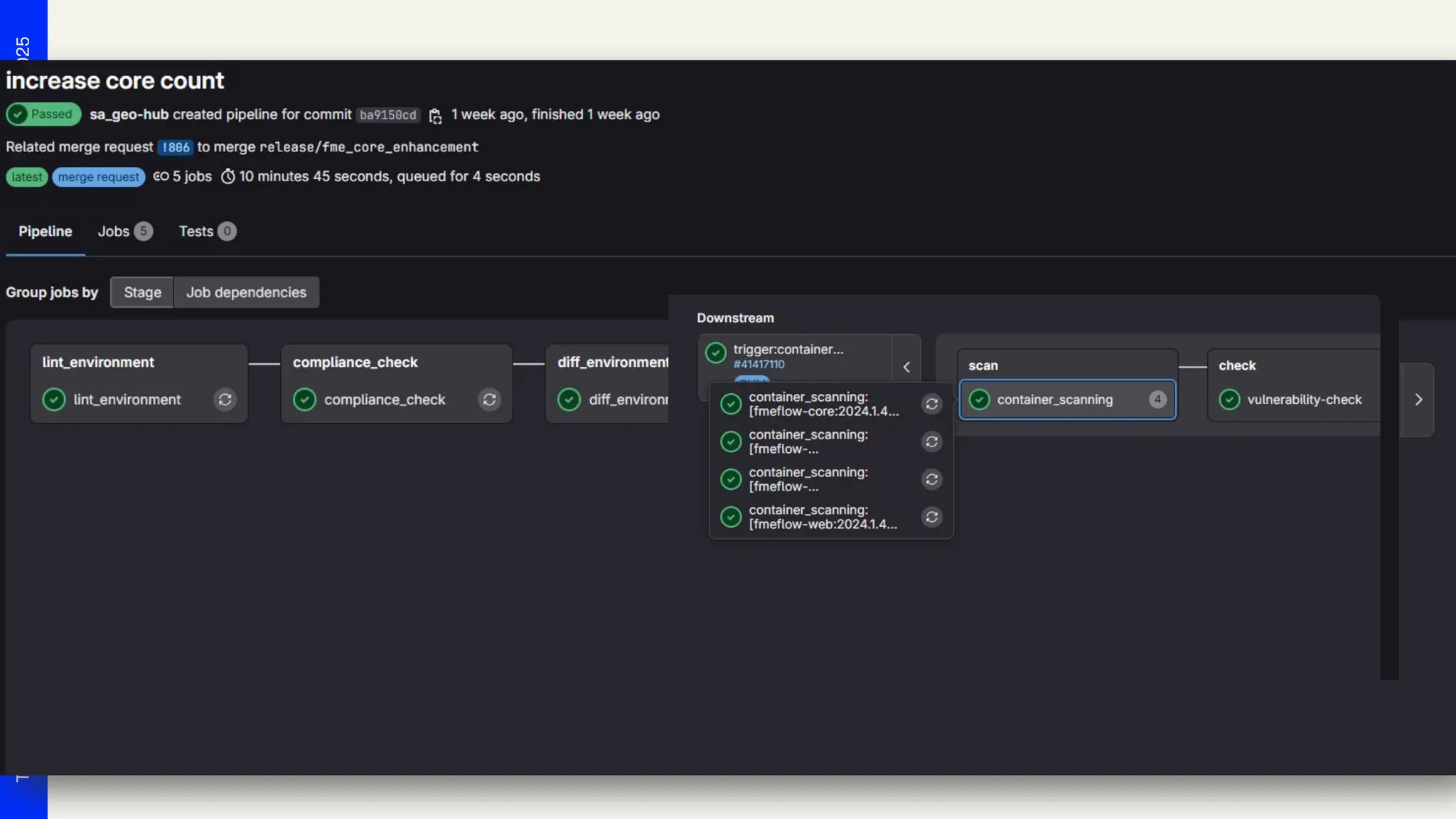
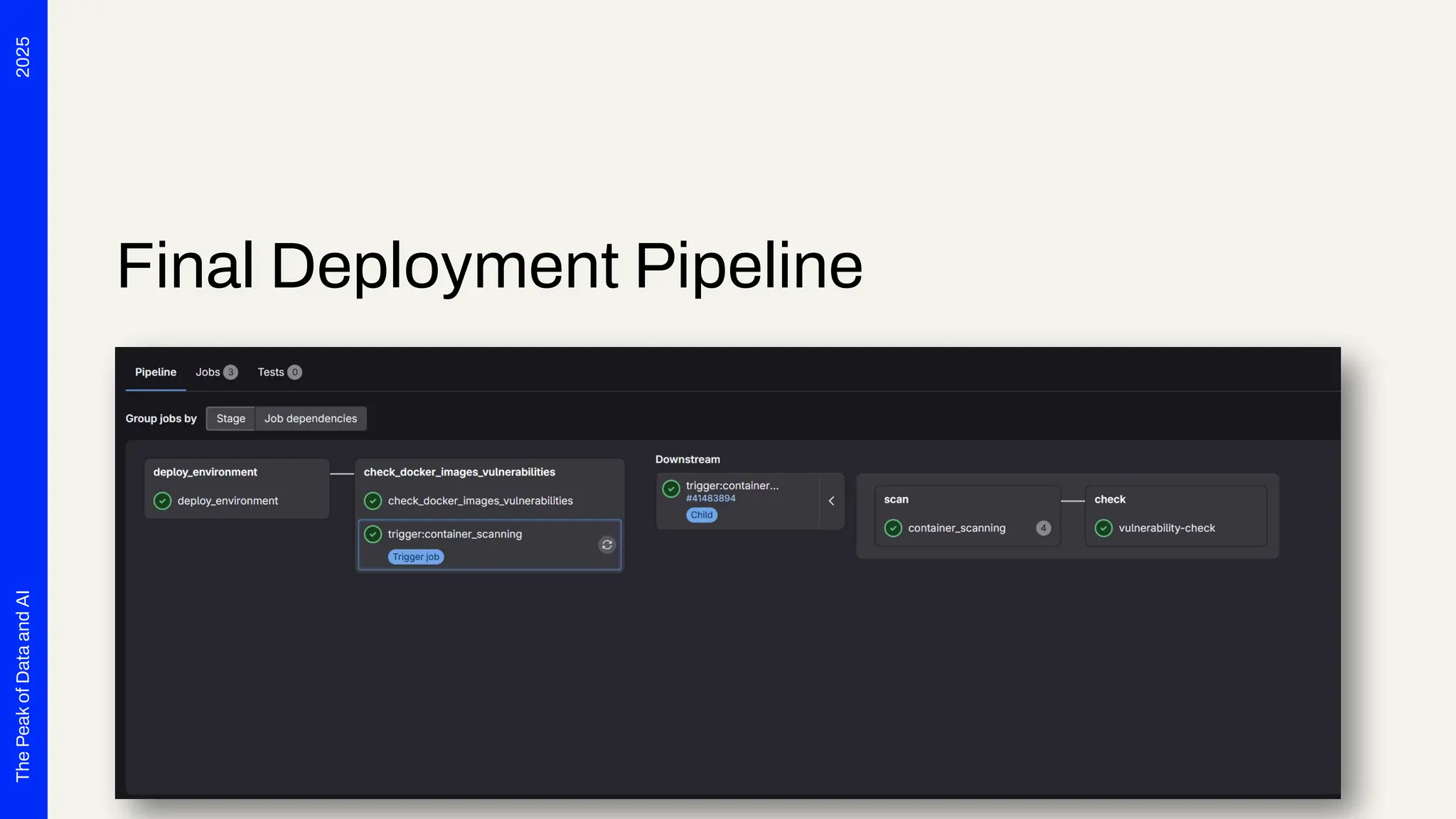


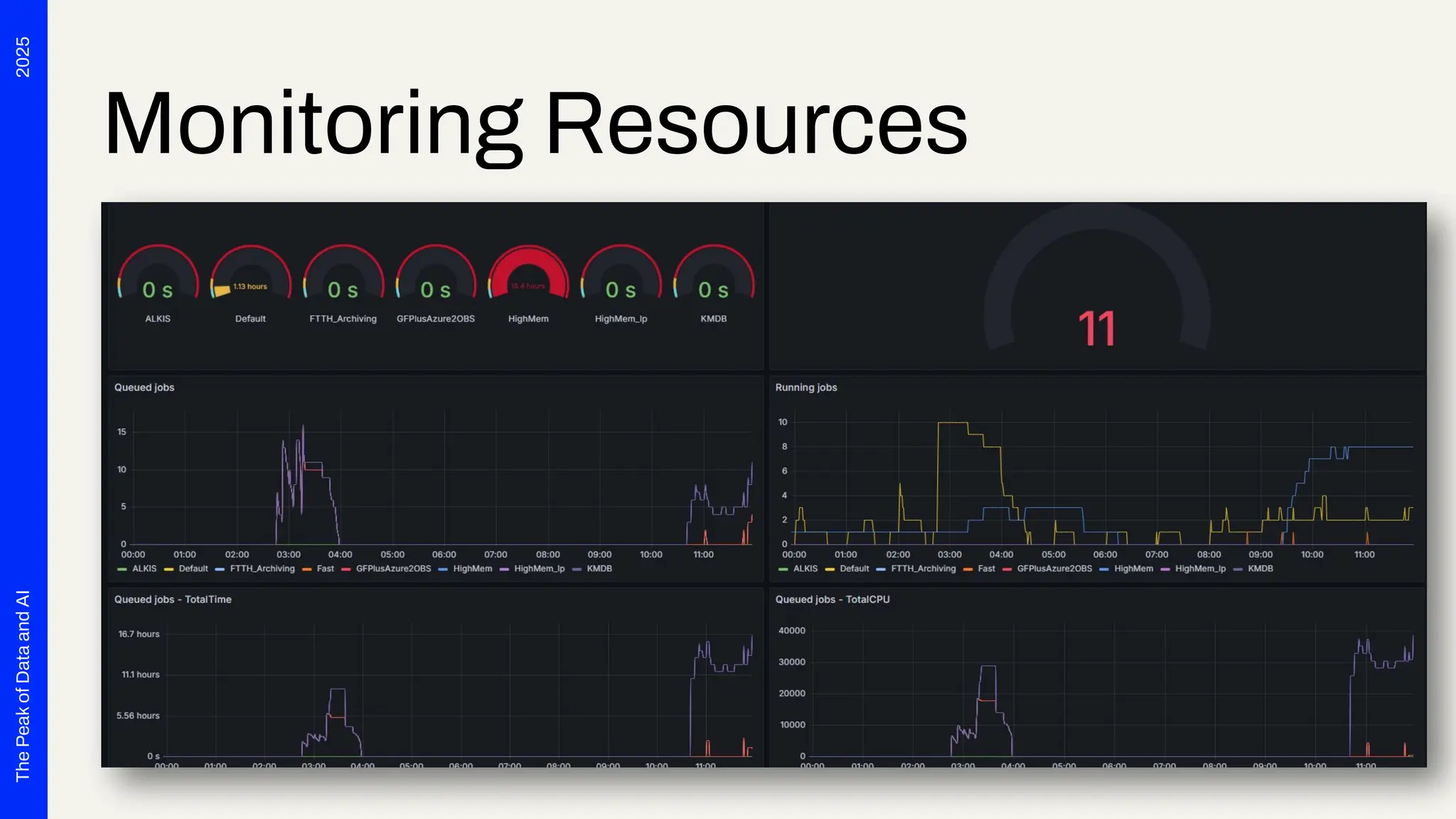

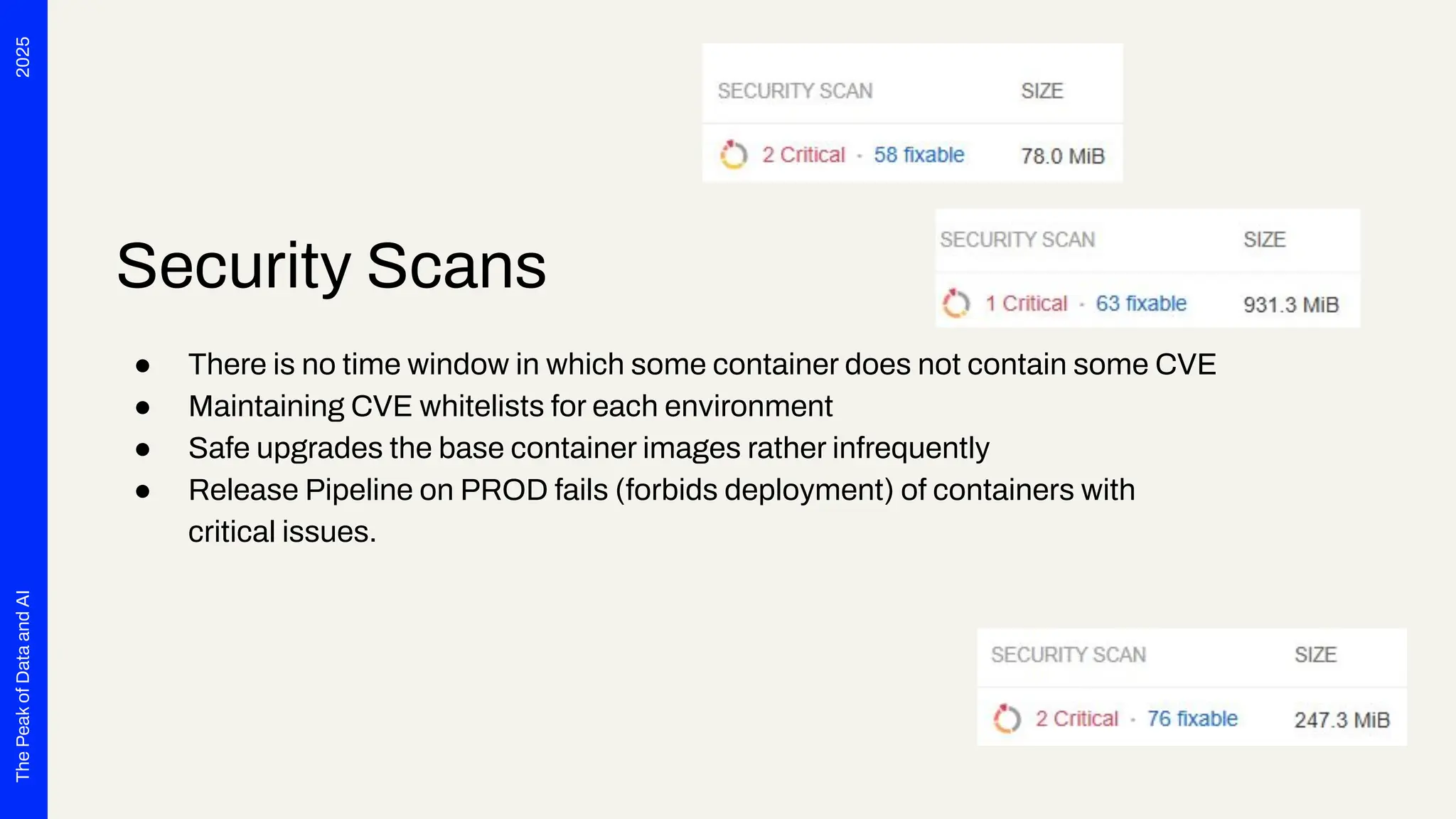









Seven years ago, we launched a project at Deutsche Telekom with the aim of developing end-to-end automation to support planning processes for the expansion of fiber optics (Fiber To The Home) throughout Germany. The requirements were tempting: cloud-based, microservices, scalability and OSS preferred. Thanks to Safe Software's innovation, we were able to deploy FME Flow for K8s (FME Server 2017 Beta) right from the start. The FME platform has thus become a central component of Telekom's GDI. In addition to more traditional data integration tasks, FME fulfills the role of an interface for the systems involved. In this presentation, we want to report on our experiences with the use of FME Flow for K8s/OpenShift, provide technical insight into the deployment via Gitlab Pipelines and report on future challenges for automated scaling, IT security and the tension between the maximum flexibility of FME and the requirements for robust IT operations. The audience can take away valuable tips and experiences for the use of multiple FME Flow instances in large companies from this presentation.

































































