Download to read offline
















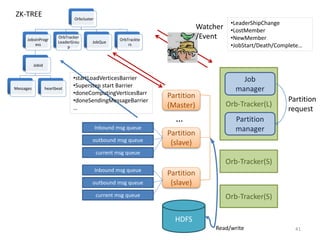
![Message Exchange
• Message교환은 Superstep간에 이루어짐
• [S-1] superstep의 outbound message들은 [s] superstep의 inbound
messages
• Outbound Queue가 가득차면 message들을 보내고 다시 queuing
• Superstep 중간에 message를 받은 partition은 inbound queue에
저장하고 다음 Superstep까지 보관
• 현재 superstep에 사용할 message들은 current message queue에 복사
• 이 때, inbound queue가 system이나 jvm의 memory size 를 넘어서면
overflow 발생](https://image.slidesharecdn.com/graphanalysisplatform20120718-180419155304/85/Graph-analysis-platform-comparison-pregel-goldenorb-giraph-42-320.jpg)




















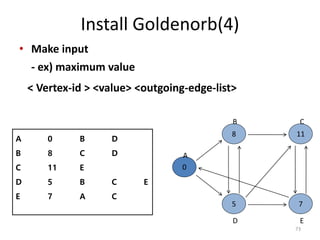


![Install Giraph(2)
• Set running environment
① >$HADOOP_HOME/bin/start-all.sh
② >$ZK_HOME/zkServer.sh start
• Upload input file to HDFS
> hadoop fs –put test.grf /giraph/test/input/
* Input Format (JASON)
76
[0,0,[[1,0]]]
[1,0,[[2,100]]]
[2,100,[[3,200]]]
[3,300,[[4,300]]]
[4,600,[[5,400]]]](https://image.slidesharecdn.com/graphanalysisplatform20120718-180419155304/85/Graph-analysis-platform-comparison-pregel-goldenorb-giraph-76-320.jpg)



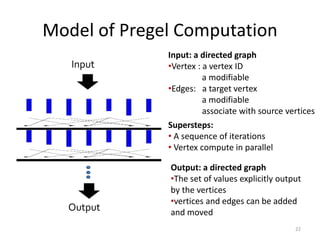
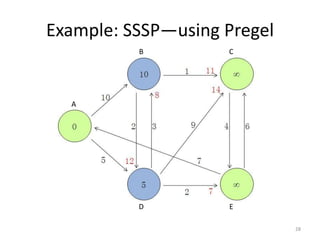
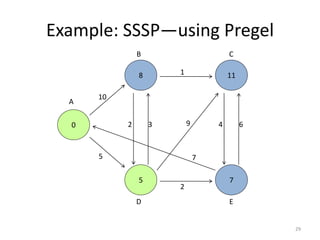
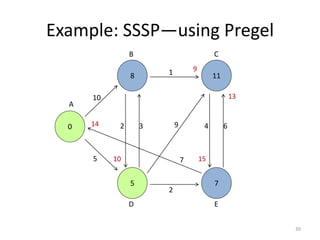
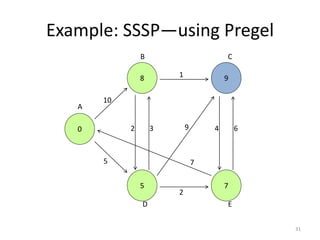
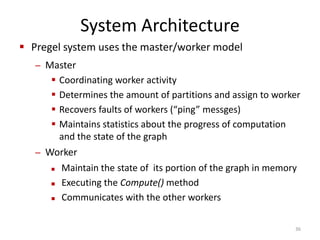
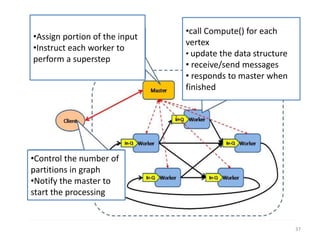
The document discusses a system for large-scale graph processing, focusing on Google's Pregel architecture, alongside its alternatives like GoldenOrb and Giraph. It highlights the limitations of MapReduce for iterative graph processing and proposes Pregel as a more efficient model that maintains graphs in memory and reduces network communication. The document also outlines the framework's fault tolerance and architecture, emphasizing the master/worker model for computation management.













































