Downloaded 17 times




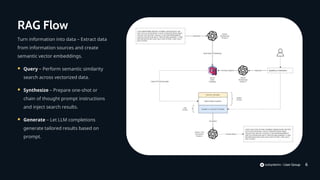





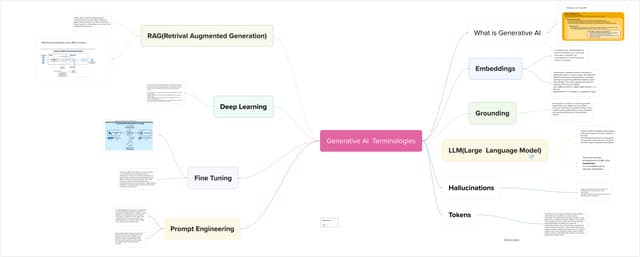
The document discusses Retrievable Augmented Generation (RAG), a technique to improve responses from large language models by providing additional context from external knowledge sources. It outlines challenges with current language models providing inconsistent responses and lack of understanding. As a solution, it proposes fine-tuning models using RAG and additional context. It then provides an example of implementing a RAG pipeline to power a question answering system for Munich Airport, describing components needed and hosting options for large language models.