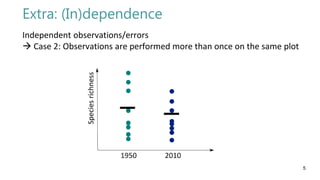
This document discusses the assumption of independence in statistical analysis and provides two examples of dependent data: 1) observations grouped within a dataset where measurements within the same group are related, and 2) repeated measures where observations are taken multiple times on the same plot over time. Proper statistical methods account for dependence by incorporating grouping structure or accounting for repetition.

![Extra: (In)dependence
Independent observations/errors
Case 1: groups in your data
2
Species richness ~ [H+]](https://image.slidesharecdn.com/independence-211104155828/85/Independent-vs-dependent-samples-2-320.jpg)
![Extra: (In)dependence
Independent observations/errors
Case 1: groups in your data
3
Species richness ~ [H+]](https://image.slidesharecdn.com/independence-211104155828/85/Independent-vs-dependent-samples-3-320.jpg)
![Extra: (In)dependence
Independent observations/errors
Case 1: groups in your data
4
Species richness ~ [H+] + group](https://image.slidesharecdn.com/independence-211104155828/85/Independent-vs-dependent-samples-4-320.jpg)