Download to read offline


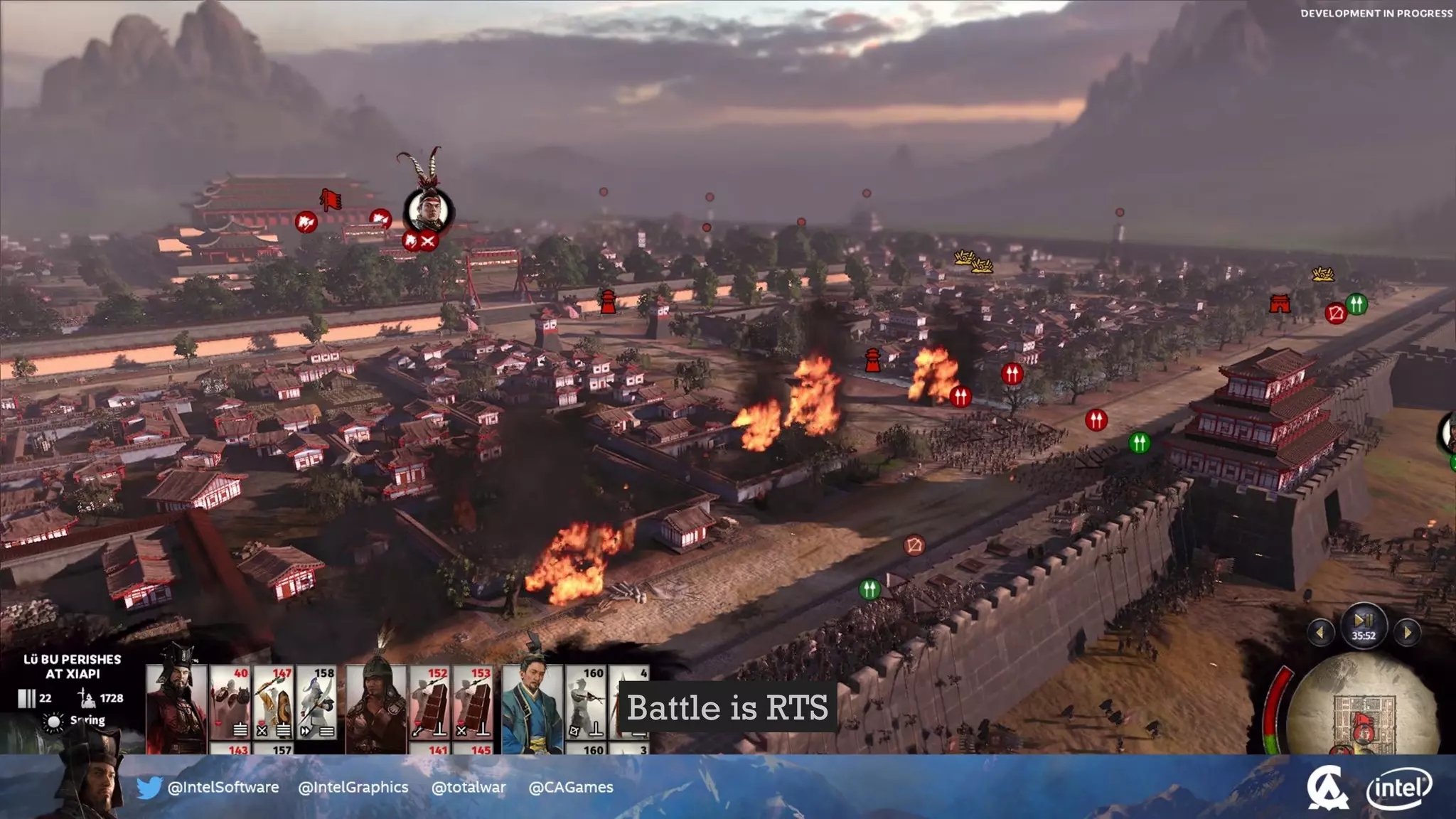
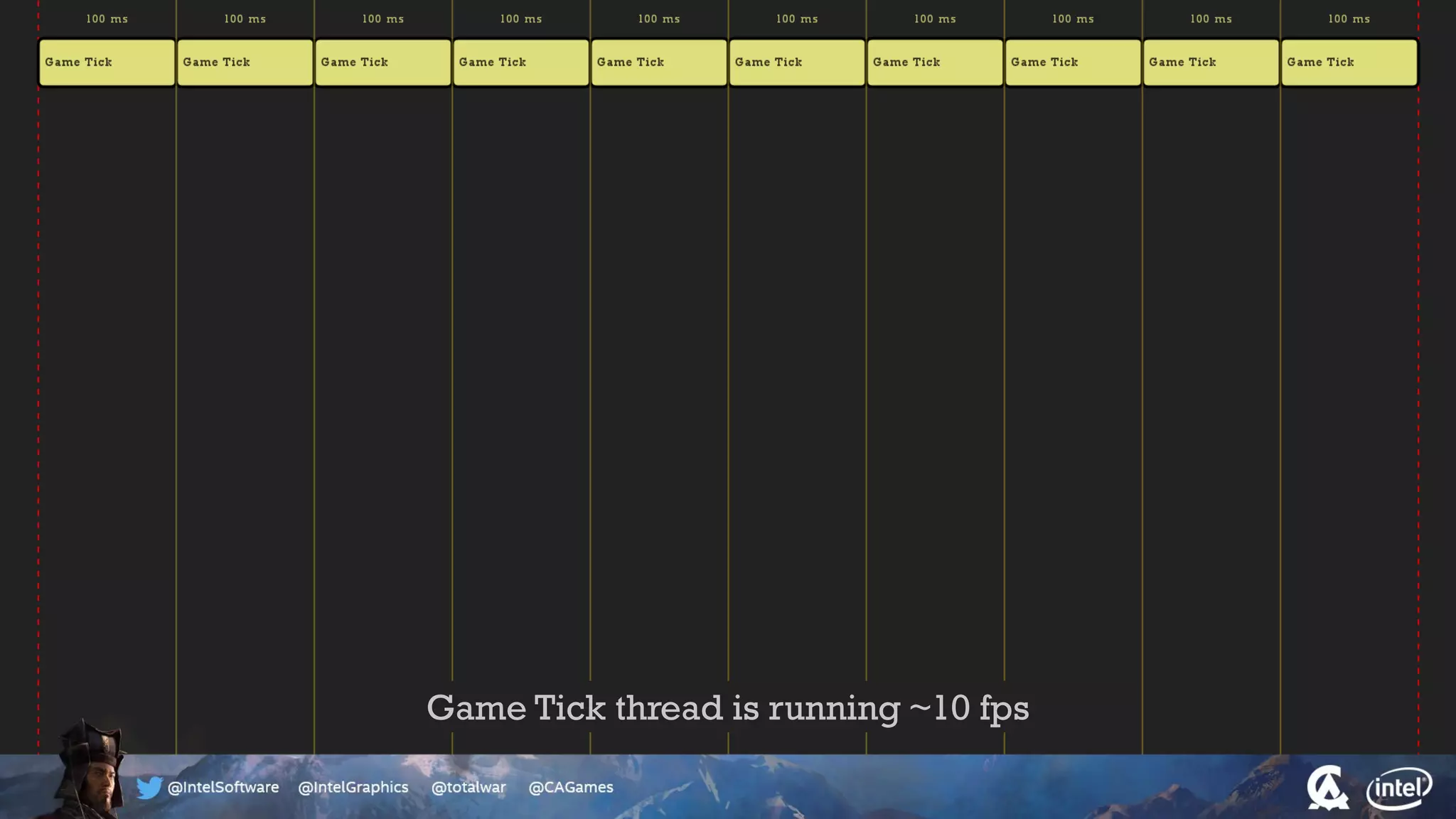


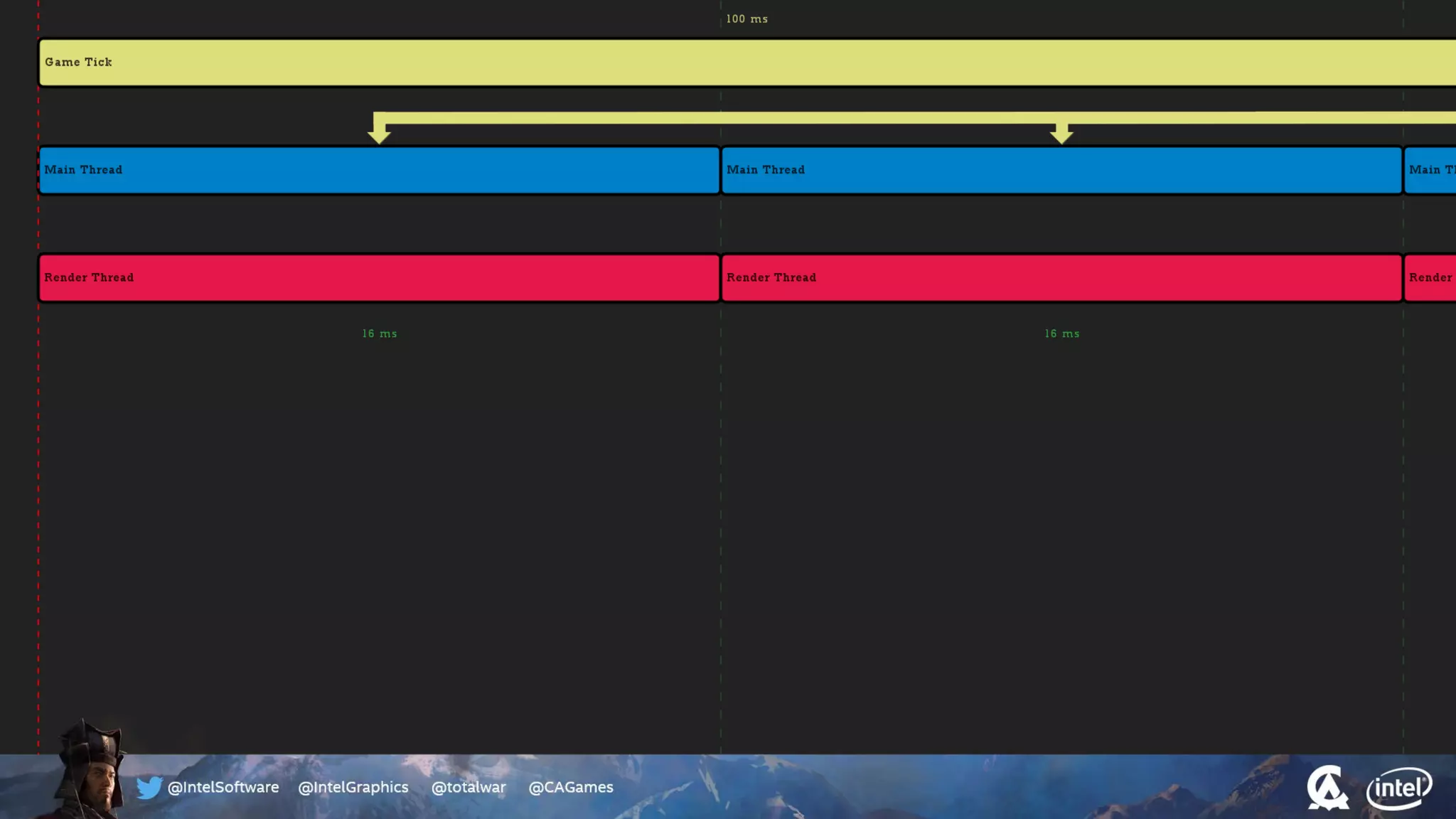
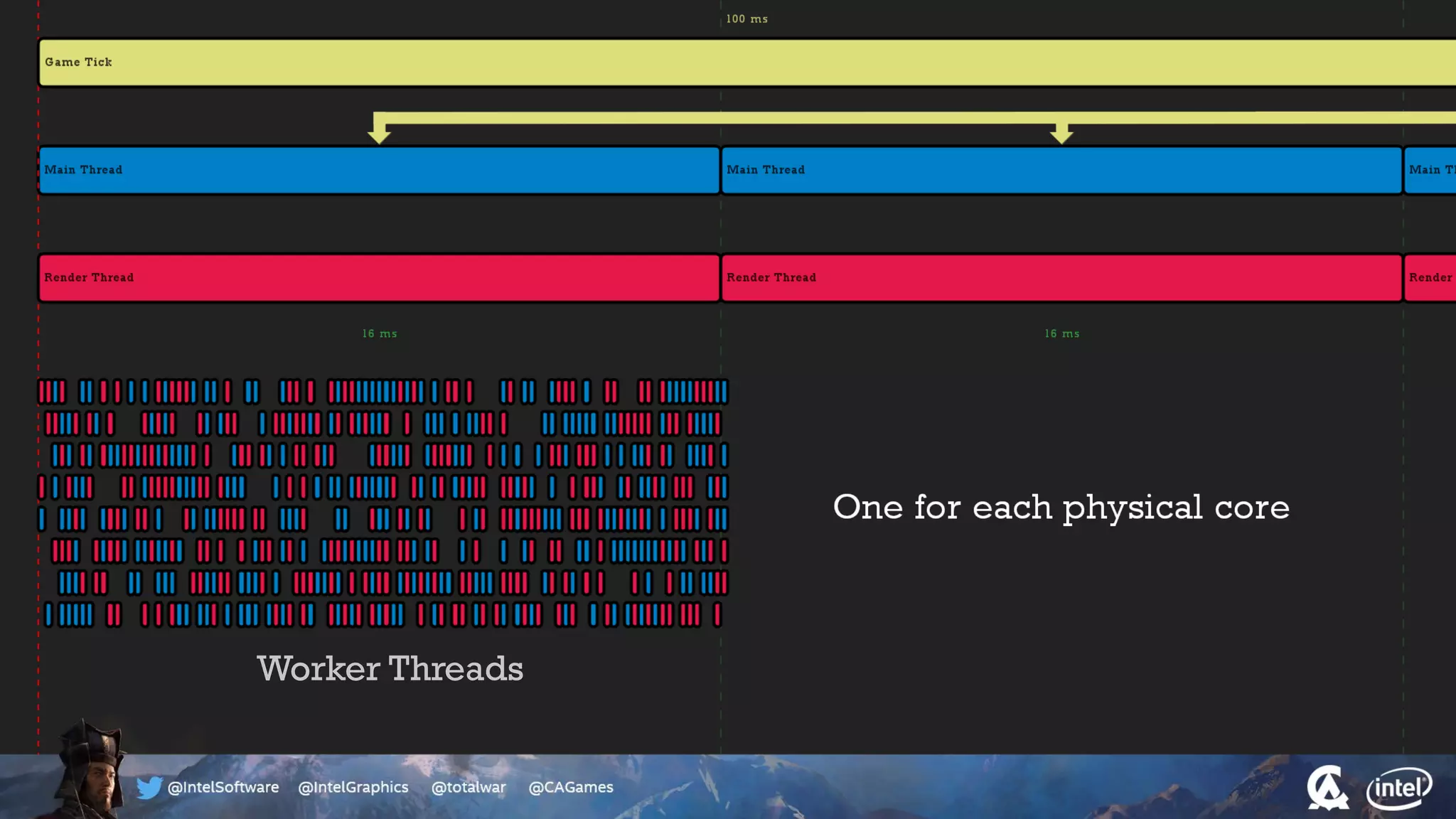
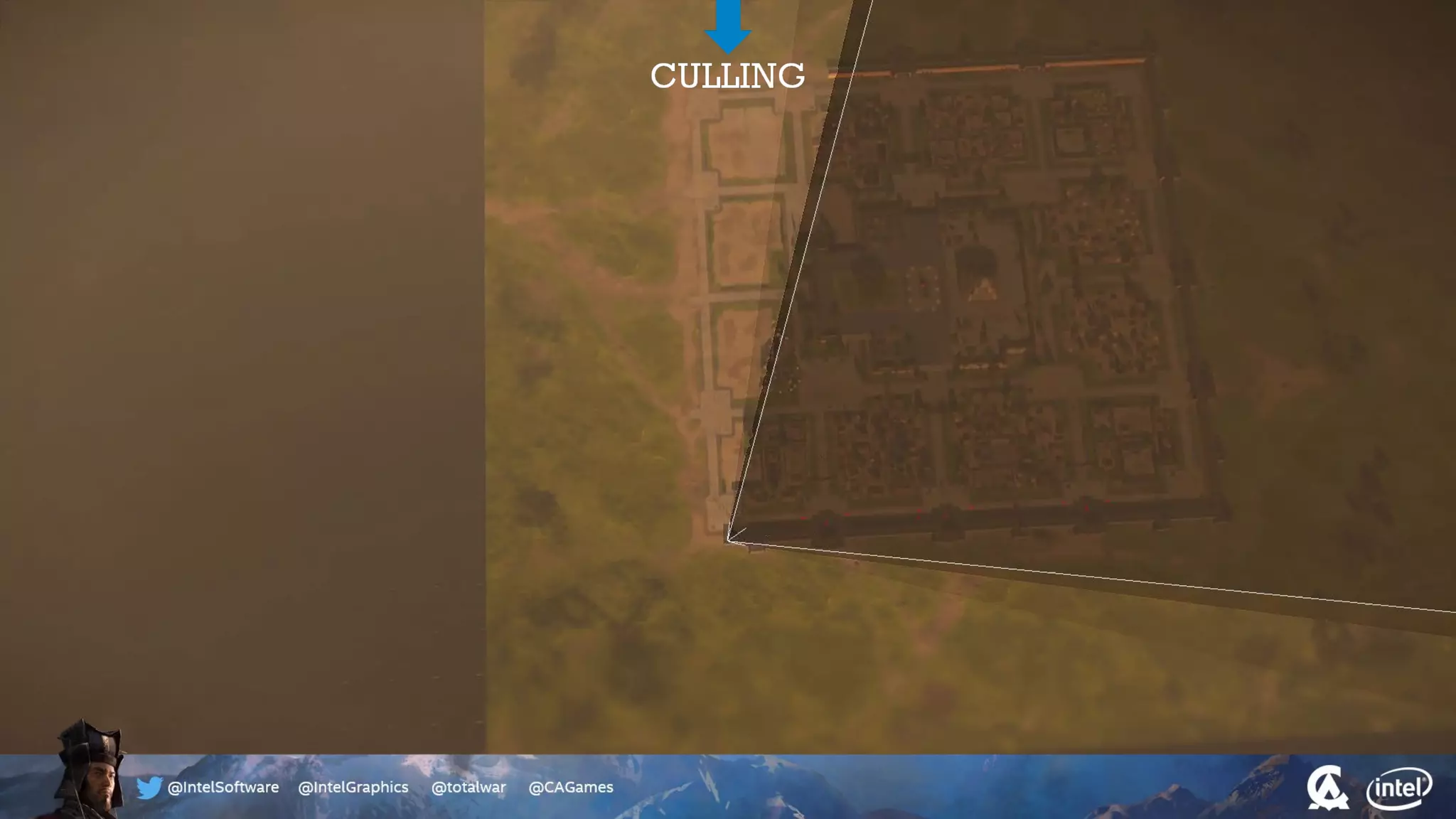
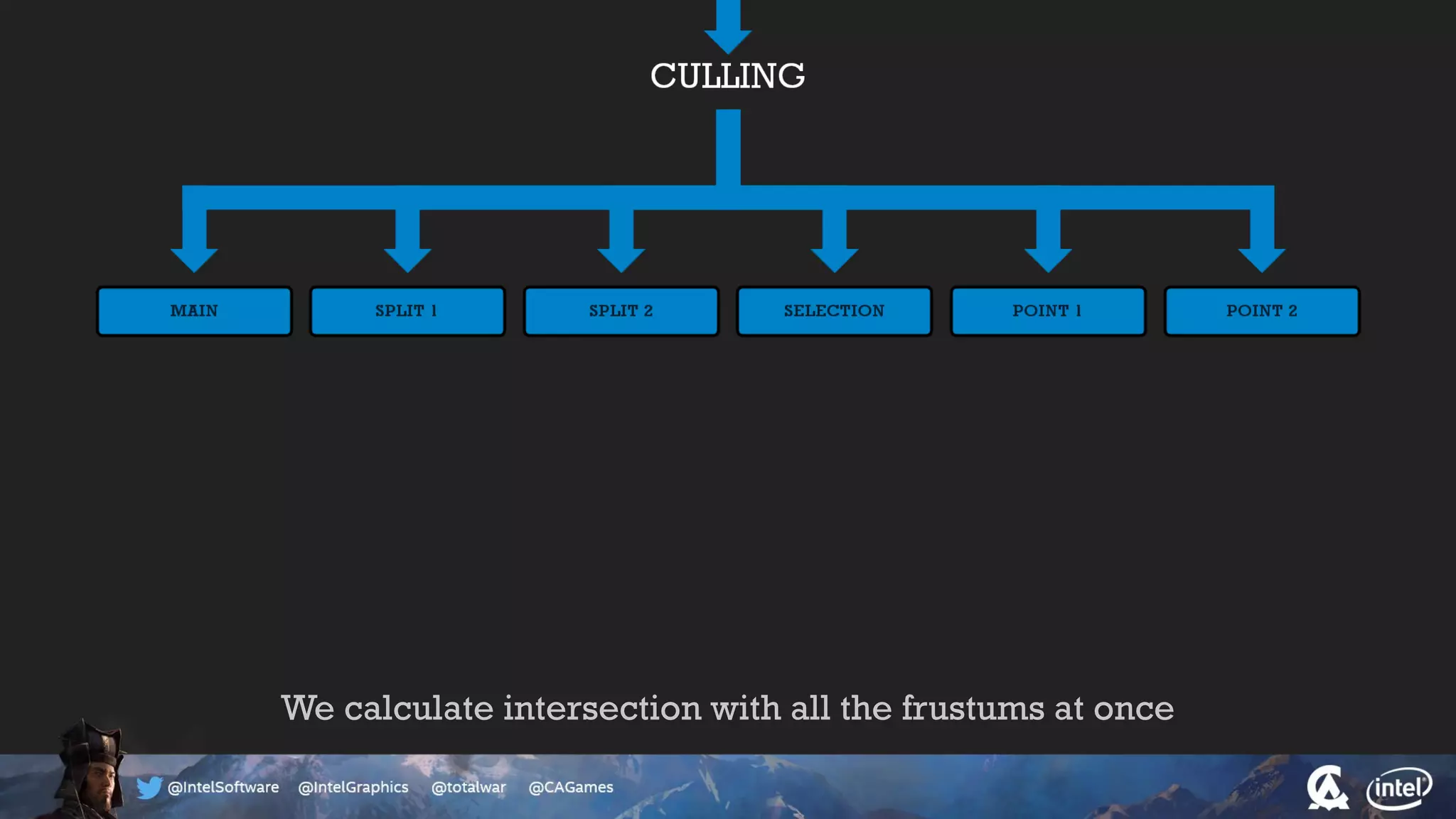
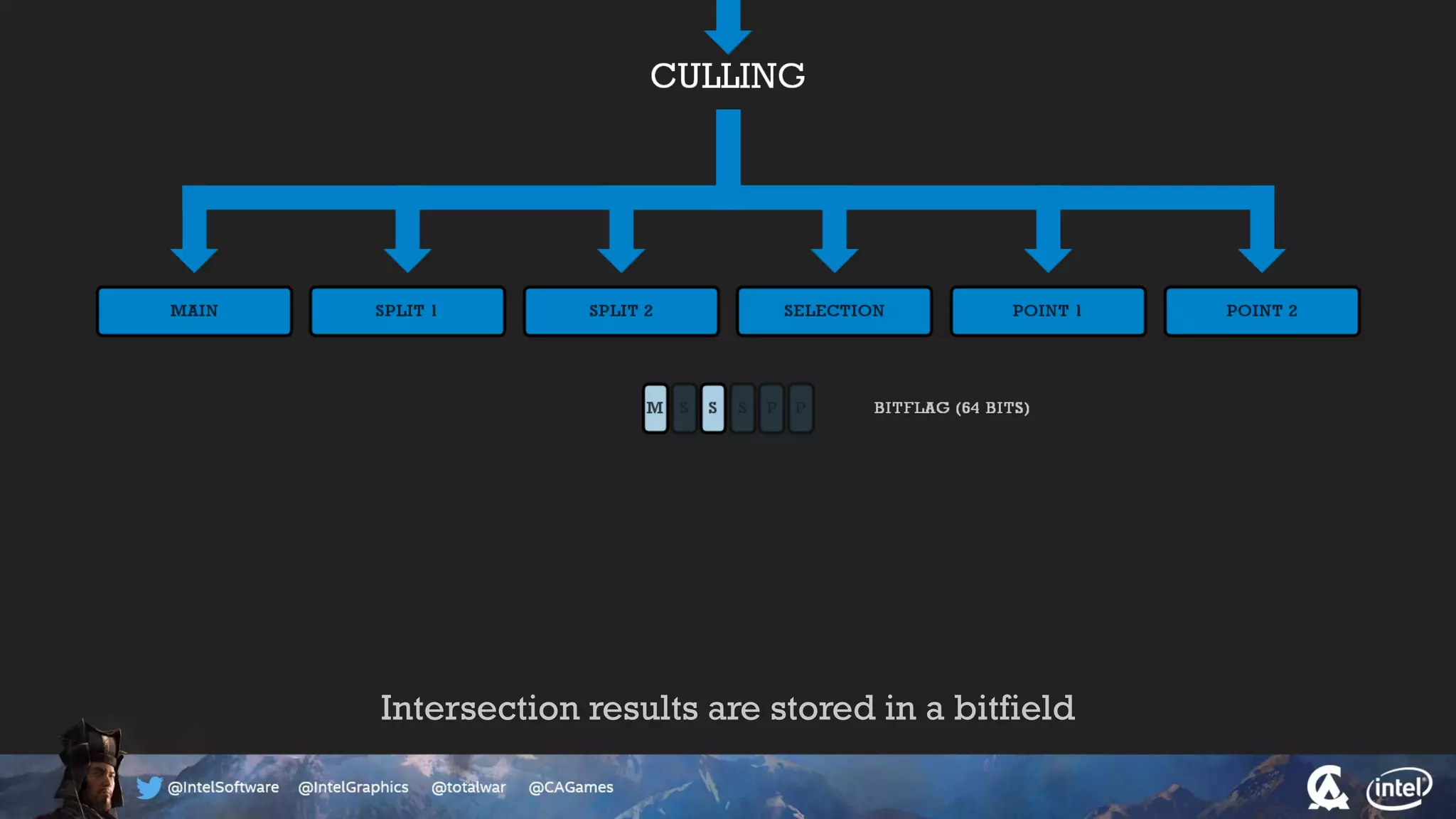
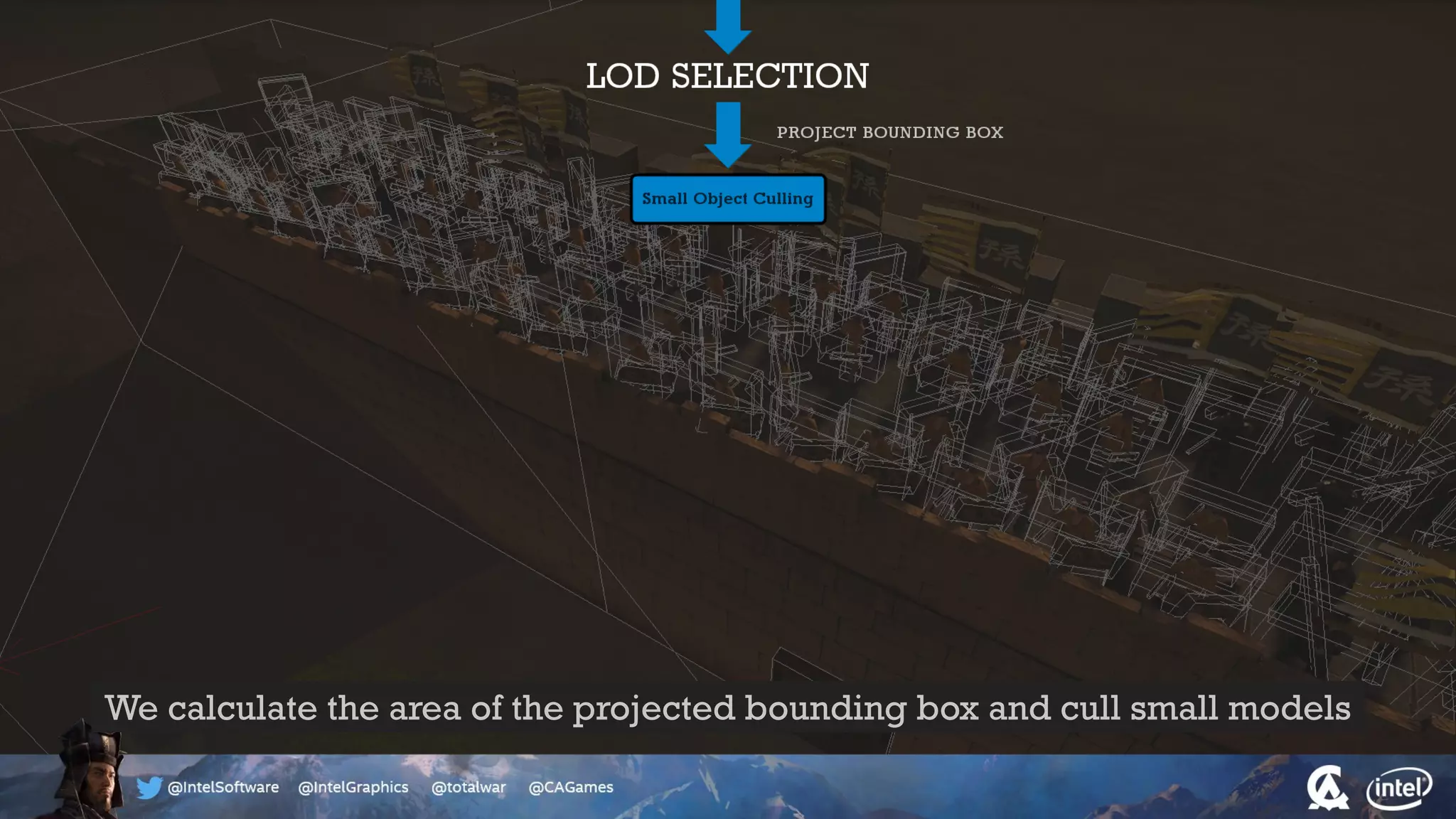
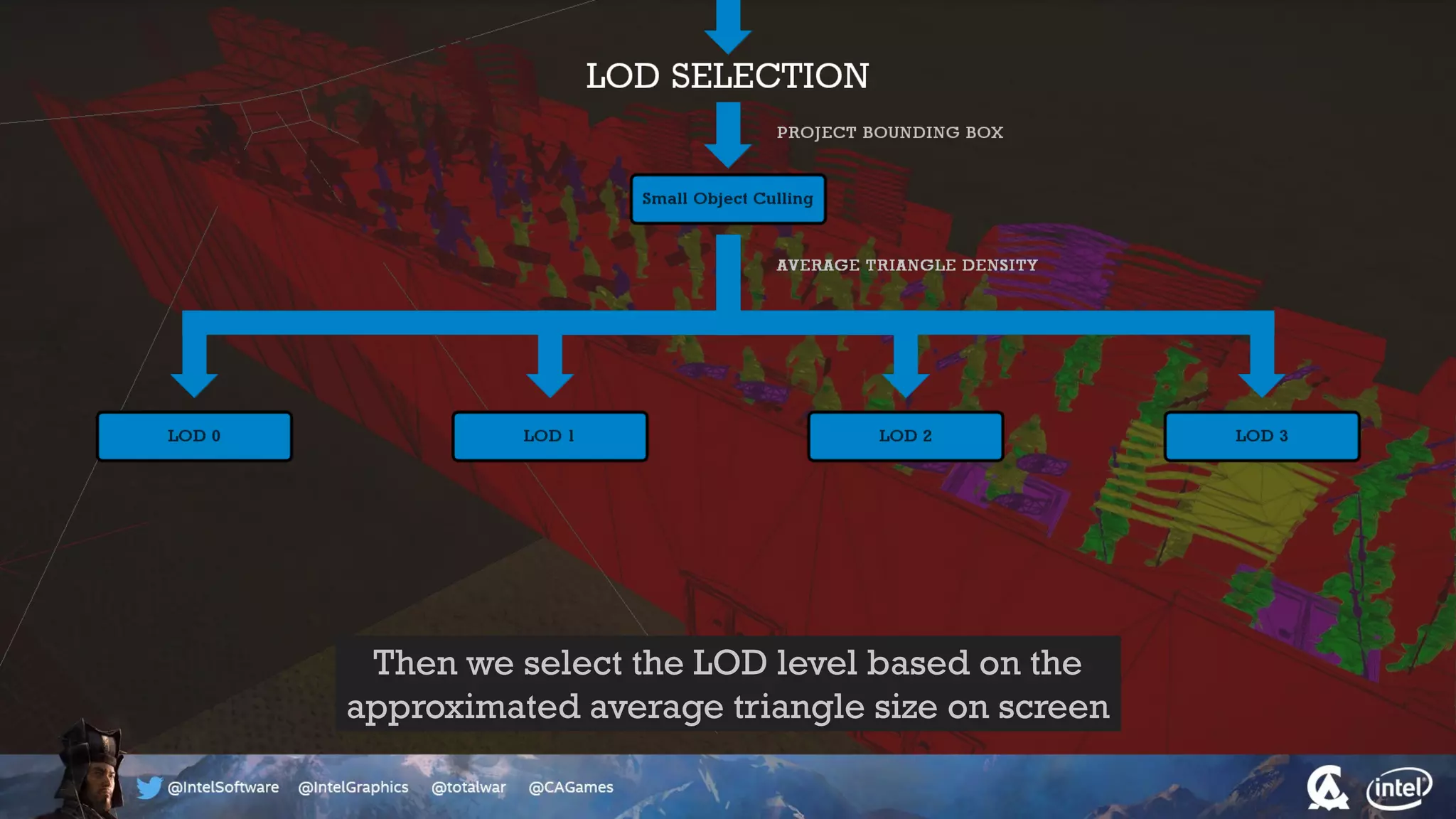
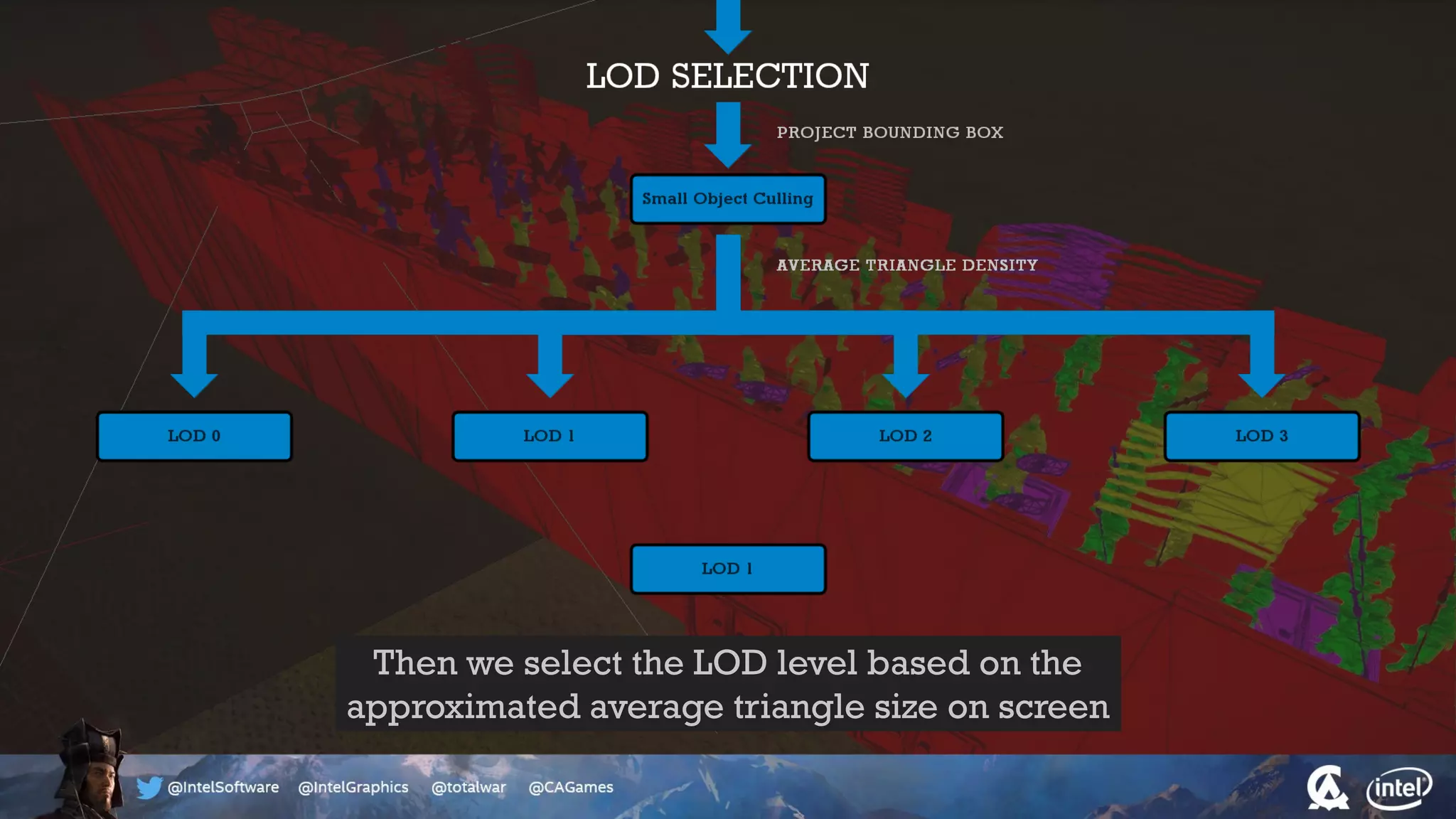
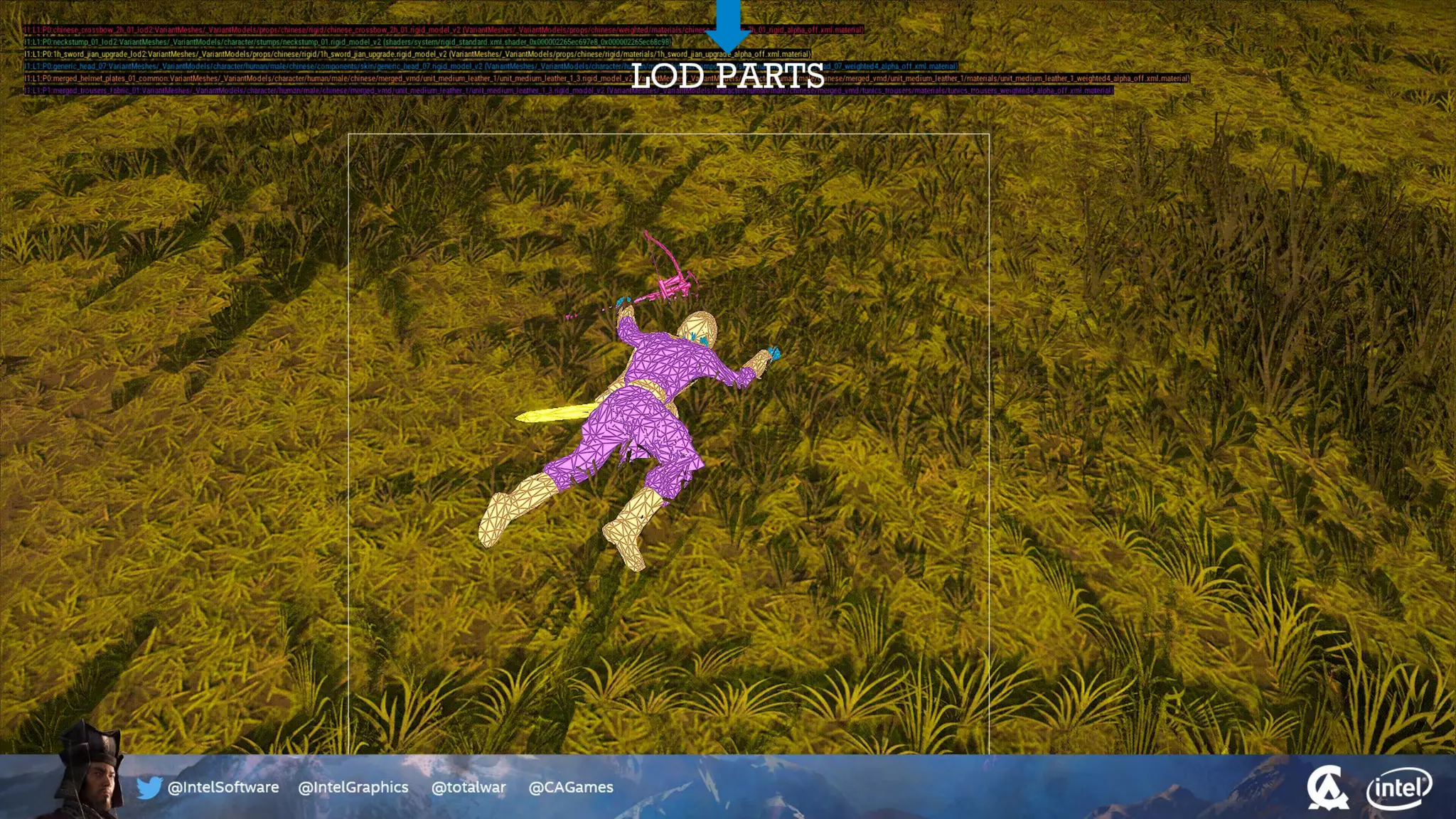










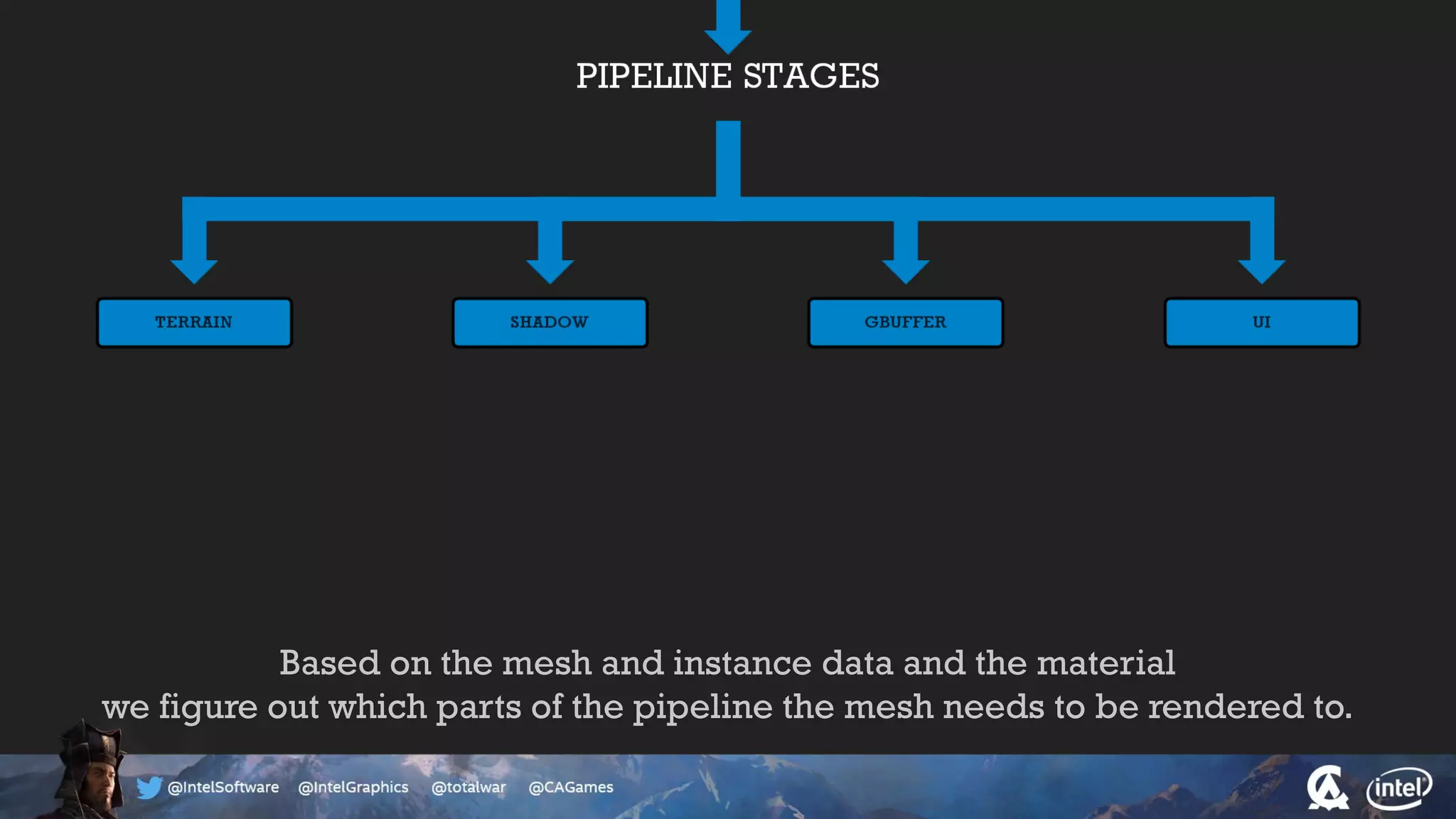
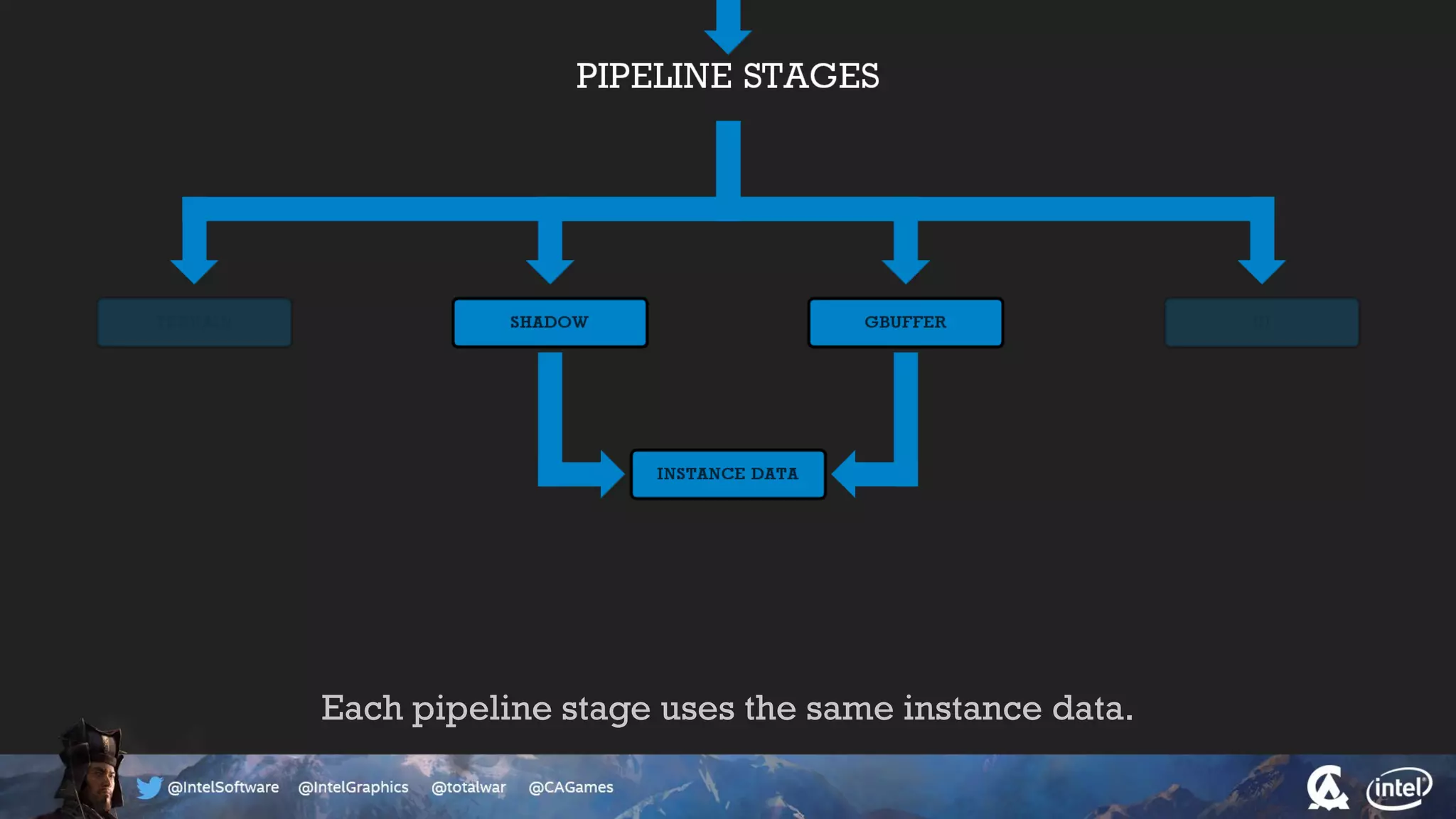


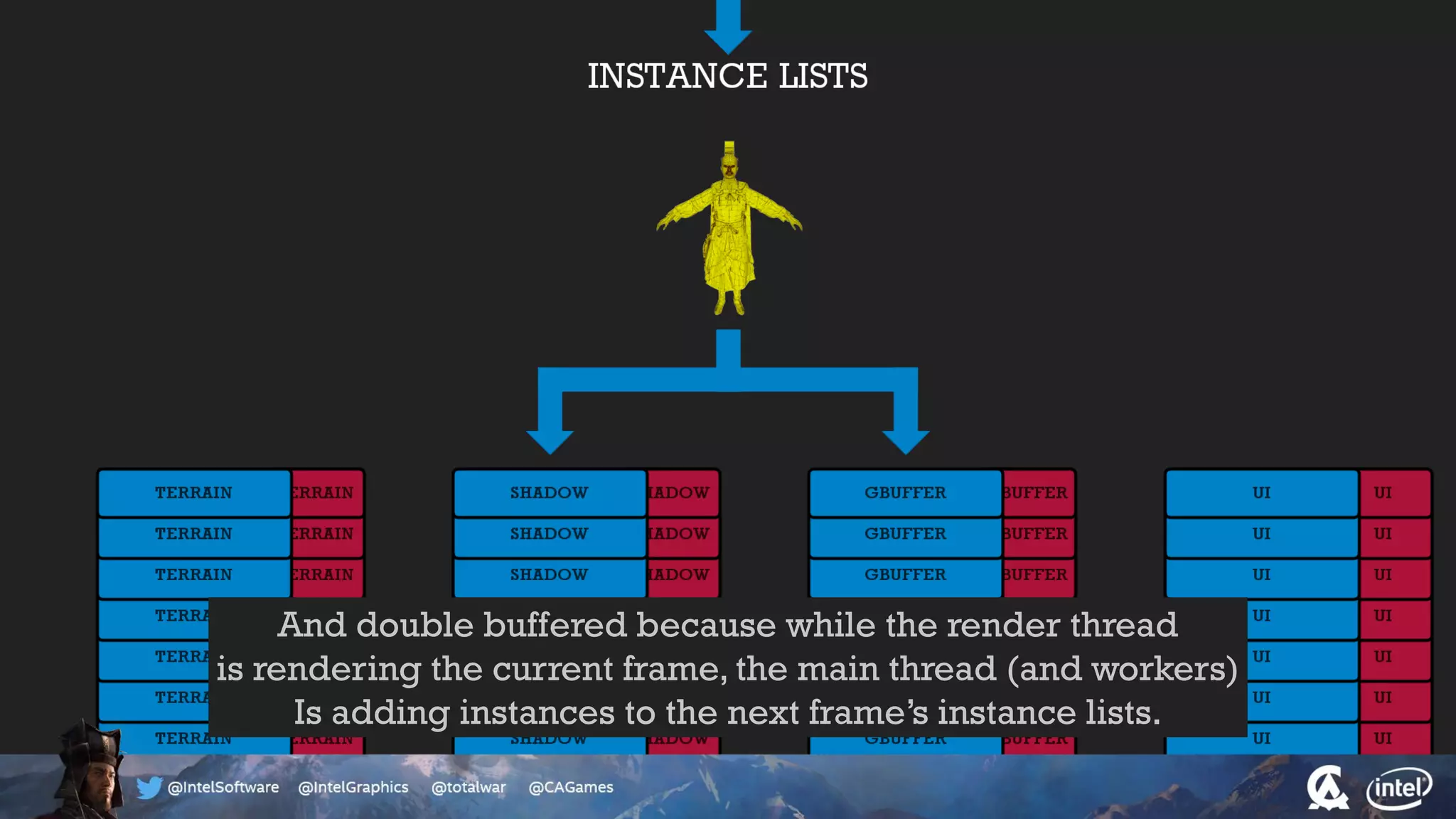
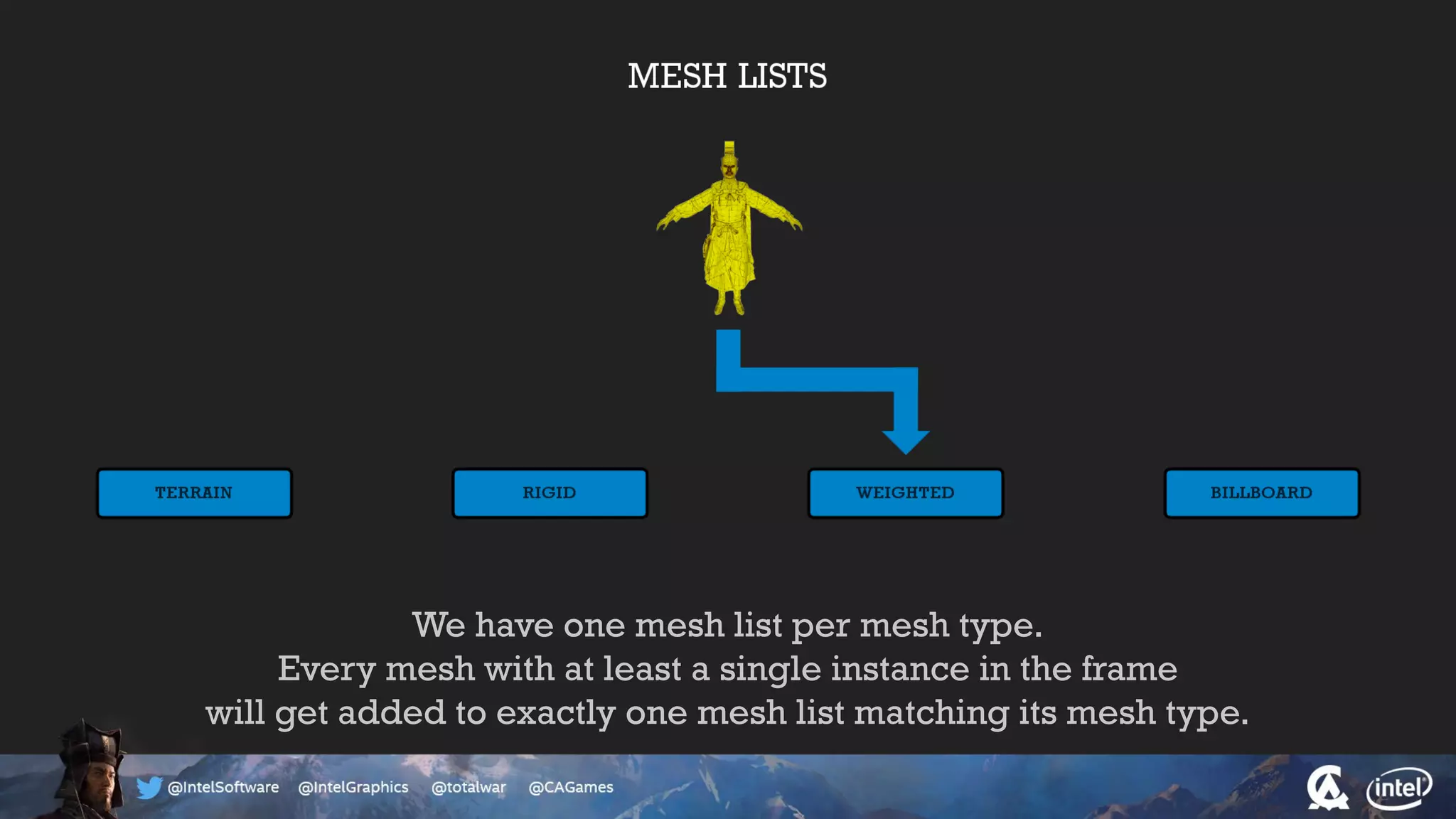

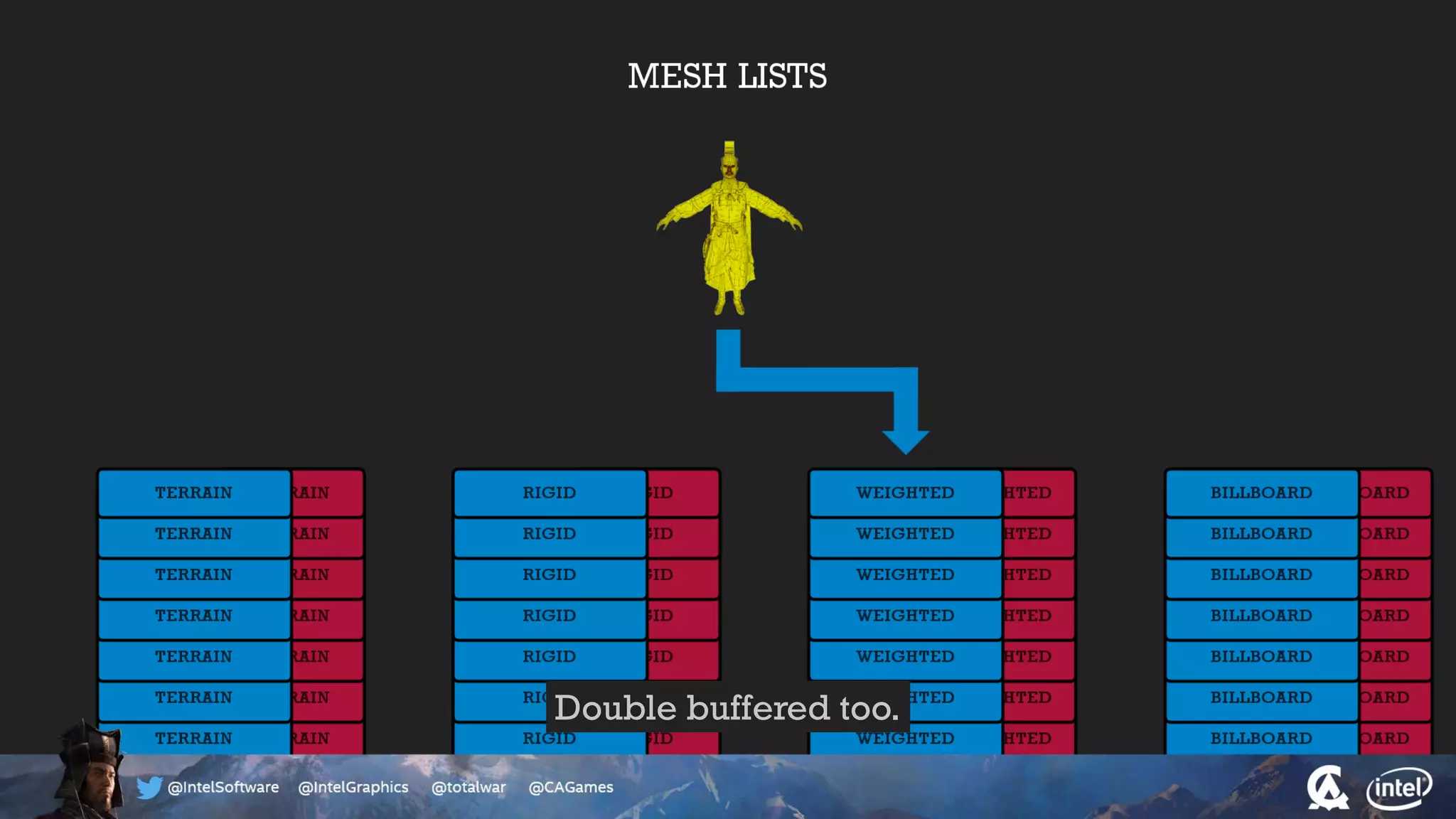
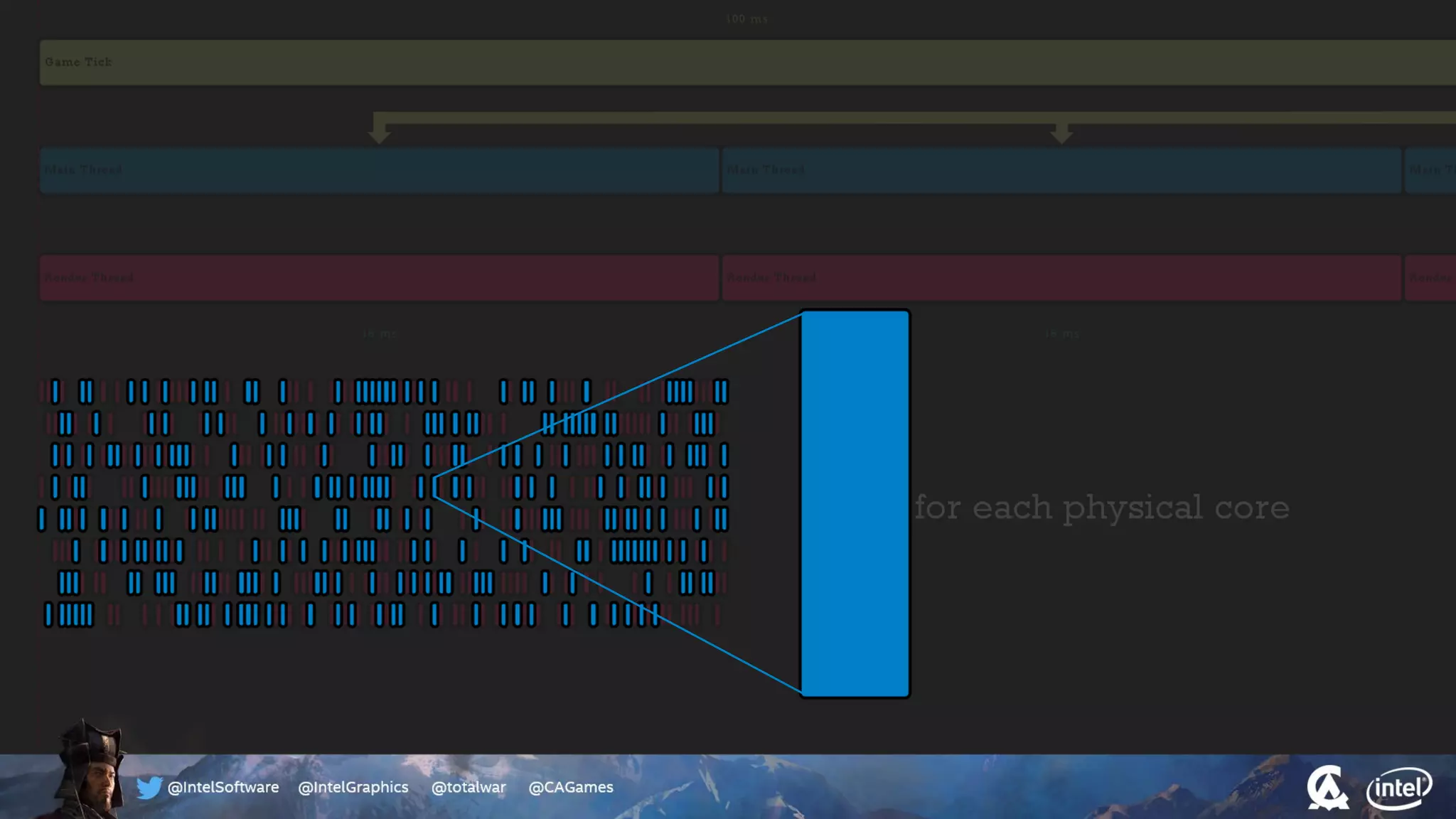
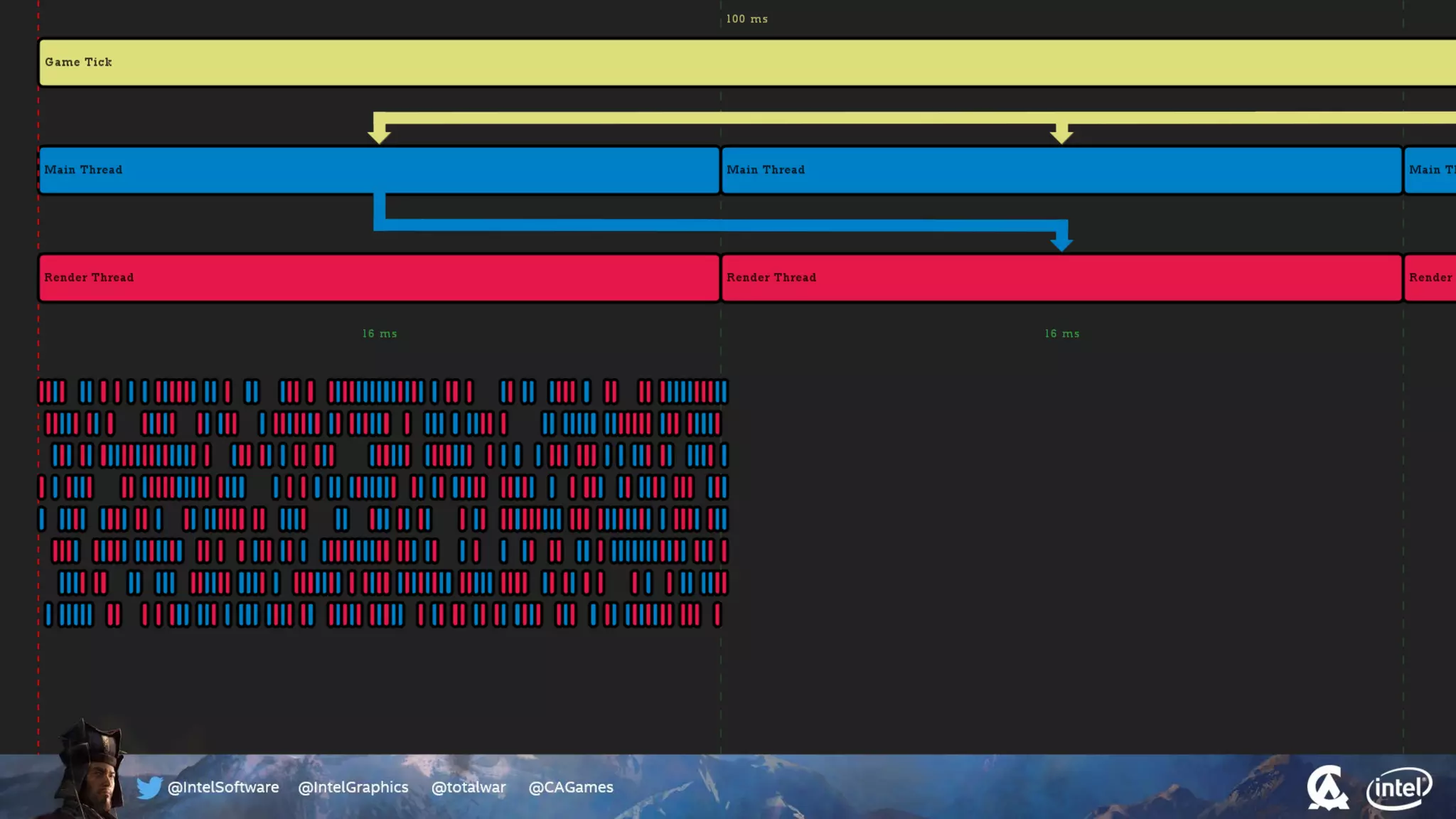
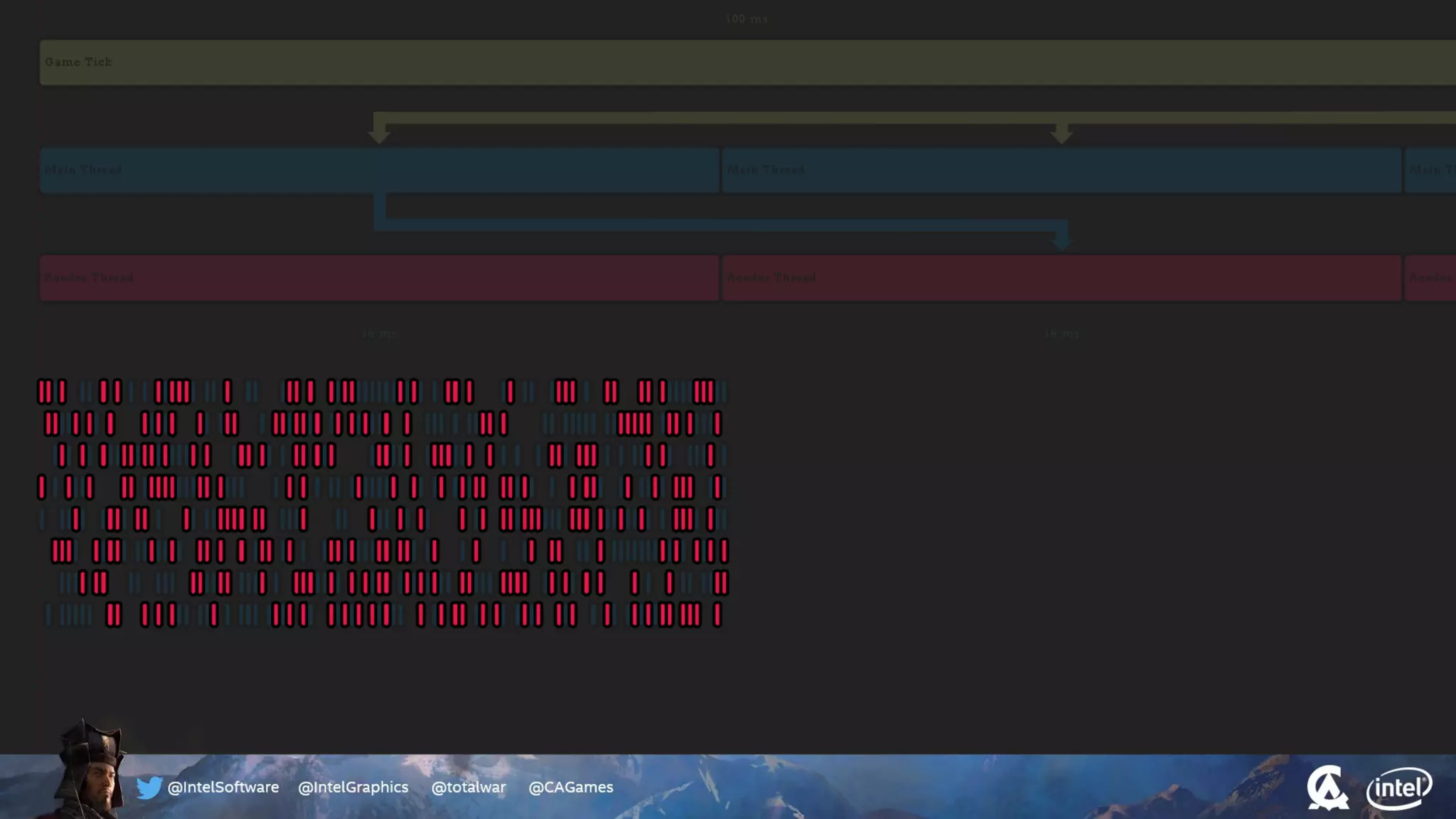
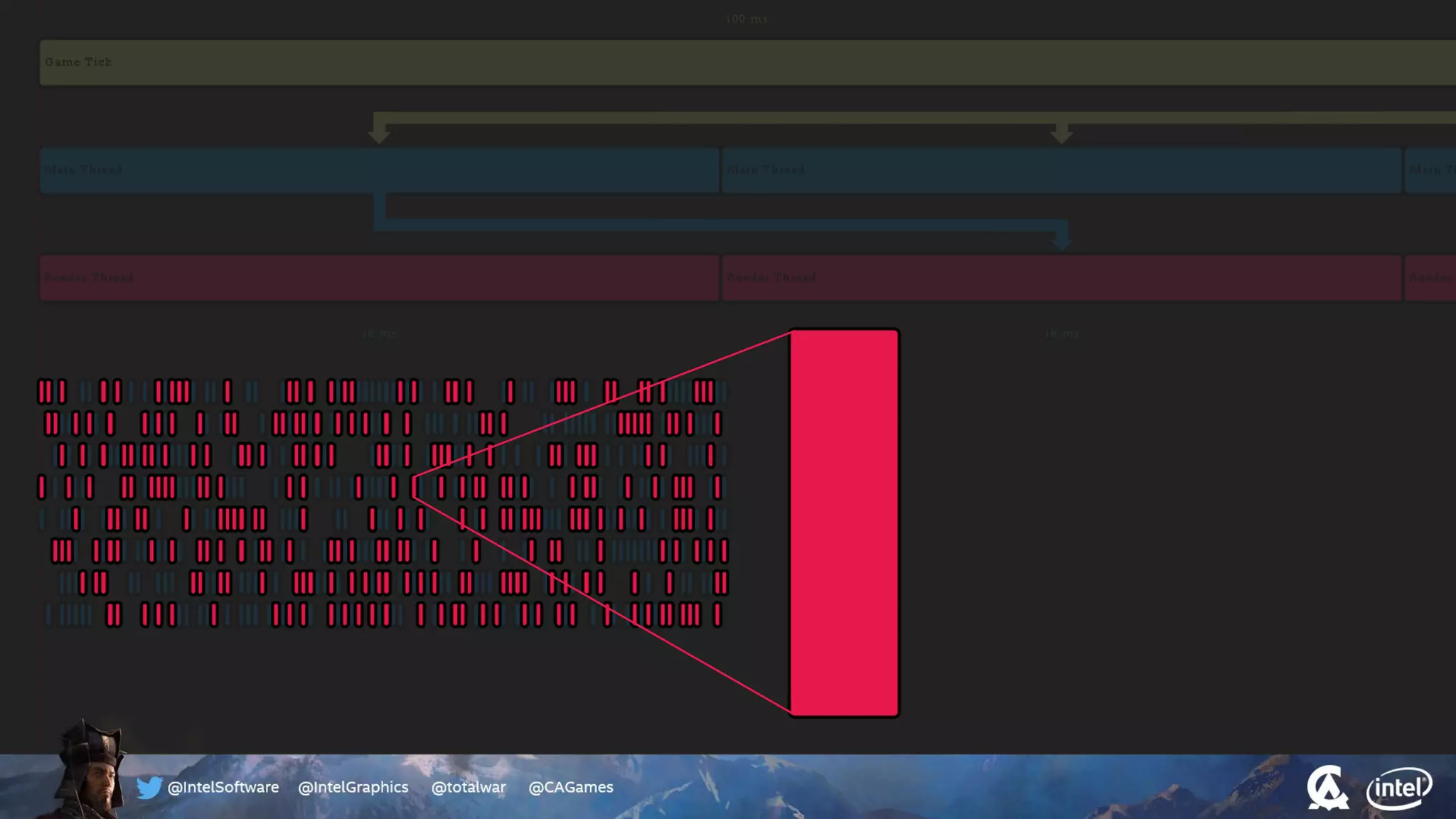







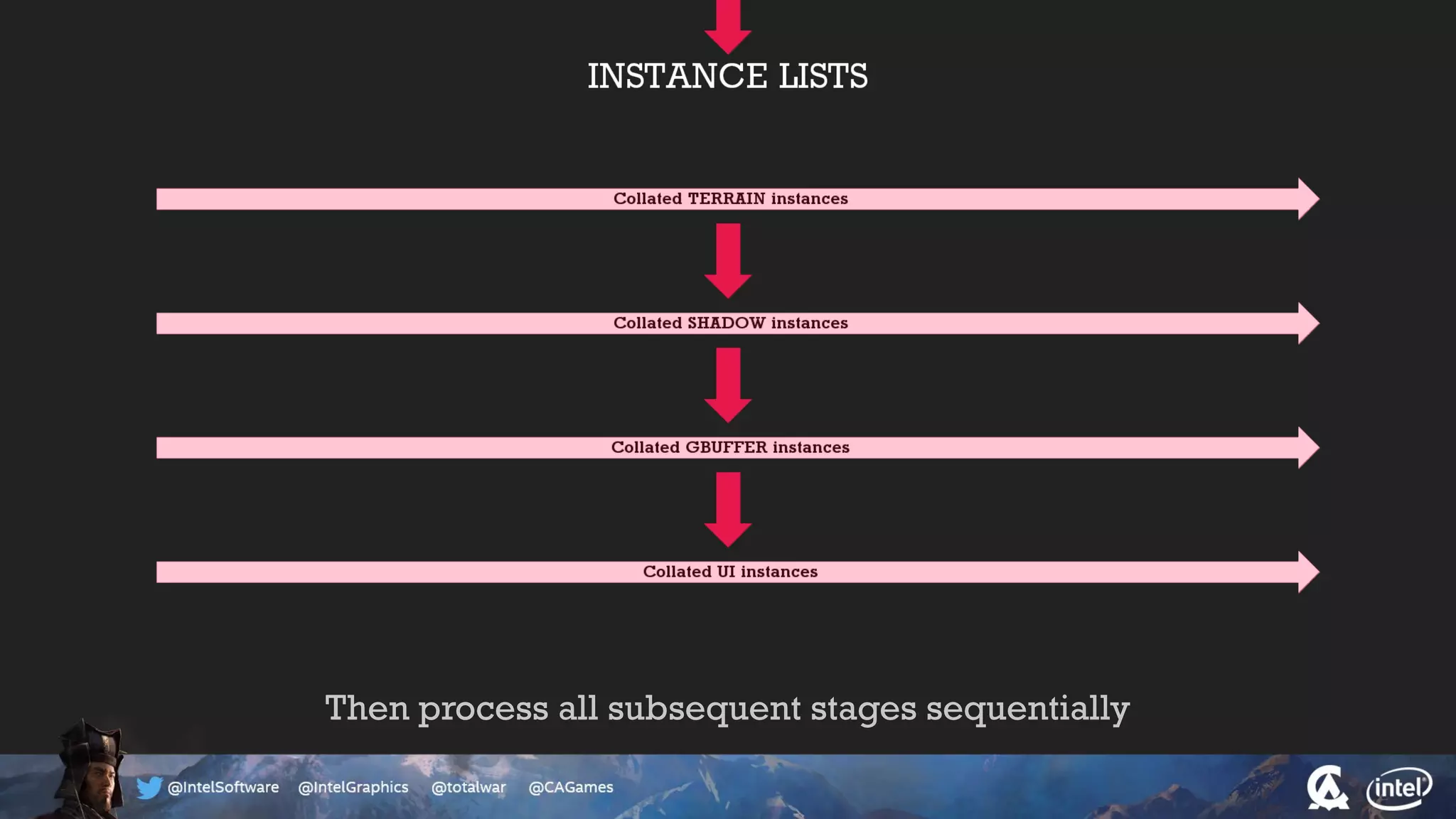





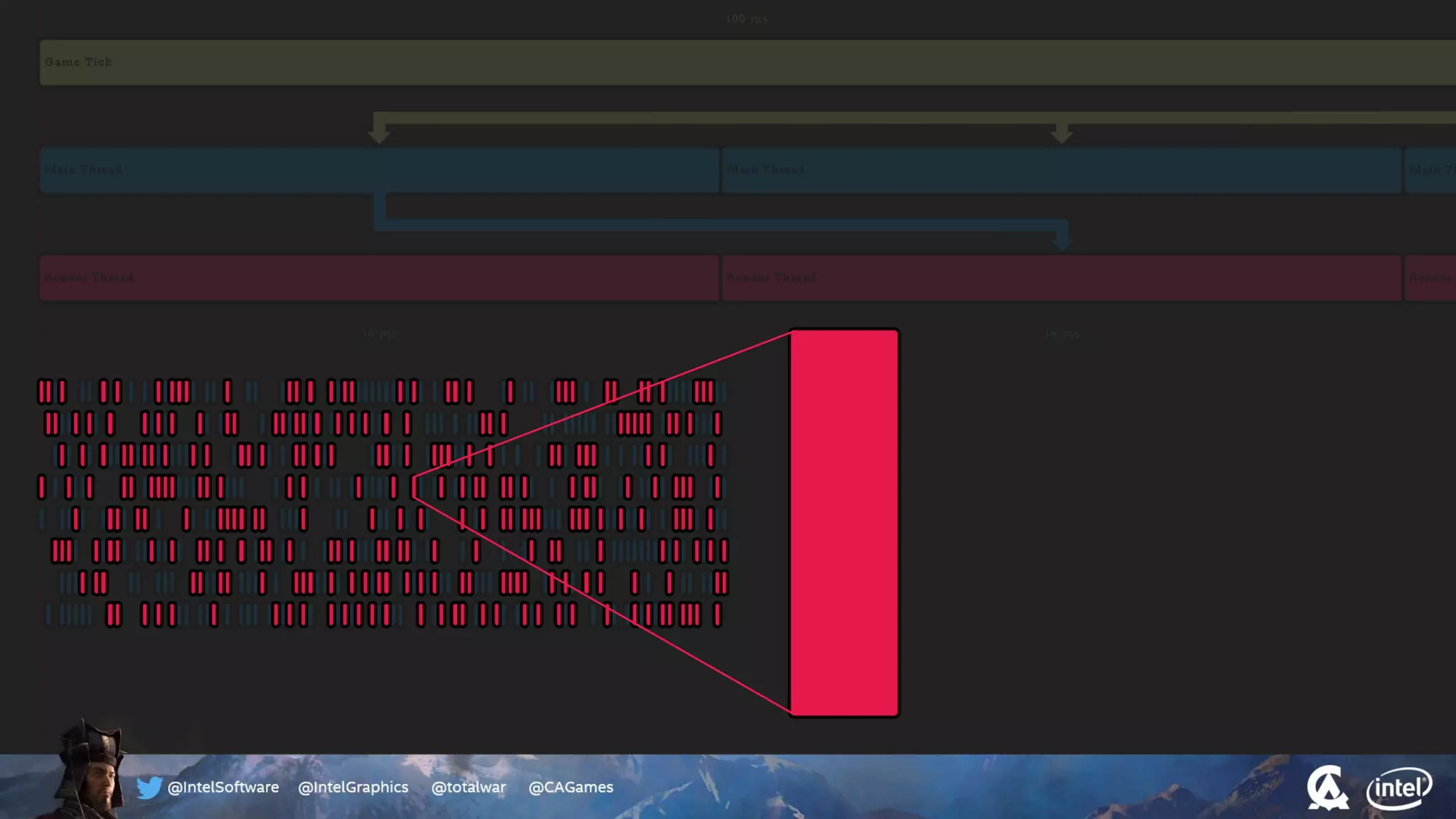
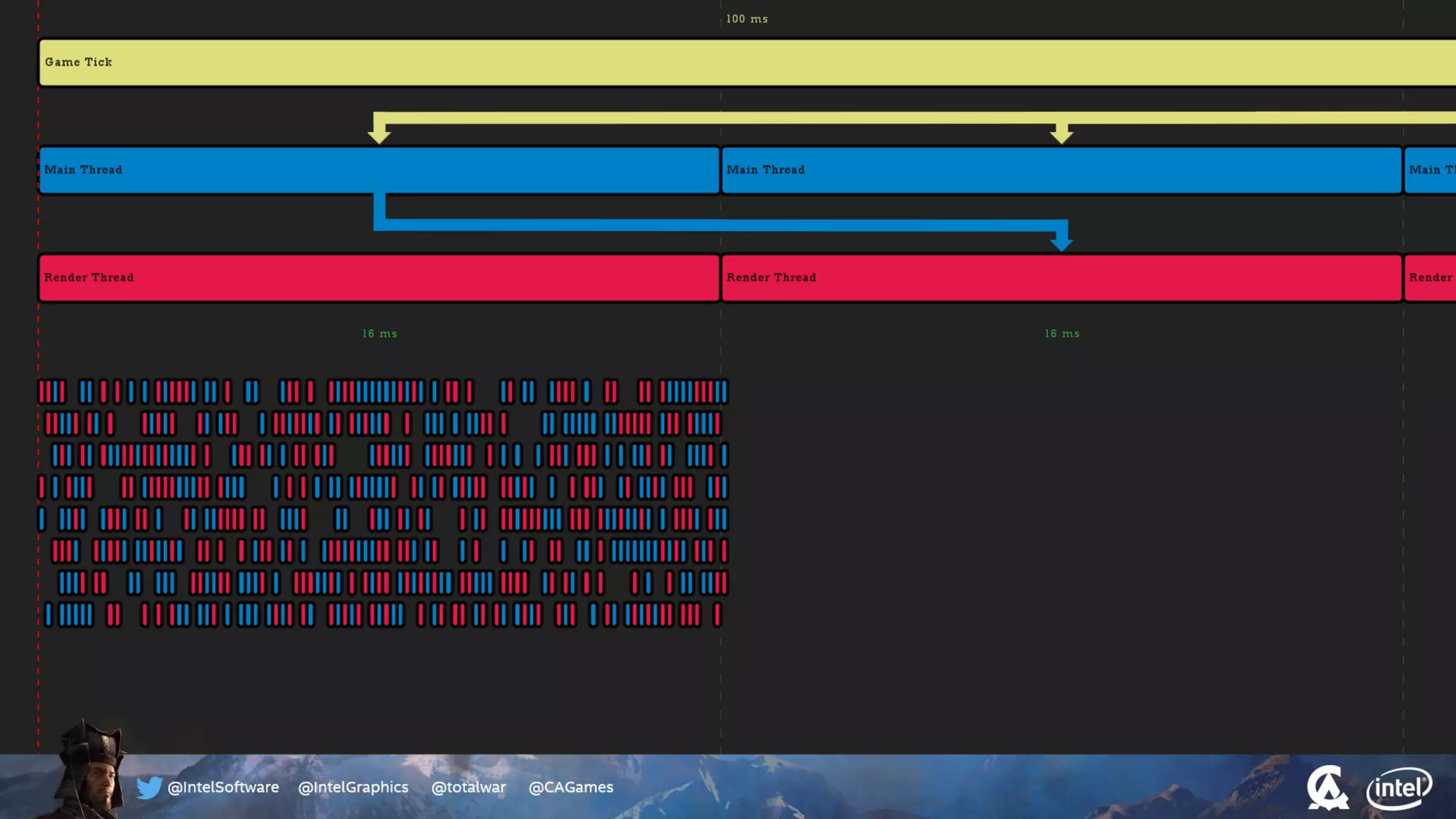

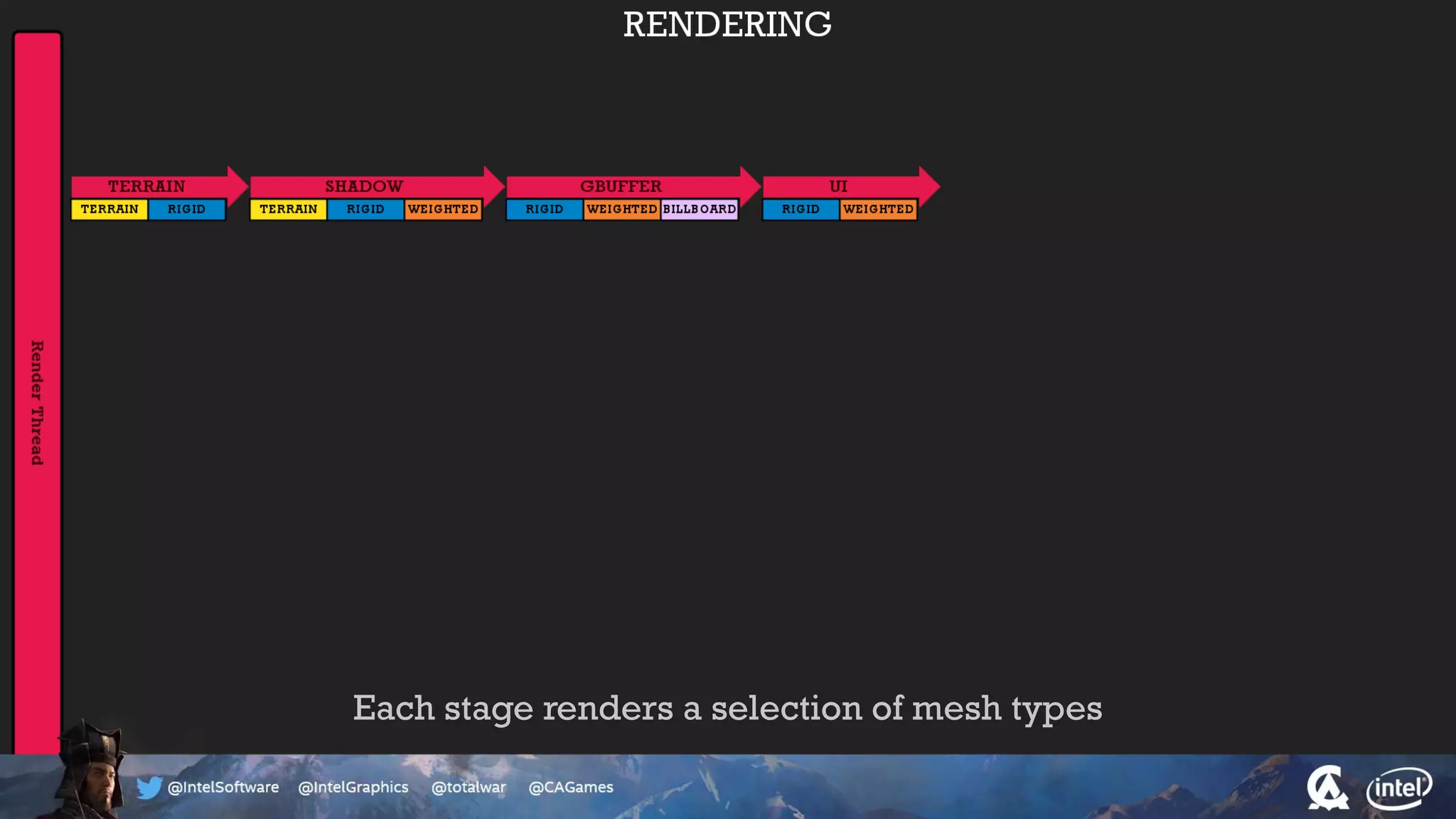
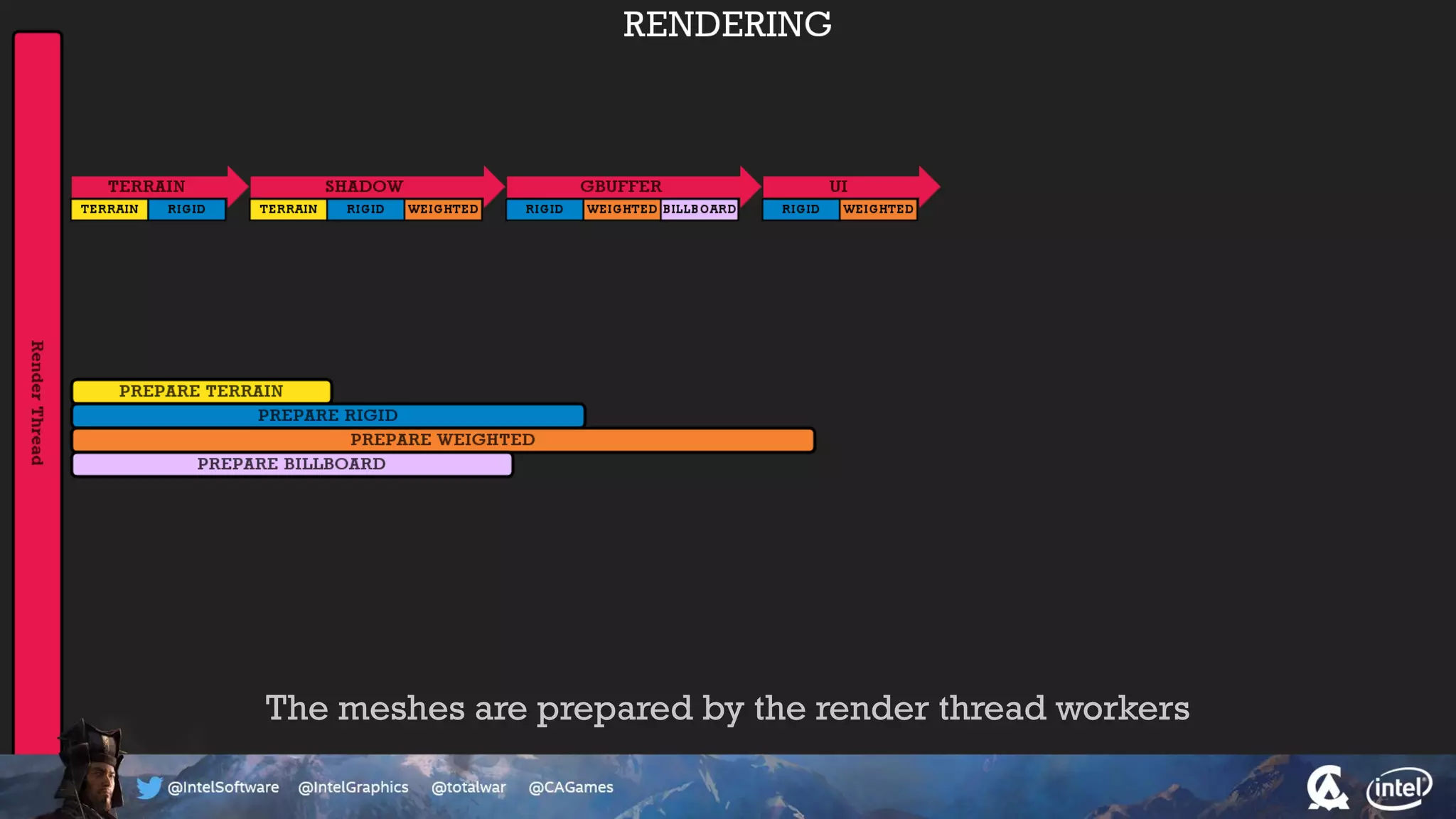
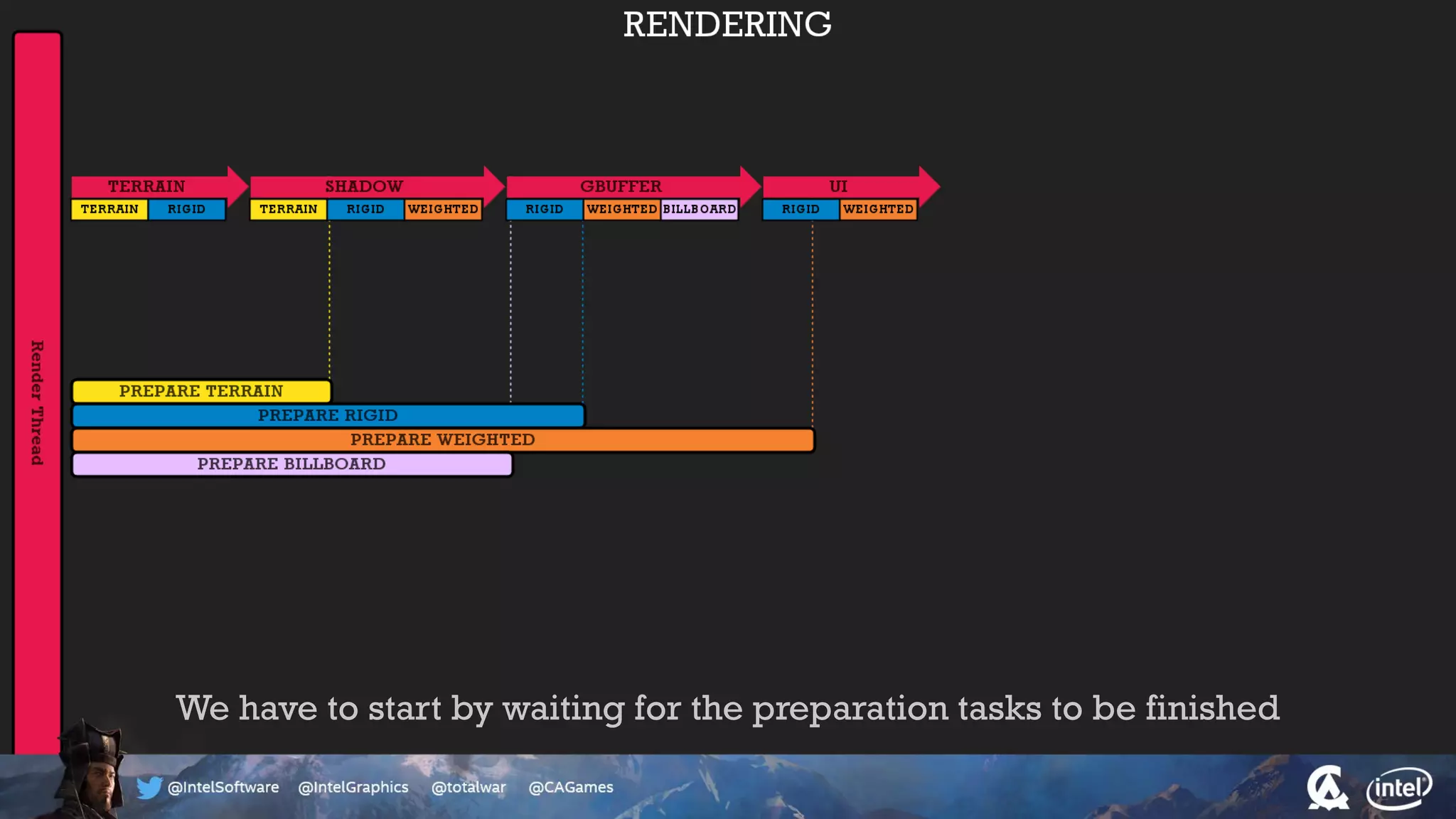

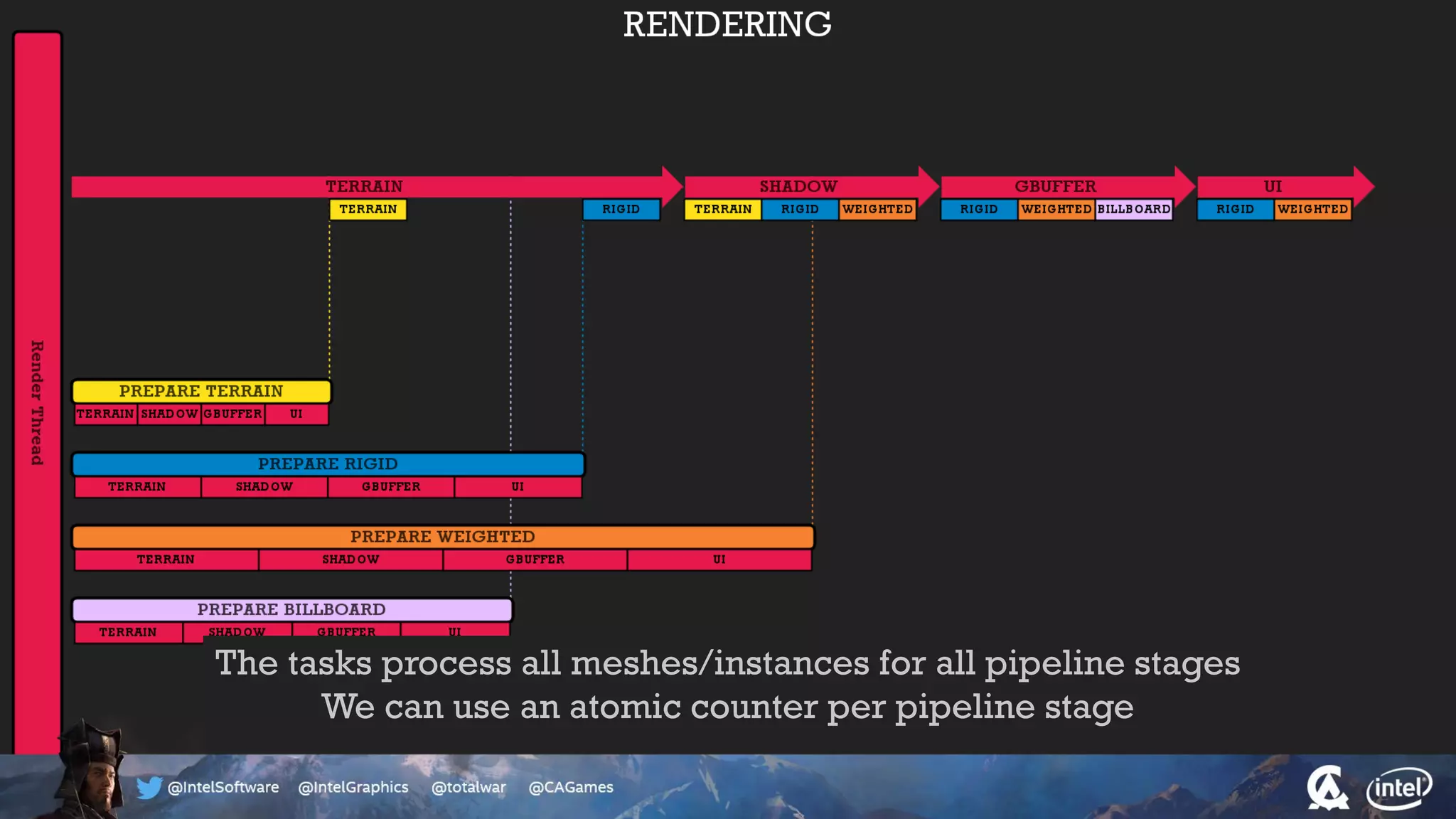

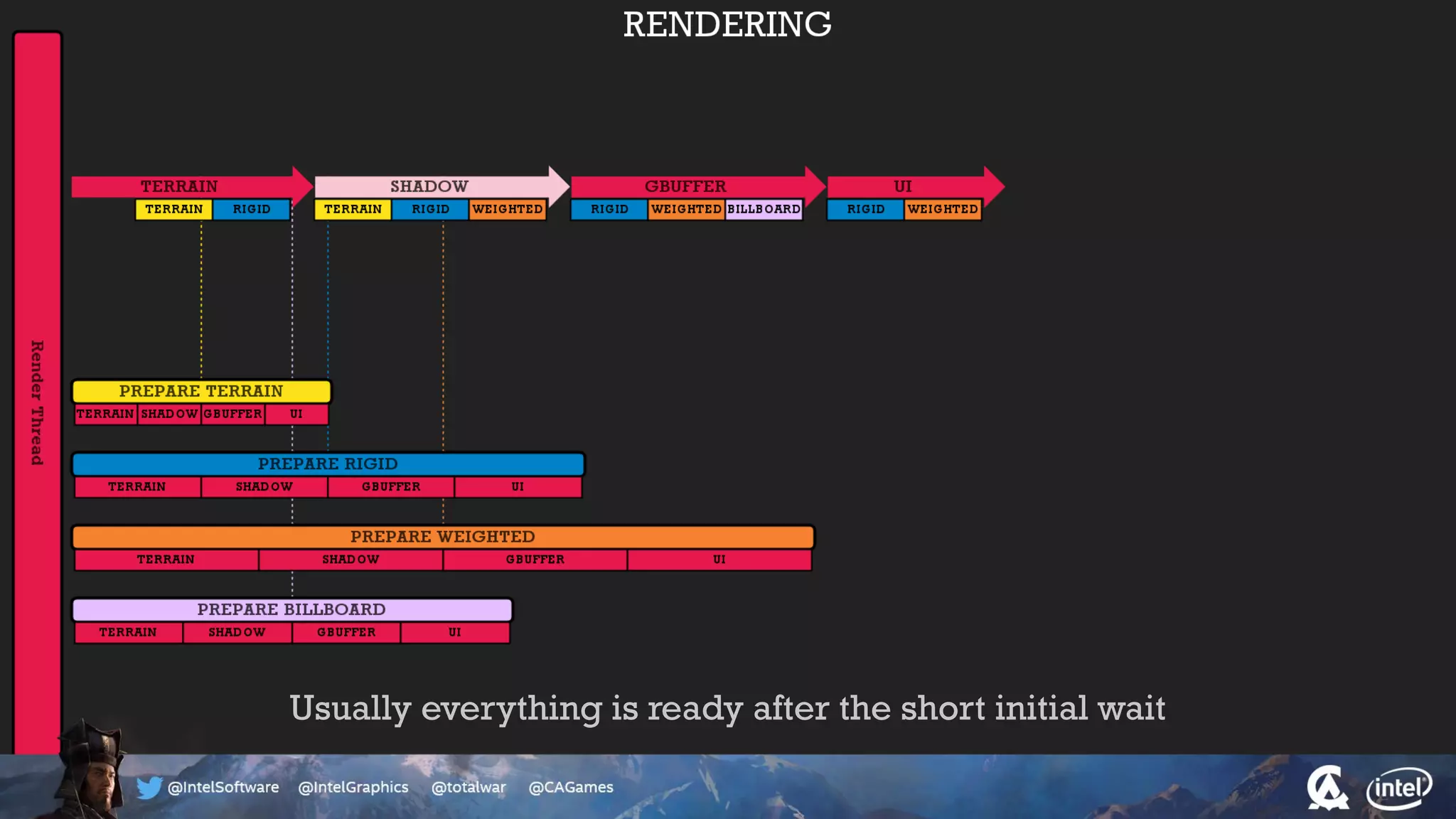
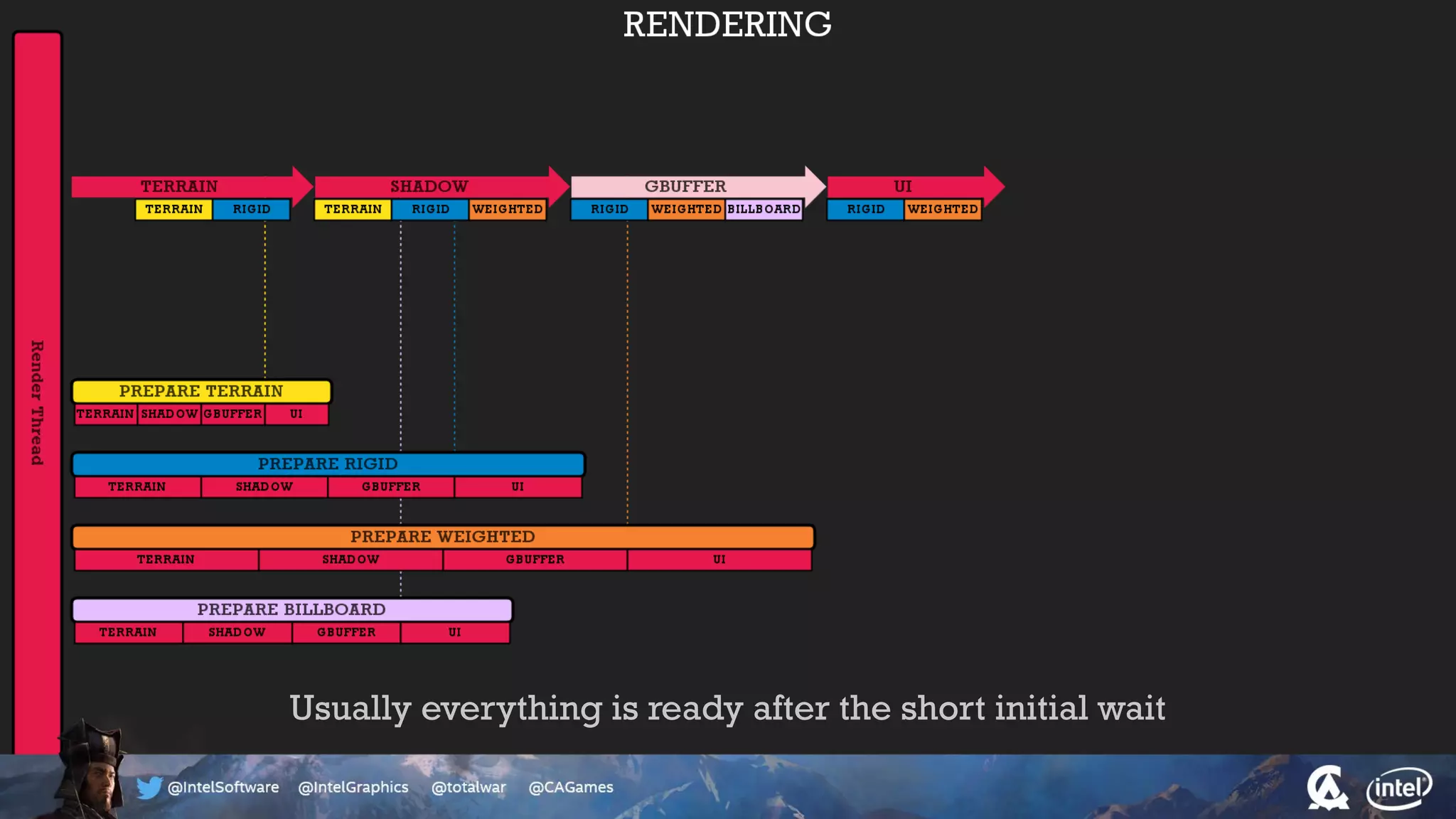
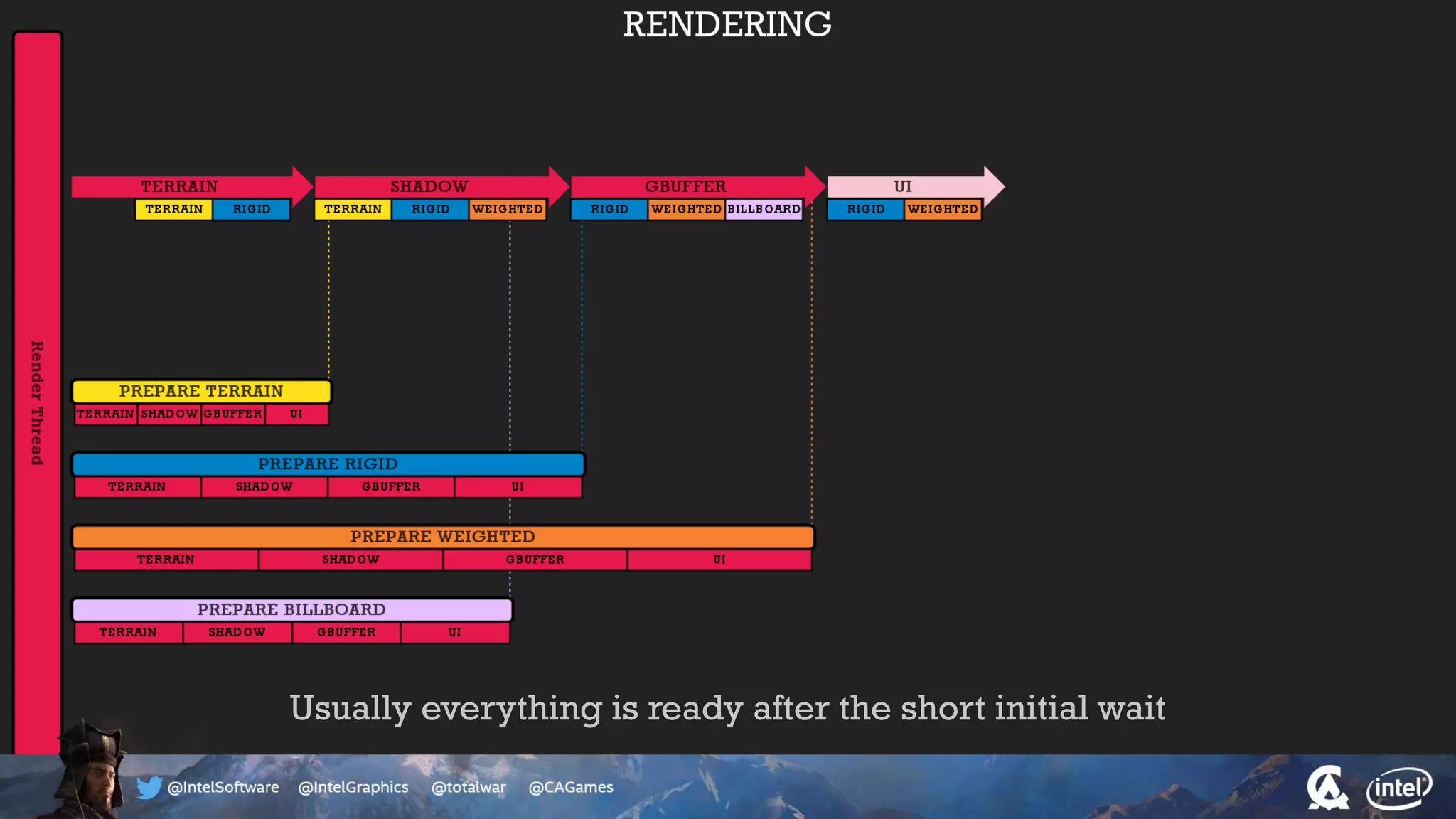
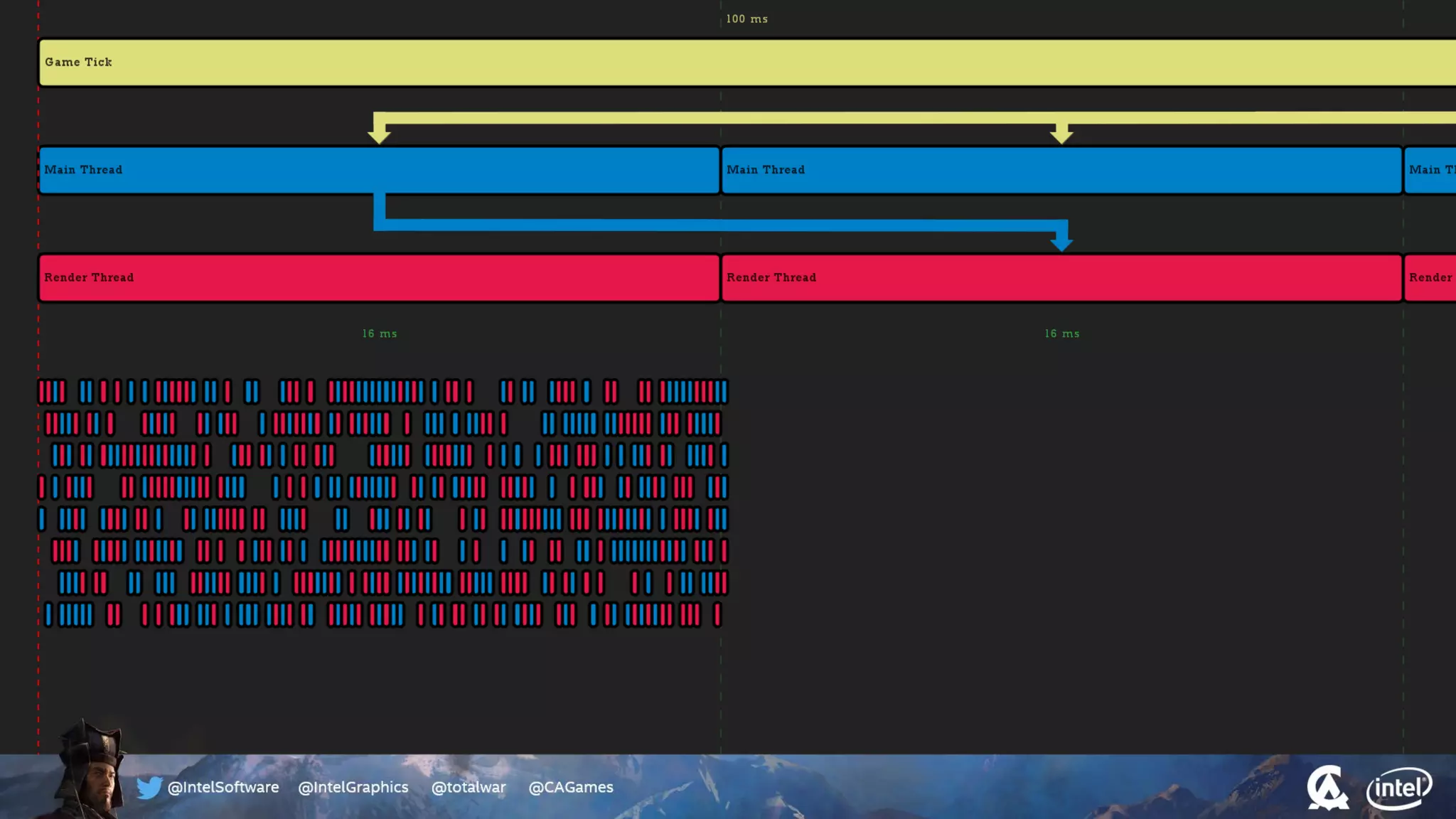
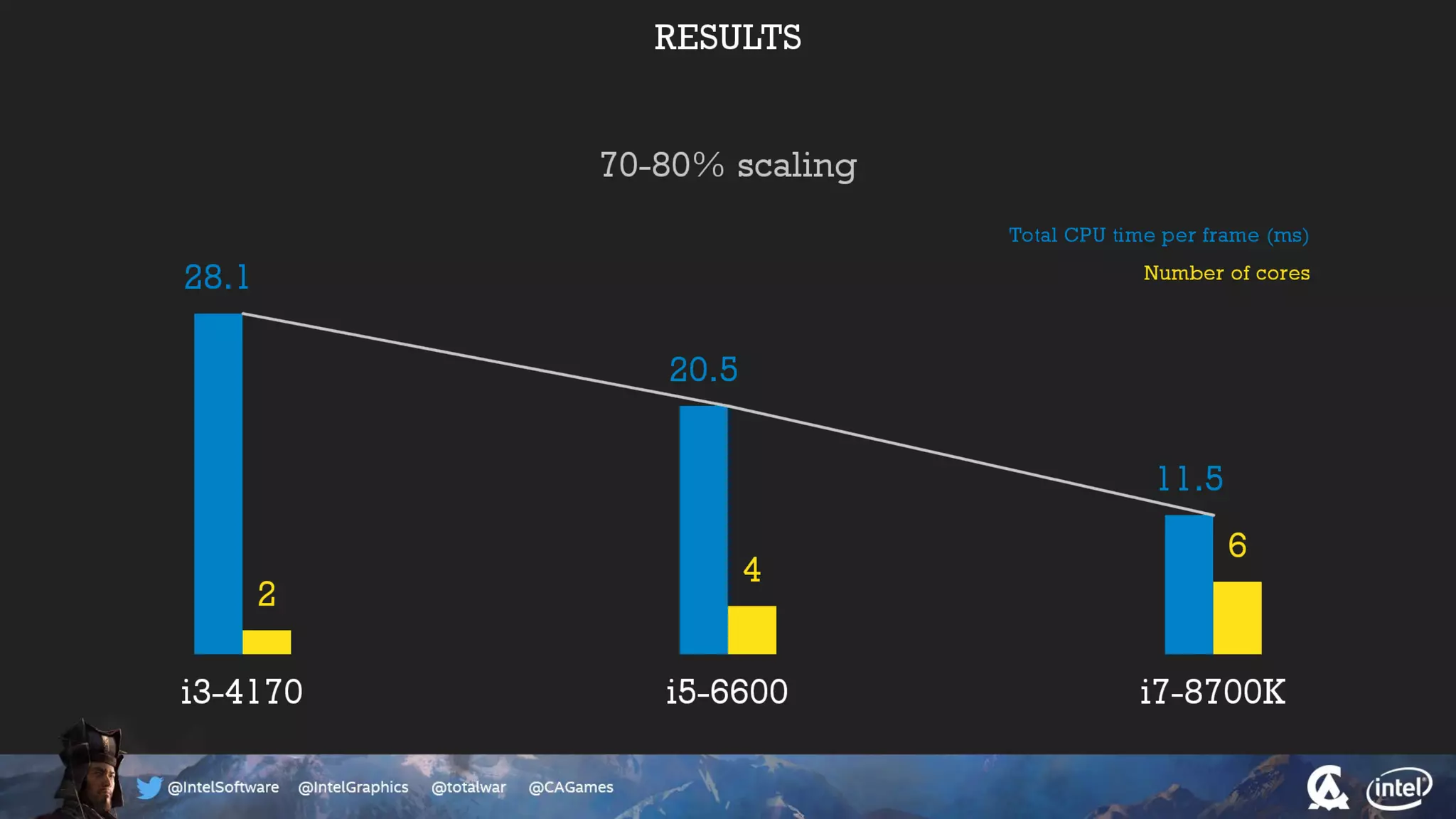


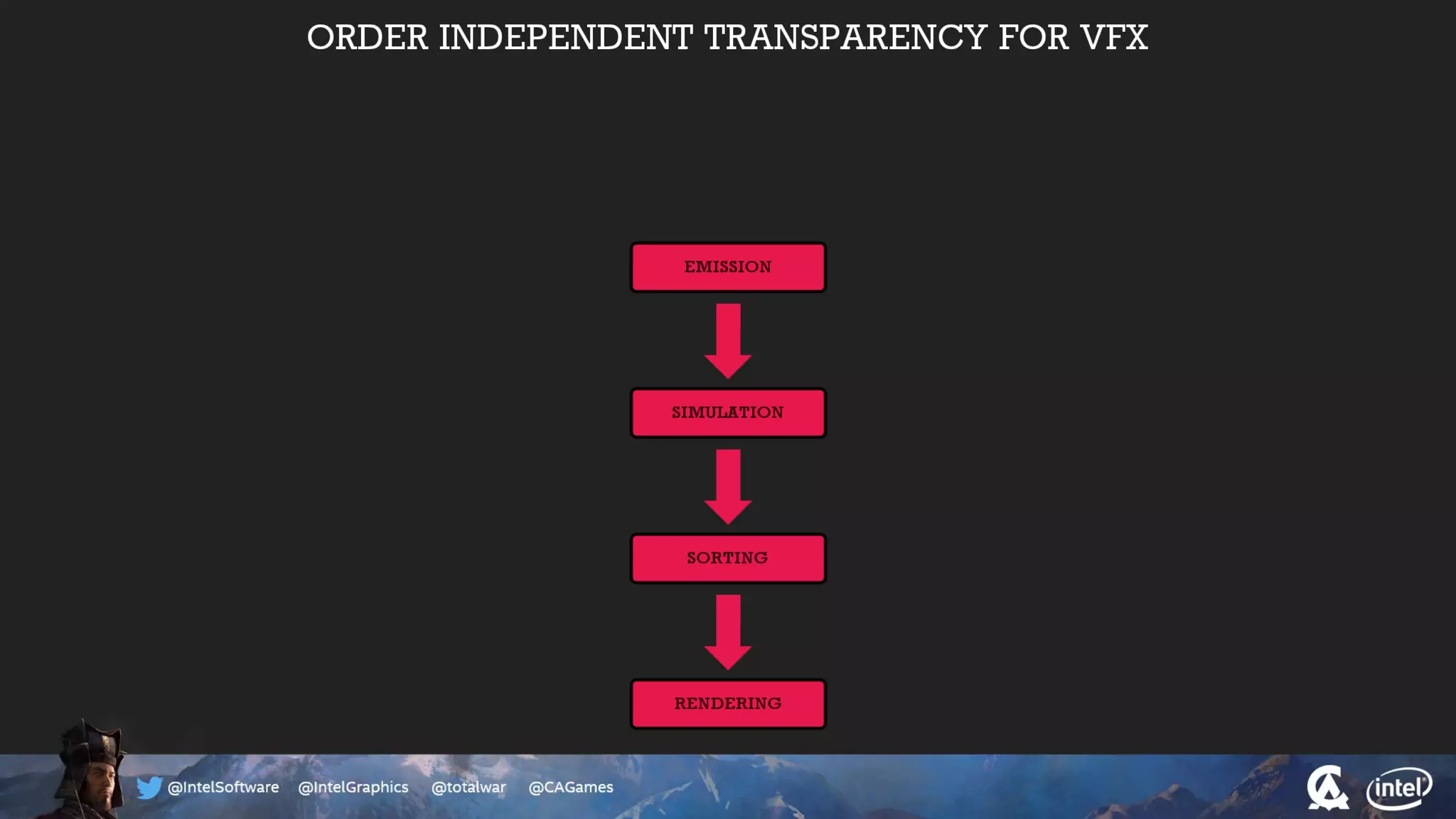
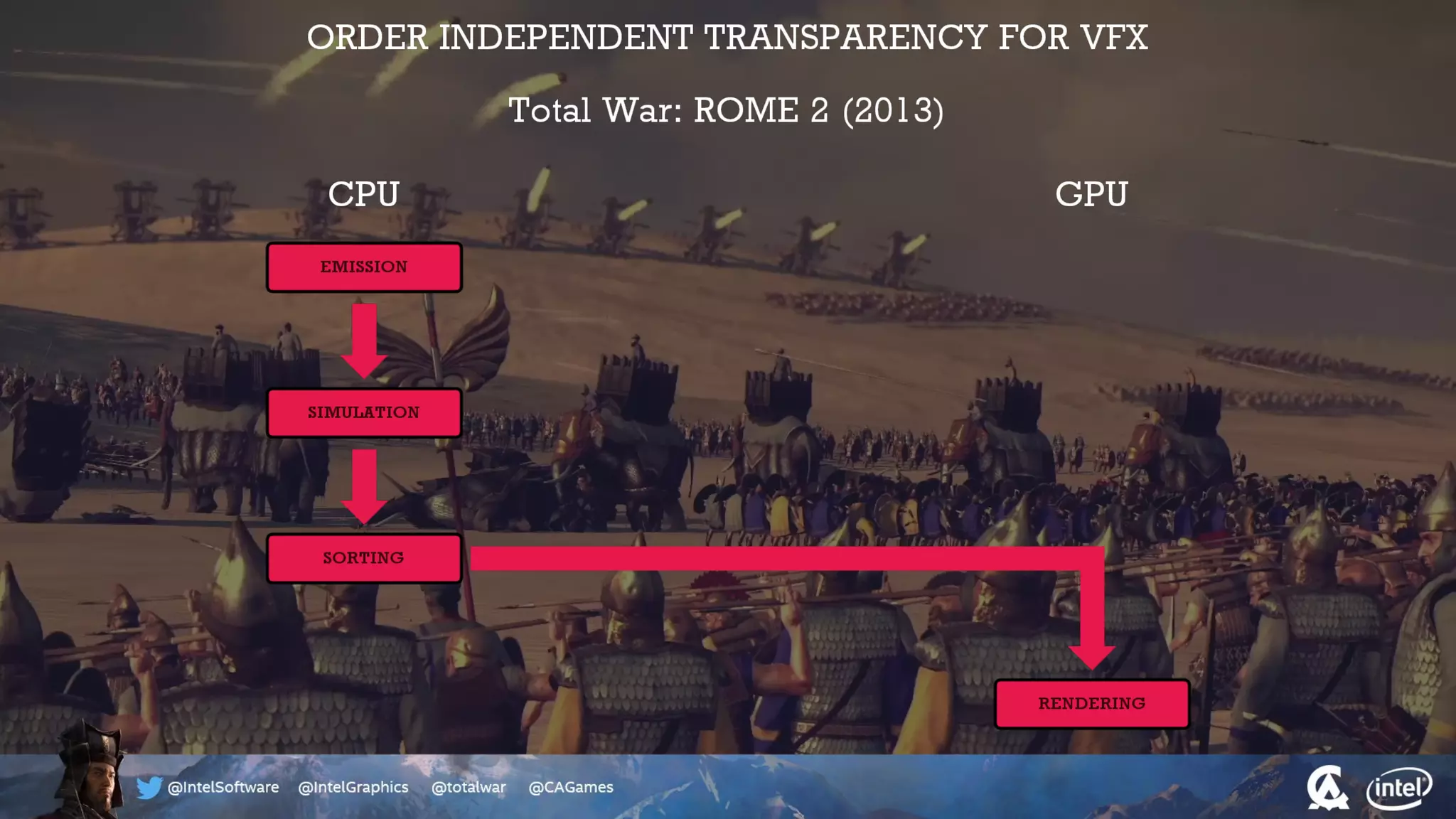
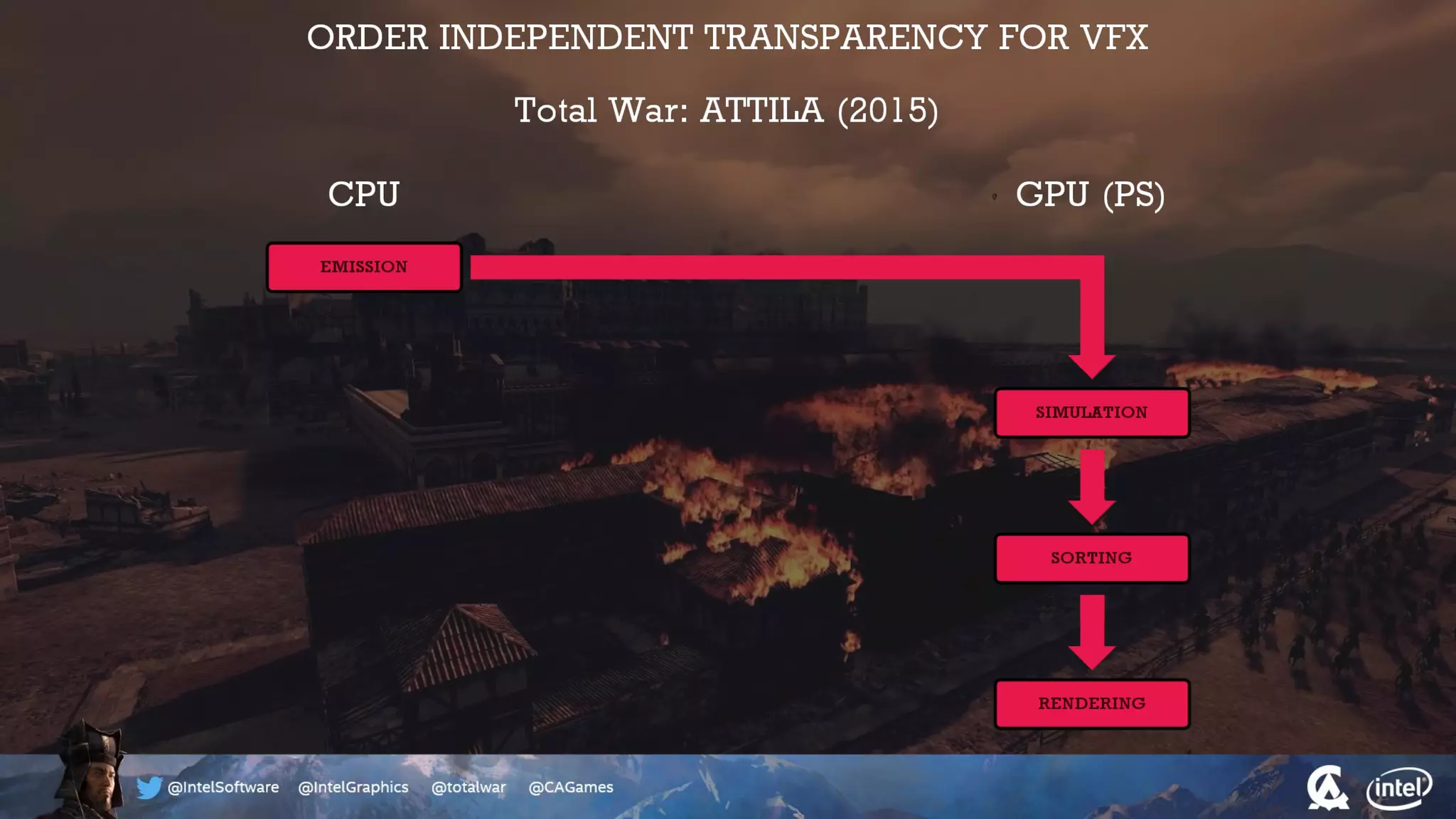
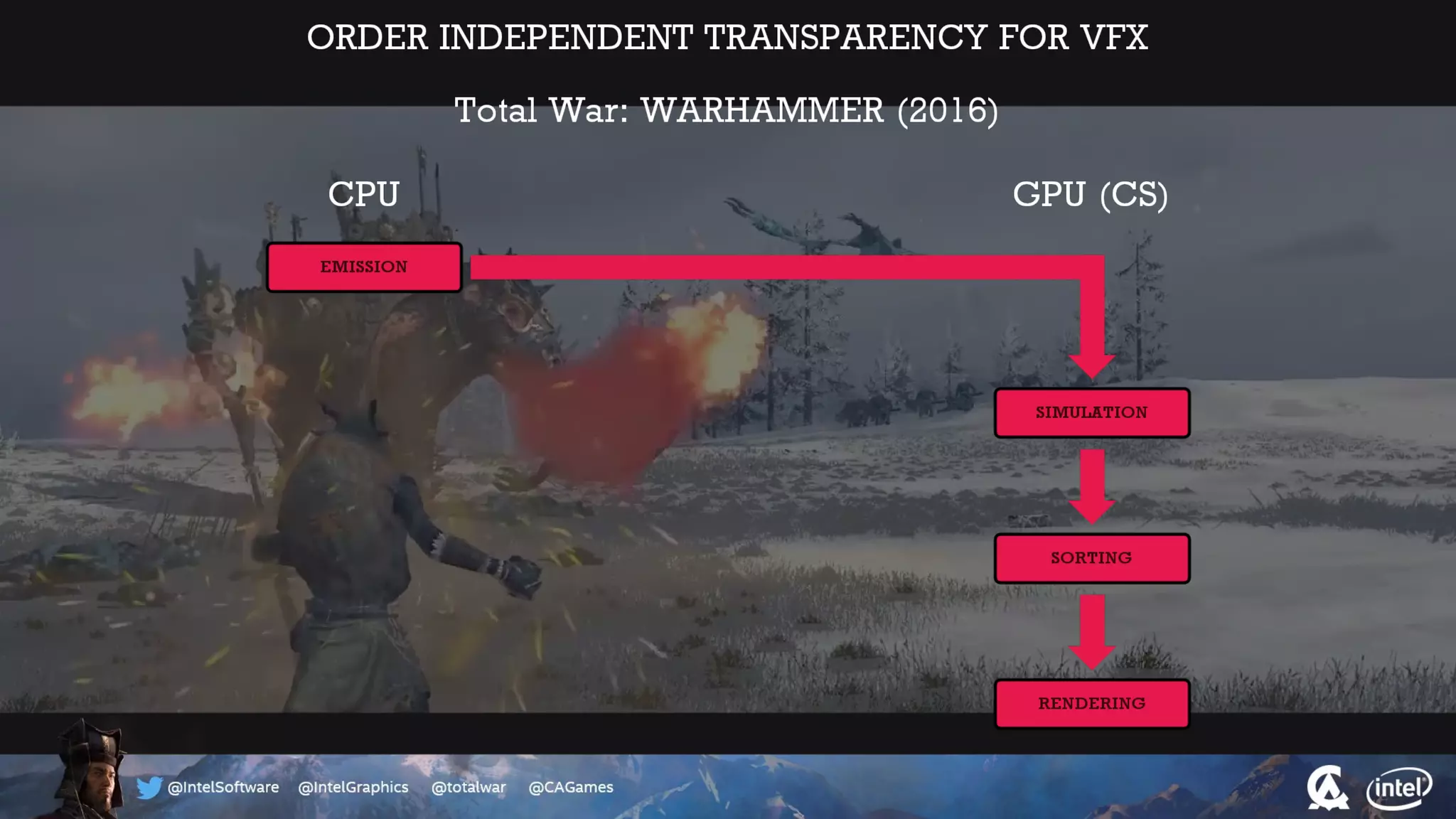
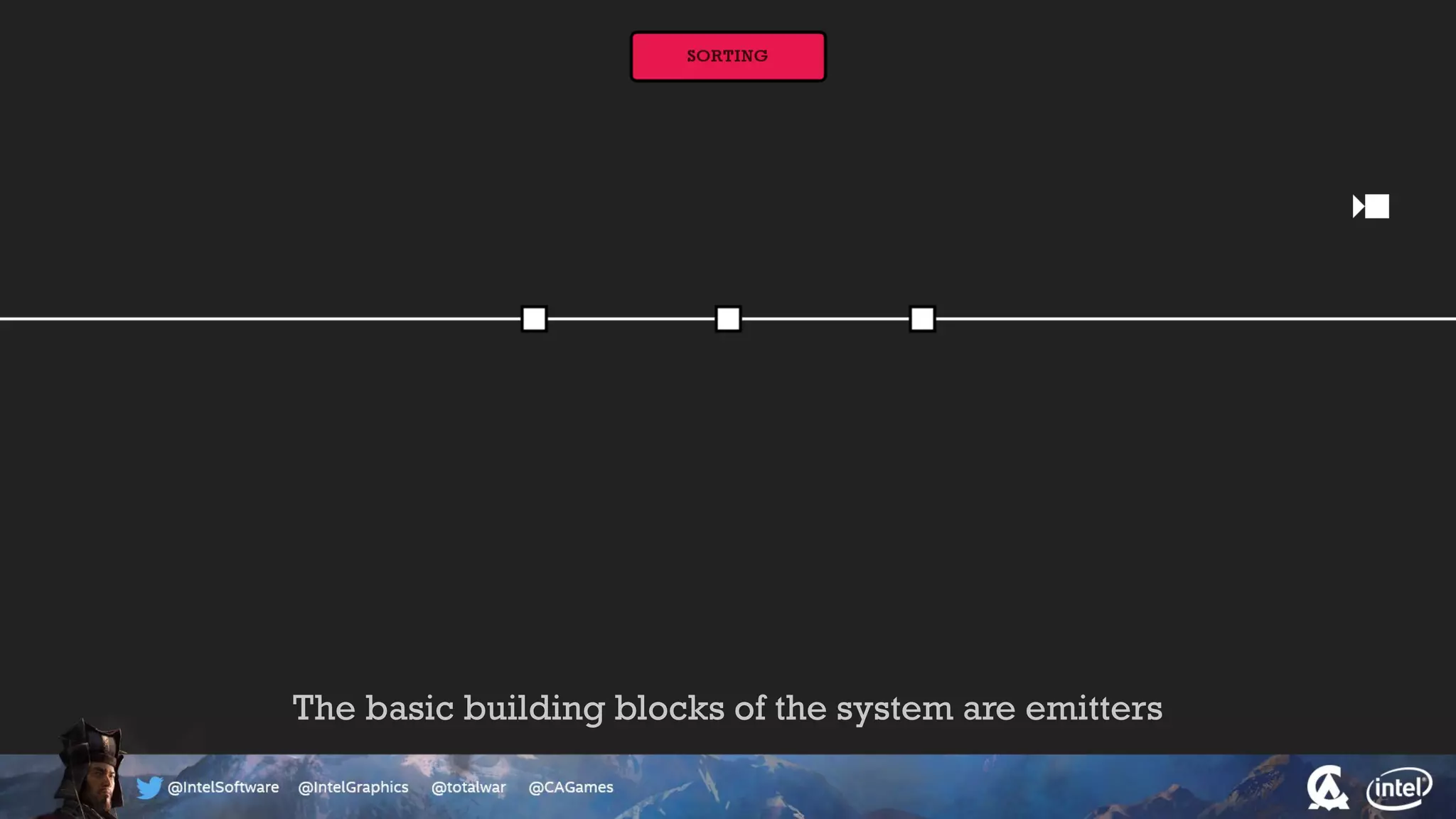
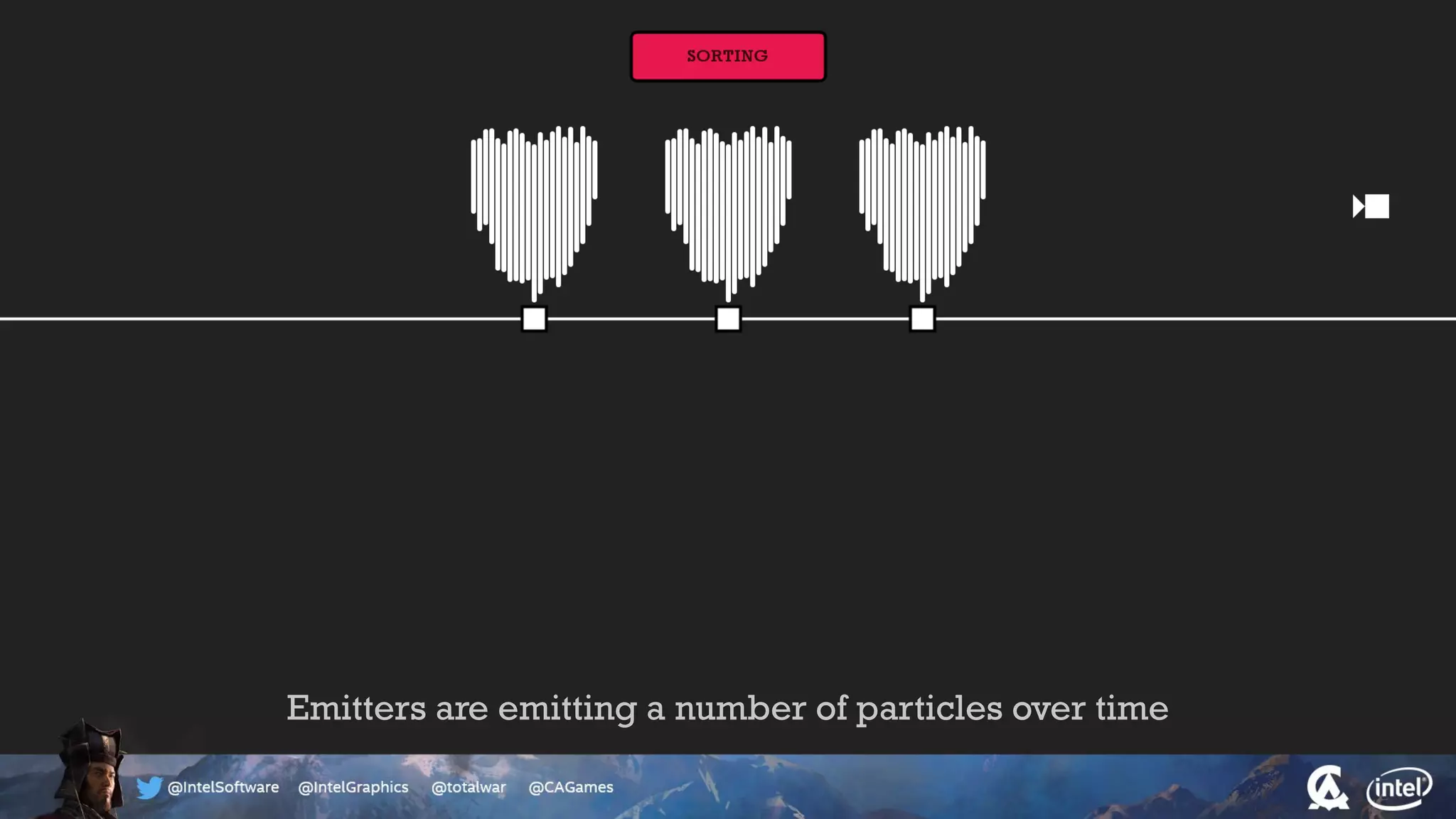

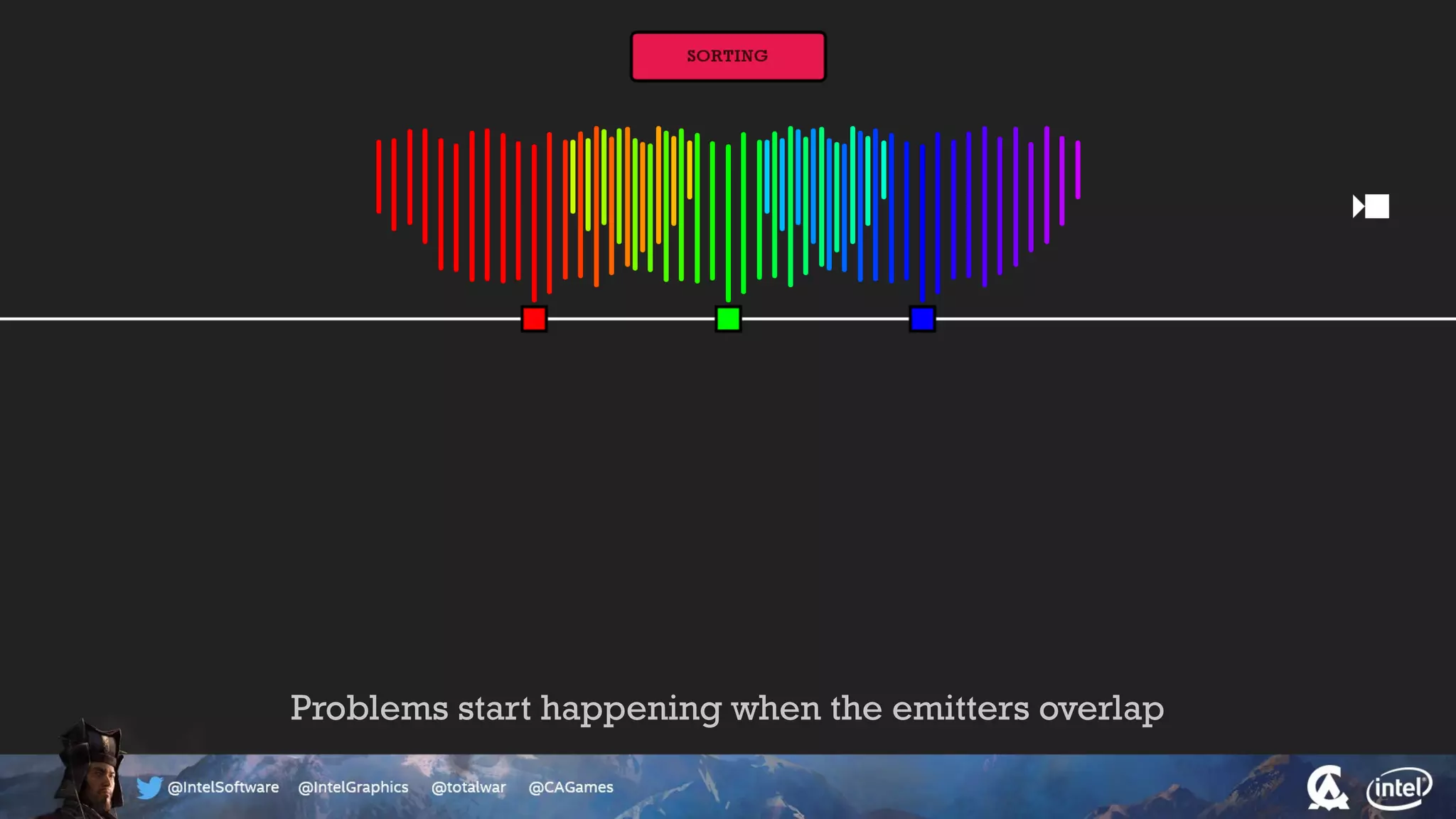
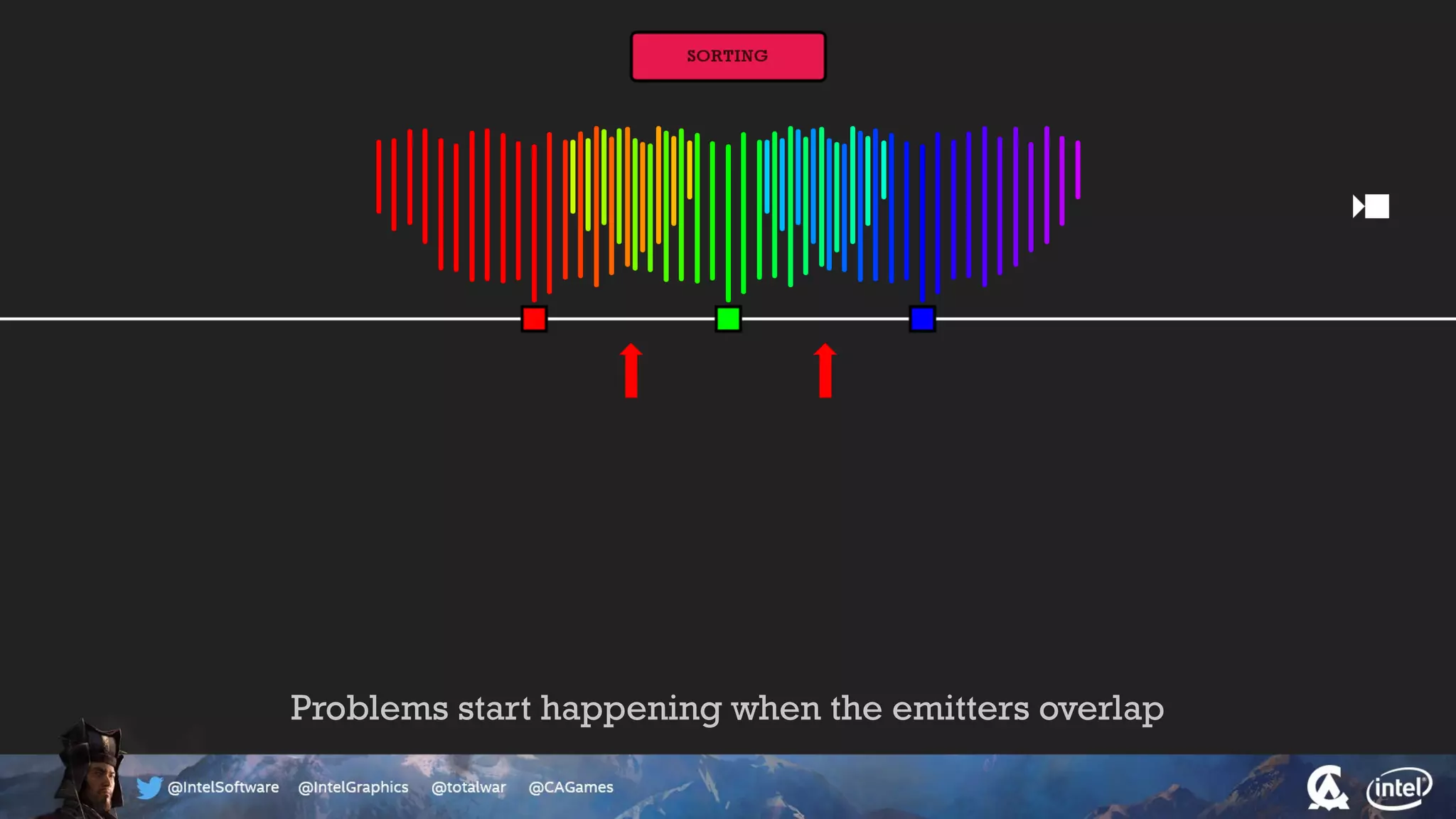
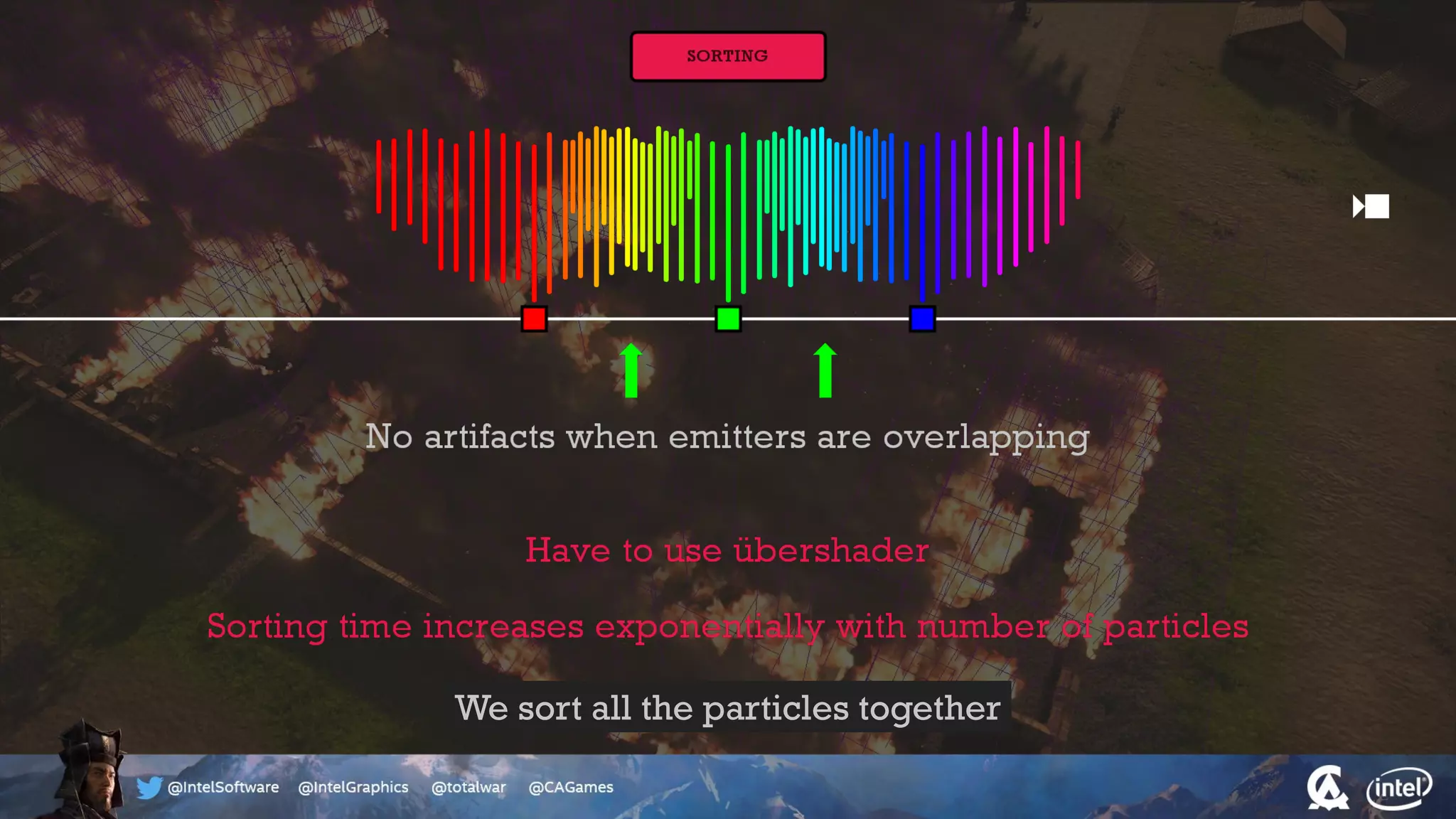
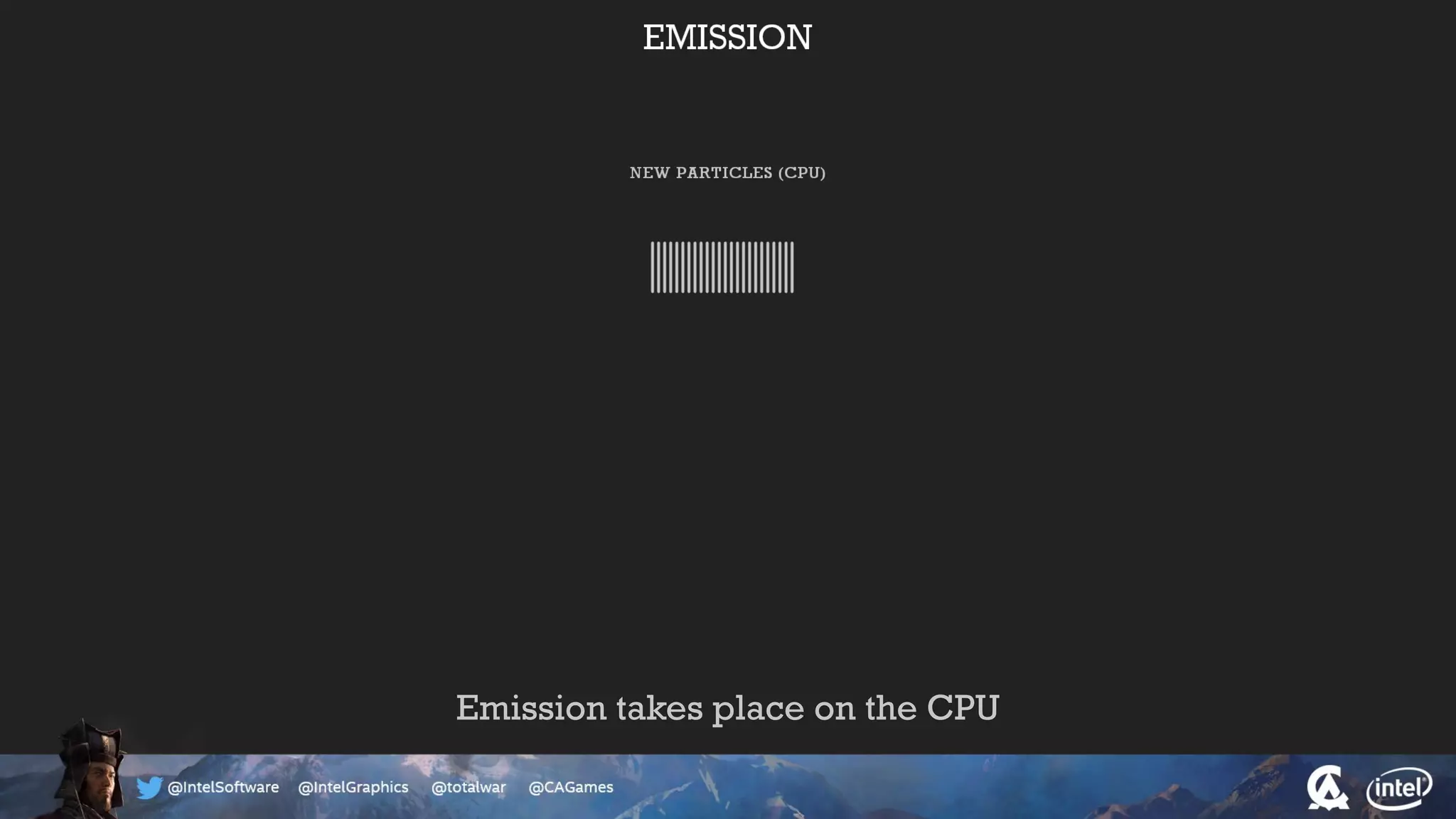











The document outlines the architecture and processing workflow of a turn-based battle RTS game, detailing how game state is built and rendered using worker threads for efficiency. It describes various processes including instance data management, mesh list handling, and rendering pipeline stages, focusing on optimizing tasks and ensuring lockless access. Additionally, it addresses challenges with particle emissions caused by overlapping emitters and the solutions explored, such as order-independent transparency techniques.









![[Unite Seoul 2019] Mali GPU Architecture and Mobile Studio](https://cdn.slidesharecdn.com/ss_thumbnails/maligpuarchitectureandmobilestudiofinal3-190717042828-thumbnail.jpg?width=640&height=640&fit=bounds)
























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)