Download as PDF, PPTX









![TEXT REPRESENTATION
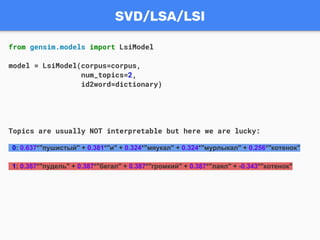
from gensim.corpora import Dictionary
from gensim.utils import tokenize
texts = [u"Пушистый котенок мурлыкал." , u"Пушистый кот
мурлыкал и мяукал.", u"Пушистый котенок мяукал.", u"Громкий
пушистый пудель бегал и лаял."]
tokenized_texts = [list(tokenize(text.lower())) for text in
texts]
dictionary = Dictionary(tokenized_texts)
corpus = [dictionary.doc2bow(text) for text in
tokenized_texts]
corpus(doc-term matrix):
[[(0, 1), (1, 1), (2, 1)],
[(1, 1), (2, 1), (3, 1), (4, 1), (5, 1)],
[(0, 1), (1, 1), (5, 1)],
[(1, 1), (4, 1), (6, 1), (7, 1), (8, 1), (9, 1)]]](https://image.slidesharecdn.com/101-170724083647/85/Gensim-RaRe-Technologies-WorldSense-9-320.jpg)


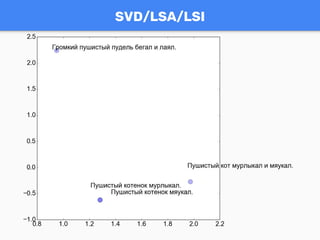

![LDA ALWAYS GIVES INTERPRETABLE TOPICS
import gensim
texts = [u"Пушистый котенок мурлыкал." , u"Пушистый кот мурлыкал и
мяукал.",
u"Пушистый котенок мяукал.", u"Громкий пушистый пудель бегал
и лаял."
u"Большой пудель лаял и кусался.", u"Громкий большой пудель
бегал."]
model = gensim.models.LdaMulticore(corpus=corpus,
id2word=dictionary,
num_topics=2)
Topics:
0: 0.185*"пушистый" + 0.134*"мяукал" + 0.134*"котенок" + 0.116*"
мурлыкал" + 0.075*"кот"
1: 0.136*"пудель" + 0.125*"и" + 0.102*"лаял" + 0.099*"пушистый" + 0.099*"
громкий"](https://image.slidesharecdn.com/101-170724083647/85/Gensim-RaRe-Technologies-WorldSense-15-320.jpg)


![CO-OCCURRENCE MATRIX FOR DOC2VEC
котенок context words: [пушистый, мурлыкал, мяукал].
кот context words: [пушистый, мурлыкал, мяукал].
пудель context words: [пушистый, бегал].
Credit: Ed Grefenstette https://github.com/oxford-cs-deepnlp-2017/
№1: Пушистый котенок мурлыкал.
№2: Пушистый кот мурлыкал и мяукал.
№3: Пушистый котенок мяукал.
№4: Громкий пушистый пудель бегал и лаял.](https://image.slidesharecdn.com/101-170724083647/85/Gensim-RaRe-Technologies-WorldSense-18-320.jpg)
![котенок context words: [пушистый, мурлыкал, мяукал].
кот context words: [пушистый, мурлыкал, мяукал].
пудель context words: [ пушистый, бегал].
пушистый мурлыкал лаял мяукал громкий бегал
котенок 2 1 0 1 0 0
кот 1 1 0 1 0 0
пудель 1 0 0 0 0 1
X =
CO-OCCURRENCE MATRIX FOR DOC2VEC](https://image.slidesharecdn.com/101-170724083647/85/Gensim-RaRe-Technologies-WorldSense-19-320.jpg)
![DOC2VEC: NEURAL NETWORK, NOT INTERPRETABLE
from gensim.models import Doc2Vec
from gensim.models.doc2vec import
LabeledSentence
corpus = [LabeledSentence(sent, [idx])
for (idx, sent) in
enumerate(texts)]
model = Doc2Vec(size=5, window=2,
min_count=1)
model.build_vocab(corpus)
model.train(corpus,
epochs=5,
total_examples=len(corpus))](https://image.slidesharecdn.com/101-170724083647/85/Gensim-RaRe-Technologies-WorldSense-20-320.jpg)





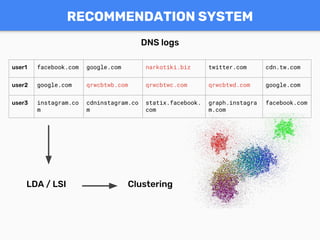





Документ обсуждает темы моделирования на основе текста с использованием библиотеки Gensim, включая его применение в классификации контента, системах рекомендаций и поисковых системах. Приведены примеры работы с терм-документной матрицей и методами, такими как LDA и Doc2Vec, а также ключевые функции Gensim и его преимущества. Также упоминаются участники сообщества и возможности для профессионального обучения и консультаций.



























