Download as PDF, PPTX





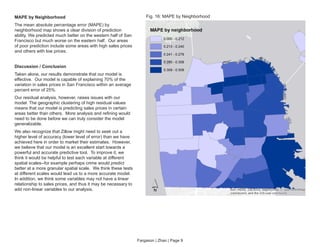

This document summarizes a hedonic home price prediction model developed by Phil Fargason and Jianting Zhao for Zillow. They collected 23 variables related to home characteristics, location, neighborhood attributes, crime, transportation and demographics. Their linear regression model explained 70% of variation in home prices in San Francisco with a mean absolute percentage error of 25%. Key factors correlated with higher prices included property size, number of bedrooms/bathrooms, proximity to transit and colleges, and surrounding home prices.













































