



















![ratio: 2)">
<!-- Device monocromatici (Kindle, etc..) -->
<link rel="stylesheet" href="mono.css" media="screen and (monochrome)">
Bene, completiamo questo capitolo aggiungendo icone e charset:
<head>
<meta charset="utf-8">
<!-- ..gli altri tag.. -->
<link rel="icon" href="standard.gif" sizes="16x16" type="image/gif">
<link rel="icon" href="iphone.png" sizes="57x57" type="image/png">
<link rel="icon" href="vector.svg" sizes="any" type="image/svg+xml">
</head>
Come potete notare è ora possibile specificare un attributo sizes per ogni icona, in questo modo lo
user agent può liberamente scegliere quale icona abbia le dimensioni più adatte. Ci sono due motivi
che giustificano l’inserimento della direttiva ‘charset’ in questo progetto: in primo luogo la nuova
sintassi è molto più succinta della passata, seppur ancora valida:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
In seconda istanza è intenzione dell’autore sottolineare come sussistano reali rischi di sicurezza legati
all’assenza di questa direttiva.
Dalla prossima lezione analizzeremo nel dettaglio i singoli elementi che concorrono alla costituzione
della nuova impalcatura semantica del linguaggio.
Header
Funzioni e dati tecnici
Il tag header serve a rappresentare "un gruppo di ausili introduttivi o di navigazione". Tale
definizione, seppure apparentemente vaga, contiene in sé i concetti chiave per comprendere appieno
la funzione di questo tag:
1. L'elemento <header> è un contenitore per altri elementi.
2. L'elemento <header> non va confuso con quella che è la testata/intestazione principale di un
documento (quella che oggi si definisce in genere con il tag <h1>).
3. La natura e gli scopi dell'elemento <header> non dipendono dalla sua posizione nel documento,
ma dai suoi contenuti (ausili alla navigazione o elementi introduttivi).
4. Il suo uso non è obbligatorio e in alcuni casi può risultare superfluo se non utilizzato in maniera
appropriata.
<header>
<h1>Questo è un titolo</h1>
<h2>Questo è un sotto-titolo</h2>
[...]](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-22-320.jpg)
![</header>
Header: esempi concreti
Riprendendo il nostro progetto guida, dove nella lezione precedente
(http://xhtml.html.it/guide/lezione/4966/panoramica-sui-content-model-e-presentazione-del-primo-
progetto-guida/) abbiamo definito il contenuto dell'<head>:
<head>
<meta charset="utf-8">
<title> We5! Il blog della guida HTML5 </title>
<link rel="stylesheet" href="monitor.css" media="screen">
<link rel="stylesheet" href="printer.css" media="print">
<link rel="stylesheet" href="phone_landscape.css"
media="screen and (max-device-width: 480px) and (orientation: landscape)">
<link rel="stylesheet" href="phone_portrait.css"
media="screen and (max-device-width: 480px) and (orientation: portrait)">
<link rel="icon" href="standard.gif" sizes="16x16" type="image/gif">
<link rel="apple-touch-icon" href="iphone.png" sizes="57x57" type="image/png">
<link rel="icon" href="vector.svg" sizes="any" type="image/svg+xml">
</head>
A questo punto possiamo iniziare a comporre il <body> del nostro documento partendo proprio con il
tag <header>, che con l'elemento <hgroup> (http://xhtml.html.it/guide/lezione/4973/hgroup/)
definisce il titolo principale del documento (del sito) e la cosiddetta tagline:
<header>
<hgroup>
<h1>We5! Il blog della guida HTML5</h1>
<h2>Approfittiamo fin da oggi dei vantaggi delle specifiche HTML5!</h2>
</hgroup>
</header>
Ma header non deve contenere necessariamente solo titoli <hn]]>! Se titolo e sottotitolo principali
sono certamente elementi introduttivi ai contenuti successivi, è naturalmente un ausilio di
navigazione una lista di link che andrà a formare la barra di navigazione principale del sito. Ecco come
possiamo completare la struttura del nostro primo <header>:
<header>
<hgroup>
<h1>We5! Il blog della guida HTML5</h1>
<h2>Approfittiamo fin da oggi dei vantaggi delle specifiche HTML5!</h2>
</hgroup>
<nav>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-23-320.jpg)

![<section>
<h1>L'ultimo post</h1>
<article>
[...]
</article>
</section>
Si noti, innanzitutto, come il tag <h1> che fa da titolo principale alla sezione non sia racchiuso in un
elemento <header>. Ribadiamo: non è obbligatorio inserire i titoli <hn]]> all'interno di un
contenitore<header>.
A questo punto, dobbiamo definire due elementi fondamentali per la struttura di un post di blog: il
titolo e la data. Sono certamente ausili introduttivi, secondo la definizione da cui siamo partiti. é più
che legittimo e sensato, pertanto, racchiuderli in un tag <header>:
<section>
<h1>L'ultimo post</h1>
<article>
<header>
<time datetime="2010-11-22" pubdate>Lunedì 22 Novembre</time>
<h2>Nuove scoperte sul tag video!</h2>
</header>
<p>
[...]
</p>
</footer>
[...]
</footer>
</article>
</section>
Ecco quindi come il nostro articolo potrebbe essere rappresentato graficamente:
Figura 9 - Struttura del documento: header degli articoli](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-25-320.jpg)


![schema template html5 [footer]
Così come l'intero documento, ogni articolo del nostro blog avrà un <footer> contenente il nome
dell'autore ed altre eventuali informazioni aggiuntive:
<section>
<h1>L'ultimo post</h1>
<article>
<header>
[...]
</header>
<p>
[...]
</p>
<footer>
<dl>
<dt>autore:</dt>
<dd><address><a href="mailto:sandro.paganotti@gmail.com">Sandro Paganotti</a>
</address></dd>
<dt>categoria: </dt>
<dd><a href="categoria/multimedia">multimedia</a>,</dd>
<dt>tags: </dt>
<dd><a href="tags/video">video</a>,</dd>
<dd><a href="tags/canvas">canvas</a>,</dd>
<dt>permalink: </dt>
<dd><a href="2010/22/11/nuove-scoperte-sul-tag-video">permalink</a>,</dd>
<dt>rank:</dt>
<dd><meter value="3.0" min="0.0" max="5.0" optimum="5.0">ranked 3/5</meter></
dd>
</dl>
</footer>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-28-320.jpg)
![</article>
</section>
È da notare la scelta di inserire le informazioni riguardanti l'autore dell'articolo all'interno del tag
<dl>; infatti nella specifica HTML5 questo elemento viene ridefinito come contenitore di metadati e
quindi semanticamente corretto all'interno del nostro <footer>.
Ecco quindi come il nostro articolo potrebbe essere rappresentato graficamente, tutte le informazioni
contenute nel <footer> per comodità abbiamo deciso di chiamarle metadati:
Figura 11 - Struttura del documento: footer degli articoli
L'elemento <footer> potrebbe essere inserito anche all'inizio di un documento subito dopo il <body>
oppure all'apertura di un tag <article> (http://xhtml.html.it/guide_preview/lezione/4970/article/)
ma in questi casi non dovrebbe contenere elementi introduttivi riguardo il contenuto della sezione che
lo contiene; il suo uso in questa posizione potrebbe essere dovuto solamente a ragioni pratiche come
ad esempio la duplicazione del <footer> in fondo alla pagina quando i contenuti della stessa sono
molto lunghi:
<body>
<footer>
<a href="#indice">Torna all'indice</a>
</footer>
<section>
[Contenuti molto lunghi...]
<section>
<section>
[Contenuti molto lunghi...]
<section>
<section>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-29-320.jpg)
![[Contenuti molto lunghi...]
<section>
<footer>
<a href="#indice">Torna all'indice</a>
</footer>
</body>
Nella prossima lezione parleremo del tag <section> e della sua importanza nel sezionare la pagina in
blocchi semanticamente distinti.
Tabella del supporto sui browser
Nuovi tag semantici e strutturali
<footer> 9.0+ 3.0+ 3.1+ 5.0+ 10.0+
Section
Funzioni e dati tecnici
Il tag <section>, secondo la definizione presente nella specifica HTML5, rappresenta una sezione
generica di un documento o applicazione. L'elemento <section>, in questo contesto, individua
un raggruppamento tematico di contenuti,ed in genere contiene un titolo introduttivo.
Vediamo quindi quali sono i punti fondamentali da ricordare riguardo il suo utilizzo:
1. l'elemento <section> non deve essere utilizzato in sostituzione del <div> per impostare
graficamente la pagina; inoltre è fortemente consigliato utilizzare i <div> anche quando
risultano più convenienti per gli script;
2. l'elemento <section> non deve essere preferito all'elemento <article> quando i contenuti
possono essere ripubblicati anche su altri siti;
3. l'elemento <section> e l'elemento <article> non sono indipendenti ed esclusivi: possiamo
avere sia un <article> all interno di un <section> che viceversa.
<article>
<section>
<h1>Titolo 1</h1>
<p>Testo correlato al titolo 1.</p>
</section>
<section>
<h1>Titolo 2</h1>
<p>Testo correlato al titolo 2.</p>
</section>
</article>
L'elemento <section> può essere utilizzato in combinazione con l'attributo cite attraverso il quale è
possibile specificare l'url dalla quale si stanno riportando i contenuti.](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-30-320.jpg)
![Section: esempi concreti
Come abbiamo visto nei capitoli precedenti, il codice del nostro progetto inizia a prendere una forma
più chiara e definita: infatti, dopo aver compreso l'utilità semantica
dell'<header>(http://xhtml.html.it/guide_preview/lezione/4967/header/) e del <footer>
(http://xhtml.html.it/guide_preview/lezione/4968/footer/), capiamo come utilizzare l'elemento
<section> all'interno del nostro blog.
Per strutturare la pagina raggruppando i contenuti correlati, in ordine decrescente incontriamo le
prime due grandi macrosezioni del blog: "l'ultimo post" e "i post meno recenti" contenuti quindi in
due<section>:
<section>
<h1>L'ultimo post</h1>
<article>
[contenuto del post...]
<section>
[commenti...]
</section>
</article>
</section>
<section>
<h1>Post meno recenti</h1>
<article>
[contenuto del post...]
</article>
<article>
[contenuto del post...]
</article>
<article>
[contenuto del post...]
</article>
</section>
Nel seguente schema abbiamo realizzato graficamente ciò che il codice semanticamente rappresenta
nel nostro progetto:
Figura 12 - Struttura del documento: sezioni principali](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-31-320.jpg)
![Nel nostro progetto le <section>, oltre a poter raggruppare i vari <article>
(http://xhtml.html.it/guide_preview/lezione/4970/article/), sono presenti anche all'interno del primo
<article> per suddividere i commenti dal contenuto del post. La sezione dei commenti a sua volta
contiene un'altra sezione contenente il form per l'inserimento di un nuovo commento:
<article>
[contenuto del post...]
<section>
<article>
[commento1...]
</article>
<article>
[commento2...]
</article>
<article>
[commento3...]
</article>
<section>
[Inserisci un nuovo commento...]
</section>
</section>
</section>
</article>
In questo modo il post è diviso in maniera molto netta rispetto ai propri contenuti solo con l'ausilio dei
tag HTML5, separando quindi i commenti che sono una sezione aggiuntiva eventualmente anche
eliminabile dall'argomento principale trattato all'interno dell'articolo.](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-32-320.jpg)


![<p>
Attraverso un utilizzo sapiente del tag canvas è possibile leggere uno stream
di dati proveniente da un tag video e <mark>manipolarlo in tempo reale</mark>.
</p>
<footer>
<dl>
<dt>autore: </dt>
<dd><address><a href="mailto:sandro.paganotti@gmail.com">Sandro Paganott
i</a></address></dd>
<dt>categoria: </dt>
<dd><a href="categoria/multimedia">multimedia</a>,</dd>
<dt>tags: </dt>
<dd><a href="tags/video">video</a>,</dd>
<dd><a href="tags/canvas">canvas</a>,</dd>
<dt>permalink: </dt>
<dd><a href="2010/22/11/nuove-scoperte-sul-tag-video">permalink</a>,</dd
>
<dt>rank:</dt>
<dd><meter value="3.0" min="0.0" max="5.0" optimum="5.0">ranked 3/5</met
er></dd>
</dl>
</footer>
<section>
<h3>Commenti</h3>
<article>
<h4>
<time datetime="2010-11-22" pubdate>Lunedì 22 Novembre</time>
Angelo Imbelli ha scritto:
</h4>
<p>C'è un bell'esempio sulla rete: effetto ambi-light!</p>
<footer>
<address><a href="mailto:ambelli@mbell.it">Angelo Imbelli</a></addre
ss>
</footer>
</article>
<article>
<h4>
<time datetime="2010-11-23" pubdate>Martedì 23 Novembre</time>
Sandro Paganotti ha scritto:
</h4>
<p>Bellissimo! Grazie per la segnalazione!</p>
<footer>
<address><a href="mailto:sandro.paganotti@gmail.com">Sandro Paganott
i</a></address>
</footer>
</article>
<section>
<h4>Inserisci un nuovo commento:</h4>
<form>
[ campi form per inserire un nuovo commento]
</form>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-35-320.jpg)

![<article> 9.0+ 3.0+ 3.1+ 5.0+ 10.0+
Nav
Funzioni e dati tecnici
Il tag <nav> è uno degli elementi introdotti nelle specifiche HTML5 di più facile comprensione.
Infatti, rappresenta una sezione di una pagina che contiene link (collegamenti) ad altre pagine o
a parti interne dello stesso documento; quindi, in breve, una sezione contenente link di
navigazione.
A questo punto potremmo potremmo porci una domanda: come mai un elemento così scontatamente
fondamentale è stato introdotto solamente adesso? La risposta potrebbe essere che, così come per i
tag visti nelle precedenti lezioni, finalmente si è cercato di incentivare l'uso di standard condivisi
proponendo elementi che possano aiutare gli sviluppatori proprio perché molto vicini ai modelli
mentali oramai assimilati dagli esperti e di semplice comprensione per i novizi del mestiere.
Per poter utilizzare correttamente l'elemento <nav> dobbiamo ricordare i seguenti punti:
1. solo sezioni che sono costituite da grandi blocchi di navigazione sono appropriati per
l'elemento <nav>;
2. i link a pie' di pagina e le breadcumb non devono essere inseriti in una sezione <nav>;
3. l'elemento <nav> non sostituisce i link inseriti in elementi come gli <ul> o gli <ol> ma deve
racchiuderli.
<nav>
<ul>
<li>Questo è un link</li>
<li>Questo è un link</li>
<li>Questo è un link</li>
<li>Questo è un link</li>
[...]
</ul>
</nav>
Nav: esempi concreti
Prima di spiegare in che modo l'elemento <nav> può essere inserito nel progetto che abbiamo preso
come base, riassumiamo brevemente i tag spiegati nelle lezioni precedenti:
Con l'elemento <header> (http://xhtml.html.it/guide_preview/lezione/4967/header/) abbiamo
indicato il titolo introduttivo del blog più i titoli dei singoli articoli.
Con il <footer> (http://xhtml.html.it/guide_preview/lezione/4968/footer/) abbiamo racchiuso
le informazioni relative agli autori dei contenuti, i metadati e il copyright.
Con l'elemento <section> (http://xhtml.html.it/guide_preview/lezione/4969/section/) abbiamo
strutturato la parte centrale della pagina dividendola in due sezioni semanticamente distinte.
Infine abbiamo utilizzato <article> (http://xhtml.html.it/guide_preview/lezione/4970/article/)
per racchiudere i contenuti degli articoli.
A questo punto non possiamo che inserire i link presenti nell'<header> all'interno del tag <nav>:](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-37-320.jpg)

![esistono numerosi tipi di layout in cui il menu di navigazione può essere facilmente slegato dagli
elementi introduttivi di intestazione del documento.
Nel nostro esempio l'elemento <nav> è presente anche nella colonna laterale del blog (<aside>) e
racchiude un menu che ha come link le categorie nelle quali sono inseriti i vari articoli:
<aside>
<h1>Sidebar</h1>
<section>
<h2>Ricerca nel form:</h2>
<form>
[form di ricerca dei contenuti...]
</form>
</section>
<nav>
<h2>Categorie</h2>
<ul>
<li><a href="/categoria/multimedia">multimedia</a></li>
<li><a href="/categoria/text">marcatori testuali</a></li>
<li><a href="/categoria/form">forms</a></li>
</ul>
</nav>
</aside>
Per comprendere quale è la funzione dell'elemento <aside> che contiene il menu laterale non ci resta
quindi che leggere la prossima lezione.
Tabella del supporto sui browser
Nuovi tag semantici e strutturali
<nav> 9.0+ 3.0+ 3.1+ 5.0+ 10.0+
Aside
Funzioni e dati tecnici
L'elemento <aside> rappresenta una sezione di una pagina costituita da informazioni che sono
marginalmente correlate al contenuto dell'elemento padre che la contiene, e che potrebbero
essere considerate distinte da quest'ultimo. Questo è ciò che viene indicato nelle specifiche HTML5,
ma è facile immaginare l'utilità del tag <aside> semplicemente pensandolo come un contenitore di
approfondimentoin cui possiamo inserire gruppi di link, pubblicità, bookmark e così via.
<aside>
<h1>Questi sono dei contenuti di approfondimento marginali rispetto al contenuto pri
ncipale</h1>
<nav>
<h2>Link a pagine correlate al contenuto</h2>
<ul>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-39-320.jpg)
![<li>Informazione correlata al contenuto</li>
<li>Informazione correlata al contenuto</li>
<li>Informazione correlata al contenuto</li>
</ul>
</nav>
<section>
<h2>Pubblicità</h2>
[immagini pubblicitarie]
<section>
</aside>
Aside: esempi concreti
Ritornando al nostro progetto guida, dopo aver definito il contenuto dell'elemento <nav>, possiamo
analizzare la parte di codice in cui abbiamo utilizzato il tag <aside>:
<aside>
<h1>Sidebar</h1>
<section>
<h2>Ricerca nel form:</h2>
<form name="ricerca" method="post" action="/search">
<label> Parola chiave:
<input type="search" autocomplete="on" placeholder="article, section, ..." name
="keyword" required maxleng
th="50">
</label>
<input type="submit" value="ricerca">
</form>
</section>
<nav>
<h2>Categorie</h2>
<ul>
<li><a href="/categoria/multimedia">multimedia</a></li>
<li><a href="/categoria/text">marcatori testuali</a></li>
<li><a href="/categoria/form">forms</a></li>
</ul>
</nav>
</aside>
Nel seguente schema abbiamo realizzato graficamente ciò che il codice semanticamente rappresenta
nel nostro progetto:
Figura 16 - Struttura del documento: visualizzazione grafica del tag aside](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-40-320.jpg)












![<form name="commenti" method="post" action="/141/comments">
[...]
<label>Messaggio:
<textarea name="messaggio" placeholder="Scrivi qui il tuo messaggio (max 300 carat
teri)" maxlength="300" required></textarea>
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
autocomplete
Anche se questo attributo non è esattamente un attributo per le validazioni, abbiamo deciso di
inserirlo in questa lezione in quanto previene un comportamento dei browser non sempre voluto:
spesso i browser riempiono i campi da inserire in maniera automatica.
Questo comportamento è nella maggior parte dei casi un comportamento comodo, però in alcuni casi
è fastidioso. Si pensi per esempio ai campi password o ai campi del codice della banca: probabilmente
non vogliamo che il browser li completi in automatico.
Ecco che arriva in nostro soccorso l'attributo autocomplete che è un attributo enumerato. In
particolare i valori che accetta sono:
on: indica che il valore non è particolarmente sensibile e che il browser può compilarlo in
maniera automatica;
off: indica che il valore è particolarmente sensibile o con un tempo di scadenza (il codice di
attivazione di un servizio, per esempio) e che quindi l'utente deve inserirlo manualmente ogni
volta che lo compila;
nessun valore: indica in questo caso di usare il valore di default scelto dal browser
(normalmente on).
Ecco un esempio di utilizzo:
<form name="commenti" method="post" action="/141/comments">
[...]
<label>Nick:
<input type="text" name="nickname" autocomplete="on"
required pattern="[a-z]{1}[a-z_]{2,19}"
title="Un nickname è composto da lettere minuscole e '_'; Sono consentiti da 3
a 20 caratteri."
placeholder="your_nickname">
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
multiple](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-53-320.jpg)
![In molti casi abbiamo bisogno che l'utente possa inserire più valori per lo stesso input (per
esempio se gli stiamo chiedendo gli indirizzi e-mail di amici a cui inviare un invito).
Ecco che arriva in nostro soccorso l'attributo multiple che è un attributo booleano.
Un esempio di utilizzo:
<form>
<label>eMail a cui inviare l'invito:
<input type="email" multiple name="friendEmail"
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia">
</form>
pattern
In molti casi abbiamo bisogno di validare un determinato input verificando che il valore inserito
sottostia a determinate regole di creazione (per esempio potremmo volere che il campo password non
contenga spazi).
Possiamo contare in questi casi sull'attributo pattern.
Il valore di pattern, se specificato, deve essere una espressione regolare valida (http://www.ecma-
international.org/publications/standards/Ecma-262.htm).
Se viene indicato l'attributo pattern bisognerebbe indicare anche il title per dare una descrizione
del formato richiesto, altrimenti il messaggio di errore sarà generico e probabilmente di poco aiuto.
Ecco un esempio di utilizzo:
<form name="commenti" method="post" action="/141/comments">
[...]
<label>Nick:
<input type="text" name="nickname" autocomplete="on"
required pattern="[a-z]{1}[a-z_]{2,19}"
title="Un nickname è composto da lettere minuscole e '_'; Sono consentiti da 3
a 20 caratteri."
placeholder="your_nickname">
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
In questo esempio si sta richiedendo che lo username sia una parola in minuscolo composta solo da
lettere e da "_", di una lunghezza minima di 3 caratteri e massima di 20 e che non cominci con "_"
min e max](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-54-320.jpg)
![I valori min e max descrivono rispettivamente il valore minimo e massimo consentito.
Il valore di max deve essere maggiore del valore di min se indicato.
Questi attributi si applicano sia alle date (come detetime
(http://xhtml.html.it/guide_preview/lezione/4986/nuovi-tipi-di-input-per-la-gestione-delle-date/),
date(http://xhtml.html.it/guide_preview/lezione/4986/nuovi-tipi-di-input-per-la-gestione-delle-
date/), month (http://xhtml.html.it/guide_preview/lezione/4986/nuovi-tipi-di-input-per-la-gestione-
delle-date/)) sia ai numeri (number (http://xhtml.html.it/guide_preview/lezione/4987/input-type-
number/) e range (http://xhtml.html.it/guide_preview/lezione/4988/input-type-range/)). Per
maggiore dettagli rimandiamo alle lezioni che trattano in maniera specifica questi nuovi tipi di input.
Ecco un esempio di utilizzo:
<form name="commenti" method="post" action="/141/comments">
[...]
<label>Età:
<input type="number" name="age" min="13" max="130" step="1">
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
In questo caso stiamo chiedendo un'età compresa tra i 13 e i 130 anni (estremi compresi).
step
Il valore step definisce la distanza che intercorre tra un valore e il successivo. Definisce, in altre
parole, la granularità dei valori permessi.
Il valore di step deve essere un valore positivo non nullo.
Questo attributo si applica sia alle date (come detetime, date, month) sia ai numeri (number e
range).
Ecco un esempio di utilizzo:
<form name="commenti" method="post" action="/141/comments">
[...]
<label>Età:
<input type="number" name="age" min="13" max="130" step="1">
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
In questo caso stiamo chiedendo solo valori interi.
novalidate](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-55-320.jpg)


![indirizzo web.
Il tipo url, se specificato, dovrebbe rappresentare l'inserimento di un URL assoluto, ovvero nel
formato http://www.sito.com/etc.... Nel caso in cui il valore inserito non sia valido, viene
sollevata, nei browser che supportano il tipo url, un'eccezione che non riconosce il pattern.
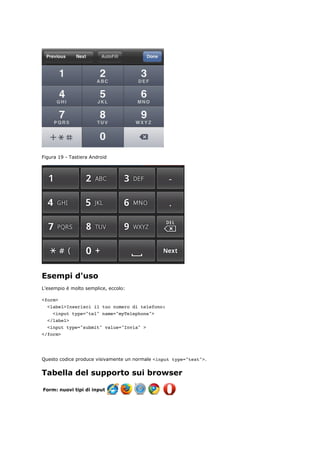
I dispositivi mobili e il type url
I dispositivi mobili possono presentare tastiere personalizzate per facilitare l'inserimento. iPhone
modifica la sua tastiera eliminando la barra spaziatrice e mettendo il punto, la slash e l'estensione
".com" come visualizzato nella figura sottostante. Android, invece, visualizza attualmente la tastiera
standard.
Figura 21 - Tastiera iPhone con un campo di tipo url
Esempi d'uso
L'esempio è molto semplice, eccolo:
<form name="commenti" method="post" action="/141/comments">
[...]
<label> Www:
<input type="url" name="url" autocomplete="on" placeholder="http://mywebsite.com">
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
Produce visivamente un normale <input type="text">.
Tabella del supporto sui browser
Form: nuovi tipi di input
url No 4.0+ 4.0+ 2.0+ 9.0+](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-59-320.jpg)
![Input type: email
L'elemento input con type=email viene usato per creare un campo per inserire un indirizzo e-
mail.
L'input con tipo email, se specificato, dovrebbe rappresentare l'inserimento di indirizzi e-mail. Una
fondamentale condizione di validità, dunque, sarà rappresentata dalla presenza del simbolo @. Nel
caso in cui il valore inserito non sia valido viene sollevata un'eccezione.
I dispositivi mobili e il type email
I dispositivi mobili possono presentare, anche in questo caso, tastiere ad hoc. iPhone modifica la sua
tastiera mostrando la chiocciola e il punto come visualizzato in figura 22. Android attualmente
visualizza la tastiera standard.
Figura 22 - Tastiera iPhone con un campo di tipo email
Esempi d'uso
Anche per questo tipo di input presentiamo un piccolo snippet di codice:
<form name="commenti" method="post" action="/141/comments">
[...]
<label> Email:
<input type="email" name="email" autocomplete="on" placeholder="email@domain.ext">
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
Il codice visto produce visivamente un normale <input type="text">.](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-60-320.jpg)






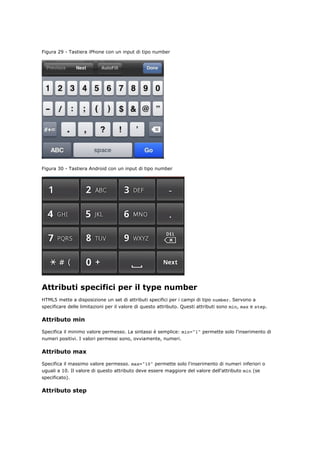
![L'attributo step indica la granulosità che deve avere il valore, limitando i valori permessi. Il valore di
step se specificato deve essere un numero (anche non intero) maggiore di zero oppure la stringa
"any" (che equivale a non inserire l'attributo).
La sintassi è anche in questo caso molto semplice: step=3 influenza i valori permettendo valori come
-3, 0, 3, 6 ma non -1 o 2.
Esempi d'uso
Un esempio potrebbe avere questa forma:
<form name="commenti" method="post" action="/141/comments">
[...]
<label>Età:
<input type="number" name="age" min="13" max="130" step="1">
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
In questo caso stiamo chiedendo di inserire un'età compresa tra i 13 e i 130 anni (estremi compresi)
e i valori accettati sono interi.
Nella maggior parte dei browser si produce attualmente un normale <input type="text">, ma nei
browser che supportano number abbiamo:
Figura 31 - Un input di tipo number
Tabella del supporto sui browser
Form: nuovi tipi di input
number No No 4.0+ 2.0+ 9.0+
Input type: range
Molto simile semanticamente all'input type=number
(http://xhtml.html.it/guide_preview/lezione/4987/input-type-number/), questo nuovo tipo di input
permette agli utenti di inserire un numero tramite uno slider.
Attributi specifici
HTML5 mette a disposizione un set di attributi specifici per il tipo range (che sono gli stessi del
type=number): servono a specificare delle limitazioni per il valore di questo attributo. Questi attributi](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-68-320.jpg)
![sono min,max e step.
min: specifica il minimo valore permesso. Esempio: min="1", che permette solo di passare
numeri da 1 in su.
max
: specifica il massimo valore permesso. Esempio: max="10", che permette solo di inviare
numeri inferiori o uguali a 10. Il valore di questo attributo deve essere maggiore del valore
dell'attributo min (se specificato).
step: indica la granulosità che deve avere il value limitando i possibili valori passati. Il valore
di step se specificato deve essere un numero (anche non intero) maggiore di zero oppure la
stringa "any" (che equivale a non inserire l'attributo). Esempio: step=3, che influenza i valori
inseriti passando valori come -3, 0, 3, 6.
Esempi d'uso
L'esempio è molto semplice, eccolo:
<form name="commenti" method="post" action="/141/comments">
[...]
<label>Voto:
<input type="range" name="voto" min="0" max="5" step="1">
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
Ecco come appare un input di tipo range sui browser che lo supportano:
Figura 32 - Un input di tipo range
Tabella del supporto sui browser
Form: nuovi tipi di input
range No No 4.0+ 2.0+ 9.0+
Input type: color
L'elemento input con type=color dovrebbe creare un color picker, quel tipo particolare di widget
utile per la selezione di un colore a partire da una palette di colori. Una volta selezionato il
colore, il campo passa alla nostra pagina di ricezione un colore RGB esadecimale composto da 6 cifre.
Questo tipo input ad oggi non è molto supportato. Per la sua implementazione sui nostri siti si può
però ricorrere ad una qualsiasi delle tante soluzioni Javascript disponibili.](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-69-320.jpg)

![Esempi d'uso
Per utilizzare datalist prima di tutto dobbiamo scrivere un input a cui collegare la nostra datalist.
Per collegare l'input alla datalist basta impostare l'attributo list dell'input con l'id della datalist.
Per ogni suggerimento che vogliamo dare all'utente facciamo discendere da datalist un tag option,
mettendo il suggerimento nell'attributo value. Il value dell'option non deve essere vuoto e l'option
non deve essere settata su disabled per essere visualizzata.
Vediamo il codice:
<form name="commenti" method="post" action="/141/comments">
[...]
<label>Stato d'animo:
<input type="text" name="mood" placeholder="felice, triste, incuriosito, ..." list
="stato-danimo">
<datalist id="stato-danimo">
<option value="triste">
<option value="annoiato">
<option value="curioso">
<option value="felice">
<option value="entusiasta!">
</datalist>
</label>
[...]
<input type="reset" value="Resetta il form">
<input type="submit" value="Invia il commento">
</form>
Tabella del supporto sui browser
Form: nuovi tipi di input
datalist No 4.0+ No No 9.0+
La potenza dei microdati
Introduzione: semantica e rich snippet
Leggendo questa guida dovrebbe essere chiaro che un punto focale di HTML5 è la semantica.
HTML5 ha introdotto infatti diversi tag semantici (come header, article o nav) che permettono di
strutturare il contenuto secondo una logica, appunto, semantica. Ma questa suddivisione non assolve
a tutte le necessità semantiche di cui il web ha bisogno.
L'obbiettivo è quello di dare la possibilità a programmi come crawler dei motori di ricerca o screen
reader di comprendere il significato del testo. Queste informazioni sono accessibili da questi](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-72-320.jpg)




![Ora impostiamo la pagina html perché richiami il file Javascript:
<!doctype html>
<html lang='it'>
<head>
<meta charset="utf-8">
<title>FiveBoard: uno spazio per gli appunti.</title>
<script src="js/application.js" defer></script>
</head>
</html>
L’attributo defer, poco supportato perché definito in modo poco chiaro nelle specifiche HTML4
(http://www.w3.org/TR/html401/interact/scripts.html#h-18.2.1), assume nella versione 5 un
significato più delineato:
“(se) [..] l'attributo defer è presente, allora lo script viene eseguito quando la pagina ha
finito di essere processata.”
In questo nuovo contesto è interessante l’utilizzo di defer per velocizzare il caricamento della pagina
posticipando in seconda battuta il load del file Javascript. Da notare, prima di proseguire, anche
l’aggiunta nelle specifiche dell’attributo async che causa il caricamento dello script in parallelo, o
asincrono, da qui il nome, rispetto a quello della pagina.
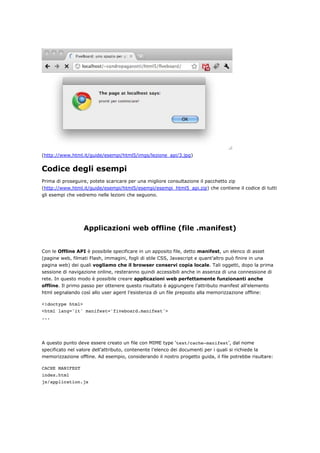
Prima di concludere sinceriamoci del funzionamento del nostro impianto aggiungendo al file
Javascript:
alert("pronti per cominciare!");
e caricando il tutto all’interno di un browser:
Figura 43 (click per ingrandire) - Risultato dell'operazione](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-79-320.jpg)



![}else{
recuperaLibri();
}
}
aggiornaLoSchema = function(){
window.transazione = event.result;
transazione.oncomplete = recuperaLibri;
transazione.onabort = function(){console.log("Ops, errore");}
var libri = database.createObjectStore("libri", "isbn", false);
var titolo = libri.createIndex("titolo", "titolo", false);
var autore = libri.createIndex("autore", "autore", false);
}
recuperaLibri = function(){
// recupera l'elenco dei libri e stampali a video
}
...
La funzione createObjectStore richiede 3 parametri, di cui solamente il primo, il nome, obbligatorio;
il secondo parametro rappresenta il nome della proprietà del record che vogliamo funga da chiave
all'interno dell'object store. Il terzo parametro imposta invece la proprietà autoincrement; nel caso
non sia presente una chiave nel record in inserimento e autoincrement = true, una chiave verrà
generata in automatico. Le due chiamate alla funzione createIndex provvedono alla creazione di due
indici, utili per ricerche e query, sui campi ‘titolo' e ‘autore'; il terzo parametro impostato a
falseconsente la presenza di valori duplicati. Ora che abbiamo creato la struttura del database
stampiamo a video l'elenco, per ora vuoto, dei libri registrati e creiamo un piccola form per
l'inserimento di un nuovo volume:
...
recuperaLibri = function(){
window.transazione = database.transaction(["libri"],
IDBTransaction.READ_WRITE, 0);
var request = transazione.objectStore("libri").openCursor();
request.onsuccess = stampaLibri;
request.onerror = function(){console.log("Ops, errore");}
}
stampaLibri = function(){
var cursor = event.result;
if( cursor != null){
document.getElementById("catalogo_libri").insertAdjacentHTML('beforeend',
"<li>" + cursor.value.autore + ": " + cursor.value.titolo +
" (ISBN: "+ cursor.value.isbn +"); </li>");
cursor.continue();
}
}
aggiungiLibro = function(){
// aggiungiamo un nuovo libro all'object store
}
</script>
</head>
<body onload="init();">
<h1> WebLibreria: gestionale per librerie</h1>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-89-320.jpg)
![<section>
<h1>Elenco dei libri</h1>
<ul id="catalogo_libri">
</ul>
</section>
<aside>
<h1>Aggiungi un nuovo libro</h1>
<form name="aggiungi_libro" onsubmit="aggiungiLibro(this); return false;">
<fieldset name="info_libro">
<legend>Dati richiesti:</legend>
<label>Titolo:
<input name="titolo" type="text" required placeholder="es: Dalla terra alla
luna">
</label>
<label>Autore:
<input name="autore" type="text" required placeholder="es: Jules Verne">
</label>
<label>ISBN:
<input name="isbn" type="text" required placeholder="es: 8862221320">
</label>
<input type="submit" value="Aggiungi">
</fieldset>
</form>
</aside>
</body>
</html>
Possiamo tranquillamente tralasciare la spiegazione della nuova porzione di codice HTML aggiunto:
trattasi semplicemente di un form che all'invio chiama una funzione, ancora da sviluppare, per
l'aggiunta di un nuovo libro. Molto più interessanti sono invece recuperaLibri e stampaLibri. In
recuperaLibri viene creata una nuova transazione che coinvolge l'object store ‘libri'; il secondo
parametro indica il tipo di transazione: purtroppo lettura/scrittura (IDBTransaction.READ_WRITE) è
l'unica opzione supportata ad oggi; il terzo valore rappresenta invece il timeout della transazione: lo 0
utilizzato significa mai. Vediamo l'istruzione successiva:
var request = transazione.objectStore("libri").openCursor();
La funzione openCursor inizializza un puntatore, detto anche cursore, al primo record dell'object
store ‘libri'. La funzione stampaLibri, che viene chiamata appena il cursore è stato creato e popola
una lista con i libri in catalogo, agisce come una specie di ciclo, infatti il metodo continue non fa
nient'altro che richiamare nuovamente stampaLibri, posizionando però il cursore al record successivo;
questo fino a quando non si giunge alla fine dei risultati di ricerca, a quel punto il valore del cursore
diviene null e un apposito if si preoccupa dell'abbandono della funzione.
Completiamo il nostro progetto con la funzione aggiungiLibro:
...
aggiungiLibro = function(data){
var elements = data.elements
window.transazione = database.transaction(["libri"],
IDBTransaction.READ_WRITE, 0);](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-90-320.jpg)
![var request = transazione.objectStore("libri").put({
titolo: elements['titolo'].value,
autore: elements['autore'].value,
isbn: elements[ 'isbn'].value
}, elements[ 'isbn'].value));
request.onsuccess = function(){pulisciLista(); recuperaLibri();}
request.onerror = function(){console.log("Ops, errore");}
}
pulisciLista = function(){
document.getElementById("catalogo_libri").innerHTML ="";
}
</script>
Il metodo interessante in questo caso è il put, che si preoccupa di aggiungere al database, previa
apertura di una transazione appropriata, un nuovo record con gli elementi ricevuti dal form (da notare
il secondo parametro, corrispondente alla chiave del record). Da notare che esiste anche un metodo
add che differisce nell'impedire la creazione di un record la cui chiave sia già presente nel database.
Eseguiamo un ultima volta l'applicazione, proviamo ad inserire un paio di libri ed ammiriamone il
risultato (figura 3):
Figura 3 (click per ingrandire)
(http://www.html.it/guide/esempi/html5/imgs/lezione_database/3.jpg)
Una funzione di ricerca
Aggiungiamo questa funzione al progetto:
...
ricercaLibro = function(autore){
pulisciLista();
window.transazione = database.transaction(["libri"],
IDBTransaction.READ_WRITE, 0);
var request = transazione.objectStore("libri").index('autore').openCursor(](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-91-320.jpg)
![IDBKeyRange.bound(autore,autore+"z",true,true), IDBCursor.NEXT);
request.onsuccess = stampaLibri;
request.onerror = function(){console.log("Ops, errore");}
}
</script>
L'unica differenza rispetto alla già analizzata recuperaLibri sta nel fatto che, in questo caso, con il
metodo ‘index(‘autore')' indichiamo al database che la selezione dovrà essere fatta utilizzando
come discriminante l'indice ‘autore' creato sull'omonimo campo. In particolare tale selezione dovrà
recuperare tutti i record il cui autore inizia con una stringa passata al metodo. Per provare questa
funzione di ricerca creiamo un nuovo frammento HTML in coda alla form di inserimento:
...
</form>
<h1>Cerca un libro per autore</h1>
<form name="cerca_per_autore"
onsubmit="ricercaLibro(this.elements['keyword'].value); return false;">
<fieldset name="campi_ricerca">
<legend>Ricerca per autore:</legend>
<label>Inizio del nome:
<input name="keyword" type="search" required placeholder="es: Franc">
</label>
<input type="submit" value="Ricerca">
</fieldset>
</form>
</aside>
...
Ricarichiamo l'applicazione e proviamo ad inserire una valida stringa di ricerca (figura 4):
Figura 4 (click per ingrandire)](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-92-320.jpg)

![Le WebStorage API nascono per risolvere due problematiche tipiche dei cookies; la loro limitata
dimensione massima (tipicamente 4K) e l’impossibilità di avere cookies differenziati tra due
diverse sessioni di navigazione sullo stesso dominio dallo stesso browser. Il secondo punto si
esplicita molto bene cercando di mantenere aperti contemporaneamente due account Gmail sullo
stesso browser, ogni navigazione sul primo comporterà il logout del secondo e viceversa.
I problemi in questione sono stati risolti creando due nuovi oggetti. sessionStorage consente di
avere un meccanismo di persistenza dei dati distinto per ogni sessione di navigazione in ogni finestra,
o tab, del browser. Usando sessionStorage sarebbe quindi possibile coordinare l’apertura
contemporanea di due distinti account GMail sullo stesso browser. localStorage mantiene il
comportamento del cookie essendo comune a tutte finestre del browser che condividono lo stesso
dominio. Entrambi sono inoltre stati studiati per ospitare molti più dati, almeno 5Mb, ed essere
persistenti anche alla chiusura ed alla riapertura del browser.
Le specifiche
Le API si compongono di una singola interfaccia Storage. localStorage e sessionStorage
implementano entrambi questa interfaccia e quindi dispongono dello stesso set di metodi anche se
chiaramente restano due oggetti distinti. Le principali operazioni possono essere eseguite come su di
un normale array associativo:
localStorage.nome = 'Sandro';
localStorage.cognome = 'Paganotti';
o con l’ausilio di metodi dedicati:
localStorage.setItem('nome','Sandro');
localStorage.getItem('nome'); // ritorna 'Sandro'
Se però ci accingiamo ad inserire valori diversi da stringhe il comportamento diverge: in un oggetto
come localStorage o sessionStorage è consentita la memorizzazione di soli contenuti testuali:
localStorage.ordini = Array("1","2","3");
localStorage.ordini; // ritorna "1,2,3"
È quindi necessario ricorrere a stratagemmi, come la serializzazione su JSON, per ottenere l’effetto
desiderato:
localStorage.ordini = JSON.stringify(Array(1,2,3));
JSON.parse(localStorage.ordini); // ritorna un array di 3 elementi: [1,2,3]
Chromium mette a disposizione degli sviluppatori web che intendono utilizzare queste API la linguetta
‘Storage’ dei Developer Tools (raggiungibili da menu o con la combinazione di tasti Control - Shift -
J e visibile in figura 1):
Figura 1 (click per ingrandire)](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-94-320.jpg)
![(http://www.html.it/guide/esempi/html5/imgs/lezione_webstorage/1.jpg)
Un esempio
Utilizziamo il progetto guida per implementare una meccanica di salvataggio dei dati basata su
localStorage. Non avendo ancora sviluppato la gestione della lavagna ci concentreremo sul
memorizzare e visualizzare stringhe inserite dall’utente attraverso una textarea, iniziamo con il
markup completando il file index.html:
<!doctype html>
<html lang='it' manifest='fiveboard.manifest'>
<head>
<meta charset="utf-8">
<title>FiveBoard: uno spazio per gli appunti.</title>
<script src="js/application.js" defer></script>
</head>
<body>
<hgroup>
<h1>Dì qualcosa </h1>
<h2>FiveBoard ricorda tutto</h2>
</hgroup>
<form name="form_da_ricordare">
<menu type="toolbar">
<button type="button" onclick="salvaIlDato(this.form.elements['testo_da_ricordar
e'].value);">
Memorizza quanto scritto
</button>
<button type="button" onclick="recuperaIlDato(this.form.elements['testo_da_ricor
dare']);">
Recupera l'ultimo testo memorizzato
</button>
</menu>
<label>Cosa hai in mente?
<textarea name="testo_da_ricordare" required autofocus
placeholder="La lista della spesa, il teatro di questa sera ..."></textarea>
</label>
</form>
</body>
</html>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-95-320.jpg)



![Mantenere a video un elenco dei Client registrati;
Hub.js (SharedWorker)
Registrare ogni Client e notificare, se presente, la dashboard;
Registrare la dashboard ed inviarle tutti i Client registrati fino a quel momento.
Lo scambio di messaggi tra le varie parti avverrà tramite stringhe di testo nel formato
“chiave:valore”, come ad esempio “registra_client:Documento di prova”; questa scelta non è
dettata dalle specifiche, che sono abbastanza lasche in tal senso, ma da una semplice convenzione
adottata anche da alcuni esempi del W3C (http://www.whatwg.org/specs/web-apps/current-
work/complete/workers.html#shared-state-using-a-shared-worker).
Bene, possiamo partire; iniziamo dal file ‘application.js’ che dovrà assumere questo aspetto:
salvaIlDato = function(info_da_salvare){
localStorage.setItem("fb_" + titolo_fiveboard,info_da_salvare);
alert("Memorizzazione effettuata");
};
recuperaIlDato = function(elemento){
if(confirm("Sostituire il contenuto attuale con l'ultimo pensiero memorizzato?")){
elemento.value = localStorage.getItem("fb_" + titolo_fiveboard);
}
};
var titolo_fiveboard = null;
window.onload = function(){
var worker = new SharedWorker('js/hub.js');
worker.port.onmessage = function(evento){
nome_comando = evento.data.split(":")[0]
valore_comando = evento.data.substr(nome_comando.length + 1);
console.log("Ricevuto comando: " + nome_comando);
switch (nome_comando){
case 'pronto':
titolo_fiveboard = prompt("Seleziona il titolo per questa FiveBoard");
document.title = "FB: " + titolo_fiveboard;
worker.port.postMessage("registra_client:" + titolo_fiveboard);
break;
}
}
}
Al caricamento della pagina viene attivata la funzione collegata a window.onload: questa crea il
collegamento con lo SharedWorker (se il worker non è già presente verrà caricato in memoria e
lanciato) e definisce una funzione di ‘ascolto’ nella quale, per ogni messaggio ricevuto, esegue
particolari azioni a seconda della chiave estratta. In questo momento la funzione reagisce alla sola
chiave ‘pronto’ chiedendo all’utente un titolo del documento ed inviando il risultato al worker con la
chiave ‘registra_client’.
Il titolo del documento viene anche utilizzato nelle funzioni di salvataggio e di recupero del dato, per
differenziare fra di loro le variabili memorizzate su LocalStorage in modo da evitare collisioni durante
l’apertura contemporanea di più index.html.
Ora definiamo hub.js:](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-100-320.jpg)
![var fiveboards_registrate = new Array();
var dashboard = null;
processa_il_messaggio = function(evento){
nome_comando = evento.data.split(":")[0]
valore_comando = evento.data.substr(nome_comando.length + 1);
switch (nome_comando){
case 'registra_client':
fiveboards_registrate[valore_comando]=evento.target;
if(dashboard != null){
dashboard.postMessage("nuova_fiveboard:" + valore_comando);
}
break;
case 'registra_dashboard':
dashboard = evento.target;
for(fiveboard in fiveboards_registrate){
evento.target.postMessage("nuova_fiveboard:" + fiveboard);
}
break;
}
}
onconnect = function(nuova_finestra){
var port = nuova_finestra.ports[0];
port.onmessage = processa_il_messaggio;
port.postMessage("pronto");
}
L’handler onconnect viene invocato ogni qualvolta una pagina tenta di aprire una connessione verso il
worker; nella funzione si delega al metodo ‘processa_il_messaggio’ la gestione dei futuri scambi tra
in worker e la pagina; a quest’ultima è inoltre segnalato il concludersi delle operazioni con un
messaggio ‘pronto’.
La funzione processa_il_messaggio interpreta e gestisce le due chiavi registra_client e
registra_dashboard: nel primo caso aggiunge la MessagePort di comunicazione con il client ad una
collezione fiveboards_registrate e comunica alla dashboard, se presente, la nuova aggiunta
tramite un messaggio con chiave nuova_fiveboard. Nel secondo caso registra la MessagePort della
dashboard (attraversoevento.target, che corrisponde ad evento.ports[0]) e comunica alla stessa
tutti client finora memorizzati attraverso un ciclo sulla collezione fiveboards_registrate e ad un
messaggio con la già nota chiave nuova_fiveboard.
Perfetto, ora non ci resta che definire markup e Javascript di ‘dashboard.html’:
<html lang='it'>
<head>
<meta charset="utf-8">
<title>Five(Dash)Board: tutto sotto controllo!.</title>
<script>
var worker = null;
getInfo = function(title){
// to be defined...](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-101-320.jpg)
![}
init = function(){
worker = new SharedWorker('js/hub.js');
worker.port.onmessage = function(evento){
nome_comando = evento.data.split(":")[0]
valore_comando = evento.data.substr(nome_comando.length + 1);
console.log("Ricevuto comando: " + nome_comando);
switch (nome_comando){
case 'pronto':
worker.port.postMessage("registra_dashboard")
break;
case 'nuova_fiveboard':
document.getElementById("elenco_fiveboard").insertAdjacentHTML('beforeend',
"<li>" +
"Titolo: " + valore_comando + " " +
"(<a href='javascript:getInfo("" + valore_comando +"");'>" +
"più informazioni" + "</a>)" +
"</li>");
break;
}
}
}
</script>
</head>
<body onload="init();">
<h1>FiveBoard:</h1>
<ol id="elenco_fiveboard">
</ol>
</body>
</html>
Il listato è largamente autoesplicativo sulla base di quanto già enunciato: in questo caso le chiavi
gestite sono ‘pronto’ e ‘nuova_fiveboard’: mentre la prima attiva il meccanismo di registrazione
(registra_dashboard) appena visto in hub.js, la seconda si incarica di popolare una lista ordinata
ogniqualvolta la pagina riceve una notifica di registrazione di una nuova fiveboard.
Eseguiamo il tutto in Chromium e godiamoci il risultato dei nostri sforzi (figura 3):
Figura 3 (click per ingrandire)](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-102-320.jpg)

![// invio della richiesta allo SharedWorker (punto 1)
getInfo = function(title){
worker.port.postMessage("maggiori_informazioni:" + title);
}
// una nuova chiave da gestire.
case 'attendi_testo':
evento.ports[0].onmessage = function(e){
alert(e.data);
}
break;
// file hub.js
// una nuova chiave da gestire, creazione del canale ed invio delle porte di
// comunicazione alla dashboard ed al client interessato (punto 2)
case 'maggiori_informazioni':
var channel = new MessageChannel();
dashboard.postMessage("attendi_testo",[channel.port1]);
fiveboards_registrate[valore_comando].postMessage("richiedi_testo",
[channel.port2]);
break;
// file application.js
// una nuova chiave da gestire, invio delle informazioni richieste attraverso la
// MessagePort ricevuta dall’evento (non la MessagePort di comunicazione col worker)
// (punto 3)
case 'richiedi_testo':
evento.ports[0].postMessage(
"testo corrente:" + document.forms['form_da_ricordare'].elements
['testo_da_ricordare'].value + "n" +
"testo memorizzato:" + localStorage.getItem("fb_" + titolo_fiveboard)
);
break;
Eseguiamo il tutto in Chromium ed ammiriamone il risultato (figura 5):
Figura 5 (click per ingrandire)](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-104-320.jpg)


![implementazione utilizzeremo Ruby (http://ruby.html.it), un linguaggio di programmazione elegante
e conciso. L'installazione dell'interprete Ruby è veramente facile ed il codice che utilizzeremo molto
leggibile. Per prima cosa colleghiamoci al portale ufficiale: http://www.ruby-lang.org/it/downloads/
(http://www.ruby-lang.org/it/downloads/) e selezioniamo la procedura di installazione dedicata al
nostro sistema operativo, quindi apriamo una console di comando (a volte chiamata anche terminale)
e digitiamo:
gem install em-websocket
Per installare la libreria necessaria allo sviluppo del WebSocket Server (per alcuni sistemi operativi è
necessario anteporre sudo all'istruzione).
Creiamo ora un file 'websocket_server.rb' e modifichiamone il contenuto come segue:
require 'rubygems'
require 'em-websocket'
EventMachine.run {
@channels = Hash.new {|h,k| h[k] = EM::Channel.new }
EventMachine::WebSocket.start(:host => "0.0.0.0", :port => 8080, :debug => true) do
|
ws|
ws.onopen do
sid = nil
fiveboard_channel = nil
ws.onmessage do |msg|
command, value = msg.split(":", 2);
case command
when 'registra'
fiveboard_channel = @channels[value]
sid = fiveboard_channel.subscribe { |txt| ws.send(txt) }
when 'aggiorna'
fiveboard_channel.push('testo:' + value)
end
end
ws.onclose do
fiveboard_channel.unsubscribe(sid)
end
end
end
puts "Il server è correttamente partito"
}
Seppur possiate essere non abituati a questo linguaggio il codice è tutto sommato comprensibile e
succinto, ecco la spiegazione dell'algoritmo:
Con l'istruzione WebSocket.start(.. l'applicazione si mette in attesa di connessioni websocket
sulla porta 8080; ogni connessione in ingresso viene memorizzata nella variabile ws e causa
l'esecuzione delle successive istruzioni (quelle comprese nell'attiguo blocco do..end).](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-109-320.jpg)
![Alla ricezione di un messaggio attraverso una connessione ws (ws.onmessage) il server si
comporta dividendo il testo ricevuto secondo la solita convenzione 'comando:valore' ed agendo
in modo diverso a seconda che il comando sia 'registra' o 'aggiorna'.
Nel caso il messaggio sia 'registra:titolo_del_documento' il server aggiungerà la
connessione attuale ad un canale che porta il nome del valore del messaggio (in questo caso
'titolo_del_documento'). In questo modo tutte le pagine che vorranno 'osservare' il
documento 'A' non dovranno far altro che inviare al WebSocket Server il messaggio
'registra:A'.
Nel caso il messaggio sia 'aggiorna:testo_del_documento' il server si comporterà
semplicemente inviando lungo il canale associato alla connessione corrente il valore del
messaggio (in questo caso 'testo_del_documento'), propagandolo in questo modo a tutte le
connessioni registrate al canale.
Infine con l'istruzione ws.onclose do... si gestisce, in caso di disconnessione del client, la
rimozione di ws dal canale presso il quale si era registrata.
Eseguiamo il server portandoci con il terminale nella posizione dello script e digitando:
ruby websocket_server.rb
Un messaggio, 'Il server è correttamente partito', dovrebbe confermare la bontà del nostro operato.
Dedichiamoci ora alle API Javascript ed alla loro implementazione, per prima cosa editiamo il file
'js/application.js' per fare in modo che ogni FiveBoard si registri presso il server ed invii segnali di
aggiornamento ad ogni modifica del testo, ecco il codice da inserire all'interno della funzione
window.onload:
// all'interno di window.onload, js/application.js
// queste due istruzioni sono state spostate dalla loro precedente posizione
titolo_fiveboard = prompt("Seleziona il titolo per questa FiveBoard");
document.title = "FB: " + titolo_fiveboard;
// creazione di un nuovo socket verso il server Ruby
websocket = new WebSocket('ws://0.0.0.0:8080');
websocket.onopen = function(){
// invio del comando 'registra'
websocket.send("registra:" + titolo_fiveboard);
}
// ad ogni variazione di input segue l'invio del comando 'aggiorna' /
/ verso il server Ruby
document.forms['form_da_ricordare'].elements['testo_da_ricordare'].oninput = function
(event){
websocket.send("aggiorna:" + event.target.value);
}
Anche in questo caso l'implementazione risulta abbastanza leggibile; unico appunto da fare
sull'evento oninput, anch'esso novità introdotta dalle specifiche HTML5, che viene invocato ad ogni
attività di input (pressione di un tasto, copia ed incolla, drag and drop,...) sull'elemento in oggetto.
Completiamo l'esempio con la creazione della semplicissima pagina 'viewer.html':
<!doctype html>
<html>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-110-320.jpg)
![<head>
<title>FiveBoard Viewer</title>
<script>
window.onload = function(){
var documento_da_visionare = prompt("Inserisci il nome del documento che vuoi
osservare");
var websocket = new WebSocket('ws://0.0.0.0:8080');
websocket.onopen = function(){
document.title = "VB: " + documento_da_visionare;
websocket.send("registra:" + documento_da_visionare);
}
websocket.onmessage = function(evento){
nome_comando = evento.data.split(":")[0]
valore_comando = evento.data.substr(nome_comando.length + 1);
switch (nome_comando){
case 'testo':
document.getElementById('documento_in_visione').value = valore_comando;
break;
}
}
}
</script>
</head>
<body>
<textarea id="documento_in_visione" readonly>Aspettando il primo aggiornamento...</
textarea>
</body>
</html>
In questo caso la pagina è istruita nel reagire alla ricezione di un messaggio da parte del WebSocket
Server; il valore ricevuto viene infatti gestito con la solita convenzione 'comando:valore' e, nel caso il
comando sia 'testo', il valore viene inserito all'interno di una textarea preposta.
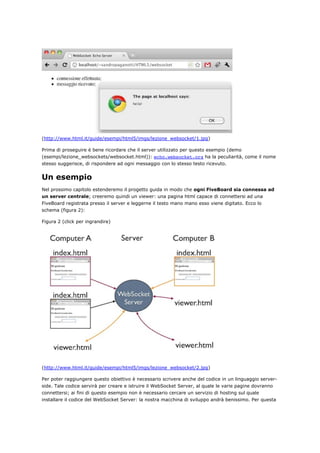
Bene, eseguiamo una prova di funzionamento
(http://www.html.it/guide/esempi/html5/esempi/lezione_websockets/fiveboard/index.html):
sincerandoci di aver lanciato il WebSocket Server navighiamo prima sulla pagina 'index.html' e
creiamo un nuovo documento 'esempio1', quindi apriamo una nuova finestra e puntiamola all'indirizzo
di 'viewer.html': alla richiesta del nome del documento inseriamo anche qui 'esempio1' in modo da
legare il viewer alla fiveboard.
Ora proviamo a digitare alcuni caratteri sulla prima finestra e noteremo che, attraverso il server,
questi sono propagati in tempo reale alla seconda! Ovviamente il tutto funzionerebbe anche se la
conversazione avvenisse tra due macchine distinte attraverso un server remoto; nell'immagine
seguente si può notare una fiveboard aperta sull'iPad ed il suo corrispondente viewer visibile su di un
portatile; in alto i messaggi di log del WebSocket Server (figura 3).
Figura 3 (click per ingrandire)](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-111-320.jpg)
![(http://www.html.it/guide/esempi/html5/imgs/lezione_websocket/3.jpg)
Conclusioni
I WebSocket, sono nella loro estrema semplicità, degli strumenti incredibilmente potenti; a riprova di
questo fatto la rete ha già incominciato ad offrire interessanti prospettive di utilizzo nonostante
l'innegabile giovinezza di queste API. Tra le soluzioni degne di nota merita sicuramente una citazione
Pusher (http://pusherapp.com/), un servizio che offre la possibilità di gestire eventi real-time
attraverso l'utilizzo di WebSocket. Un po' più artigianale, ma altrettanto valido è http://jsterm.com/
(http://jsterm.com/), un'applicazione che consente di collegarsi a server remoti utilizzando un proxy,
scritto in node.js, tra il protocollo WebSocket e Telnet.
Recentemente lo sviluppo delle API è stato frenato dalla scoperta di una seria vulnerabilità
[documento PDF] (http://www.adambarth.com/experimental/websocket.pdf) legata al potenziale
comportamento di un caching proxy che può essere indotto, attraverso l'utilizzo di WebSocket ad-hoc,
a modificare il contenuto delle informazioni consegnate ad altri client. La vulnerabilità è stata
correttamente risolta dalla versione 0.7 del protocollo ma sfortunatamente le versioni 4 e 5 di Firefox,
rilasciate prima del fix, hanno i websocket disabilitati per default; la versione 6 del browser dovrebbe
però ripristinare il funzionamento out-of-the-box di questa interessantissima feature.
Tabella del supporto sui browser
API e Web Applications
WebSockets No 4.0+ (parziale) 5.0+ 7.0+ 11.0+ (parziale)
WebSockets API
Le WebSockets API introducono, nella loro estrema semplicità, una funzionalità tra le più attese ed](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-112-320.jpg)


![implementazione utilizzeremo Ruby (http://ruby.html.it), un linguaggio di programmazione elegante
e conciso. L'installazione dell'interprete Ruby è veramente facile ed il codice che utilizzeremo molto
leggibile. Per prima cosa colleghiamoci al portale ufficiale: http://www.ruby-lang.org/it/downloads/
(http://www.ruby-lang.org/it/downloads/) e selezioniamo la procedura di installazione dedicata al
nostro sistema operativo, quindi apriamo una console di comando (a volte chiamata anche terminale)
e digitiamo:
gem install em-websocket
Per installare la libreria necessaria allo sviluppo del WebSocket Server (per alcuni sistemi operativi è
necessario anteporre sudo all'istruzione).
Creiamo ora un file 'websocket_server.rb' e modifichiamone il contenuto come segue:
require 'rubygems'
require 'em-websocket'
EventMachine.run {
@channels = Hash.new {|h,k| h[k] = EM::Channel.new }
EventMachine::WebSocket.start(:host => "0.0.0.0", :port => 8080, :debug => true) do
|
ws|
ws.onopen do
sid = nil
fiveboard_channel = nil
ws.onmessage do |msg|
command, value = msg.split(":", 2);
case command
when 'registra'
fiveboard_channel = @channels[value]
sid = fiveboard_channel.subscribe { |txt| ws.send(txt) }
when 'aggiorna'
fiveboard_channel.push('testo:' + value)
end
end
ws.onclose do
fiveboard_channel.unsubscribe(sid)
end
end
end
puts "Il server è correttamente partito"
}
Seppur possiate essere non abituati a questo linguaggio il codice è tutto sommato comprensibile e
succinto, ecco la spiegazione dell'algoritmo:
Con l'istruzione WebSocket.start(.. l'applicazione si mette in attesa di connessioni websocket
sulla porta 8080; ogni connessione in ingresso viene memorizzata nella variabile ws e causa
l'esecuzione delle successive istruzioni (quelle comprese nell'attiguo blocco do..end).](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-116-320.jpg)
![Alla ricezione di un messaggio attraverso una connessione ws (ws.onmessage) il server si
comporta dividendo il testo ricevuto secondo la solita convenzione 'comando:valore' ed agendo
in modo diverso a seconda che il comando sia 'registra' o 'aggiorna'.
Nel caso il messaggio sia 'registra:titolo_del_documento' il server aggiungerà la
connessione attuale ad un canale che porta il nome del valore del messaggio (in questo caso
'titolo_del_documento'). In questo modo tutte le pagine che vorranno 'osservare' il
documento 'A' non dovranno far altro che inviare al WebSocket Server il messaggio
'registra:A'.
Nel caso il messaggio sia 'aggiorna:testo_del_documento' il server si comporterà
semplicemente inviando lungo il canale associato alla connessione corrente il valore del
messaggio (in questo caso 'testo_del_documento'), propagandolo in questo modo a tutte le
connessioni registrate al canale.
Infine con l'istruzione ws.onclose do... si gestisce, in caso di disconnessione del client, la
rimozione di ws dal canale presso il quale si era registrata.
Eseguiamo il server portandoci con il terminale nella posizione dello script e digitando:
ruby websocket_server.rb
Un messaggio, 'Il server è correttamente partito', dovrebbe confermare la bontà del nostro operato.
Dedichiamoci ora alle API Javascript ed alla loro implementazione, per prima cosa editiamo il file
'js/application.js' per fare in modo che ogni FiveBoard si registri presso il server ed invii segnali di
aggiornamento ad ogni modifica del testo, ecco il codice da inserire all'interno della funzione
window.onload:
// all'interno di window.onload, js/application.js
// queste due istruzioni sono state spostate dalla loro precedente posizione
titolo_fiveboard = prompt("Seleziona il titolo per questa FiveBoard");
document.title = "FB: " + titolo_fiveboard;
// creazione di un nuovo socket verso il server Ruby
websocket = new WebSocket('ws://0.0.0.0:8080');
websocket.onopen = function(){
// invio del comando 'registra'
websocket.send("registra:" + titolo_fiveboard);
}
// ad ogni variazione di input segue l'invio del comando 'aggiorna' /
/ verso il server Ruby
document.forms['form_da_ricordare'].elements['testo_da_ricordare'].oninput = function
(event){
websocket.send("aggiorna:" + event.target.value);
}
Anche in questo caso l'implementazione risulta abbastanza leggibile; unico appunto da fare
sull'evento oninput, anch'esso novità introdotta dalle specifiche HTML5, che viene invocato ad ogni
attività di input (pressione di un tasto, copia ed incolla, drag and drop,...) sull'elemento in oggetto.
Completiamo l'esempio con la creazione della semplicissima pagina 'viewer.html':
<!doctype html>
<html>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-117-320.jpg)
![<head>
<title>FiveBoard Viewer</title>
<script>
window.onload = function(){
var documento_da_visionare = prompt("Inserisci il nome del documento che vuoi
osservare");
var websocket = new WebSocket('ws://0.0.0.0:8080');
websocket.onopen = function(){
document.title = "VB: " + documento_da_visionare;
websocket.send("registra:" + documento_da_visionare);
}
websocket.onmessage = function(evento){
nome_comando = evento.data.split(":")[0]
valore_comando = evento.data.substr(nome_comando.length + 1);
switch (nome_comando){
case 'testo':
document.getElementById('documento_in_visione').value = valore_comando;
break;
}
}
}
</script>
</head>
<body>
<textarea id="documento_in_visione" readonly>Aspettando il primo aggiornamento...</
textarea>
</body>
</html>
In questo caso la pagina è istruita nel reagire alla ricezione di un messaggio da parte del WebSocket
Server; il valore ricevuto viene infatti gestito con la solita convenzione 'comando:valore' e, nel caso il
comando sia 'testo', il valore viene inserito all'interno di una textarea preposta.
Bene, eseguiamo una prova di funzionamento
(http://www.html.it/guide/esempi/html5/esempi/lezione_websockets/fiveboard/index.html):
sincerandoci di aver lanciato il WebSocket Server navighiamo prima sulla pagina 'index.html' e
creiamo un nuovo documento 'esempio1', quindi apriamo una nuova finestra e puntiamola all'indirizzo
di 'viewer.html': alla richiesta del nome del documento inseriamo anche qui 'esempio1' in modo da
legare il viewer alla fiveboard.
Ora proviamo a digitare alcuni caratteri sulla prima finestra e noteremo che, attraverso il server,
questi sono propagati in tempo reale alla seconda! Ovviamente il tutto funzionerebbe anche se la
conversazione avvenisse tra due macchine distinte attraverso un server remoto; nell'immagine
seguente si può notare una fiveboard aperta sull'iPad ed il suo corrispondente viewer visibile su di un
portatile; in alto i messaggi di log del WebSocket Server (figura 3).
Figura 3 (click per ingrandire)](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-118-320.jpg)
![(http://www.html.it/guide/esempi/html5/imgs/lezione_websocket/3.jpg)
Conclusioni
I WebSocket, sono nella loro estrema semplicità, degli strumenti incredibilmente potenti; a riprova di
questo fatto la rete ha già incominciato ad offrire interessanti prospettive di utilizzo nonostante
l'innegabile giovinezza di queste API. Tra le soluzioni degne di nota merita sicuramente una citazione
Pusher (http://pusherapp.com/), un servizio che offre la possibilità di gestire eventi real-time
attraverso l'utilizzo di WebSocket. Un po' più artigianale, ma altrettanto valido è http://jsterm.com/
(http://jsterm.com/), un'applicazione che consente di collegarsi a server remoti utilizzando un proxy,
scritto in node.js, tra il protocollo WebSocket e Telnet.
Recentemente lo sviluppo delle API è stato frenato dalla scoperta di una seria vulnerabilità
[documento PDF] (http://www.adambarth.com/experimental/websocket.pdf) legata al potenziale
comportamento di un caching proxy che può essere indotto, attraverso l'utilizzo di WebSocket ad-hoc,
a modificare il contenuto delle informazioni consegnate ad altri client. La vulnerabilità è stata
correttamente risolta dalla versione 0.7 del protocollo ma sfortunatamente le versioni 4 e 5 di Firefox,
rilasciate prima del fix, hanno i websocket disabilitati per default; la versione 6 del browser dovrebbe
però ripristinare il funzionamento out-of-the-box di questa interessantissima feature.
Tabella del supporto sui browser
API e Web Applications
WebSockets No 4.0+ (parziale) 5.0+ 7.0+ 11.0+ (parziale)
Drag and Drop](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-119-320.jpg)




![Fin qui niente di strano, la parte divertente è tutta racchiusa nella definizione delle due funzioni.
Vediamole insieme nel file 'application.js':
consentiIlDrop = function(evento){
evento.dataTransfer.dropEffect = 'copy';
evento.preventDefault();
}
caricaIlContenutoTestuale = function(evento,element){
var files = evento.dataTransfer.files;
var reader = new FileReader();
reader.onload = function(evento){
element.value = element.value + evento.target.result;
}
for(file in files){
reader.readAsBinaryString(files[file]);
}
}
La funzione caricaIlContenutoTestuale merita un approfondimento: il metodo files chiamato su
dataTransfer ritorna un elenco di File racchiusi in un oggetto di tipo FileList, che per i nostri
scopi è assimilabile ad un array.
Successivamente, nella variabile reader, viene caricata un istanza di FileReader, una classe
predisposta esclusivamente alla lettura del contenuto degli oggetti di tipo File. Nelle righe successive
viene impostata l’azione associata all’evento onload di reader, che viene invocato al completamento
dell’azione di lettura di un file; all’interno di questa azione il contenuto testuale del file
(evento.target.result) è concatenato al testo già presente nella textarea. L’ultimo frammento di
questa funzione cicla su tutti i file presenti in files; successivamente su ognuno di essi viene
richiesta la lettura al reader attraverso il metodo readAsBinaryString.
Anche per questo esempio abbiamo preparato una demo
(http://www.html.it/guide/esempi/html5/esempi/lezione_drag/fiveboard/index.html). Funziona al
momento solo su Chromium. Per il test basta creare un file di testo, salvarlo (magari sul desktop) e
trascinarlo nella textarea.
Tabella del supporto sui browser
API e Web Applications
Drag and Drop No 3.5+ 3.2+ 2.0+ No
Geolocation API
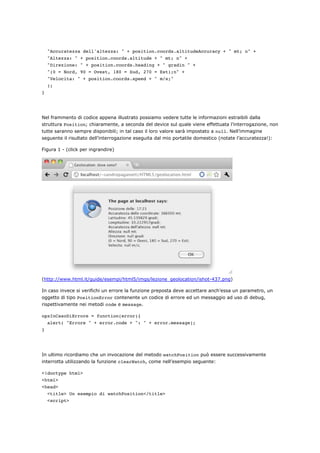
Le Geolocation Api non sono contenute all’interno dell’HTML5 ma fanno parte di quell’insieme di](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-125-320.jpg)






![Pixel per Pixel
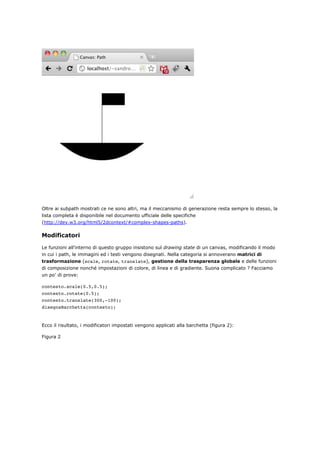
Come già anticipato in precedenza, il canvas non è nient'altro che una matrice di valori in formato
RGBA: non stupisce che sia quindi possibile insistere su ogni singolo e specifico pixel della
stessa; ecco un esempio:
disegnaBarchetta(contesto);
var dati_immagine = contesto.getImageData(0,0,
contesto.canvas.width, contesto.canvas.height);
var array_dati_immagine = dati_immagine.data;
for(var i = 0; i < array_dati_immagine.length; i +=4 ){
array_dati_immagine[i ] = Math.round(Math.random() * 255);
array_dati_immagine[i+1] = Math.round(Math.random() * 255);
array_dati_immagine[i+2] = Math.round(Math.random() * 255);
}
dati_immagine.data = array_dati_immagine;
contesto.canvas.width = contesto.canvas.width;
contesto.putImageData(dati_immagine, 0,0);
Il fulcro dello snippet è da ricercarsi nelle due funzioni getImageData e putImageData che
rispettivamente prelevano e 'stampano' sul canvas una porzione di immagine delineata dagli
argomenti passati. Tale porzione, un oggetto di classe ImageData, possiede in una sua proprietà,
data, un lunghissimo array contenente le componenti RGBA di ogni pixel. Il ciclo for presentato nel
codice precedente insiste proprio su questo array assegnando ad ognuna delle tre componenti RGB un
valore randomico. Ecco il risultato (figura 8):
Figura 8](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-137-320.jpg)
![lanciaEvento = function(nome_evento){
var evento = document.createEvent("CustomEvent");
evento.initCustomEvent(nome_evento, true, true, titolo_fiveboard);
document.dispatchEvent(evento);
}
Eliminiamo successivamente dallo stesso file le funzioni salvaIlDato e recuperaIlDato sostituendole
con le seguenti:
salvaAppunti = function(evento){
localStorage.setItem("fb_" + evento.detail,
document.forms['form_da_ricordare'].elements['testo_da_ricordare'].value
);
alert("Appunti salvati");
}
recuperaAppunti = function(evento){
document.forms['form_da_ricordare'].elements['testo_da_ricordare'].value =
localStorage.getItem("fb_" + evento.detail);
alert("Appunti recuperati");
}
document.addEventListener('salvadato', salvaAppunti);
document.addEventListener('recuperadato', recuperaAppunti);
Bene, ora abbiamo creato le due funzioni e le abbiamo registrate rispettivamente agli eventi custom
‘salvadato’ e ‘recuperadato’; ora non ci resta che scatenare questi eventi al click dei bottoni del file
index.html, modifichiamo quindi come segue:
...
<menu type="toolbar">
<button type="button" onclick="lanciaEvento('salvadato');">
Memorizza quanto scritto
</button>
<button type="button" onclick="lanciaEvento('recuperadato');">
Recupera l'ultimo testo memorizzato
</button>
</menu>
...
Ottimo! Ora possiamo aggiungere un canvas poco prima della fine della pagina e procedere con il
nostro esperimento:
...
<canvas id="drawboard"></canvas>
</form>
...](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-139-320.jpg)

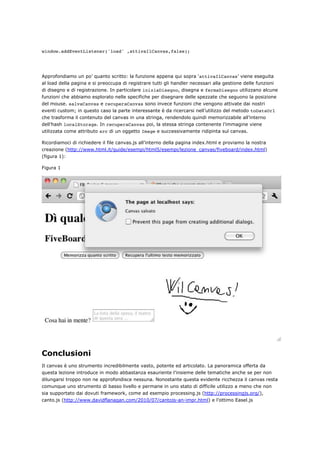



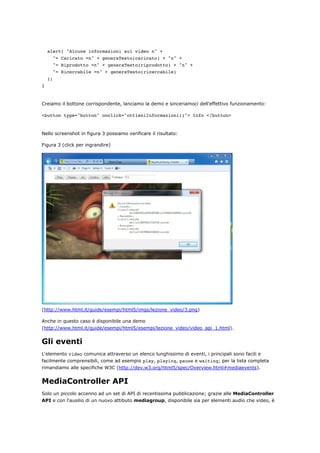


![for(var i=0; i < fotogramma_data.length; i+=4){
if (!rosso) fotogramma_data[i ] = 0;
if (!verde) fotogramma_data[i+1] = 0;
if (!blu ) fotogramma_data[i+2] = 0;
}
fotogramma.data = fotogramma_data;
context.putImageData(fotogramma,0,0);
setTimeout(function(){
decomposizioneColori(video, context, context_nascosto, colori)
},0);
}
aspettaIlPlay = function(evento){
var video = document.querySelector('video');
video.addEventListener("play", function(evento){
var context = document.querySelector('#canvas_principale').ge
tContext('2d');
var context_nascosto = document.querySelector('#canvas_elaborazione').
getContext('2d');
context.canvas.width = context_nascosto.canvas.width = video.clientWid
th;
context.canvas.height = context_nascosto.canvas.height = video.clientH
eight;
decomposizioneColori(evento.target,context,context_nascosto, document.
forms.colori);
},true);
}
window.addEventListener("load",aspettaIlPlay,true);
</script>
</head>
<body>
<canvas id="canvas_principale"></canvas>
<canvas id="canvas_elaborazione" style="display:none;"></canvas>
<video poster="big_buck_bunny/poster.jpg" controls>
<source src="big_buck_bunny/trailer.mp4" type="video/mp4" >
<source src="big_buck_bunny/trailer.ogg" type="video/ogg" >
<source src="big_buck_bunny/trailer.webm" type="video/webm">
</video>
<form name="colori">
<fieldset>
<legend>Usa le checkbox per controllare i tre canali (RGB)</legend>
<label> Rosso <input type="checkbox" name="rosso" checked></label>
<label> Verde <input type="checkbox" name="verde" checked></label>
<label> Blue <input type="checkbox" name="blu" checked></label>
</fieldset>
</form>
</body>
</html>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-149-320.jpg)

![l'elemento HTML né ricorrere a display:none o similari; tratteremo più approfonditamente di questo
aspetto nella sezione dedicata all'esempio.
Per quanto riguarda invece le API e gli eventi associati a questo elemento l'elenco è pressoché
congruente con quello dell'elemento video; le stesse funzioni play, pause, playbackRate,
duration,currentTime e tutto quanto legato ai TimeRanges mantengono inalterato il proprio
comportamento in quanto appartenenti al gruppo HTMLMediaElements al quale entrambi gli elementi
fanno parte.
Un esempio
Sfruttiamo la possibilità di creare oggetti audio utilizzando il costruttore JavaScript per studiare un
meccanismo che ci consenta di associare ad ogni bottone un suono predefinito da riprodurre al click.
Ecco il markup che useremo all'interno del body della pagina:
<button type="button" data-effetto-audio="gatto_che_miagola.mp3" disabled>
Il verso del gatto...
</button>
<button type="button" data-effetto-audio="cane_che_abbaia.mp3" disabled>
Il verso del cane...
</button>
L'utilizzo degli attributi data-* ci consente in modo elegante di aggiungere un'informazione
caratterizzante al pulsante, senza creare strane sovrastrutture. Ora il codice JavaScript dovrà
occuparsi di scandagliare la pagina alla ricerca di pulsanti con suono associato e creare un oggetto
audio con la sorgente che punti all'attributo che abbiamo definito. L'evento canplaythrough, verrà
utilizzato per intercettare il momento in cui un dato oggetto audio ritiene di aver collezionato dati
sufficienti per garantire la riproduzione dell'intero brano. All'accadere di tale evento il pulsante
associato al suono verrà abilitato e un listener in ascolto sull'evento click garantirà l'esecuzione del
suono alla pressione del bottone. Ecco il codice della demo completa:
<!doctype html>
<html>
<head>
<title>Il suono degli animali</title>
<script>
init = function(evento){
var bottoni = document.querySelectorAll('button');
for(var b=0; b < bottoni.length; b ++){
var effetto_audio = bottoni[b].dataset.effettoAudio;
if(effetto_audio != ""){
var audio = new Audio(effetto_audio);
audio.bottone_di_riferimento = bottoni[b];
audio.addEventListener('canplaythrough',
function(evento_load){
var bottone = evento_load.target.bottone_di_riferimento;
bottone.disabled = false;
bottone.audio_di_riferimento = evento_load.target;
bottone.addEventListener('click',
function(evento_click){
evento_click.target.audio_di_riferimento.play();
}](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-152-320.jpg)



![<title>Big Buck Bunny, il trailer</title>
<body>
<svg>
<!-- elementi SVG -->
</svg>
<math>
<!-- elementi MathML -->
</math>
</body>
</html>
E c’è di più: le due sintassi in questione potranno direttamente beneficiare dell’intero ecosistema
HTML5 attorno a loro. Questo significa che una espressione MathML può, in questo contesto, variare a
seguito della ricezione di alcuni dati tramite Ajax, oppure che una rappresentazione SVG può essere
pilotata da alcuni eventi JavaScript attivati attraverso una form.
Conclusioni
Con queste due nuove frecce al suo arco, le specifiche HTML5 acquistano un nuovo livello di potenza.
Forse non capiterà troppo spesso di implementare sintassi MathML per sistemi applicativi ma
sicuramente lo stesso non si può dire per SVG. Anche il supporto a queste due specifiche è diverso, la
Scalable Vector Graphic è pressoché presente su tutte le più recenti versioni dei browser, mentre il
supporto per il markup per definire espressioni matematiche comincia ora ad affacciarsi nelle prime
beta, come ad esempio Firefox 4 o la versione nightly di WebKit. In ogni caso esiste una interessante
libreria JavaScript, MathJax (http://www.mathjax.org/), capace di interpretare linguaggio MathML e
generare una corretta rappresentazione grafica sulla maggior parte dei browser in commercio.
Una 'lavagna virtuale'
Nel corso delle lezioni abbiamo assistito al graduale arricchimento del progetto guida; in questo
articolo ne esploreremo alcune possibili evoluzioni attraverso l’utilizzo delle API HTML5 apprese finora.
Il canvas nella dashboard
È possibile fare in modo che dalla dashboard (dashboard.html) si possa visualizzare il contenuto,
attuale e salvato, del canvas di una data fiveboard con un meccanismo simile a quello utilizzato per la
memorizzazione su localStorage. Per ottenere questo risultato possiamo sostituire il blocco legato al
comando ‘richiedi_testo’ nel file application.js con:
case 'richiedi_testo':
evento.ports[0].postMessage('testo_corrente:' +
document.forms['form_da_ricordare'].elements['testo_da_ricordare'].value);
evento.ports[0].postMessage('testo_memorizzato:' +
localStorage.getItem("fb_" + titolo_fiveboard));
evento.ports[0].postMessage('canvas_corrente:' +
ctx.canvas.toDataURL('image/png'));
evento.ports[0].postMessage('canvas_memorizzato:'+](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-156-320.jpg)
![localStorage.getItem("canvas_fb_" + titolo_fiveboard));
break;
A questo punto dobbiamo far sì che la dashboard sappia ricevere ed interpretare correttamente questi
4 distinti messaggi, modifichiamo quindi il blocco che fa seguito al comando attendi_testo in
dashboard.html:
case 'attendi_testo':
evento.ports[0].onmessage = function(e){
nome_comando = e.data.split(":")[0]
valore_comando = e.data.substr(nome_comando.length + 1);
elemento = document.getElementById(nome_comando);
switch (elemento.tagName){
case 'CANVAS':
elemento.width = elemento.width;
if(valore_comando == 'null') return
var context = elemento.getContext('2d');
var immagine = new Image();
immagine.src = valore_comando; context.drawImage(immagine,0,0);
break;
case 'TEXTAREA':
if(valore_comando == 'null')
valore_comando = '';
elemento.value = valore_comando;
break;
}
}
break;
Nel frammento di codice appena esposto facciamo uso dell’attributo tagName per determinare il tipo di
elemento che deve contenere le informazioni appena ricevute. In questo modo il comando
‘testo_memorizzato:contenuto_del_testo’ inviato dalla fiveboard si traduce nella valorizzazione
dell’elemento ‘testo_memorizzato’ a ‘contenuto_del_testo’ nella dashboard.
Completiamo questa evoluzione inserendo gli elementi di markup all’interno di dashboard.html:
</ol>
<section>
<h1>In Osservazione:</h1>
<textarea id="testo_corrente" placeholder="testo_corrente" readonly></textarea>
<textarea id="testo_memorizzato" placeholder="testo_memorizzato" readonly></textarea
>
<canvas id="canvas_corrente">Canvas Corrente</canvas>
<canvas id="canvas_memorizzato">Canvas Memorizzato</canvas>
</section>
Ecco uno screenshot dell’implementazione funzionante (figura 1):](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-157-320.jpg)
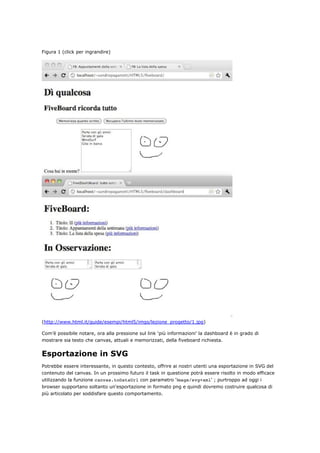

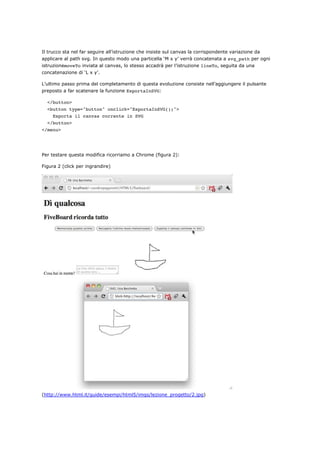
![Ed ecco il risultato! Mentre la barchetta nella finestra in sfondo risiede su di un canvas quella in primo
piano è creata a partire da un file SVG; notate inoltra il curioso URL di questa finestra, generato in
tempo reale dalla funzione di cui abbiamo parlato poco fa.
Non ci resta che rimandare alla demo
(http://www.html.it/guide/esempi/html5/esempi/lezione_progetto/fiveboard/index.html) per un test.
Il codice è disponibile per il download
(http://www.html.it/guide/esempi/html5/esempi/lezione_progetto/fiveboard.zip).
Un passo avanti
Con quest’ultima evoluzione ci apprestiamo a congedare il progetto guida, utile assistente durante le
passate lezioni. Per chi fosse interessato a mantenere questo applicativo come base per proprie
sperimentazioni ecco alcuni possibili e sfidanti implementazioni effettuabili:
Fare in modo che il viewer.html possa seguire in tempo reale anche l’atto del disegno sul
canvas della fiveboard che sta osservando, così come oggi avviene per il testo. Questa modifica
coinvolge la definizione di un protocollo snello per la trasmissione di dati di questo tipo
attraverso un WebSocket.
Refactoring! Perché non provare a fare in modo che i comandi che giungono alle pagine web
nel formato scelto per convenzione come ‘nome_comando:valore_comando’ siano trasformati in
eventi custom e propagati attraverso il DOM ? La sintassi potrebbe essere questa:
worker.port.onmessage = function(evento){
nome_comando = evento.data.split(":")[0]
valore_comando = evento.data.substr(nome_comando.length + 1);
var evento_custom = document.createEvent("CustomEvent");
evento_custom.initCustomEvent(nome_comando, true, true, valore_comando);
document.dispatchEvent(evento_custom);
}
In questo modo si potrebbe ottenere una struttura molto più elegante, nella quale ogni aspetto
dell’applicazione si sottoscrive autonomamente agli eventi dei quali necessita.
Conclusioni
Con questa lezione si conclude il ciclo dedicato all’esplorazione delle nuove API rese disponibili
dall’HTML5. Prima della conclusione di questa guida trova spazio un'ultima lezione, la prossima,
incentrata su tutte le tematiche che legano le specifiche al mondo reale. Verranno quindi trattati temi
come il feature detection ed elencate librerie che possono, di caso in caso, sopperire alla mancanza
di particolari funzionalità. Proprio a questo tema ricordiamo che il progetto guida è nato e cresciuto
con finalità didattiche e di sperimentazione e per questa ragione è molto carente in termini di
compatibilità tra browser e graceful degradation; a ben pensare anche perseguire queste tematiche
potrebbe essere un ottimo esercizio da svolgere in autonomia dopo aver letto la prossima lezione!
Feature detection e strategie di fallback
Come si comportano le API e i nuovi tag proposti dall'HTML5 nel mondo reale? Come dobbiamo](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-161-320.jpg)
![comportarci se vogliamo beneficiarne? In quest'ultima lezione risponderemo a questa importantissima
domanda esaminando alcune best-practice per una implementazione che possa arricchire le nostre
applicazioni e portali web senza causare grattacapi e disagi.
Una pioggia di tag
Possiamo usare <article>, <section> o <footer> su browser come Internet Explorer 6? La
risposta è sì, a patto di premunirsi di alcuni semplici e comodi strumenti capaci di far recepire questi
nuovi elementi HTML5 anche a user-agent non più giovanissimi. Uno di questi tool, specificatamente
progettato per i browser di casa Microsoft, prende il nome di html5shim
(http://code.google.com/p/html5shim/) e può essere incluso nelle proprie applicazioni molto
facilmente:
<!--[if lt IE 9]>
<script src="http://html5shim.googlecode.com/svn/trunk/html5.js"></script>
<![endif]-->
Questo strumento fa sì che Internet Explorer possa applicare gli stili ai nuovi tag introdotti
dall'HTML5. Ma ancora non basta. La maggior parte dei browser di non ultima generazione, infatti,
non conoscendo direttamente i nuovi elementi, applica a loro un foglio di stile di base errato,
assegnando ad esempio display:inline a tag come <article> o <section>.
Per risolvere questa fastidiosa incombenza la soluzione migliore è utilizzare un foglio di stile capace di
resettare le proprietà di questi e altri elementi attivando il comportamento atteso. HTML5 reset
stylesheet (http://html5doctor.com/html-5-reset-stylesheet/) si presta in modo ottimale a questo
obiettivo; l'unico passo da compiere è includerlo all'interno del proprio sito prima degli altri documenti
.css.
Feature detection vs. browser detection
La corsa all'HTML5 intrapresa dai vari browser nell'ultimo periodo si può descrivere come una
incrementale implementazione delle feature proposte dal W3C; il criterio con cui viene stabilita la
priorità nella 'scaletta delle API da aggiungere' è influenzato da moltissimi fattori e differisce da
prodotto a prodotto. Allo stato attuale delle cose non ha quindi particolarmente senso determinare il
comportamento della propria applicazione sulla base dello user-agent che la sta eseguendo, quanto
più cercare di intercettare la presenza o meno di una specifica feature.
L'attività, potenzialmente noiosa di per sé, viene facilitata in modo estremo dalla presenza sul
mercato di un utilissimo tool: Modernizr.js (http://www.modernizr.com/). Facciamo un esempio,
sinceriamoci del supporto per il localStorage:
if(Modernizr.localstorage) {
alert("Rilevato il supporto per il localStorage");
} else {
alert("Oh oh, nessun supporto per il localStorage");
}
Semplice, elegante e molto comodo. L'installazione di questa libreria si risolve con una semplice
inclusione e una speciale classe da applicare al tag <html>:
<html class="no-js">
<head>](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-162-320.jpg)
![<script src="/modernizr-1.6.min.js"></script>
<script>
// Ora puoi utilizzare Modernizr!
</script>
</head>
Fallback e alternative
Abbiamo scoperto che il nostro utente non supporta una certa funzionalità... e ora? Niente panico:
nella maggior parte dei casi esistono valide alternative, o quantomeno interessanti opzioni di
fallback. Vediamole nel dettaglio.
Audio e Video
In questo caso l'alternativa migliore rimane la collaudata tecnologia Flash. Esistono parecchie
librerie sulla rete capaci di determinare autonomamente il supporto o meno al tag <video> e agire di
conseguenza. Noi abbiamo scelto video.js (http://videojs.com/) per la sua maturità e per l'ottimo
supporto di skin con le quali personalizzare il proprio player. L'utilizzo è semplicissimo e ben illustrato
nella pagina di Getting Started (http://videojs.com/#getting-started).
Canvas
Abbiamo due soluzioni da segnalare come alternativa all'assenza canvas: la prima si chiama
explorercanvas (http://code.google.com/p/explorercanvas/), una libreria Javascript sviluppata da
Google per simulare il comportamento del <canvas> all'interno di Internet Explorer. Per attivarla è
sufficiente richiamare lo script excanvas.js all'interno del proprio tag <head>:
<!--[if IE]><script src="excanvas.js"></script><![endif]-->
Da qui in poi è possibile utilizzare all'interno della pagina il tag <canvas> ed invocare su questo la
maggior parte dei metodi previsti dalle specifiche W3C.
L'altra tecnica di fallback prende invece il nome di FlashCanvas (http://flashcanvas.net/) ed emula il
comportamento delle API HTML5 attraverso il sapiente utilizzo della tecnologia Flash. La versione 1.5,
supera più del 70% dei test proposti da Philip Taylor
(http://philip.html5.org/tests/canvas/suite/tests/), piazzandosi in questo modo sul primo gradino del
podio delle alternative disponibili. Anche in questo caso per beneficiare di questa libreria è necessario
solamente richiamare l'apposito file javascript:
<!--[if lt IE 9]>
<script type="text/javascript" src="path/to/flashcanvas.js"></script>
<![endif]-->
Geolocation
Come simulare le API di geolocazione quando non sono supportate? Prima di disperare è importante
ricordare che seppur non tutti browser implementano queste specifiche è comunque possibile alle
volte accedere ad informazioni geospaziali utilizzando API proprietarie messe a disposizione da
particolari device o plug-in esterni, come ad esempio Google Gears. geo-location-javascript
(http://code.google.com/p/geo-location-javascript/) è una libreria che identifica le varie estensioni
disponibili sul portatile (o smartphone) dell'utente e ne uniforma e centralizza le API permettendo di](https://image.slidesharecdn.com/html5based-120409034324-phpapp01/85/Html5-based-163-320.jpg)










Il documento presenta una guida operativa su HTML5, rivolta sia a sviluppatori che a lettori interessati ad approfondire le novità del linguaggio. Viene illustrato il percorso di apprendimento, suddiviso in macro-sezioni sui nuovi approcci semantici e sulle API, con progetti pratici per facilitare la comprensione. Inoltre, si discute la compatibilità del supporto HTML5 nei vari browser e l'evoluzione delle specifiche dal contesto di HTML4 all'attuale HTML5.
























































