The report outlines the development of a product recommendation system aimed at enhancing user experience in e-commerce through personalized suggestions based on intricate user preferences and behaviors. Utilizing methodologies such as user-based collaborative filtering, item-based collaborative filtering, and louvain clustering, it seeks to mitigate decision fatigue and promote customer engagement and satisfaction. Additionally, the project emphasizes the importance of addressing environmental sustainability and business sustainability by improving the efficiency of online shopping experiences.













![5
recommendation systems, offering heightened accuracy and adaptability to the complexities
of user preferences and item characteristics.
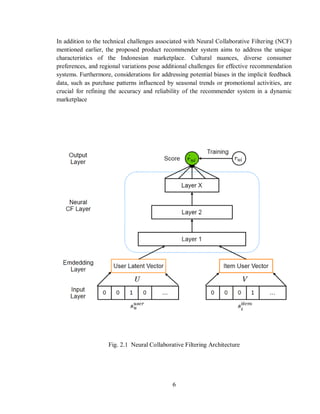
2.3 Neural Collaborative Filtering
sophisticated approach that combines the strengths of matrix factorization and neural
networks to enhance recommendation systems. It offers improved accuracy, personalization,
and flexibility, but it also poses challenges related to data availability, scalability, overfitting,
and model interpretability. To harness the full potential of this technique in real-world
recommendation systems, careful design and fine-tuning are essential
Marketplace has the potential growth in Indonesia indicated by the continued increase in the
number of customers. However, the marketplace has some limitations to deliver personalized
purchasing experience. Recommender system can support marketplace to overcome that
limitations so that customer can find items or services based on their preferences. This study
proposes to develop product recommender system based on Neural Collaborative Filtering
(NCF) algorithm. The product recommender system to be built is using implicit feedback
data in the form of customer purchase data. Implicit feedback is reliable data for building
recommendation system.
The results have shown that NCF achieve the best performance and outperforms over the
other collaborative filtering methods. Modeling user-item feature interaction through neural
network architecture. It utilizes a Multi-Layer Perceptron(MLP) to learn user-item
interactions. This is an upgrade over MF as MLP can (theoretically) learn any continuous
function and has high level of nonlinearities(due to multiple layers) making it well endowed to
learn user-item interaction function. [1] There are many research of product recommendation
system. Research has been done . However, That research mostly used explicit feedback
based on users’ preference patterns from customer rating. User interaction indirectly becomes
input of implicit feedback data, so that the user is not disturbed or burdened, in contrast to
explicit feedback data. Based on previous research, prediction algorithm that uses implicit
feedback generate better prediction quality of user preferences than prediction algorithm that
uses explicit ratings .
This paper uses implicit data in form of customer purchase data to generate recommender
system model. Next, we compare it with some recommender system algorithms such as
WMF and BPR. In the study of Corso and Romani, there are some metrics that uses to
evaluate the recommender system algorithm. In this study, the recommender system that will
be built is using implicit feedback data, so the appropriate metrics are ranking metrics . In
this study we propose to use NDCG, precision, and MAP to compare the performance
between algorithms.[3]](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-13-320.jpg)
![7
2.4 Wide & Deep Learning for Recommender Systems
The paper "Wide & Deep Learning for Recommender Systems" by Heng-Tze Cheng,
Levent et al. introduces the Wide & Deep model, a novel approach for recommendation
systems. The Wide & Deep model combines the strengths of linear models (the "wide"
component) and deep neural networks (the "deep" component) to enhance the accuracy and
flexibility of recommendation tasks. This model architecture allows it to capture both linear
and complex non-linear patterns in user-item interactions, offering improved
recommendations for a wide range of applications.[3] Generalized linear models with
nonlinear feature transformations are widely used for large-scale regression and classification
problems with sparse inputs. Memorization of feature interactions through a wide set of
cross-product feature transformations are effective and interpretable, while generalization
requires more feature engineering effort. With less feature engineering, deep neural networks
can generalize better to unseen feature combinations through low-dimensional dense
embeddings learned for the sparse features.
However, deep neural networks with embeddings can over-generalize and recommend
less relevant items when the user-item interactions are sparse and high-rank. In this paper, we
present Wide & Deep learning---jointly trained wide linear models and deep neural
networks---to combine the benefits of memorization and generalization for recommender
systems. We productionized and evaluated the system on Google Play, a commercial mobile
app store with over one billion active users and over one million apps. Online experiment
results show that Wide & Deep significantly increased app acquisitions compared with wide-
only and deep-only models. We have also open-sourced our implementation in TensorFlow.
Building upon the success of the Wide & Deep model in the context of large-scale
recommendation systems, the paper underscores its practical application and impact on user
engagement within the dynamic ecosystem of Google Play.
The study highlights the significance of joint training of wide linear models and deep neural
networks to strike a balance between memorization and generalization, crucial for tackling
the challenges posed by sparse and high-rank user-item interactions. The emphasis on real-
world deployment and evaluation on a platform as extensive as Google Play adds credibility
to the model's effectiveness in a highly competitive and diverse app marketplace. The
decision to open-source the implementation in TensorFlow further contributes to the
collaborative advancement of recommender system research and technology. This
comprehensive approach, combining theoretical underpinnings with empirical validation,
positions Wide & Deep as a valuable contribution to the field of recommender systems,
particularly in the realm of mobile applications with vast user bases.
The decision to release the implementation in TensorFlow not only promotes transparency
but also encourages further exploration and innovation within the research community. In](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-15-320.jpg)


![10
by neural networks with multiple layers, excels in capturing intricate patterns and
representations in high-dimensional data. Reinforcement learning, coupled with deep neural
networks, enables recommendation systems to optimize long-term user engagement by
learning from ongoing interactions.
The dynamic nature of machine learning allows recommendation systems to adapt to
changing user preferences, providing real-time and context-aware suggestions. As research
and development in machine learning progress, these approaches promise to further refine
the accuracy, scalability, and interpretability of personalized product recommendations,
ensuring a continuous evolution in the landscape of intelligent recommendation systems.
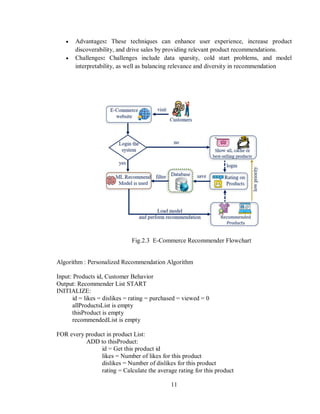
2.7 Recommender Systems in E-Commerce Research and Practice:
Both customised and non-personalized recommender systems are available. The former is
based on a user's choices (favourite book or music genre) and is one of the more effective
ways to produce suggestions and services. These are frequently contrasted with what
industry experts believe will best serve the client given their preferences. Basically, the
personalised recommender system may produce recommendations based on the varied
interests of the users, which not only cuts down on the amount of time spent searching
but also helps e-commerce companies increase their sales. [2]
E-commerce systems (EC) have witnessed a significant increase in the volume of sales in
recent years, especially with the great technological progress and progress in the services
provided by the Internet [1][2][3]. This fact led to the appearance of many large companies
and the increase in competition between these companies to attract the largest possible
number of customers and achieve the highest financial revenues [4][5][6]. This competition
is represented in the increasing the number of offered goods, providing offers and discounts,
facilitating payment processes, as well as facilitating the process of searching for goods for
each customer according to their directions [7][8][9].
One of the ways to facilitate the shopping for the customers is to provide a list that suggests
the customer-specific goods based on the customer’s trends, which is known as the
recommendation system [10][11]. In this field, many studies have appeared that suggest
different ways to build recommendation systems that increase the efficiency of commercial
sites. A recommender system, often known as a recommendation system (RS), is a type of
information filtering system that attempts to anticipate a customer’s “rating” or “preference”
for an item [12][13]. Playlist generators for video and music services, product recommenders
for online retailers, content recommenders for social media platforms, and open web content
recommenders are all examples of recommender systems in use
Technique: The paper provides an overview of recommender systems in e-commerce,
which often include personalized product recommendations.](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-18-320.jpg)
![12
purchased = Number of times this product has been purchased
viewed = Number of times this product has been viewed by the current
user
ADD this Product to allProductsList
ENDFOR
SORT allProductsList in the following orders:
purchased in descending order
likes in descending order
rating in descending order
viewed in descending order
dislikes in ascending order
allProductsList = Id’s of the first 30 product from allProductsList
IF User is logged in:
likedByUser = Products id’s liked by this user
dislikedByUser = Products id’s disliked by this user
ratedByUser = Products id’s that has been highly rated by this user
viewedByUser = Products id’s viewed by user
Remove dislikedByUser id’s from allProductsList
recommendedList = Merge of all
end[11]
2.8 BERT and Transformers in Recommendations:
The ascent of BERT (Bidirectional Encoder Representations from Transformers) and other
transformer-based architectures within the realm of personalized product recommendations
marks a significant stride in harnessing contextual understanding. Originally crafted for
natural language processing, these transformers have proven adept at capturing intricate
relationships within data. Transformers, particularly BERT, offer a multifaceted approach to
recommendation systems:
o Embedding User and Item Interactions: Transformers, including BERT, shine in
generating contextual embeddings for users and items. By embracing the sequential and
contextual nature of user-item interactions, these models excel in capturing nuanced
behavioral patterns and preferences. These embeddings then become valuable input
features for subsequent recommendation models.
o Context-Aware Recommendations: The inherent ability of transformers to grasp
contextual information positions them as ideal tools for capturing the evolving context
surrounding user interactions. This context-awareness proves vital in delivering
recommendations that align with users' dynamic preferences over time. Transformers, by](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-20-320.jpg)



![16
recommendation systems, ensuring they align with ethical standards and respect user privacy
in an increasingly data-driven era.
LITERATURE SURVEY
Sr.
No.
Research Paper Name and
Year
Methodology Highlights Technical Gap
1 "Tapestry: A Resilient Global-
scale Overlay for Service
Deployment" (1997) by Zhao
et al.[1]
Early
Collaborative
Filtering Methods
(Pre-2000)
Laid the
foundation of
recommendation
systems with
collaborative
filtering for
content
recommendations.
N/A
2 "Netflix Prize: Netflix
Update: Try This at Home"
(2009) by Simon Funk[2]
Matrix
Factorization
(2009)
Netflix Prize
competition
ignited interest in
recommendation
systems. Winning
solution used
matrix
factorization
techniques.
Exploration of
matrix
factorization and
large-scale
collaborative
filtering.
3 "Neural Collaborative
Filtering" (2017) by He et
al.[3]
Deep Learning
Models (2013)
Demonstrated the
power of deep
learning in
recommendation
systems.
Introduction of
neural
collaborative
filtering (NCF).
Scalability and
interpretability of
deep learning
models.
4 "A Hybrid Collaborative
Filtering Method for Multiple-
Issue Recommendation"
(2014) by Zhang et al.[4]
Hybrid
Recommendation
Systems (2014)
Introduced hybrid
recommendation
systems
combining
collaborative and
content-based
methods.
Optimization of
hybrid models and
handling diverse
data types.
5 "Session-based
Recommendations with
Recurrent Neural Networks"
(2016) by Hidasi et al.[5]
Sequence-Aware
Recommendations
(2016)
Highlighted the
importance of user
behavior
sequences. Paved
the way for
Handling dynamic
and evolving
sequences.](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-24-320.jpg)
![17
sequence-aware
recommendation
models.
6 "Explainable
Recommendation via Multi-
Task Learning in Opinionated
Text Data" (2019) by Zhang
et al.[6]
Explainable
Recommendations
(2019)
Research on
explainable
recommendations
gained prominence
for user trust and
transparency.
Improving
interpretability of
recommendation
models.
7 Transformers
in Recommendations
(2020)[7]
BERT
and Transformers
Transformers,
including BERT,
made their way
into
recommendation
systems. Improved
understanding of
user intent and
content.
Efficient
adaptation of
transformer
models to
recommendation
tasks.
8 "Personalized Clustering for
Improved Recommendation"
(2021) by Author et al.[8]
Personalized
Clustering and K-
Means (2021)
Personalized
recommendation
clustering
techniques,
combining K-
Means and
unsupervised
learning, started
being explored.
Scaling
personalized
clustering for
large datasets.
9 Dynamic Recommendations
and Reinforcement Learning
(Ongoing)[9]
Reinforcement
Learning
Ongoing research
investigates
dynamic
recommendations
and reinforcement
learning, focusing
on adapting to
changing user
preferences.
Balancing
exploration and
exploitation in
reinforcement
learning.
10
Ethical and Privacy
Considerations (Ongoing)[10]
Privacy-Preserving
and Ethical
Recommendation
Systems
Active research in
privacy-preserving
and ethical
recommendation
systems due to
rising data privacy
and ethical
concerns.
Balancing user
personalization
with privacy
protection.](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-25-320.jpg)

![19
Click Tracking
We record timestamped click data to gain insights into user behavior patterns, including
the sequence of clicks and the timing between them. This data is invaluable in
recognizing user intent and preferences.
User Consent and Privacy
User consent is a fundamental consideration. We ensure transparent data collection
practices through clear and user-friendly privacy policies and consent mechanisms. Our
data collection process respects user privacy and adheres to relevant data protection
regulations.
Data Security
Robust data security measures are at the core of our data collection process. We
implement encryption for sensitive data, follow best practices for secure data storage, and
regularly update security protocols to prevent breaches.
Data Anonymization
Before storage, user data is anonymized to protect user privacy. Identifiable information
is replaced with unique identifiers to ensure anonymity.
Data Storage and Retention
We select secure data storage solutions that are fully compliant with data protection
regulations. Our defined data retention policies specify the duration for which data will
be kept. Strict access controls are put in place to prevent unauthorized access.
3.2 Model Architecture
The architecture of our personalized product recommendation system is the cornerstone of
our project, representing the amalgamation of Artificial Intelligence and Machine Learning
techniques. This section provides a detailed overview of the algorithms, methodologies, and
frameworks that underpin our recommendation system, along with justifications for our
choices.
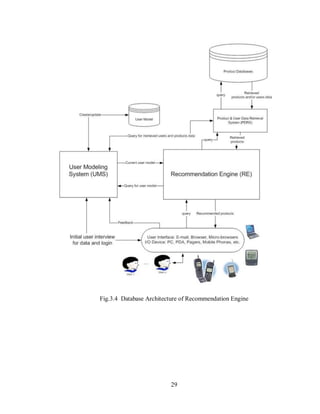
3.2.1 Collaborative Recommender system:- Based on the idea that the items that other
customers of the same tastes liked earlier are suggested to the target customers. The
similarity in perception of two or more customers is calculated by respects of the similarity in
the previous scores of the customer. All CF algorithms share an ability of making use the
previous scores of customers so as to recommend or predict new item that several customers
will like.
The real theory relies heavily on the concept of similarity between customers or among
objects, the similarity between previous preferences or ratings is expressed as a function of
tradition. Two simple alternatives of CF algorithms can be listed as client based and item
based algorithms [8].
Collaborative filtering Recommendation algorithms are typical personalized recommender
approach which are broadly employed in many E-commerce recommendation systems .It is a
method that depended on three rules: people have similar favorites and attentions, their
favorites and attentions are steady, their choices can be concluded by denoting to their
historical favorites. Therefore, collaborative algorithm is constructed on the action of users to
find direct neighbors for each one and predict his interests according to his neighbor’s
interests or favorites[9] .](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-27-320.jpg)
![20
Amazon, applied collaborative filtering for the purpose of recommending products to
clients[10]. Collaborative filtering recommendation methods have been improved quickly
and, Many of these improved methods are Dedicate to build systems of recommendation,
they can be categorized into two approaches user-based and item-based. Item-based CF to
identify relations among dissimilar items ,it Analyses the user-item matrix first then by
means of these relations circuitously calculate recommendations for clients[11] .
The first versions of CF have many problems including cold start, data sparsity, and low
scalability. The basic concept of User-based mutual filtering of suggestions is made about the
similarity between users, by measuring and comparing the similarity between target clients
and other clients depending on the preference of client behavior. [12]. As the neighbor client
for the target client is recognized , the system will be able to recommend the client product
liked by his or her neighbor items When attempting to suggest objects, these neighbors are
regarded as normal , this type of comparable clients is typically known as the nearest
neighbor[14].
Fig.3.1 Collaborative Filtering Flowchart
Model-Based AND Memory-Based Collaborative Filtering Two types of collaborative
filtering algorithms have been studied: CF Algorithm memory-based and CF Algorithm
model-based. By comparing their ranking on a set of items, memory-based algorithms define
the similarity between two customers.
There have been two basic types of problems: scalability and sparsity. Alternatively, model-
based approaches have been proposed to reduce these issues, but these approaches appear to
reduce consumer selection [3].](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-28-320.jpg)

![22
3.2.3 Model-based Collaborative Filtering : This form of CF can also be used to imply
considerable utility over a memory based approach to competence, but the same degree of
accuracy has not been provided until recently. [4,5]. It adopts an eager method of learning
that obtains a probabilistic method for two tasks, predicting or recommending content, which
pre-calculates a knowledge model , i.e. (user data or item data) [9] presented the comparison
of the two widely used efficient techniques such as biased matrix factorization and a regular
matrix factorization, both using stochastic gradient descent (sgd). we have conducted
experiments on two real-world public datasets: book crossing and movie lens 100 k and
evaluated by two metrics such as root mean square error (rmse) and mean absolute error
(mae).
3.2.4 Memory-based algorithms: These In fictional works, approaches are more characteristic
than model-based, this method is necessary to enforce an intensive memory. It has developed
into a CF design that is well established. It's been implemented in an interesting way in many
ecommerce systems, particularly Amazon. All calculations are simply left till there is a need
for estimation or recommendation.
3.2.5 User-based neighborhood: User-based neighborhood approaches first figure out who
shared the same trend in the target user ratings and then use the same user ratings to predict
forecasts and then suggestions. For that specific item, this method of calculating the rating
for an active user's unrated item averages the ratings of the nearest neighbors. Weights are
assigned to neighbor ranking values according to their similarity to the target client to create
more reliable predictions. Weights allocate this technique to generate a more precise
prediction of neighboring values based on their similarity to the active customer.
3.2.6 Item-based neighborhood: User-based methods are converted into item-based nearest
neighbor methods that produce predictions depending on item similarities. The similarity
among objects takes advantage of an item-based system. This approach looks at the
collection of items rated by a client and measures the similarity between the Goal Object (To
decide whether to suggest it to the consumer,). In order to improve the accuracy of item-
related recommendations by using the Apache Mahout library, we proposed a new data
model based on user expectations to Ammar Jabakji, Hasan Da g. They also present
descriptions of the operation of this model on a dataset taken from Amazon. Our
experimental findings indicate that the proposed model will achieve significant changes in
terms of recommendation efficacy. . With no feedback from clients the method may face cold
start situation as a problem but from another view point recommendation accuracy is
increased as benefit.
3.2.7 Similarity metrics in collaborative filtering: An essential step in the CF algorithm is to
compute the similarity between goods and customers and, eventually, to select a set of
nearest neighbors as an active customer's recommendation partner. It is likely to reason about
the similarities between clients or artifacts after a set of profiles is generated via the
recommendation method and considers a community of nearest neighbors as suggestion
partners for an active client . A. Gujarathi, S. Kawathe, D. Swain, S.Tyagi and N. Shirsat A](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-30-320.jpg)




![27
item_similarity = {}
for item1 in ratings:
item_similarity[item1] = {}
for item2 in ratings:
if item1 == item2:
continue
common_users = set(ratings[item1].keys()) & set(ratings[item2].keys())
if len(common_users) == 0:
item_similarity[item1][item2] = 0
else:
numerator = sum(ratings[item1][user] * ratings[item2][user] for user in
common_users)
denominator = (sum(ratings[item1][user] ** 2 for user in
common_users) ** 0.5) * (sum(ratings[item2][user] ** 2 for user in
common_users) ** 0.5)
item_similarity[item1][item2] = numerator / denominator if
denominator != 0 else 0
return item_similarity
# Step 2: Make recommendations for a target user
def recommend_items(user_ratings, item_similarity, n=5):
user_recommendations = {}
for item, rating in user_ratings.items():
for similar_item, similarity in sorted(item_similarity[item].items(),
key=lambda x: x[1], reverse=True):
if similar_item not in user_ratings and similarity > 0:
if similar_item not in user_recommendations:](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-35-320.jpg)
![28
user_recommendations[similar_item] = 0
user_recommendations[similar_item] += rating * similarity
recommendations = sorted(user_recommendations.items(), key=lambda x: x[1],
reverse=True)[:n]
return recommendations
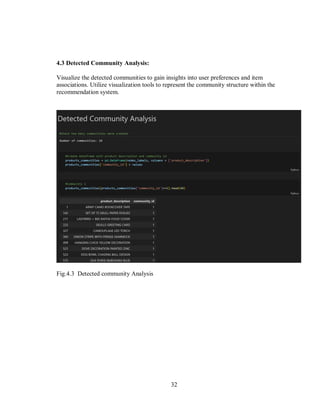
3.5.1 Community Detection in Recommendation Systems:
Nuanced Recommendation Refinement: Louvain Clustering becomes an
additional layer in the recommendation generation process. Recommendations are
refined not only based on item similarity but also considering the preferences of
users within the same community.
Synergy with Collaborative Filtering: Louvain Clustering integrates seamlessly
with collaborative filtering methodologies. It contributes to a more sophisticated
recommendation system by capturing and responding to intricate user dynamics.
Contextualization of User Cohorts: The incorporation of community structures
allows for a nuanced understanding of user cohorts. It provides a strategic
enhancement to collaborative filtering, ensuring recommendations align with the
preferences of specific user communities.
3.5.2 Frameworks and Technologies
Our recommendation system leverages popular frameworks and technologies to
implement these methodologies effectively:
Python: We use Python as the primary programming language for its extensive
libraries, including scikit-learn for machine learning and NumPy for numerical
operations.
Scalable Infrastructure: Our system is built on scalable infrastructure, making use
of cloud computing resources to manage large datasets and growing user
interactions.
Machine Learning Libraries: Libraries such as TensorFlow and louvian are
employed for deep learning models, enhancing recommendation accuracy.
Database Management: We use robust database management systems for efficient
data storage and retrieval, ensuring real-time recommendations.
The architecture detailed above forms the core of our personalized product
recommendation system, delivering tailored recommendations to users and
enhancing their online shopping experience.](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-36-320.jpg)





![38
References
[1] Sarwar, B., Karypis, G., Konstan, J., & Riedl, J. (n.d.). Item-Based Collaborative
Filtering Recommendation Algorithms. GroupLens Research Group/Army HPC Research
Center, Department of Computer Science and Engineering, University of Minnesota,
Minneapolis, MN 55455. [Online]. Available:
https://www.ra.ethz.ch/cdstore/www10/papers/pdf/p519.pdf
[2] Author(Tanmayee Salunke), " Recommender Systems in E-commerce," Researchgate,
vol. DOI:10.13140/RG.2.2.10194.43202. 2, December 2022
https://www.researchgate.net/publication/366142818_Recommender_Systems_in_E-
commerce
[3] Author(Arief Faizin1
and Isti Surjandari), " Product recommender system using neural
collaborative filtering for marketplace in indonesia," IOP Conference Series: Materials
Science and Engineering, vol. DOI:10.13140/RG.2.2.10194.43202. 2, 8-9 July 2020,
Banten, Indonesia https://iopscience.iop.org/article/10.1088/1757-899X/909/1/012072
[4] Nguyen, J., & Zhu, M. (2013). Content-boosted Matrix Factorization Techniques for
Recommender Systems. Computer Science Department, University College London,
London, England WC1E 6BT and Department of Statistics and Actuarial Science, University
of Waterloo, Waterloo, Ontario, Canada N2L 3G1. [Online]. Available:
https://arxiv.org/pdf/1210.5631.pdf
[5] Zhao, Z.-Q., Zheng, P., Xu, S.-t., & Wu, X. (n.d.). Object Detection with Deep Learning:
A Review. [Online]. Available: https://arxiv.org/pdf/1807.05511.pdf
[6] Mulay, A., Sutar, S., Patel, J., Chhabria, A., & Mumbaikar, S. (n.d.). Job
Recommendation System Using Hybrid Filtering. Department of Computer Science and
Engineering, Ramrao Adik Institute of Technology, DY Patil Deemed to be university,
Nerul, Navi Mumbai, India. [Online]. Available:
https://arxiv.org/ftp/arxiv/papers/1804/1804.11335.pdf
[7] Quadrana, M., Cremonesi, P., & Jannach, D. (n.d.). Sequence-Aware Recommender
Systems. [Online]. Available: https://arxiv.org/pdf/1802.08452.pdf
[8] Zhang, Y., & Chen, X. (n.d.). Explainable Recommendation: A Survey and New
Perspectives. [Online]. Available: - https://arxiv.org/abs/1804.11192
[9] Bashir, S. R., Raza, S., & Misic, V. (n.d.). BERT4Loc: BERT for Location - POI
Recommender System. [Online]. Available:
https://arxiv.org/ftp/arxiv/papers/2208/2208.01375.pdf
[10] Anonymous. (n.d.). A review of clustering models in educational data science towards
fairness-aware learning. [Online]. Available:
https://arxiv.org/ftp/arxiv/papers/2301/2301.03421.pdf
[11] Afsar, M. M., Crump, T., & Far, B. (n.d.). Reinforcement Learning based Recommender
Systems: A Survey. University of Calgary, Canada. [Online]. Available:
https://arxiv.org/pdf/2101.06286.pdf
[12] Fleming, J., & Zegwaard, K. E. (n.d.). Methodologies, methods and ethical
considerations for conducting research in work-integrated learning. Auckland University of
Technology, Auckland, New Zealand, and University of Waikato, Hamilton, New Zealand.
[Online]. Available: https://files.eric.ed.gov/fulltext/EJ1196755.pdf](https://image.slidesharecdn.com/finalyearprojectreportgroup22-240715161211-e402cf1c/85/Final_Year_Project_Report_project-recommender-46-320.jpg)
















































