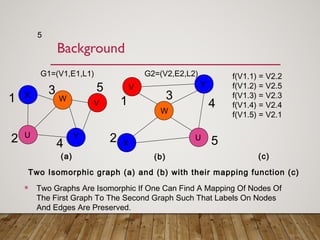
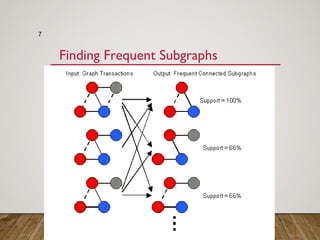
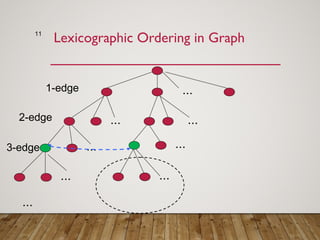
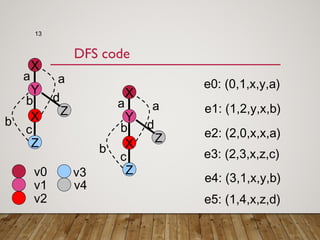
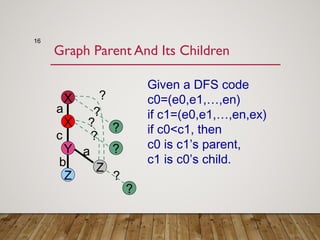
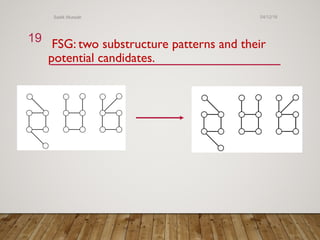
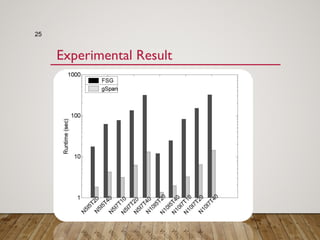
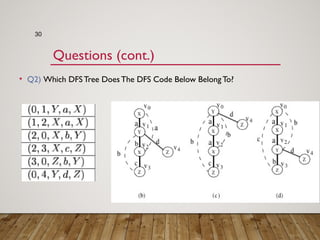
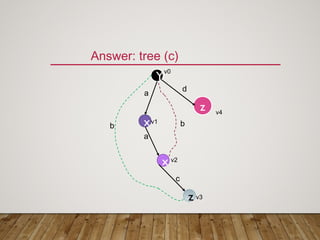
Gspan is an algorithm for frequent subgraph mining that avoids two major costs of previous approaches. It represents graphs as depth-first search (DFS) codes and builds a DFS code tree to systematically explore the search space. Each node in the tree represents a unique graph. Gspan tests for graph isomorphism by comparing minimum DFS codes, allowing it to prune redundant portions of the search space. An experimental evaluation showed it has good performance and scales well compared to previous methods.















































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)










