Download to read offline




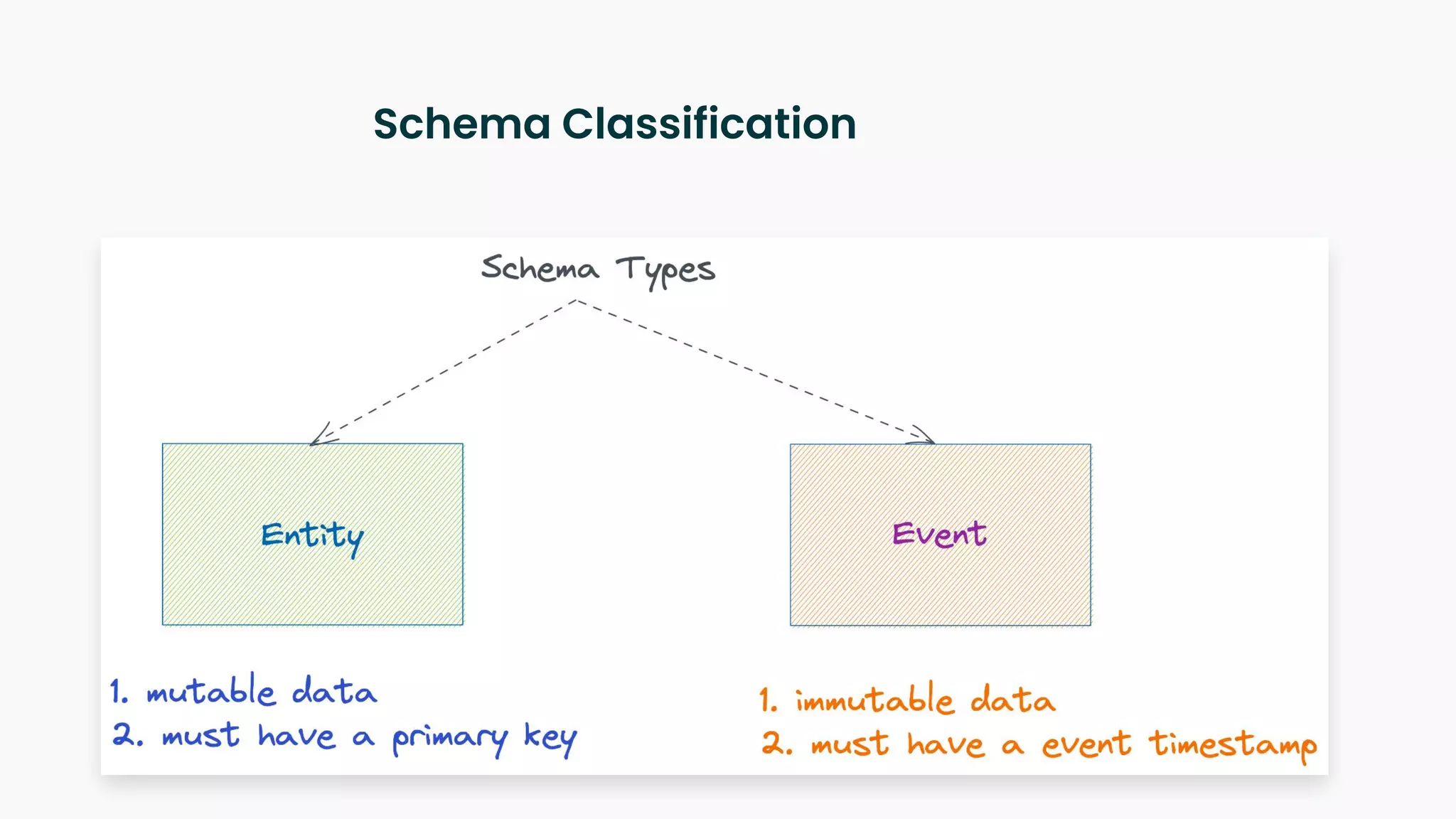

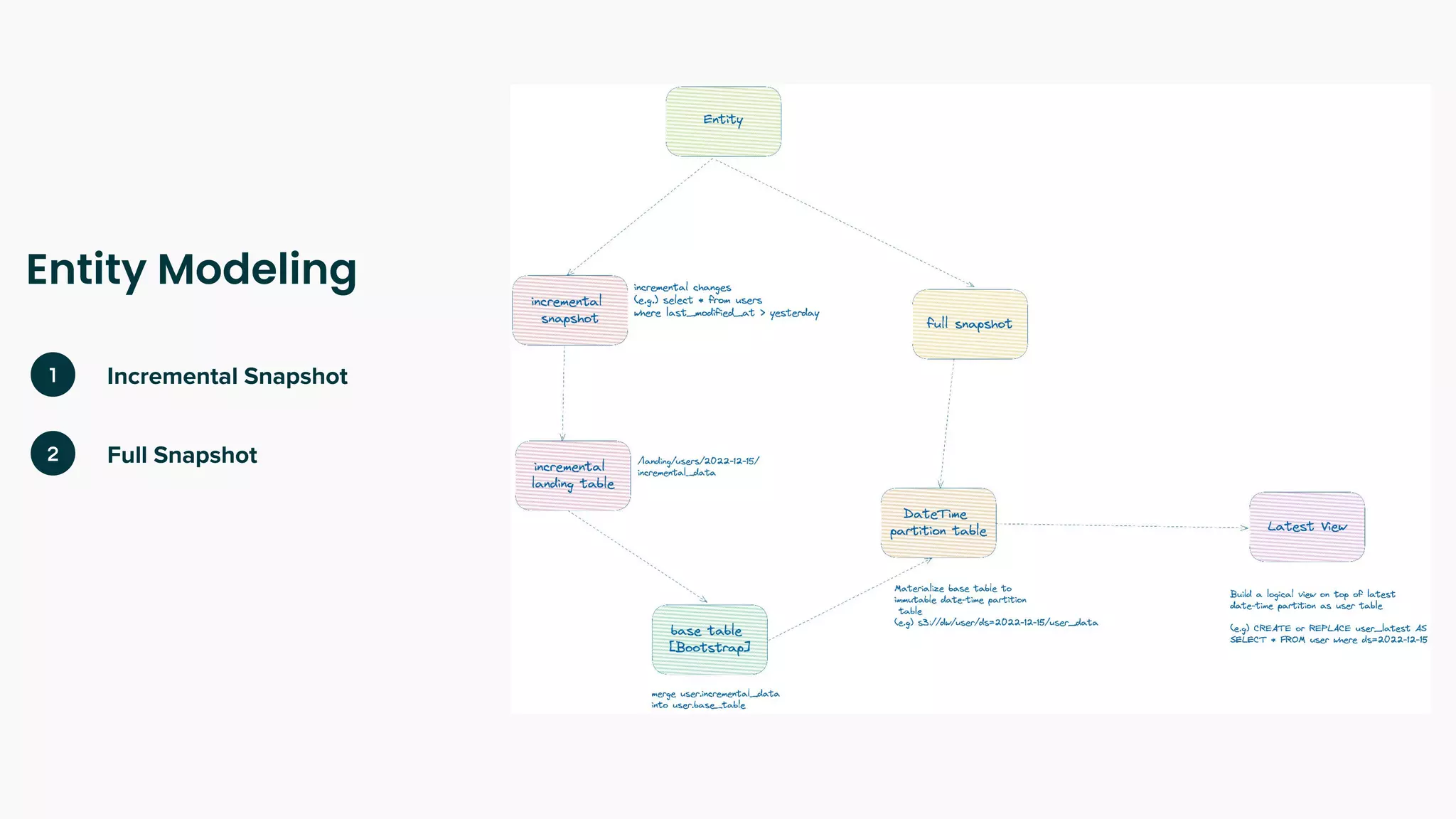
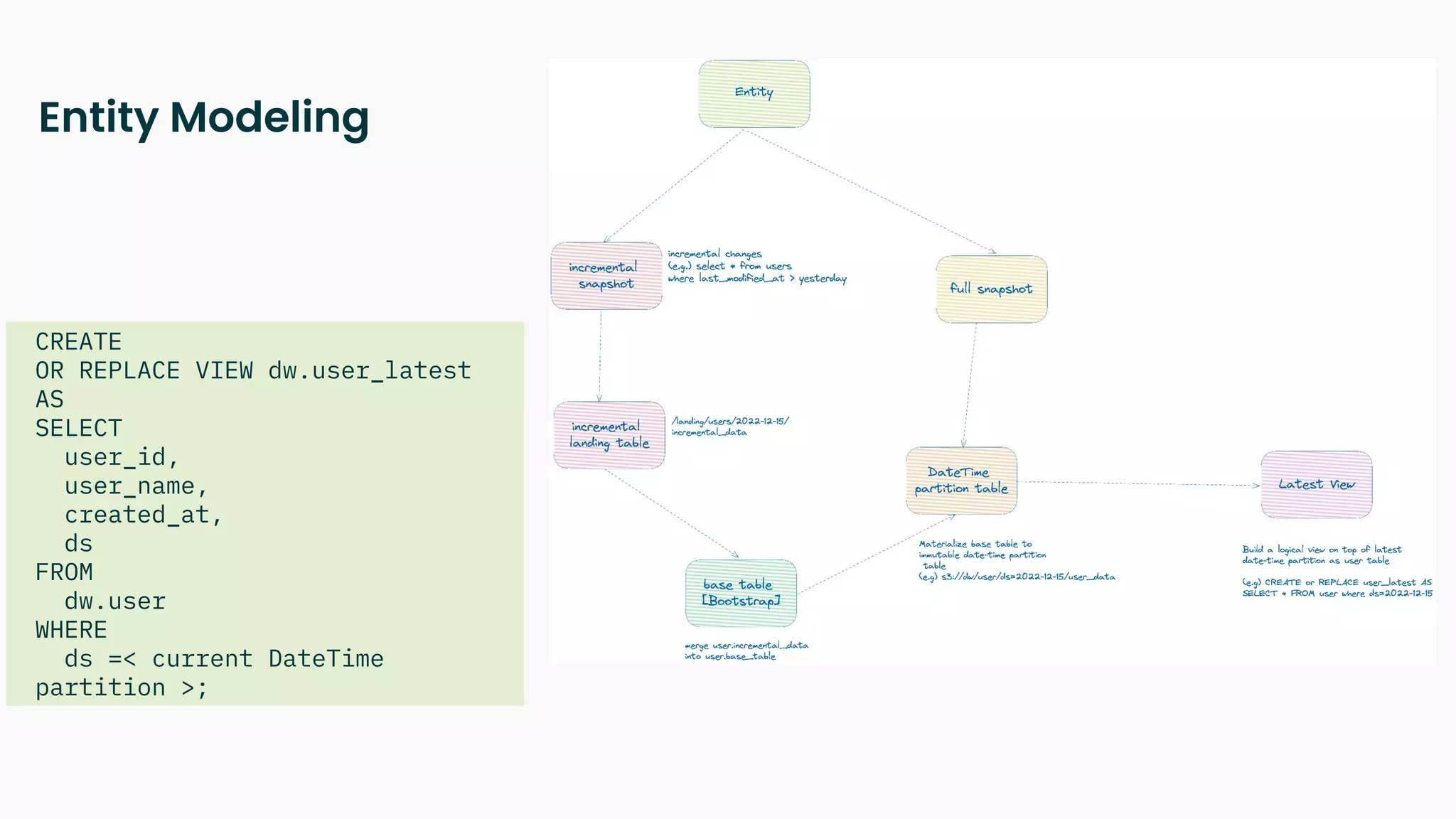
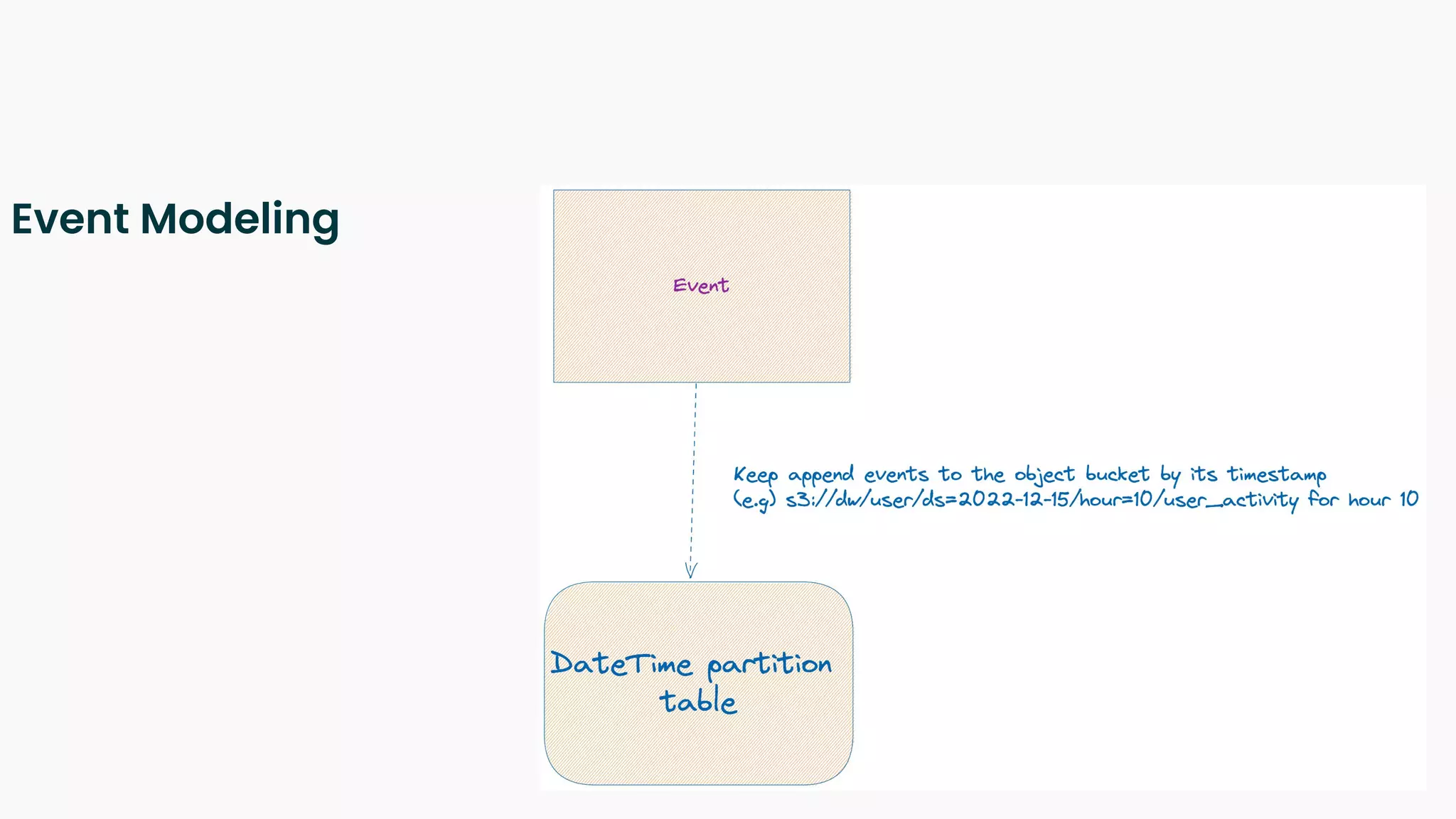


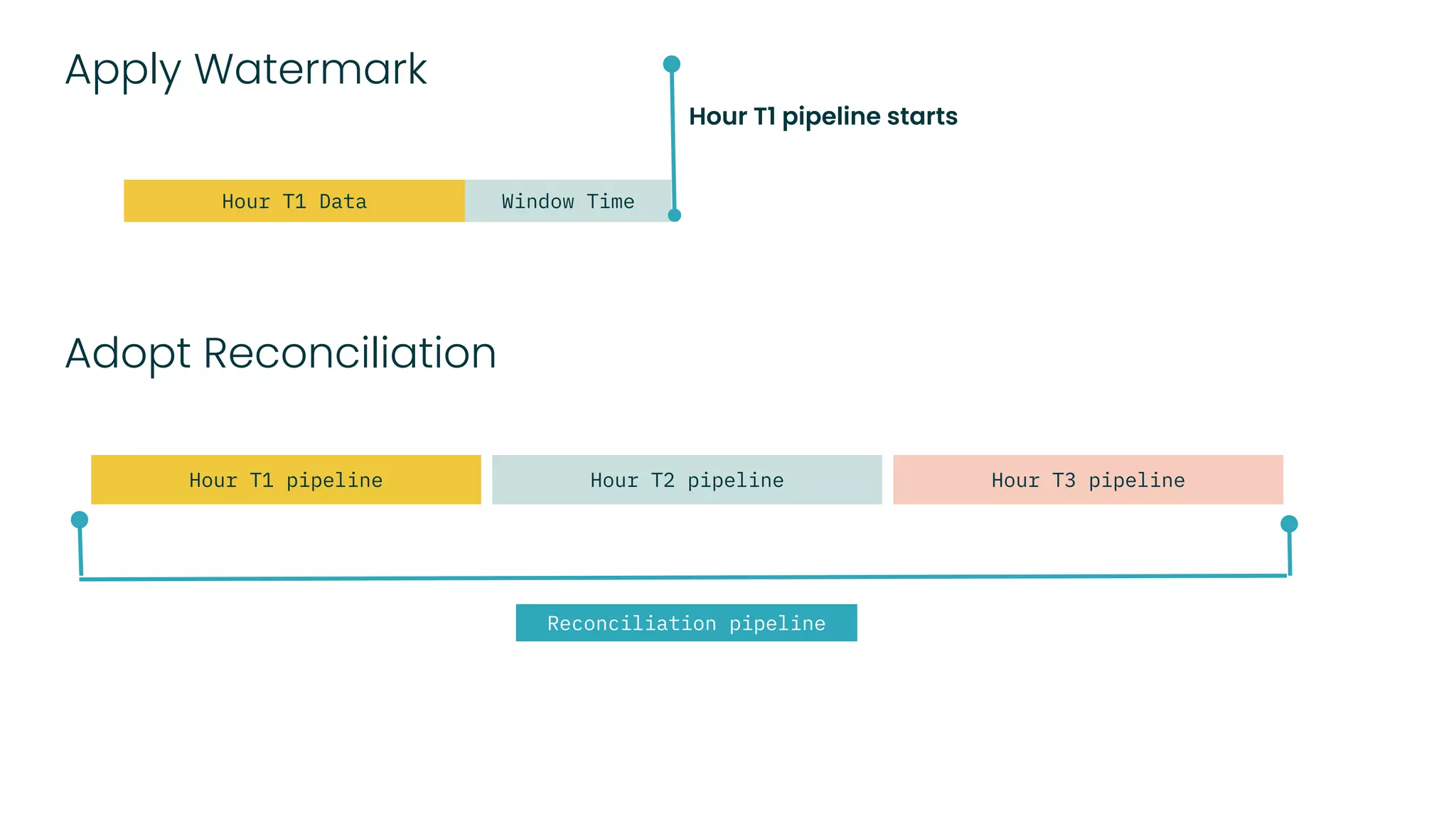




The document outlines a blueprint for adopting functional principles in data engineering, focusing on reproducibility and re-computability within modern data architectures like lakehouses and warehouses. It discusses key concepts such as entity modeling, incremental and full snapshots, as well as challenges related to data processing, including late arriving data and data deletion. Additionally, it provides examples of data table design and views to enhance data management practices.















![[DSC Europe 23] Milos Solujic - Data Lakehouse Revolutionizing Data Managemen...](https://cdn.slidesharecdn.com/ss_thumbnails/xihnewjtu6mlbi5hbkoq-milos-solujic-data-lakehouse-revolutionizing-data-management-231129142742-90fb161d-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)





