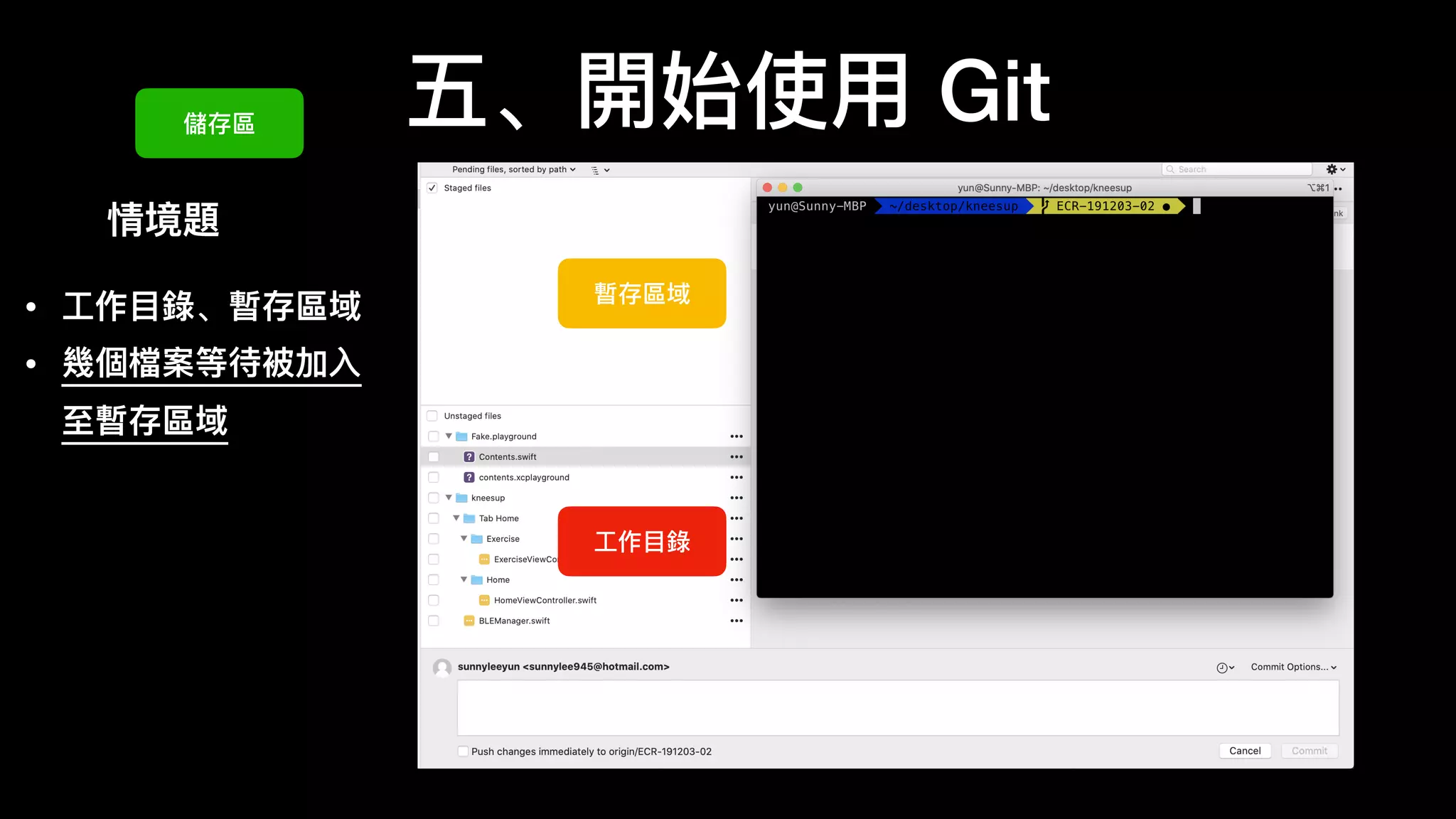
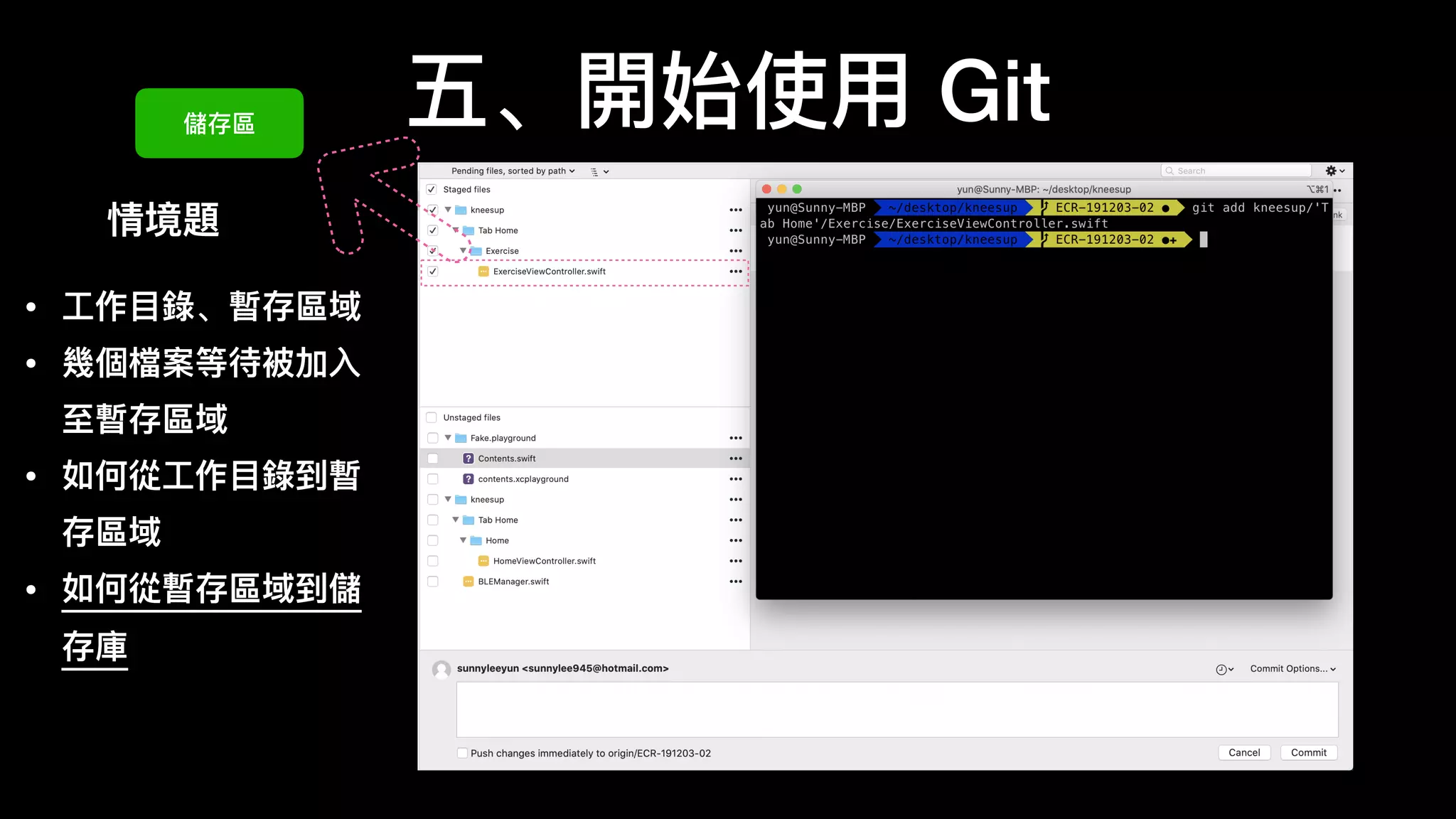
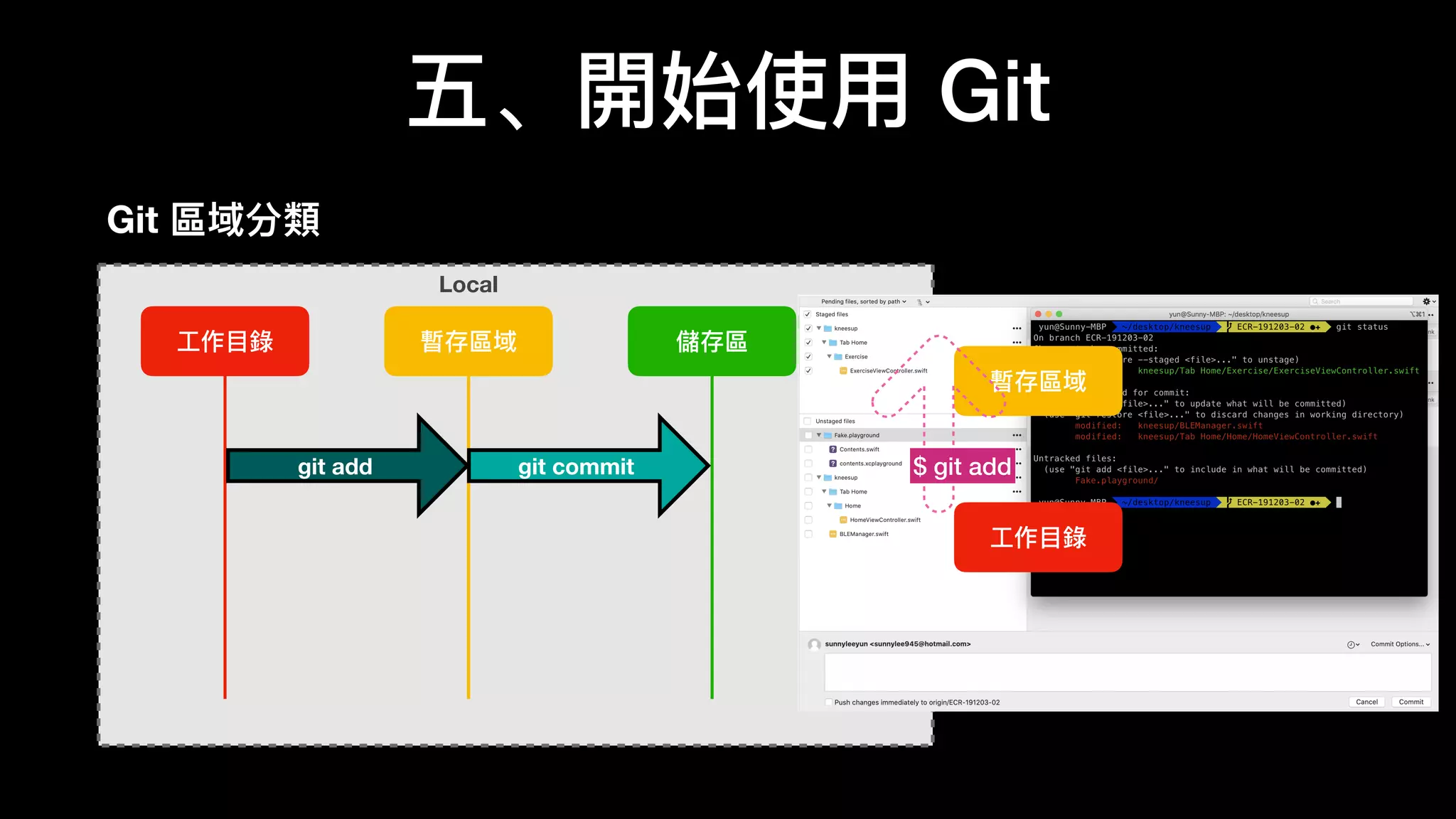
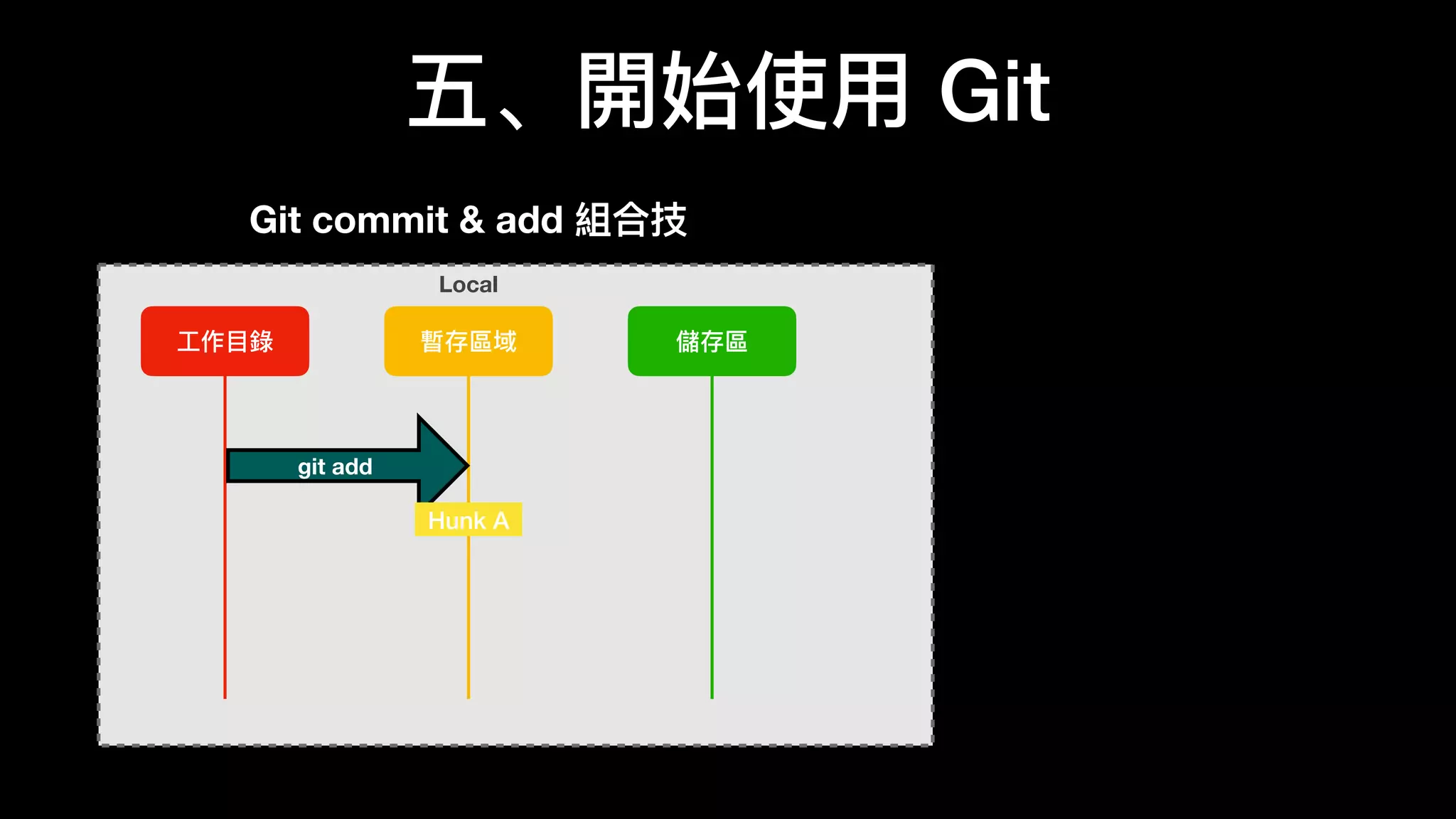
文档介绍了 Git 的基本概念和使用方法,强调其优点包括免费、开源和速度快。作者提及 Git 的历史背景以及如何在不同操作系统上安装和配置 Git。文中还详细说明了 Git 的工作区、暂存区和版本库的状态变化,以及常用的命令和技巧。























![四、設定 Git
• $ git help sth
• ⽐比如 $ git help config
• $ man [insert command here]
• 補充:每天使⽤用 Git 的 19 ⼩小技巧
Need Some Help?](https://image.slidesharecdn.com/a-200725140809/75/Git-24-2048.jpg)
![四、設定 Git
• $ git help sth
• ⽐比如 $ git help config
• $ man [insert command here]
• 補充:每天使⽤用 Git 的 19 ⼩小技巧
更更重要的是
善⽤用⾕谷歌⼤大神的⼒力力量量
Need Some Help?](https://image.slidesharecdn.com/a-200725140809/75/Git-25-2048.jpg)





























































































































































![[PHP 也有 Day #64] PHP 升級指南](https://cdn.slidesharecdn.com/ss_thumbnails/php-upgrade-guide-220301051052-thumbnail.jpg?width=640&height=640&fit=bounds)








































