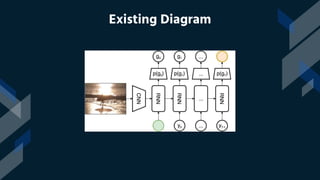
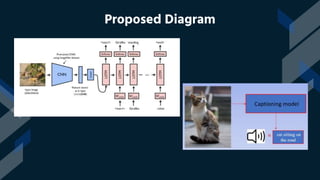
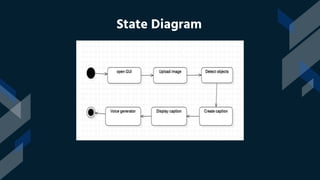
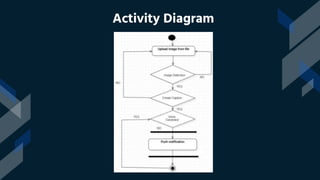
This project introduces an image captioning system that incorporates sound to generate more comprehensive captions. Two extensively trained models are combined - one for computer vision and one for natural language processing. Sound recommendations are made based on the image scene. The system achieves a top 5 accuracy of 67% and top 1 accuracy of 53%, setting a new standard. It is the first image captioning system to offer this level of accuracy while also incorporating audio. This has significant implications for helping visually impaired individuals understand visual content more vividly.




















![[Image Results] Java Build Tools: Part 2 - A Decision Maker's Guide Compariso...](https://cdn.slidesharecdn.com/ss_thumbnails/java-build-tools-part-2-maven-gradle-ant-ivy-140121040954-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























































