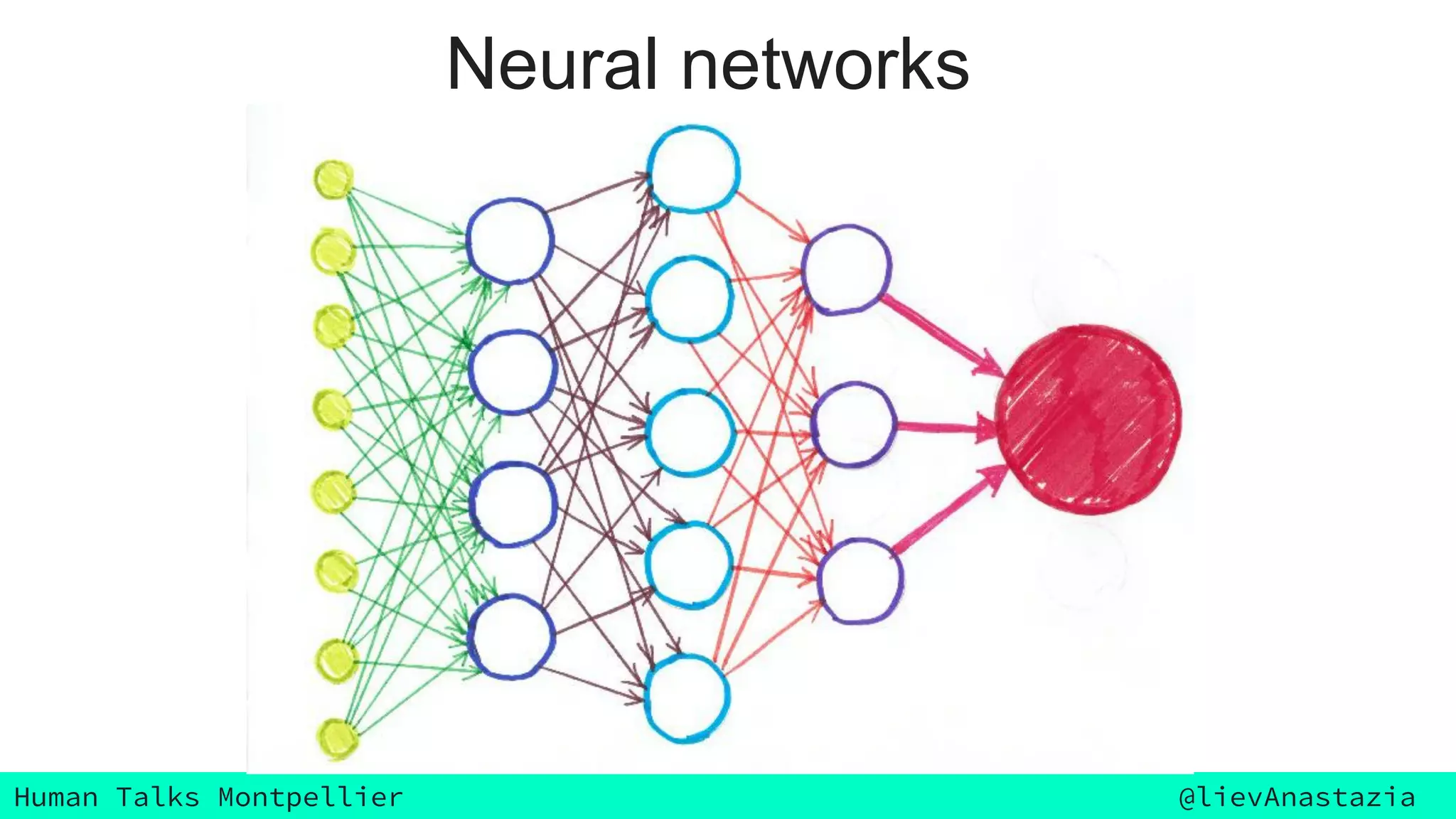
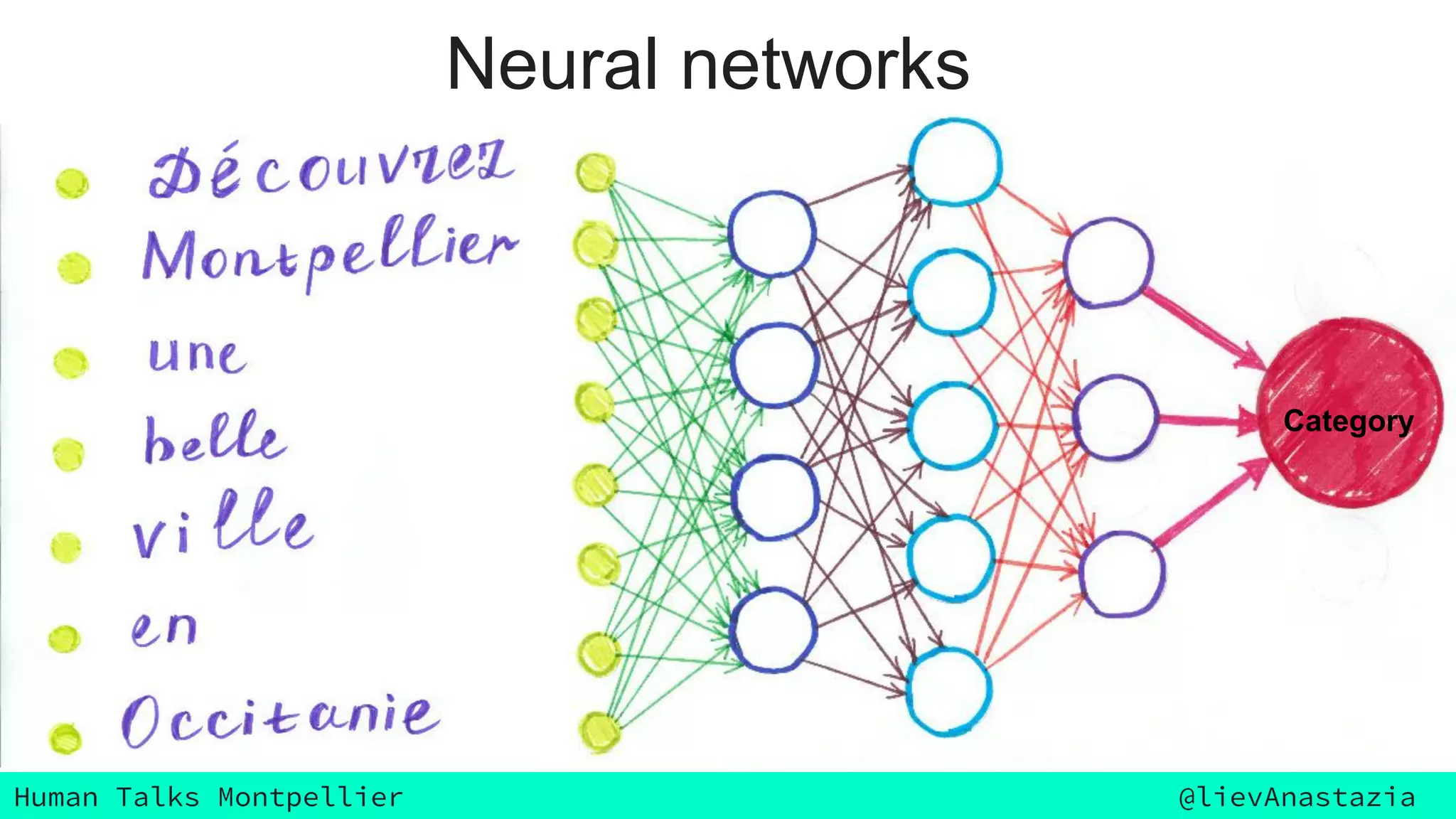
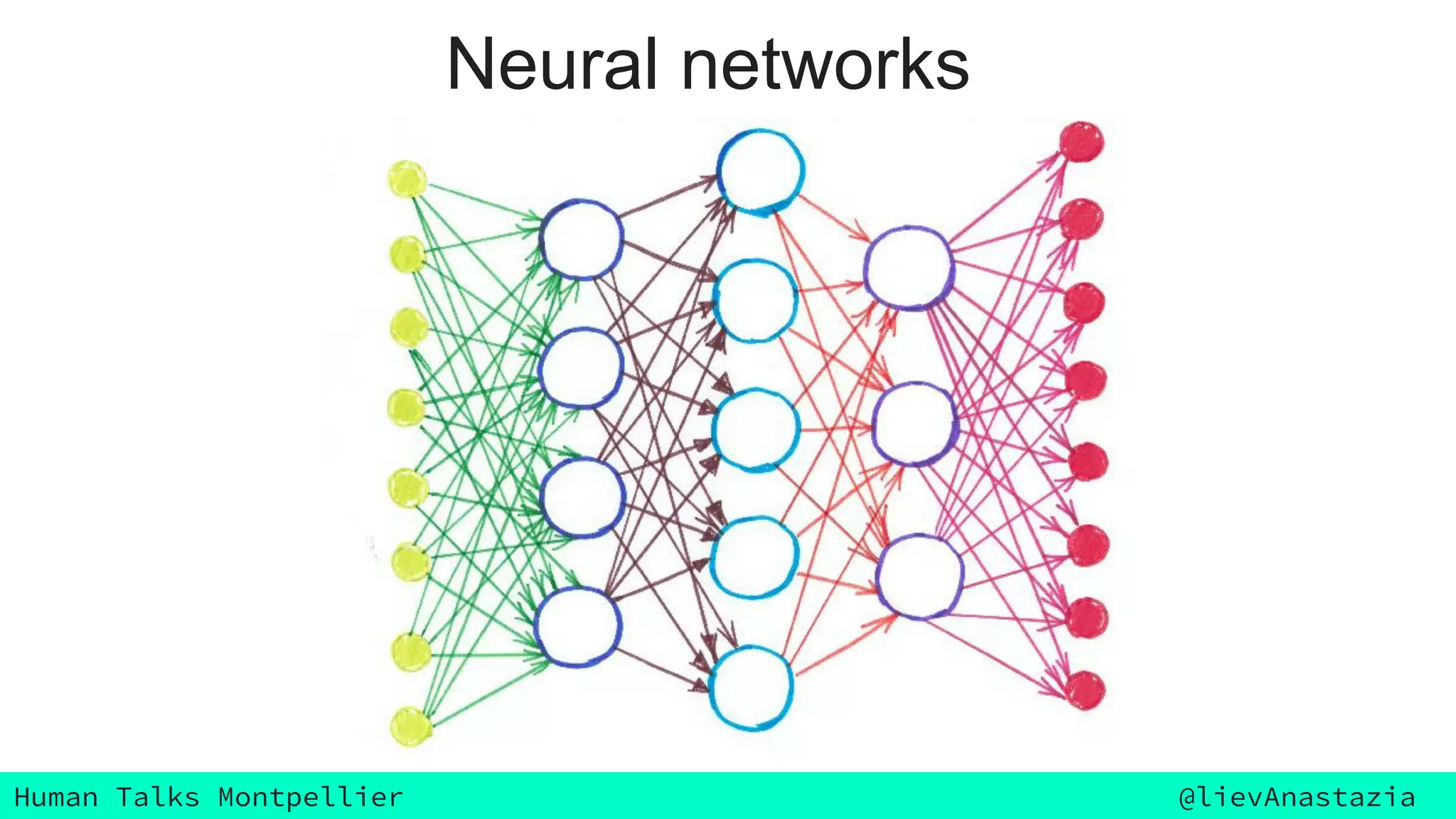
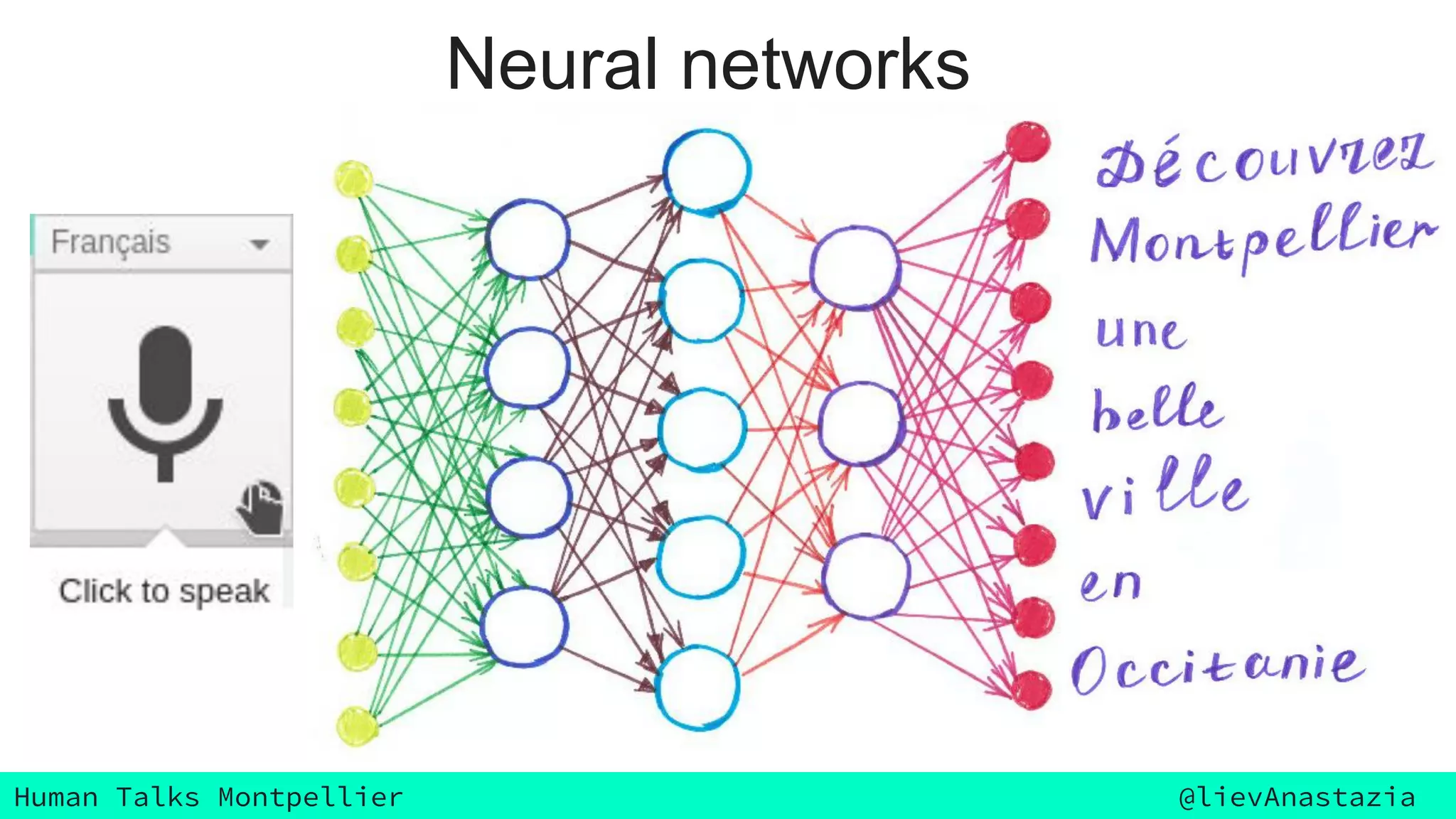
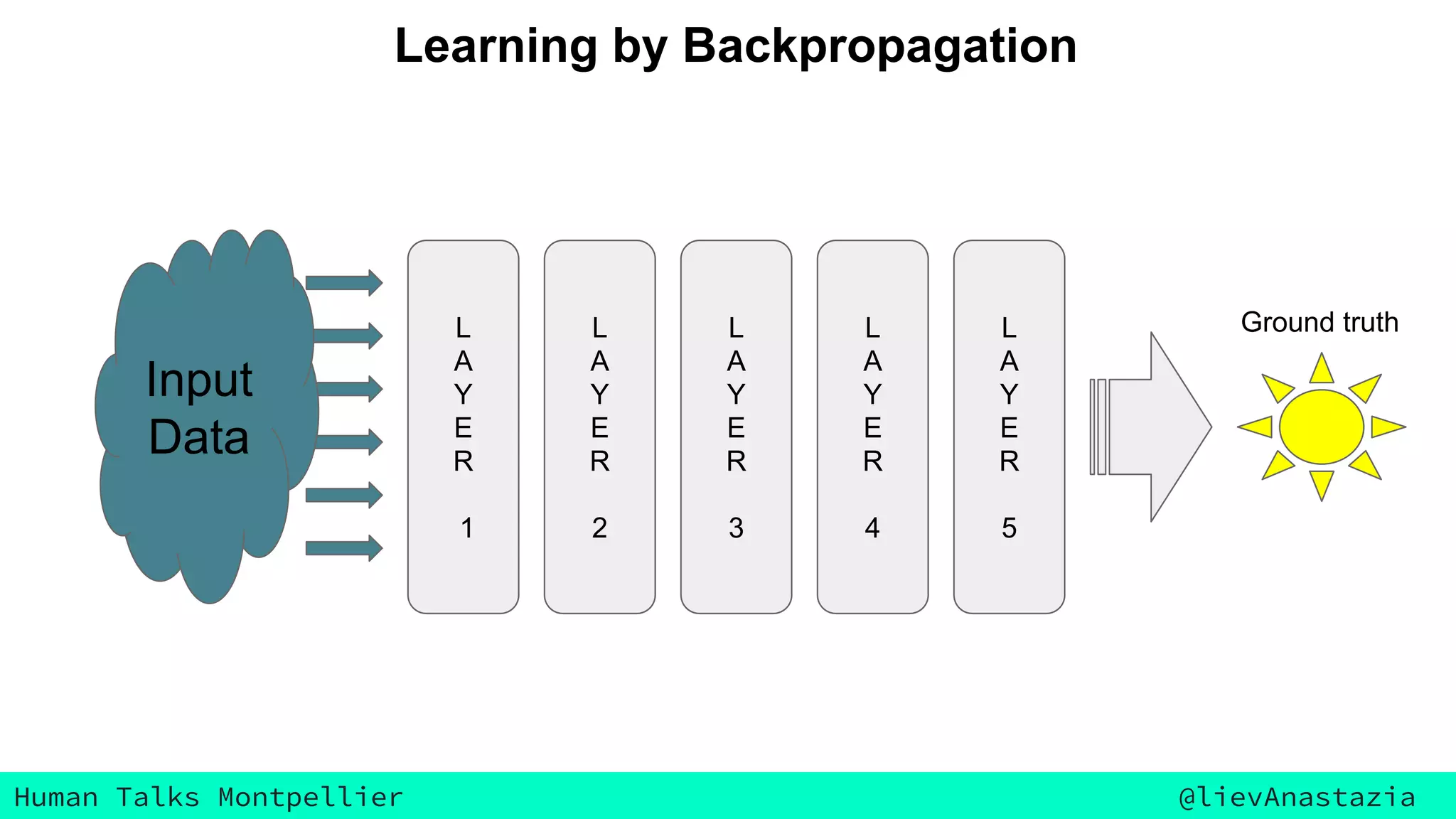
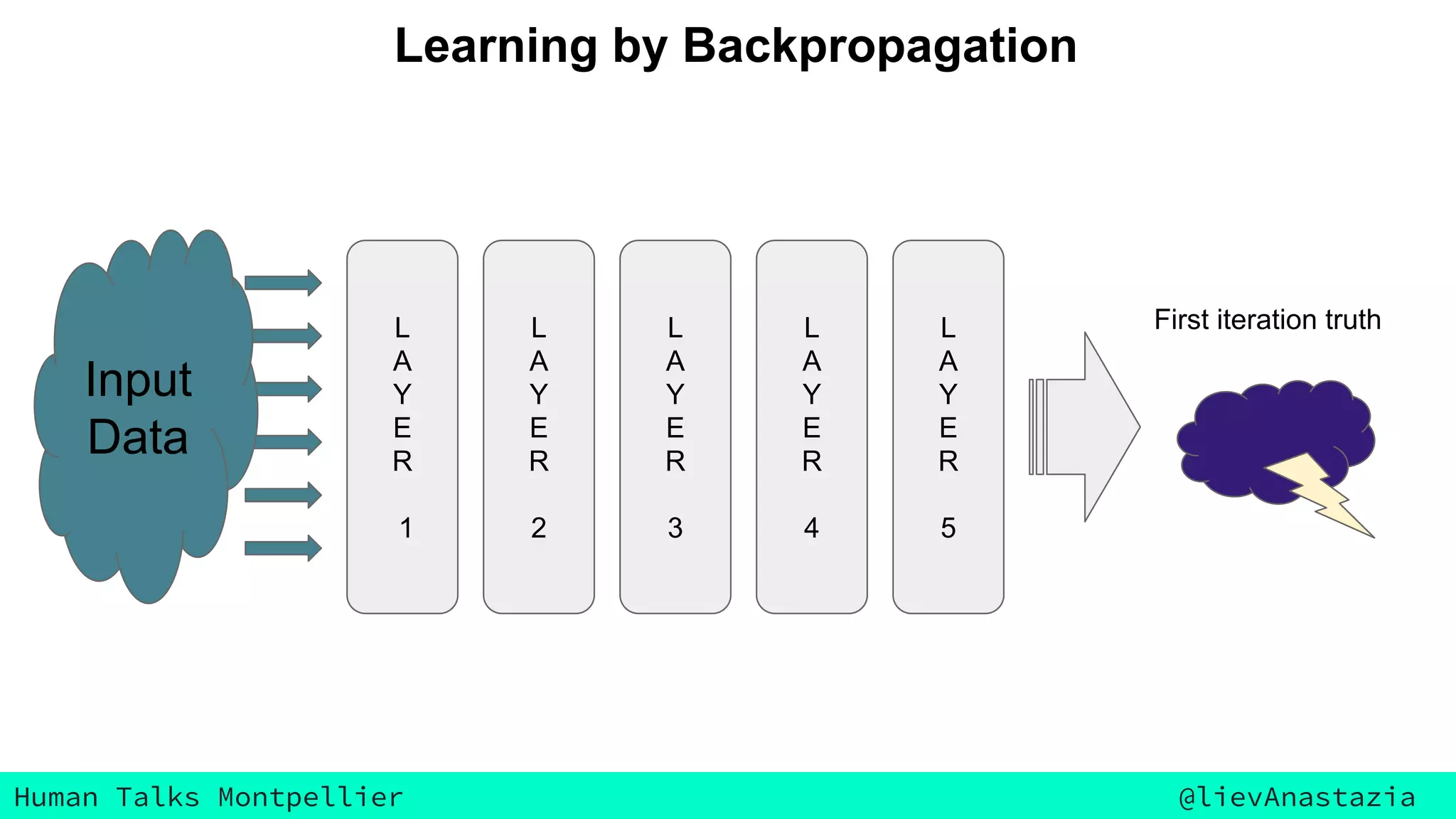
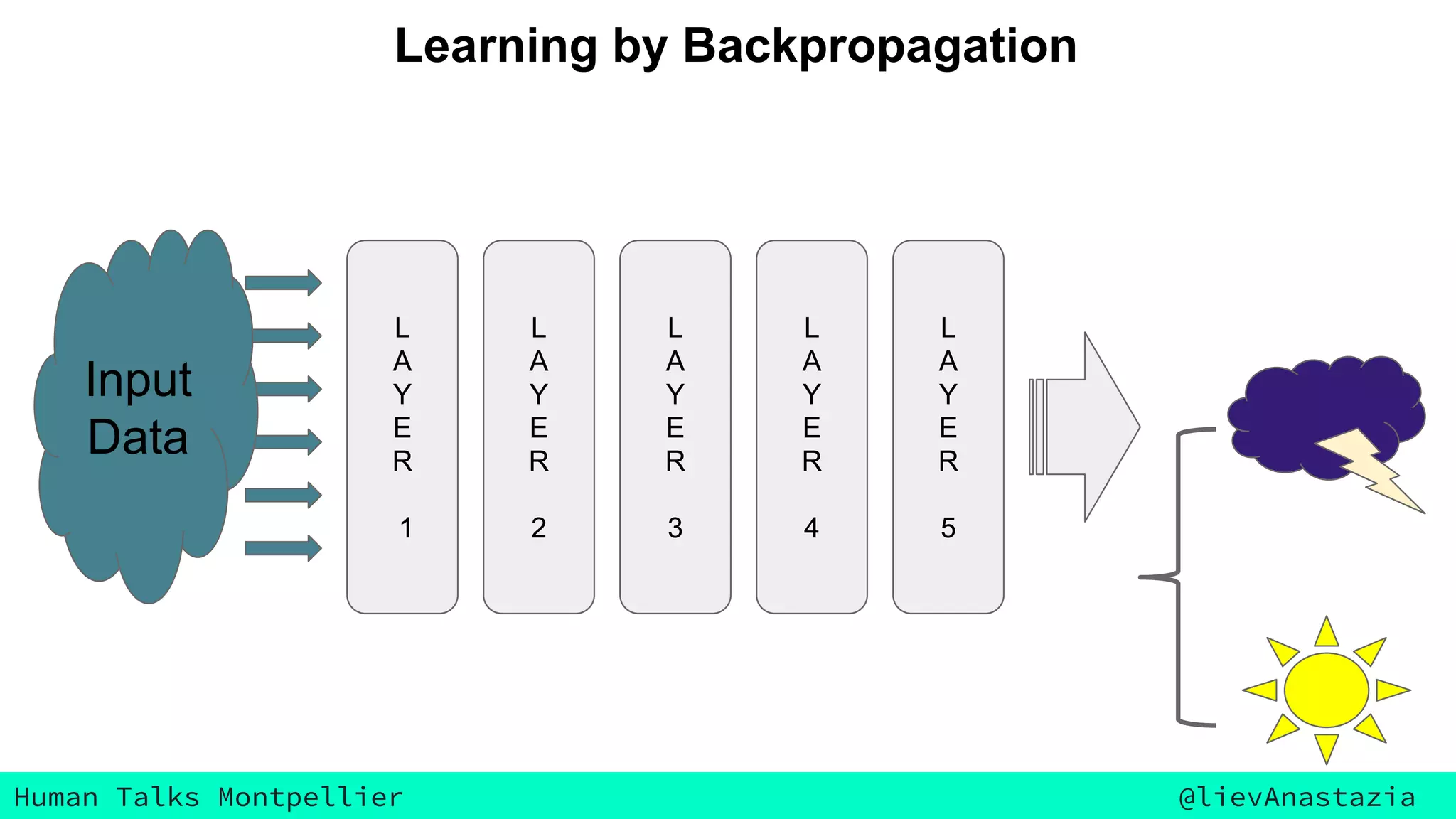
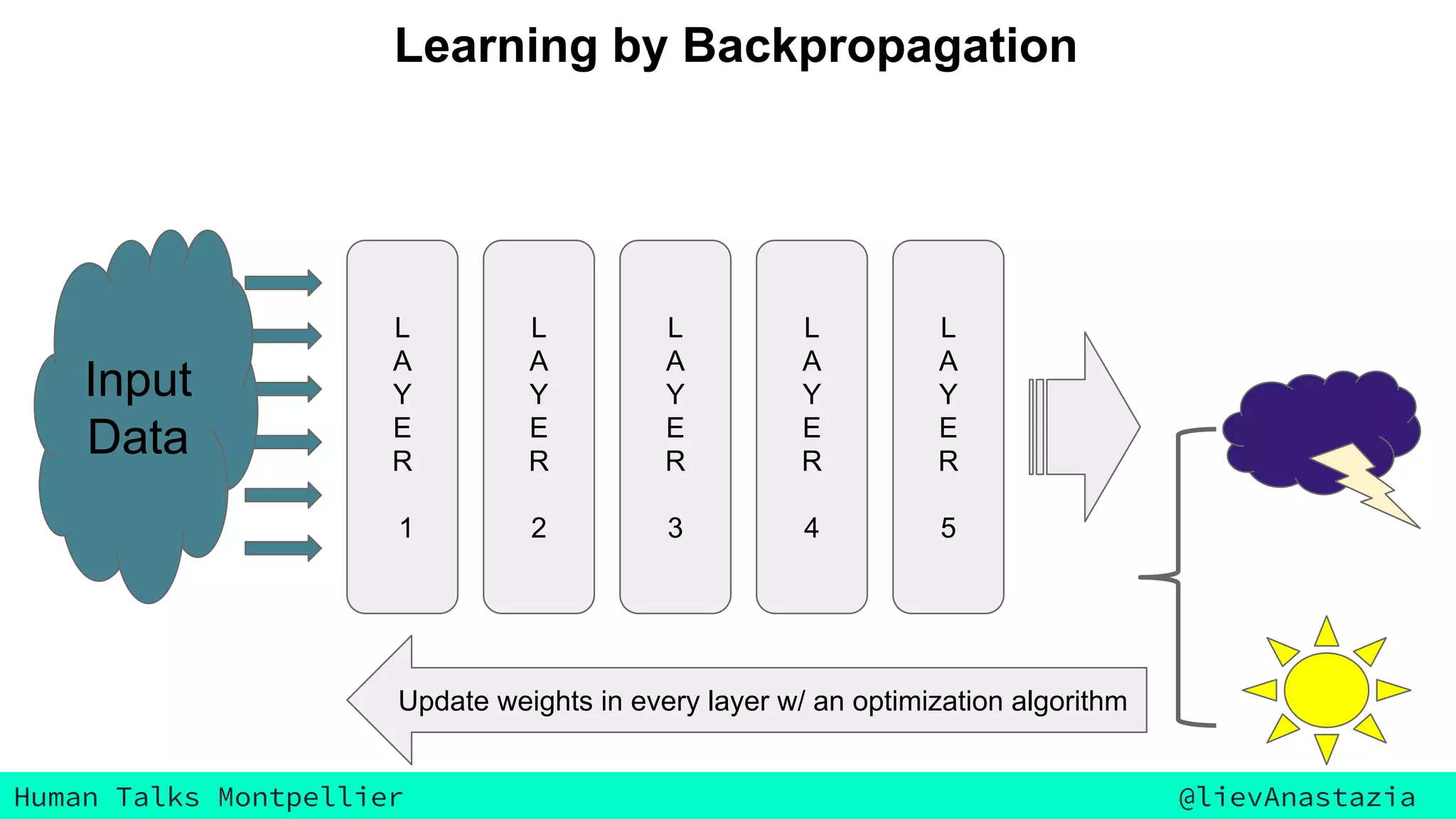
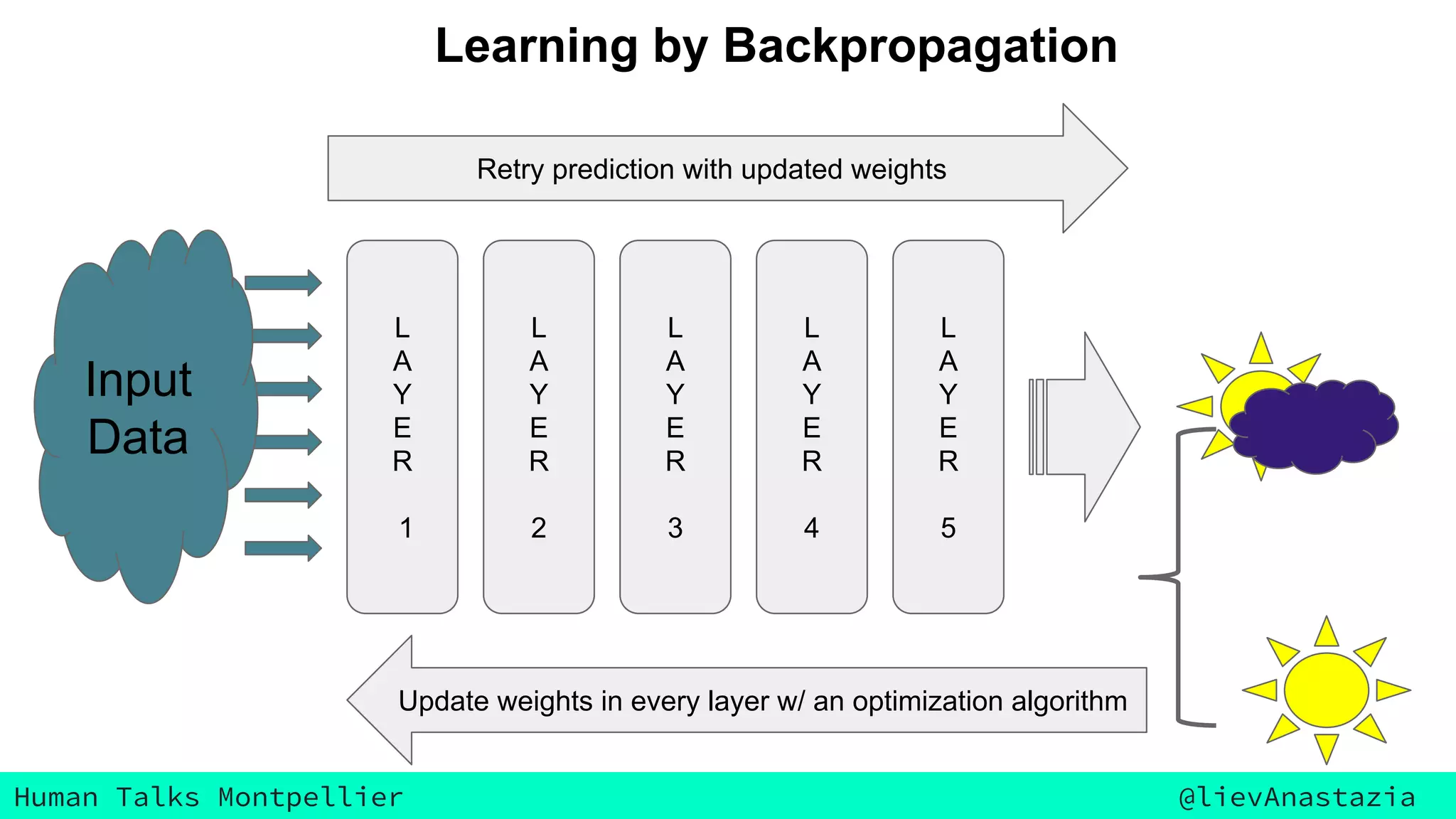
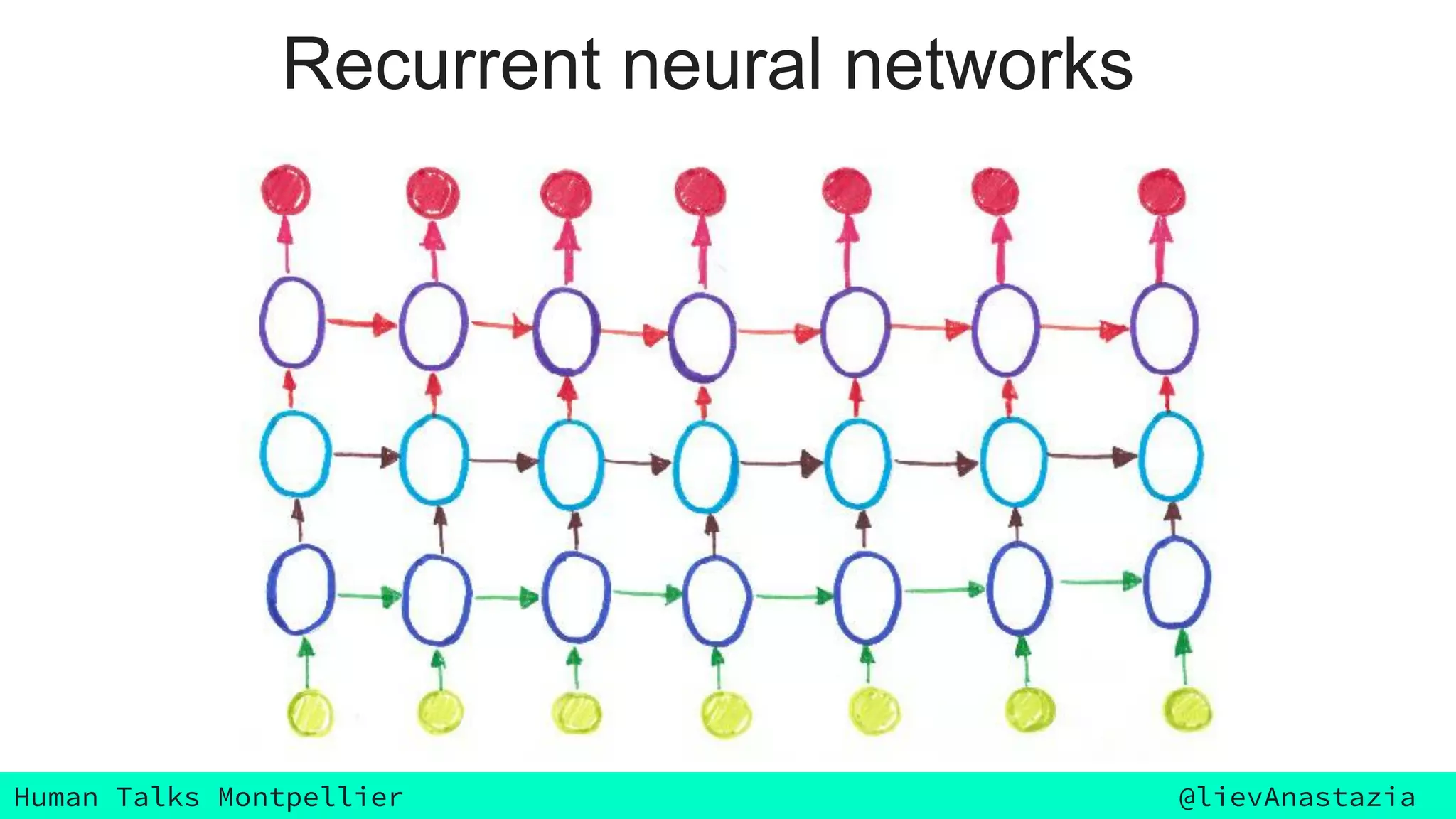
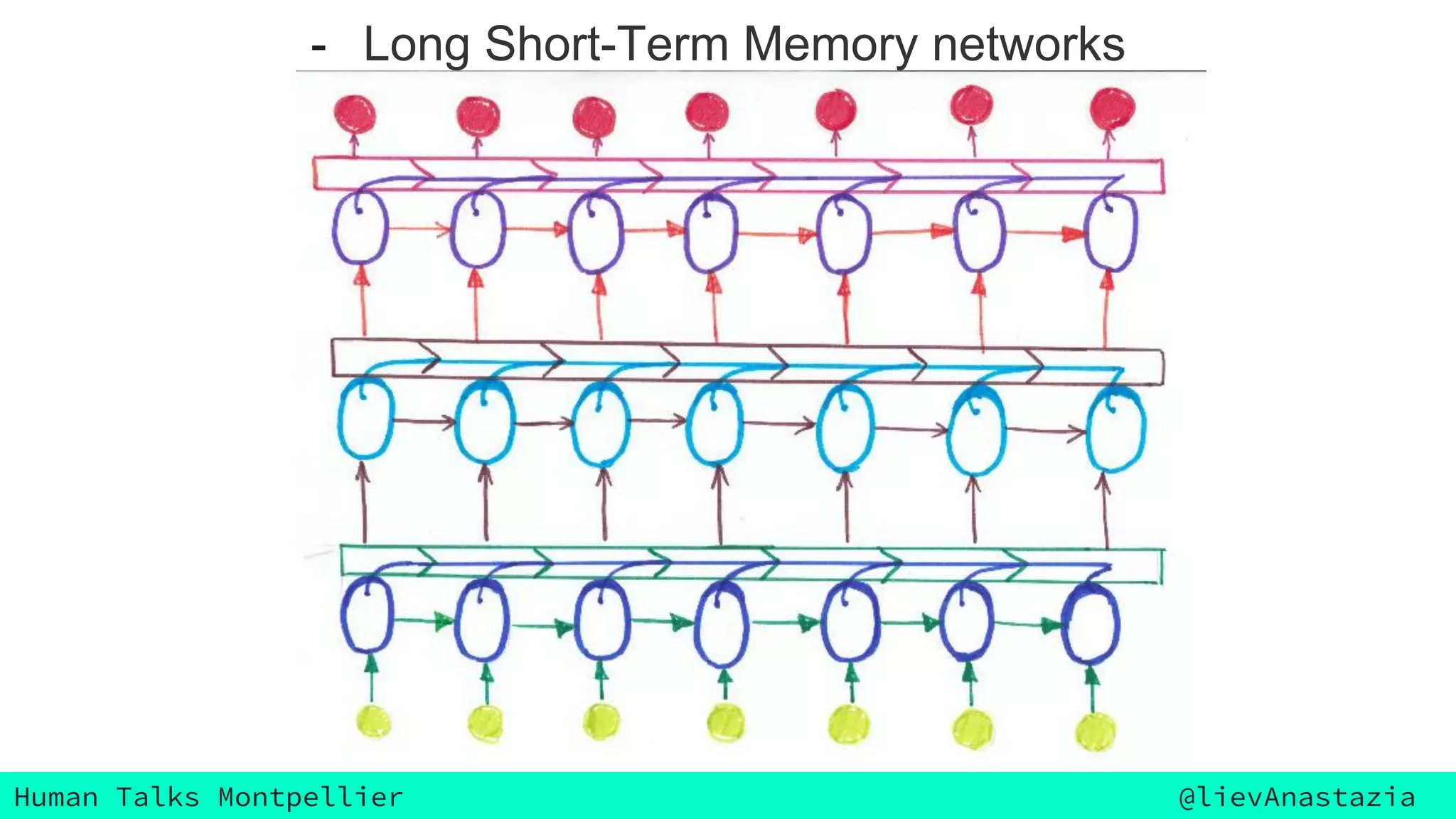
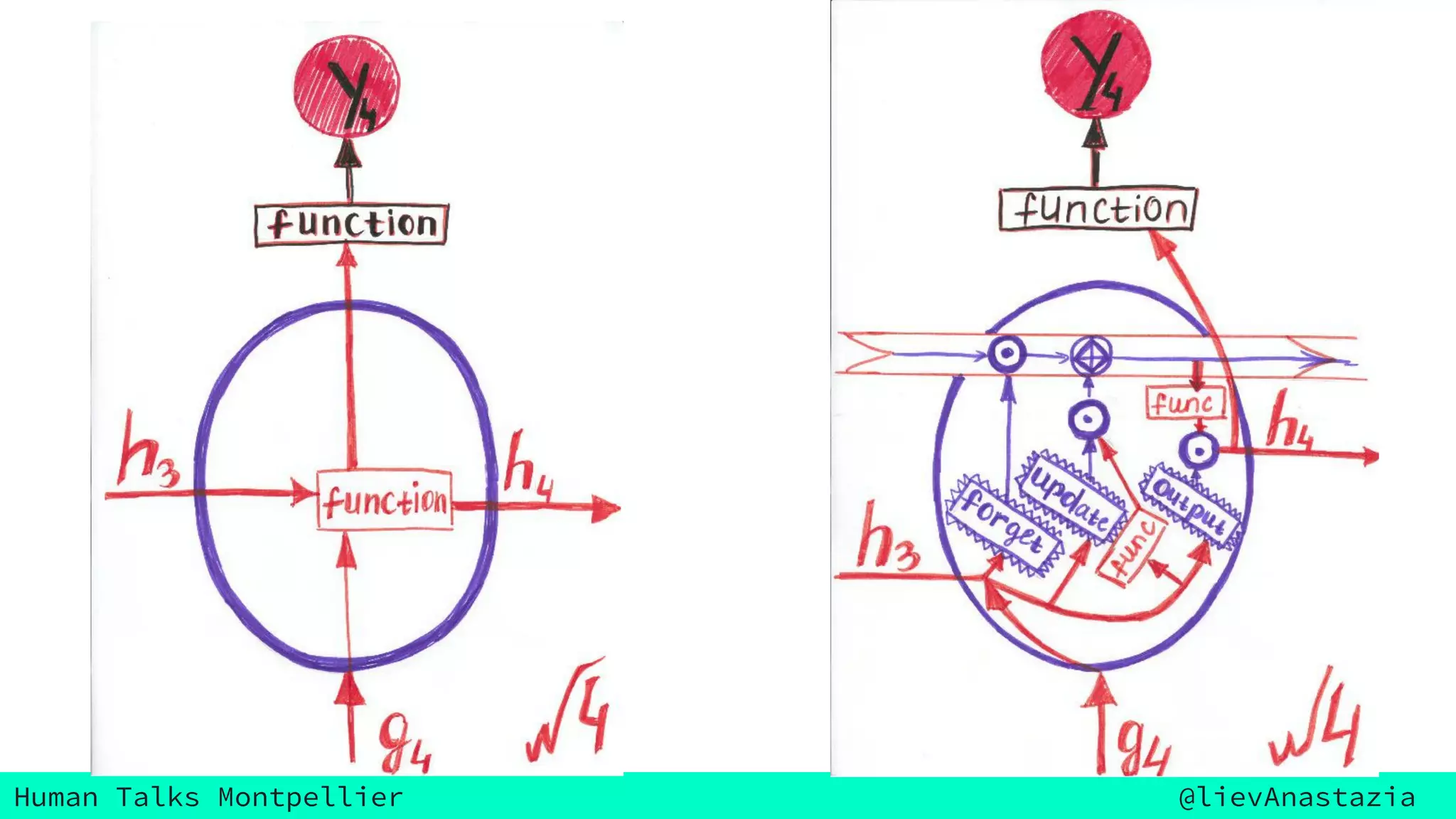
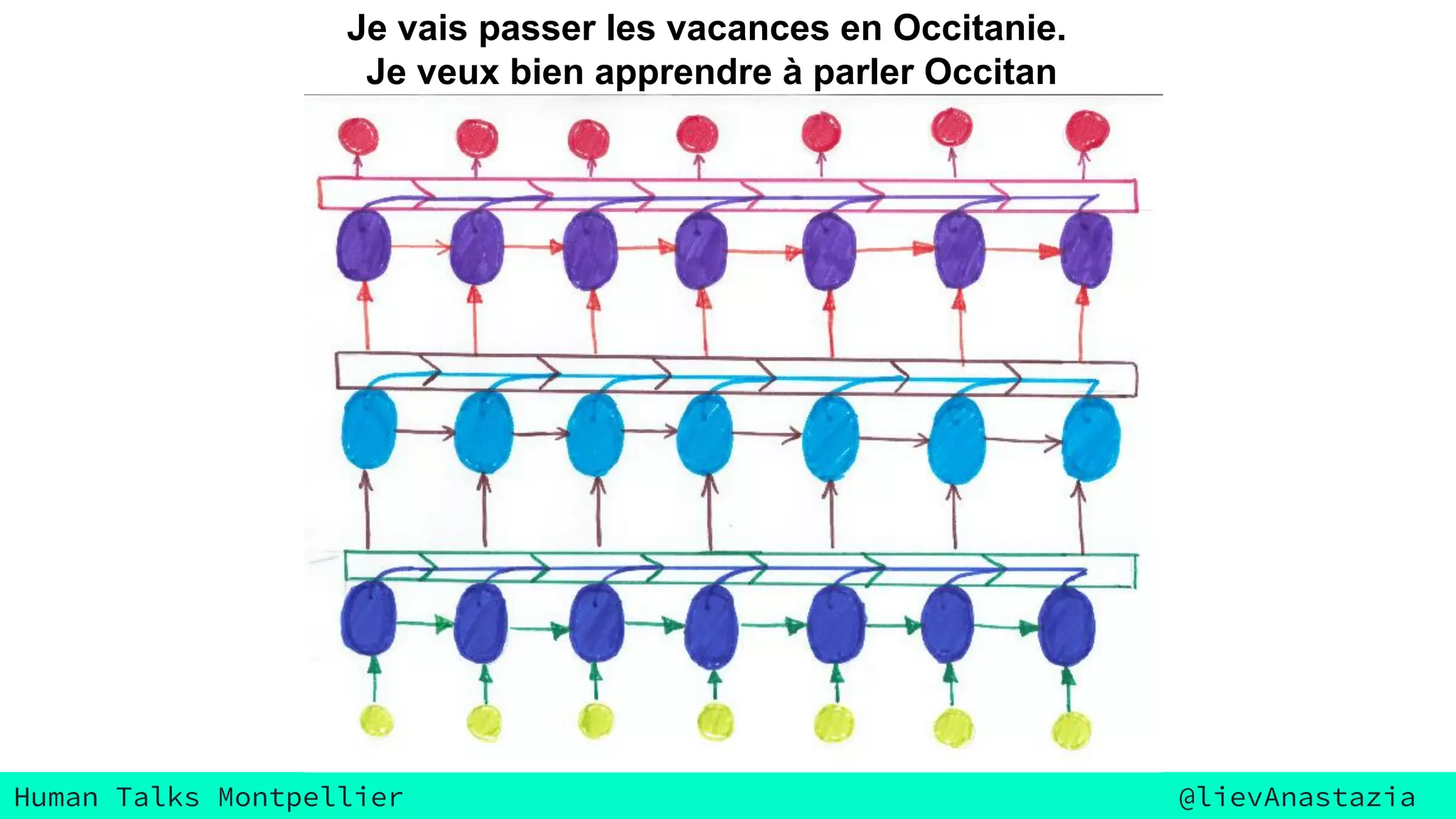
The document discusses Google Voice transcriptions and introduces recurrent neural networks (RNNs) and long short-term memory (LSTM) networks, emphasizing their architecture and learning process through backpropagation. It mentions various applications of RNNs and LSTMs, including time series analysis, natural language processing, and automatic cars. The document also suggests further reading materials for those interested in deepening their understanding of these neural networks.