Downloaded 77 times




















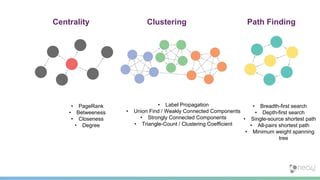
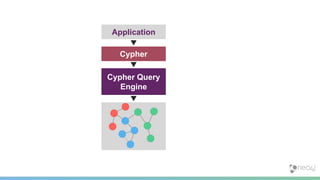
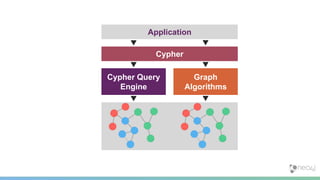
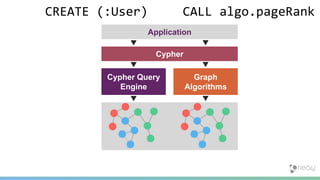
![PageRank
N MATCH (n) RETURN count(n)
M(p) MATCH (p)<--(q) RETURN q
L(p) MATCH (p)-[r]->() RETURN count(r)](https://image.slidesharecdn.com/graphtour2018closingkeynote-180220105018/85/GraphTour-Closing-Keynote-48-320.jpg)


![(:Page)-[:Link]->(:Page)
11 million nodes
116 million relationships
DBPedia](https://image.slidesharecdn.com/graphtour2018closingkeynote-180220105018/85/GraphTour-Closing-Keynote-51-320.jpg)





![Traversals
Realistic retail dataset from Amazon
Commodity dual Xeon processor server
Social recommendation (Java procedure) equivalent to:
MATCH (you)-[:BOUGHT]->(something)<-[:BOUGHT]-(other)-[:BOUGHT]->(reco)
WHERE id(you)={id}
RETURN reco](https://image.slidesharecdn.com/graphtour2018closingkeynote-180220105018/85/GraphTour-Closing-Keynote-58-320.jpg)




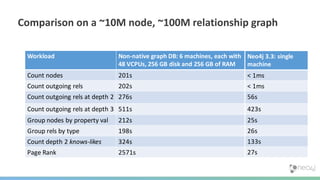


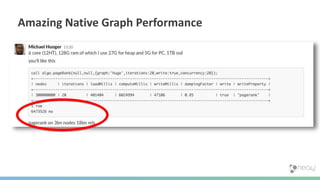




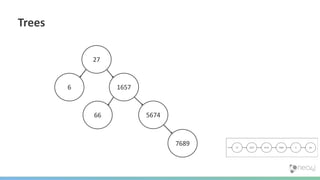
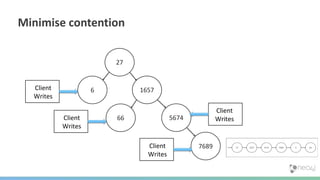
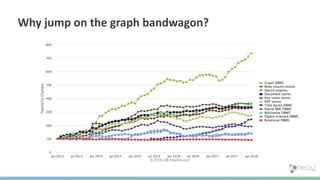
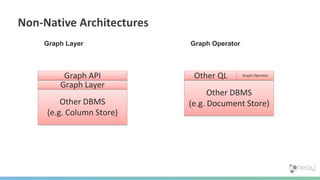
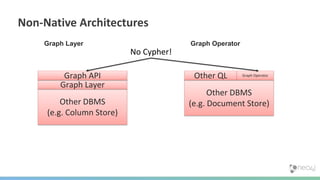
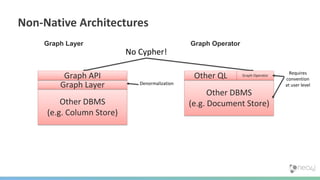
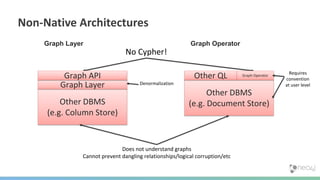
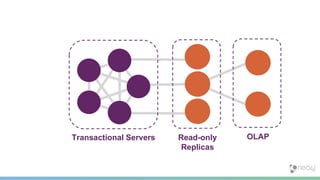
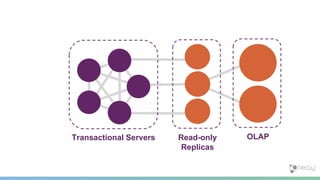
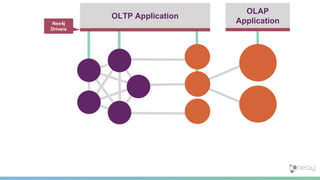
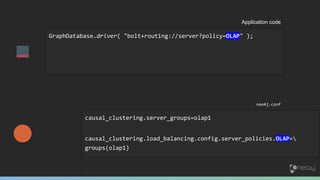
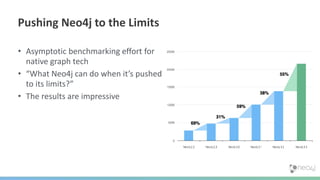
The document summarizes the advantages of a native graph database like Neo4j over non-native graph approaches. It discusses how: 1) Non-native graph databases require denormalization and cannot fully enforce graph integrity since the database was not designed for graphs. 2) Neo4j is a native graph database where the engine, data structures, and query language are purpose-built for graphs, allowing it to achieve better performance, scale, and enforcement of graph constraints compared to non-native solutions. 3) Benchmarks show Neo4j can handle workloads with trillions of relationships, millions of writes per second, and outperform non-native databases on common graph queries by over






















































































