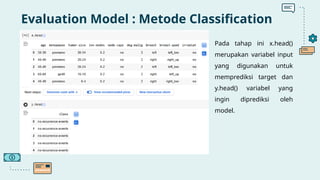
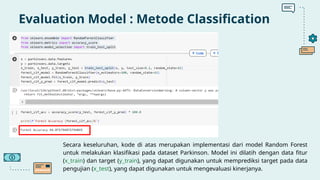
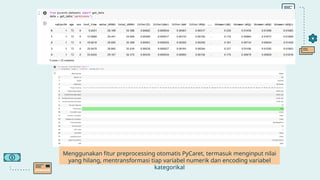
Dokumen ini membahas implementasi machine learning dalam analisis penyakit Parkinson menggunakan dataset suara biomedis untuk membedakan individu sehat dan penderita Parkinson. Model klasifikasi Random Forest mencapai akurasi 94,87%, menunjukkan efektivitas tinggi dalam prediksi. Selain itu, model Light Gradient Boosting Machine menunjukkan performa terbaik dalam metrik evaluasi lainnya.