



![$13.01 forevery$1
a company spends on analytics, it
gets back spend on data
management and analytics
Source: MIT Sloan, NucleusResearch
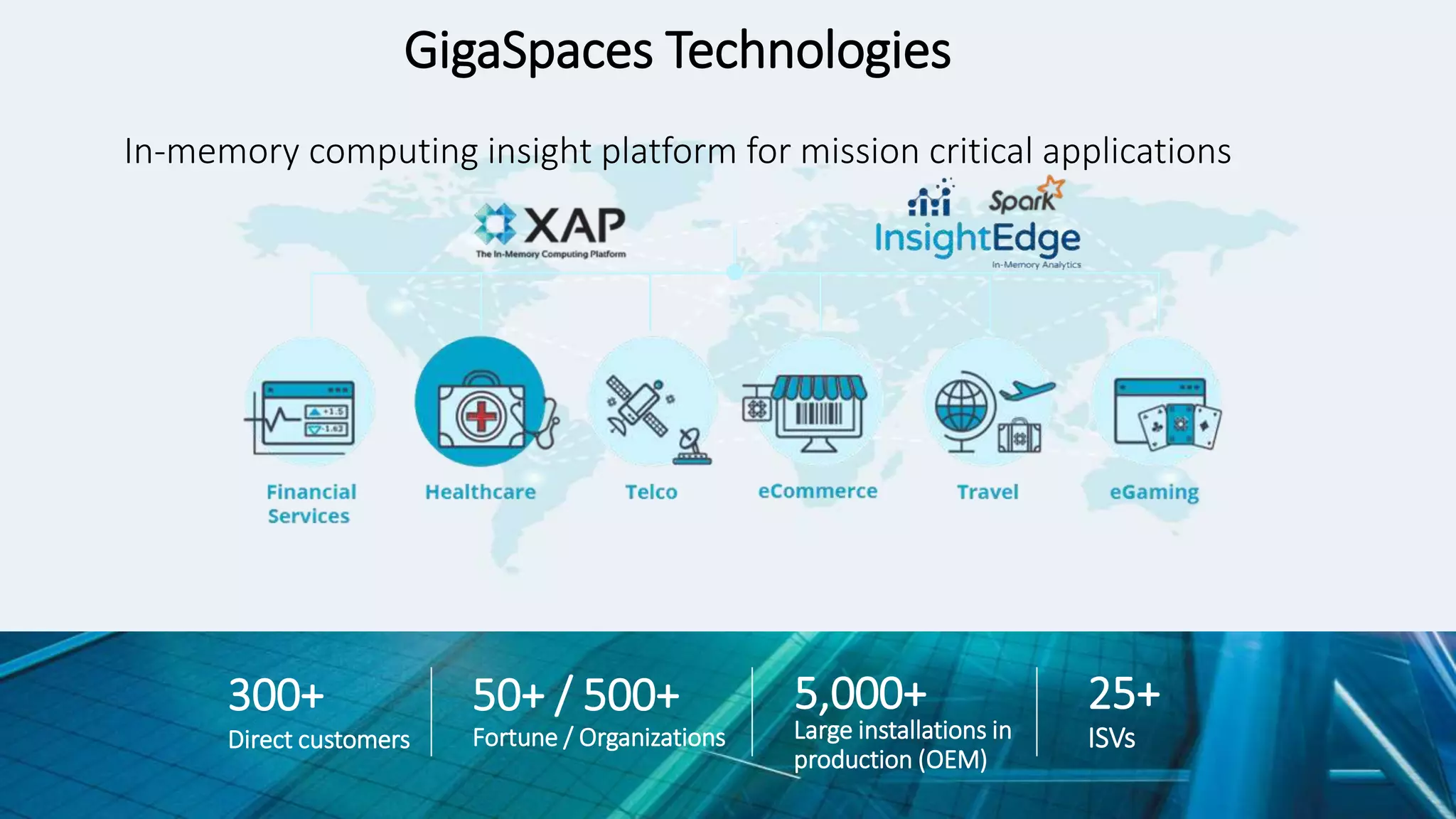
Value of leveraging analytics and data-driven decisions
74%of firms say they want to be data-
driven, but only 23%are successful
Source: Forbes: Actionable Insight: Missing Link between Data and Value
2x [companies are twice] likely to
outperform their peers if they use
advanced analytics
Source: MIT Sloan](https://image.slidesharecdn.com/fromdatatoservicesatthespeedofbusiness-170831230343/75/From-Data-to-Services-at-the-Speed-of-Business-8-2048.jpg)



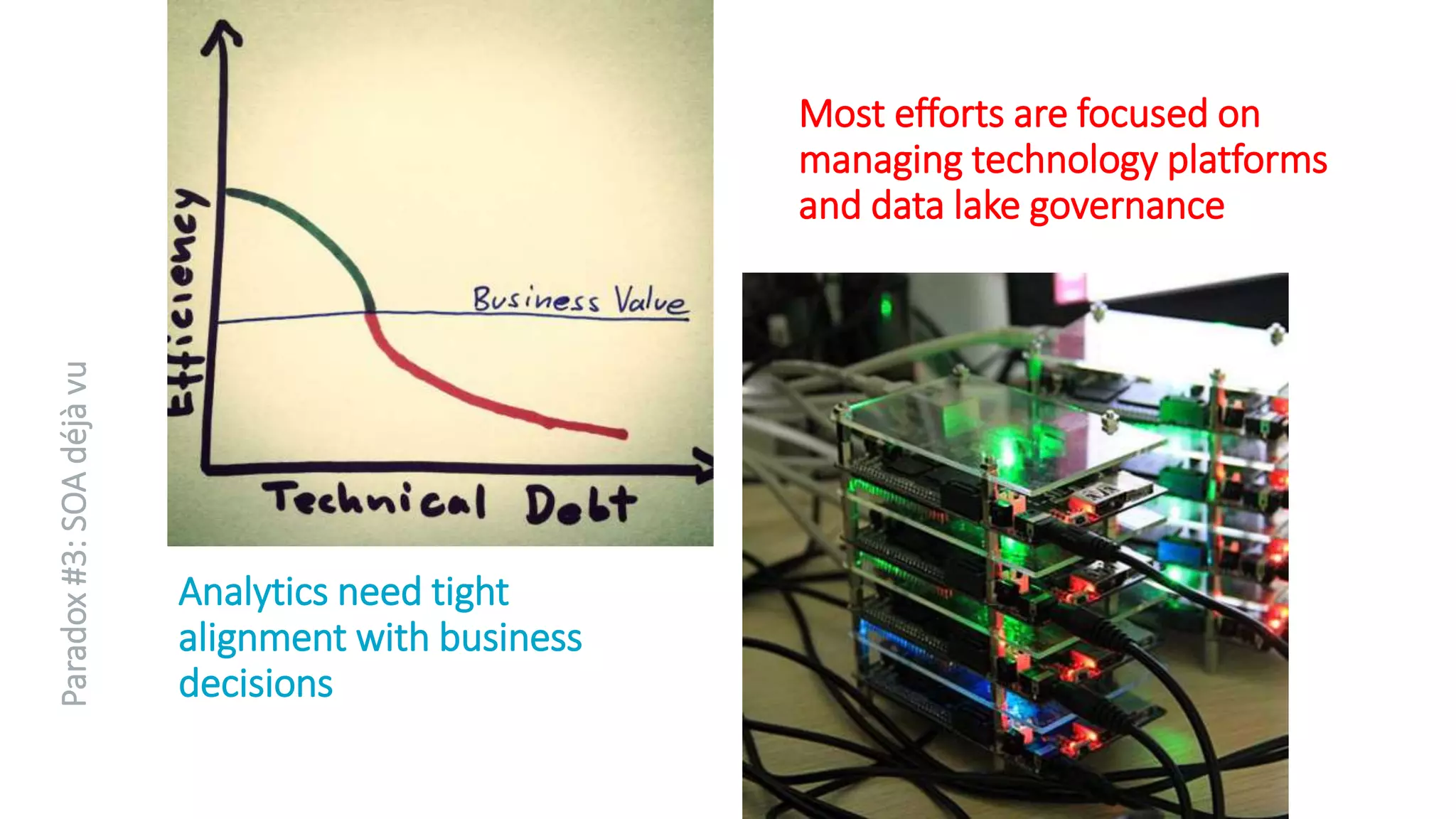


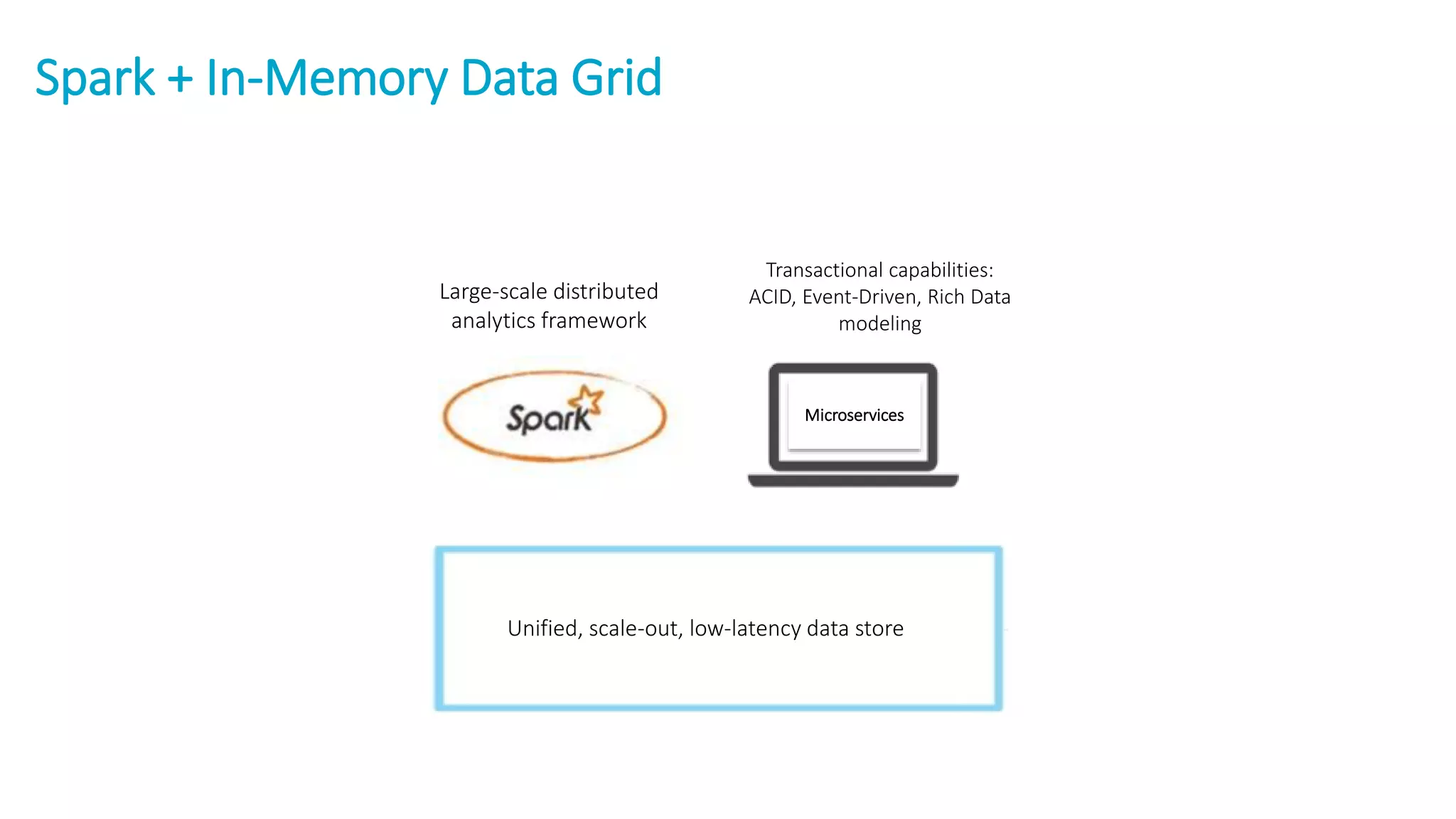

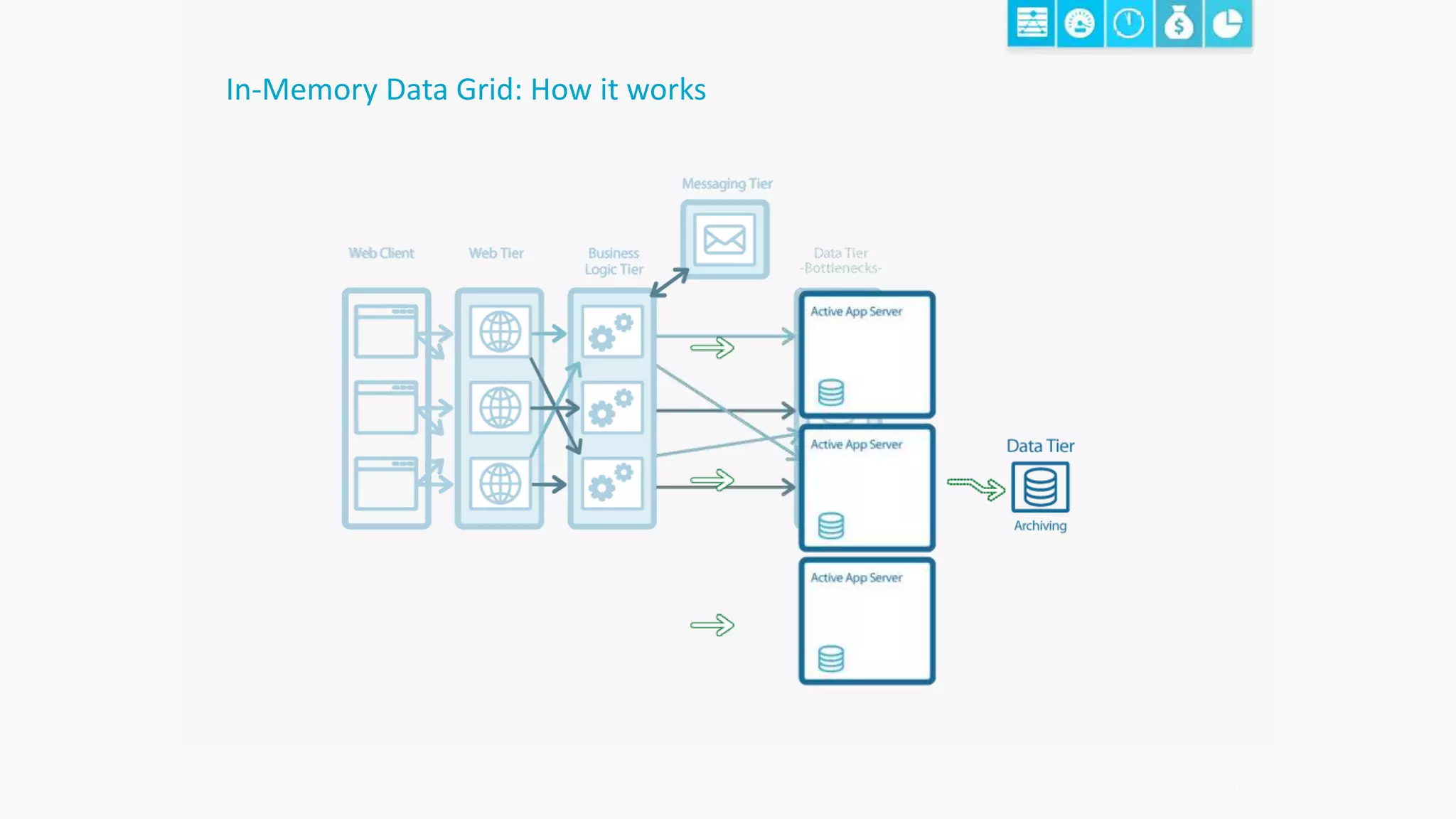

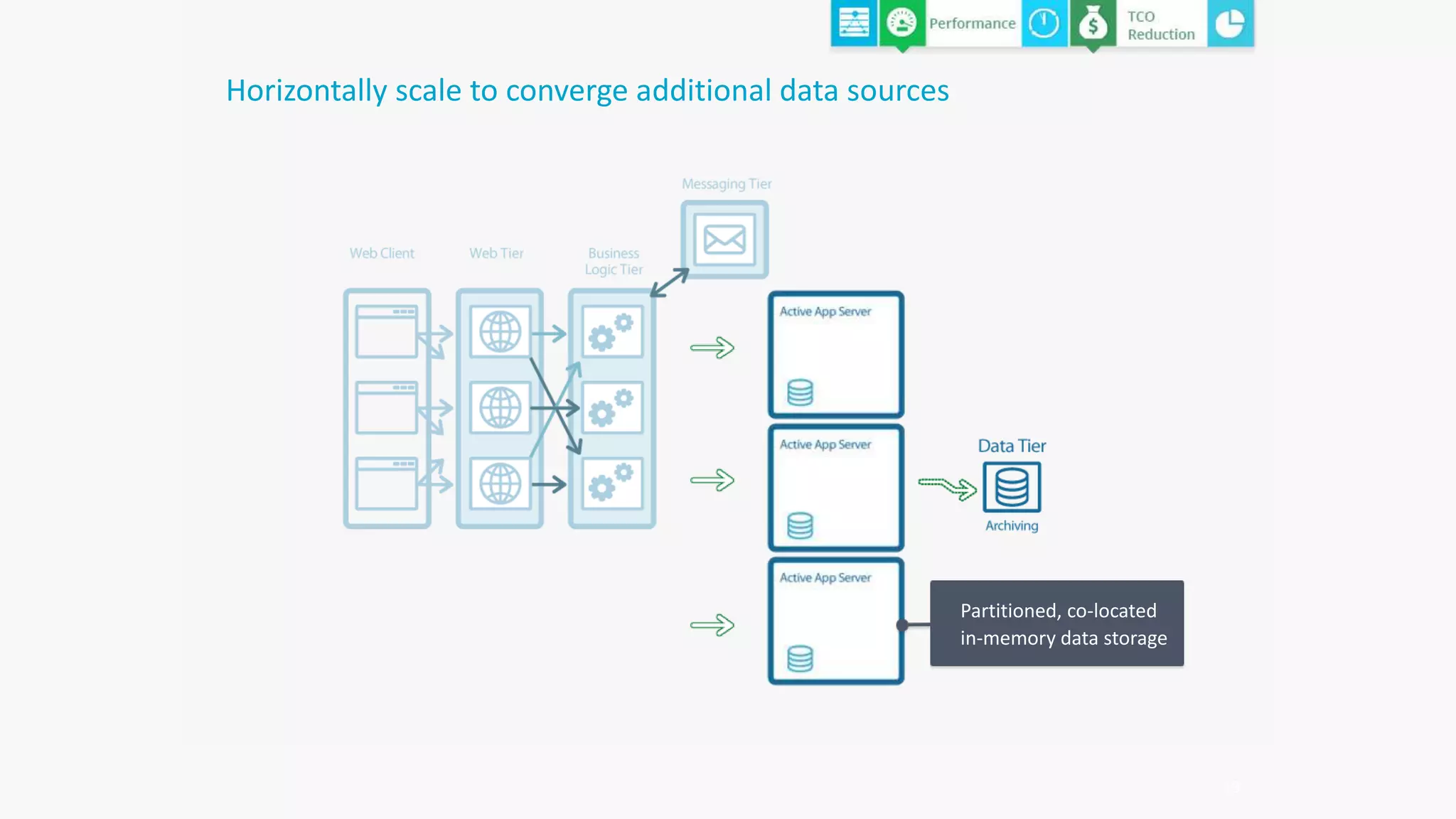


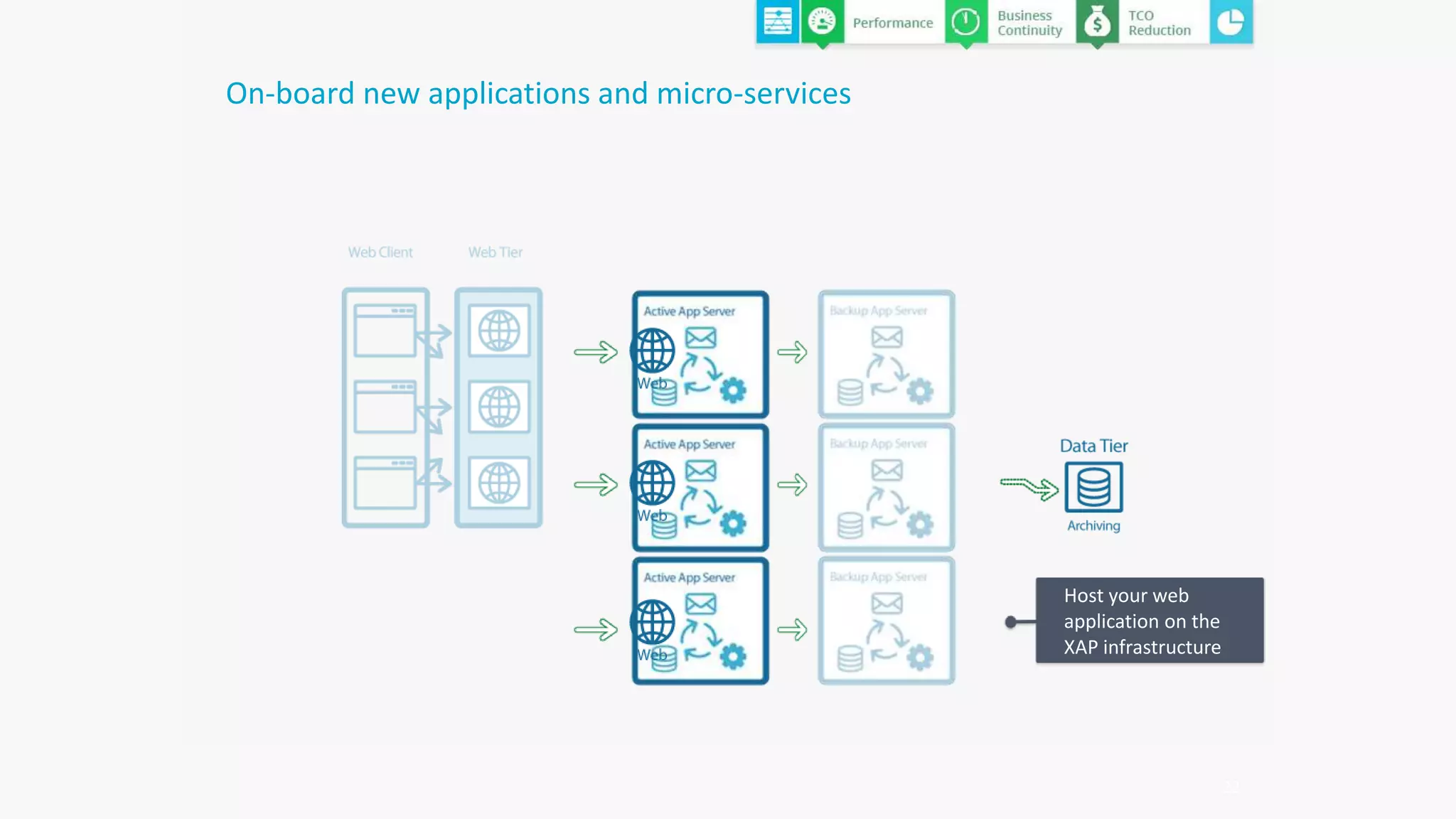
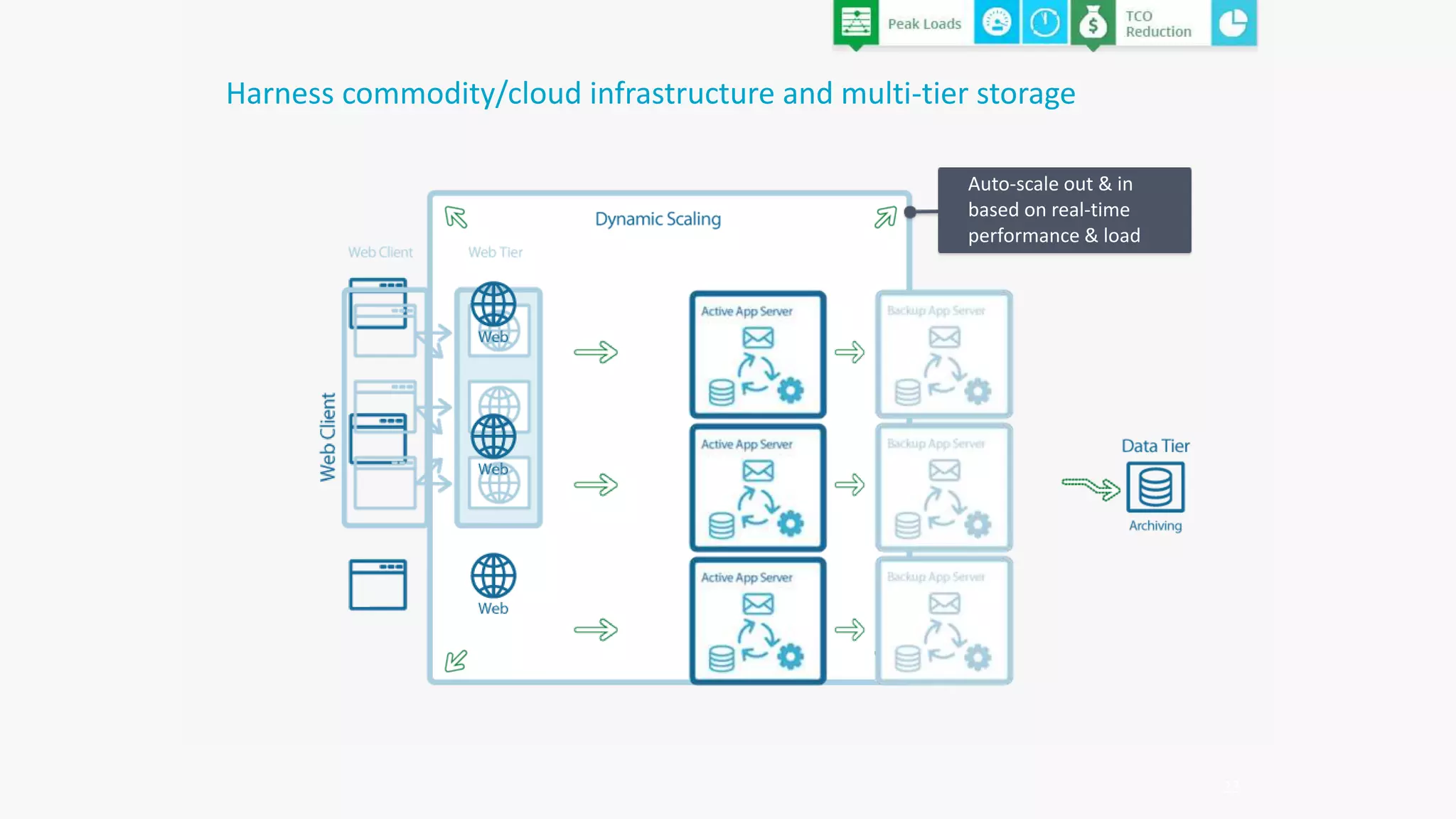
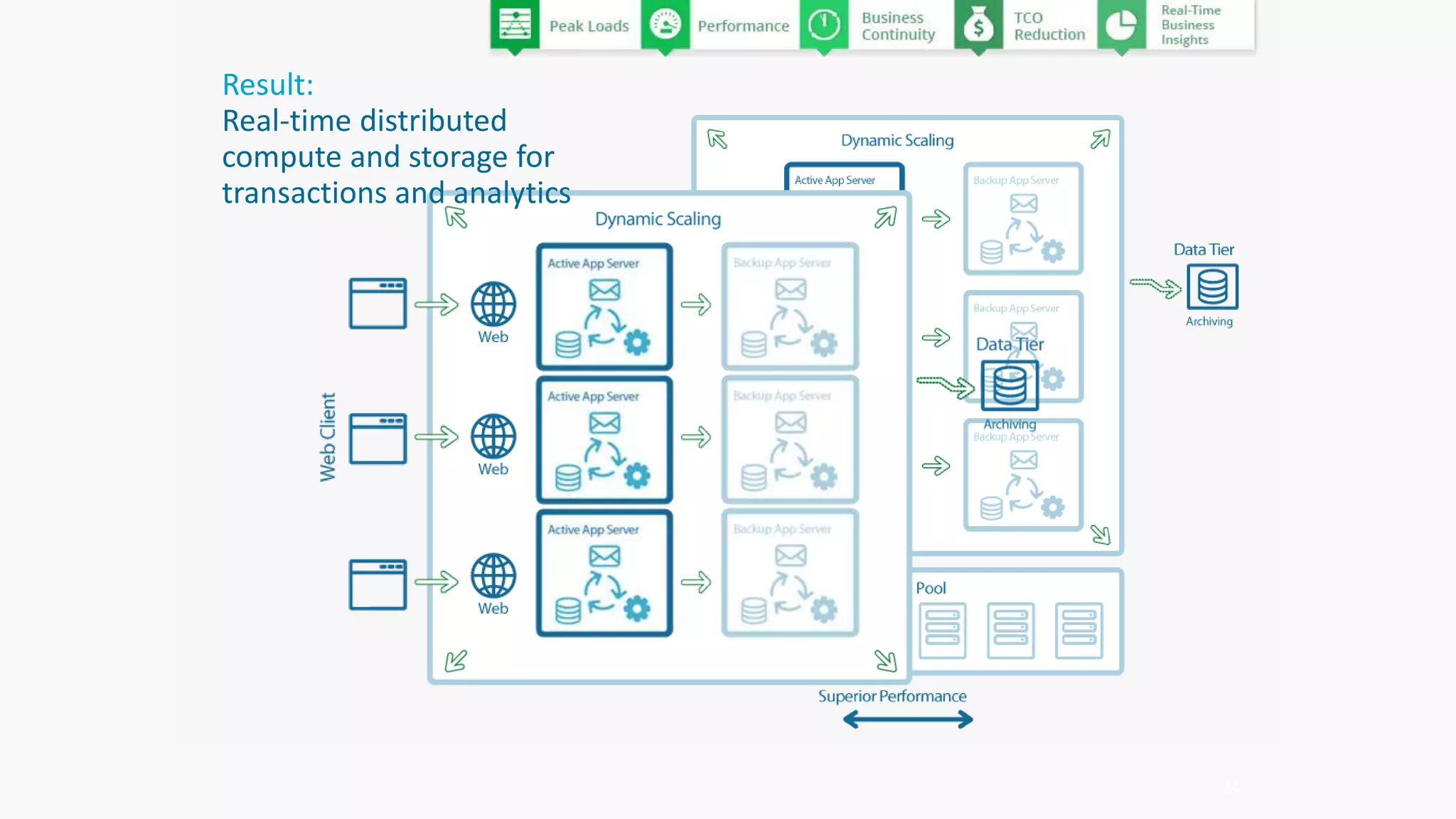

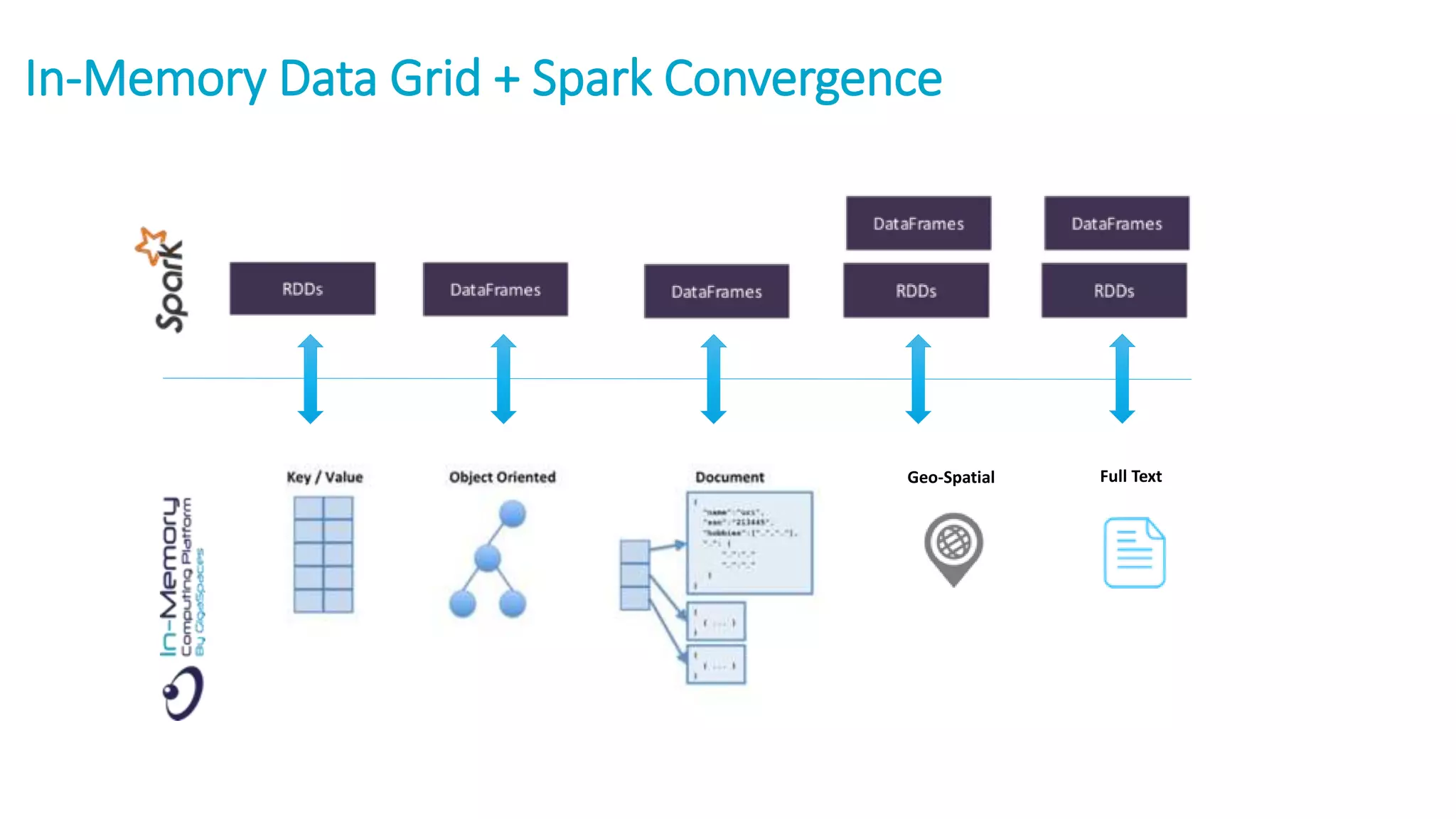
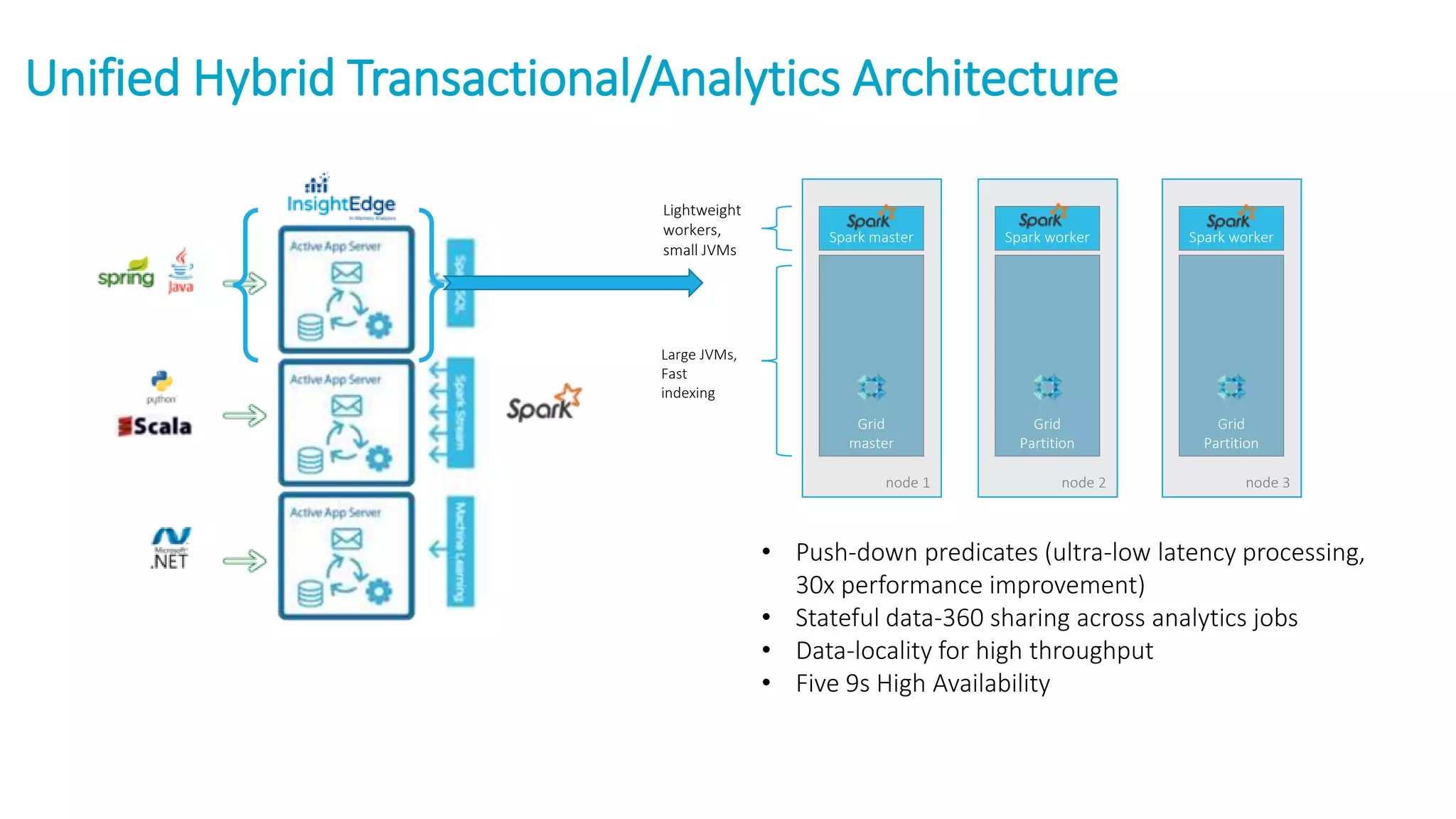




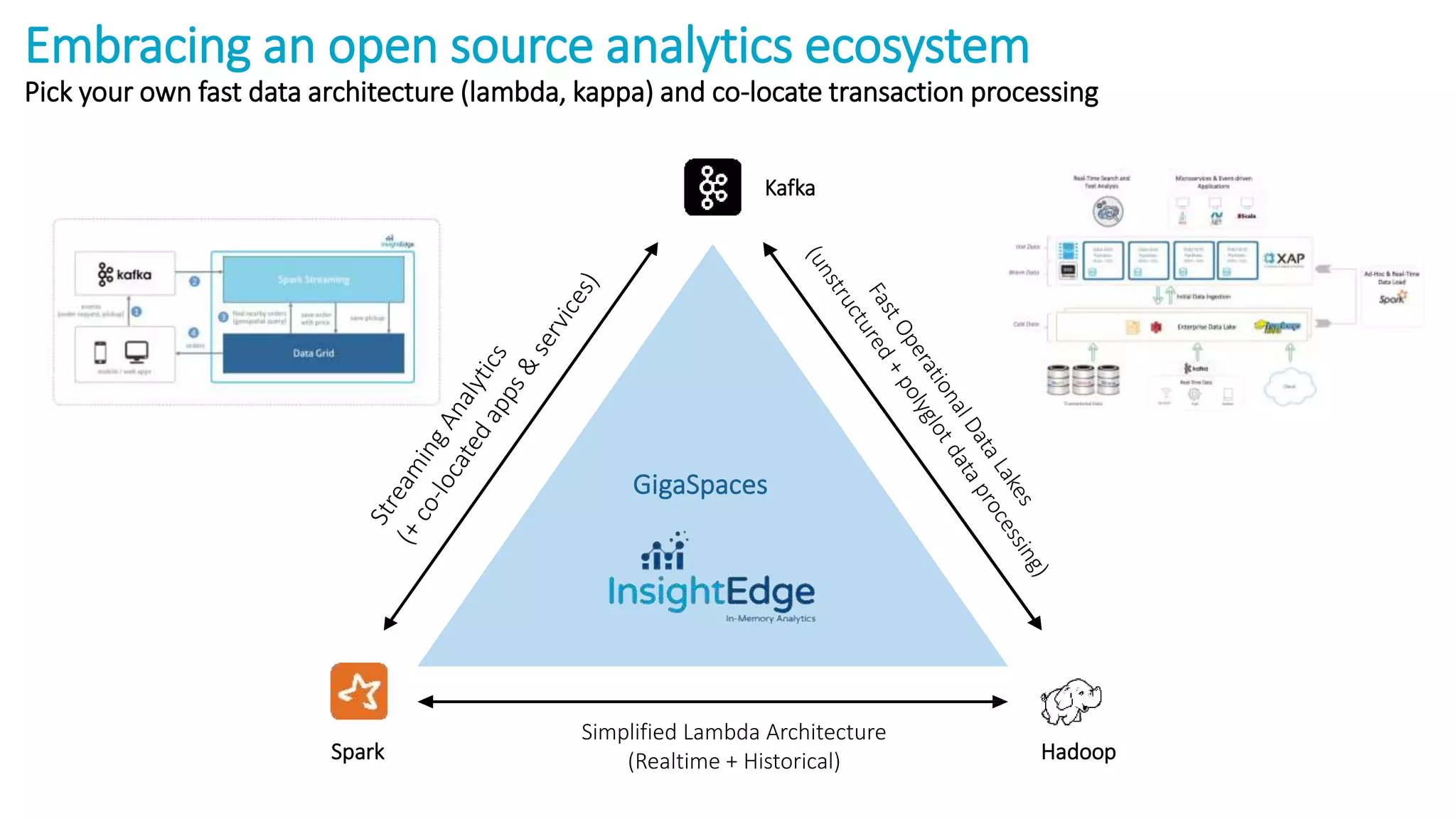
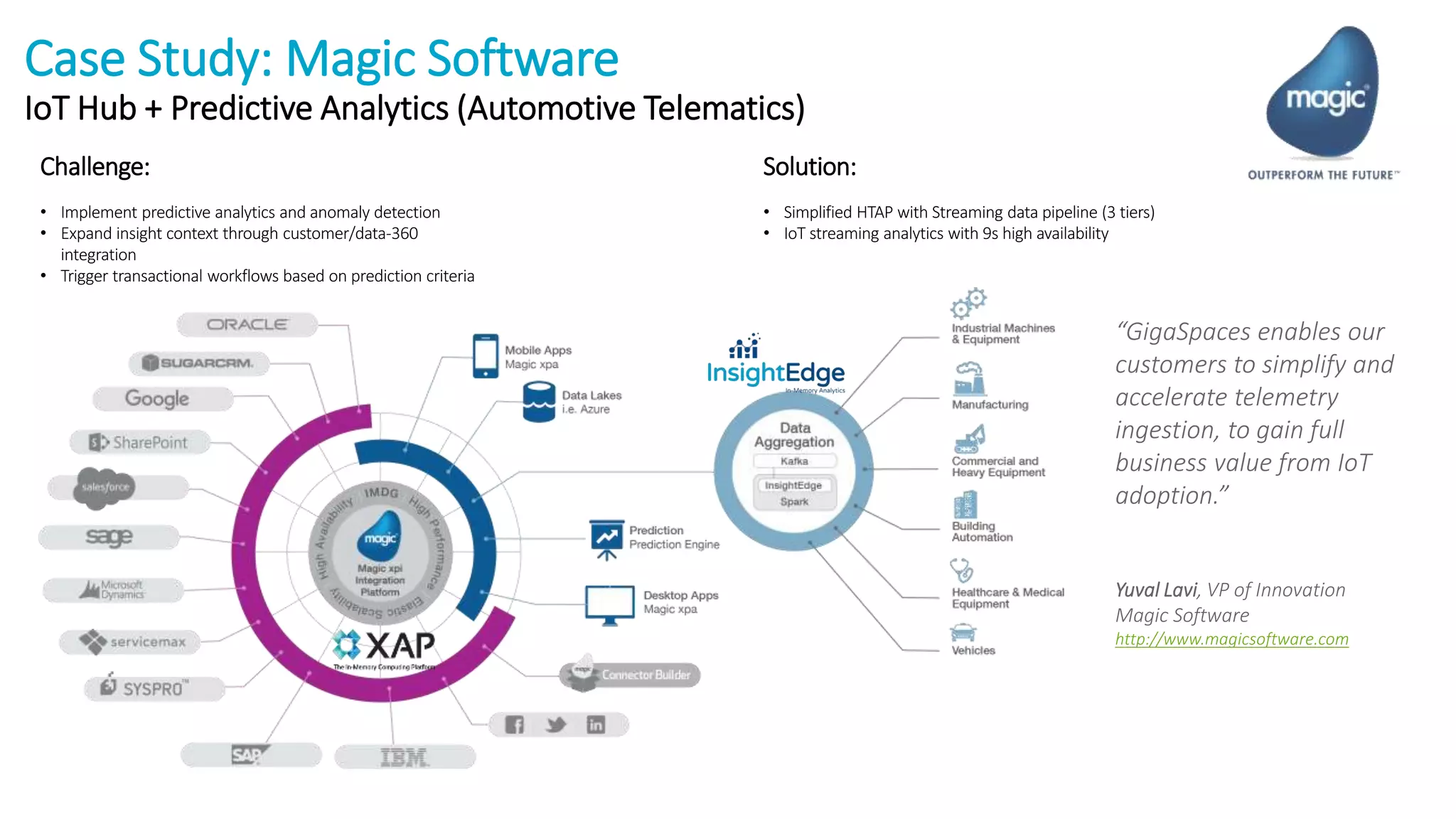





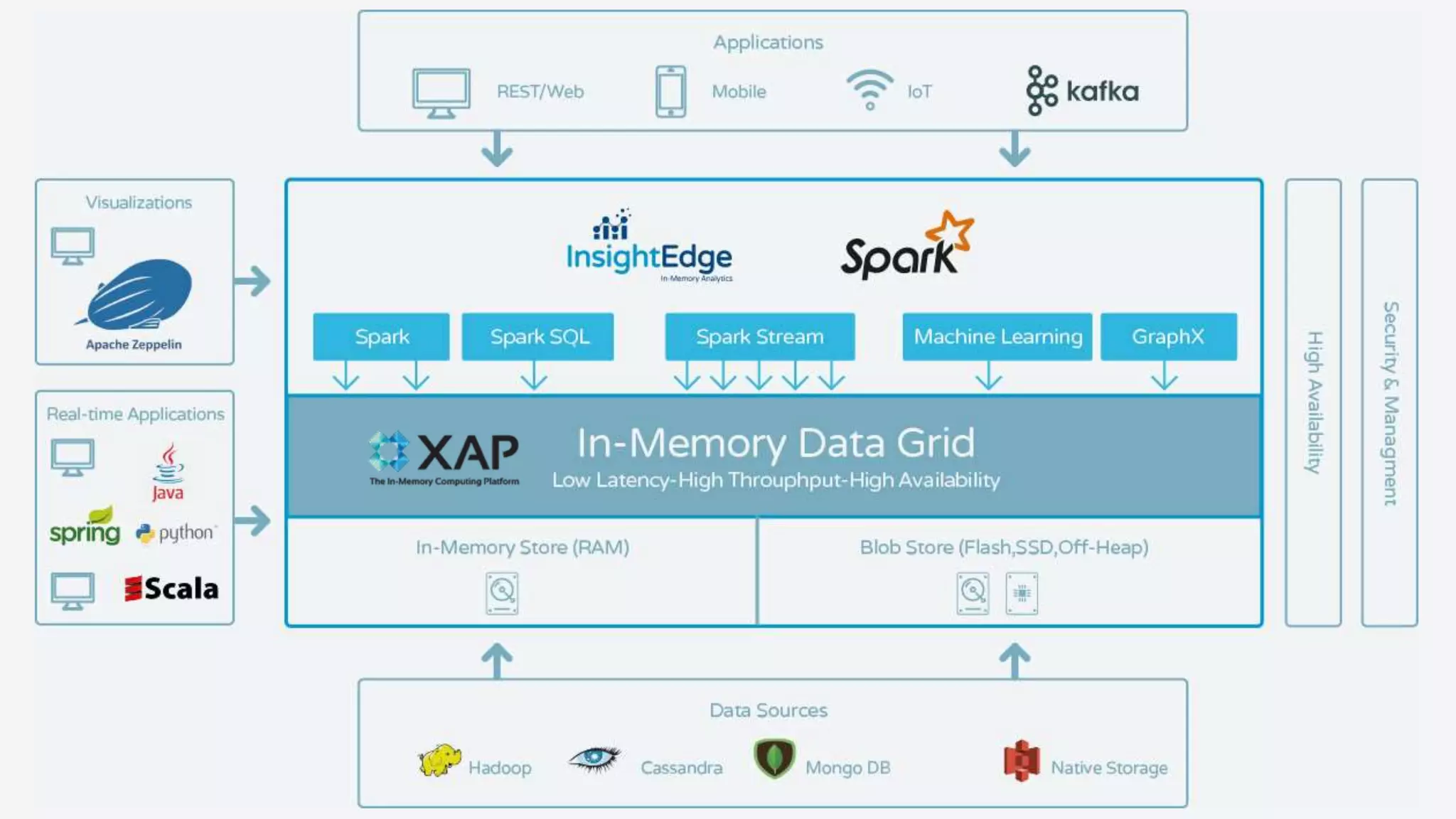
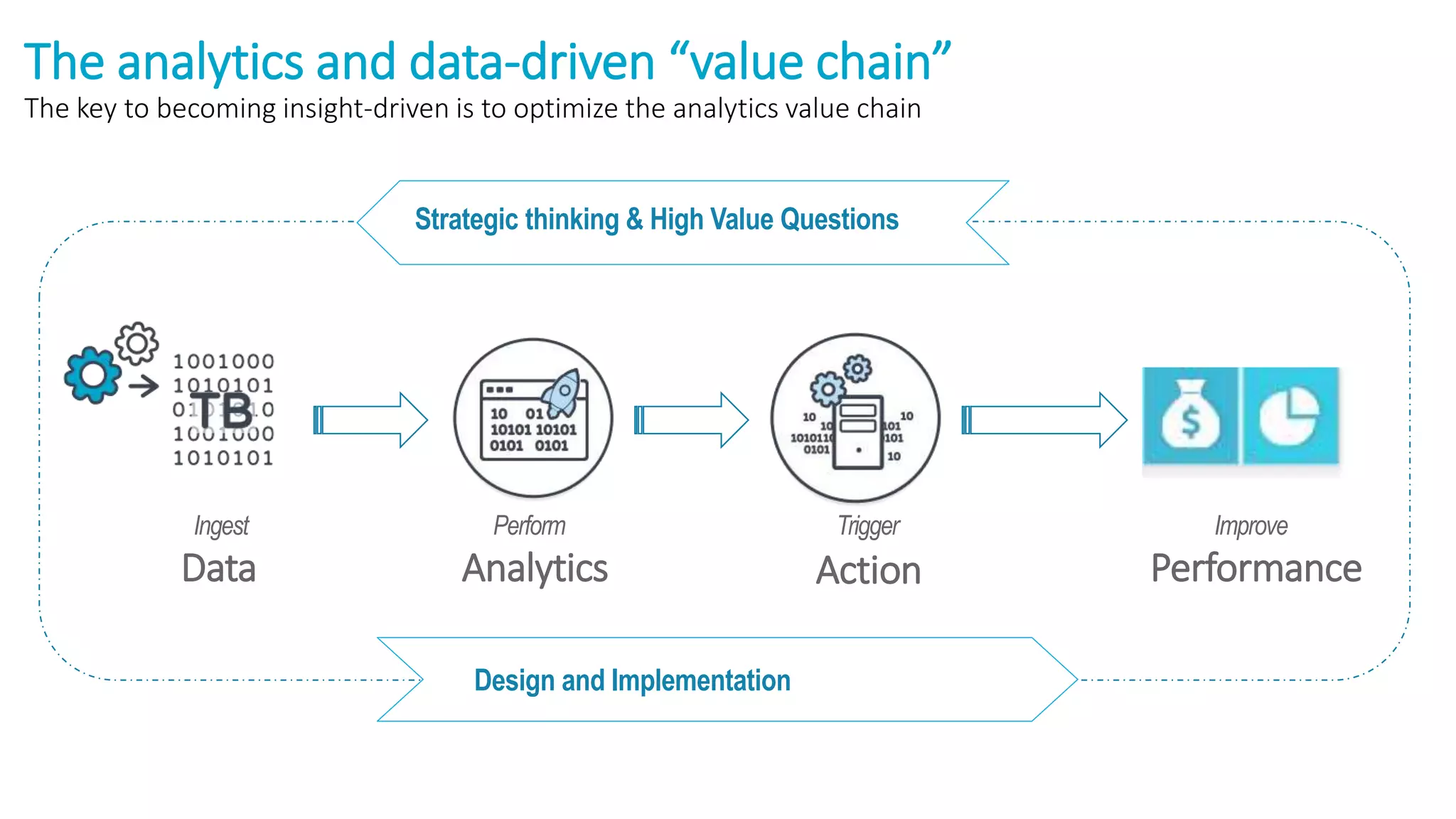
The document discusses the transformation of data to services leveraging microservices and in-memory computing for analytics-driven businesses. It highlights challenges such as slow innovation and misalignment with business decisions, and proposes solutions through distributed analytics architectures. It emphasizes the importance of real-time insights and agile data-driven decision-making to optimize performance and value generation for organizations.





















![[Webinar] Getting to Insights Faster: A Framework for Agile Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/agile-big-datav2-131122164332-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)










