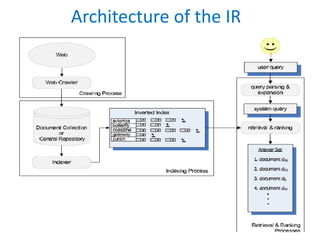
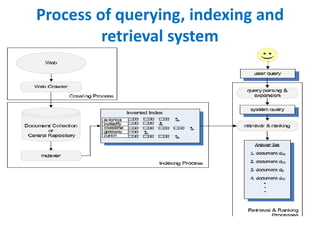
The document discusses the architecture and components of information retrieval (IR) systems, including document collection, preprocessing, indexing, query processing, search and retrieval, user interface, and relevance feedback. It elaborates on various information retrieval models like the Boolean model, Vector Space Model, and Probabilistic model, illustrating how queries are formulated and matched against indexed documents. Additionally, it describes different visualization techniques such as scatter plots, bar charts, and heat maps, which help display search results and data relationships.