Downloaded 48 times

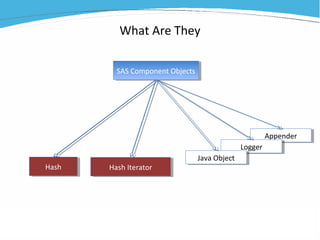
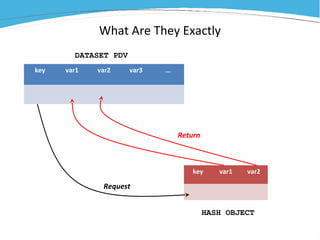

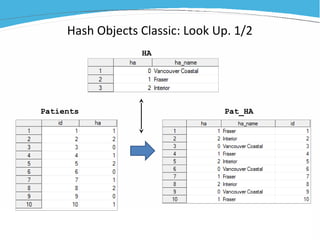
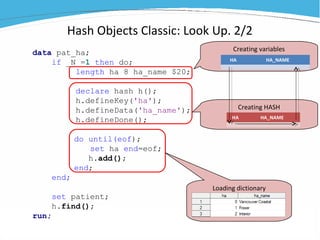
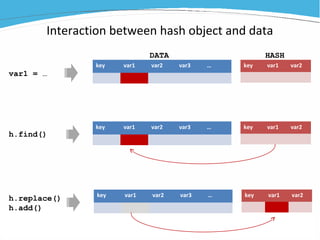

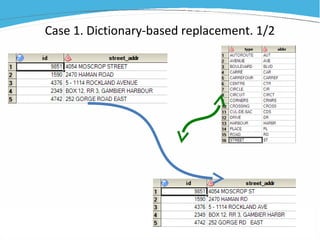
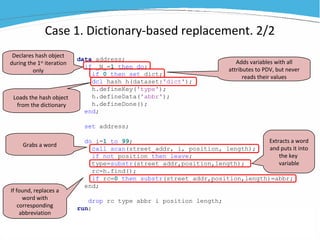
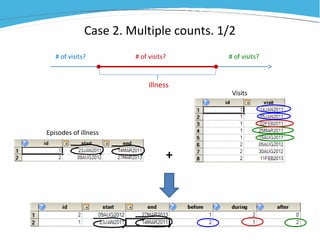


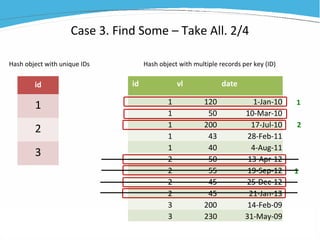
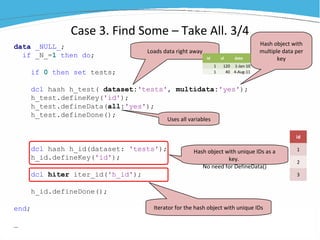
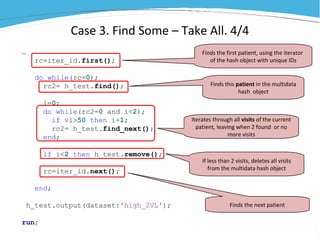
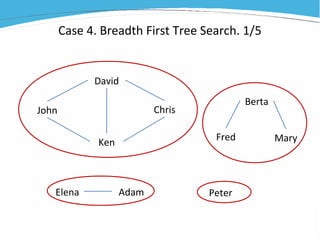
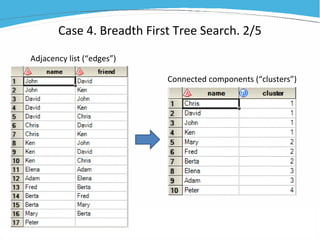
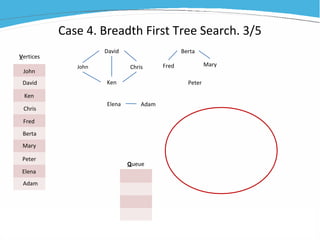
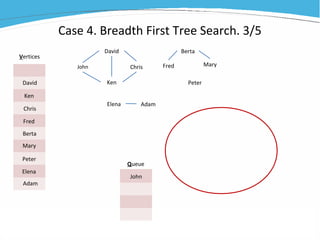
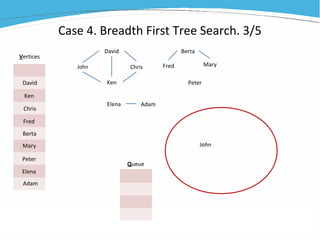
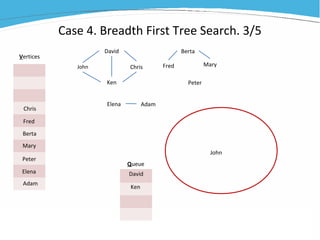
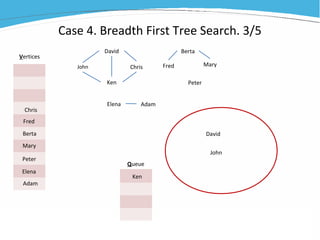
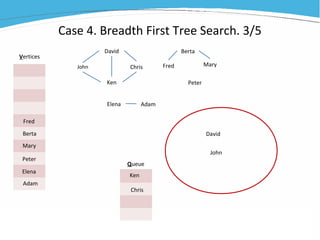
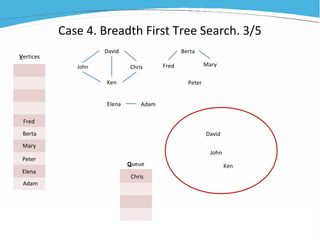
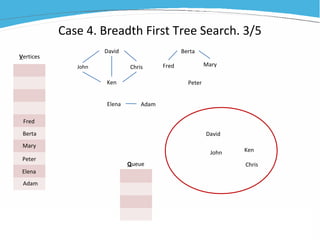
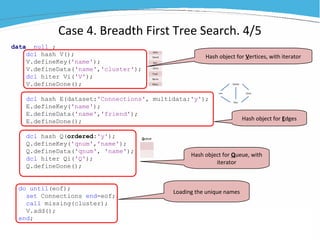
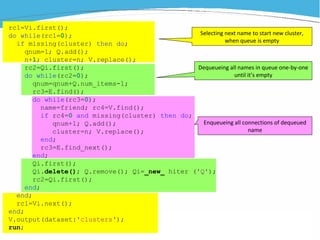


1) The document discusses various examples of using SAS hash objects including looking up values in a dictionary, counting multiple occurrences, finding records that meet certain criteria, and performing a breadth-first tree search. 2) Hash objects allow storing and accessing data in memory for fast lookups and processing without reading from disk each time. 3) The examples demonstrate how to declare, define, load, access, and manipulate hash objects to perform common data manipulation tasks more efficiently.
































![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)

