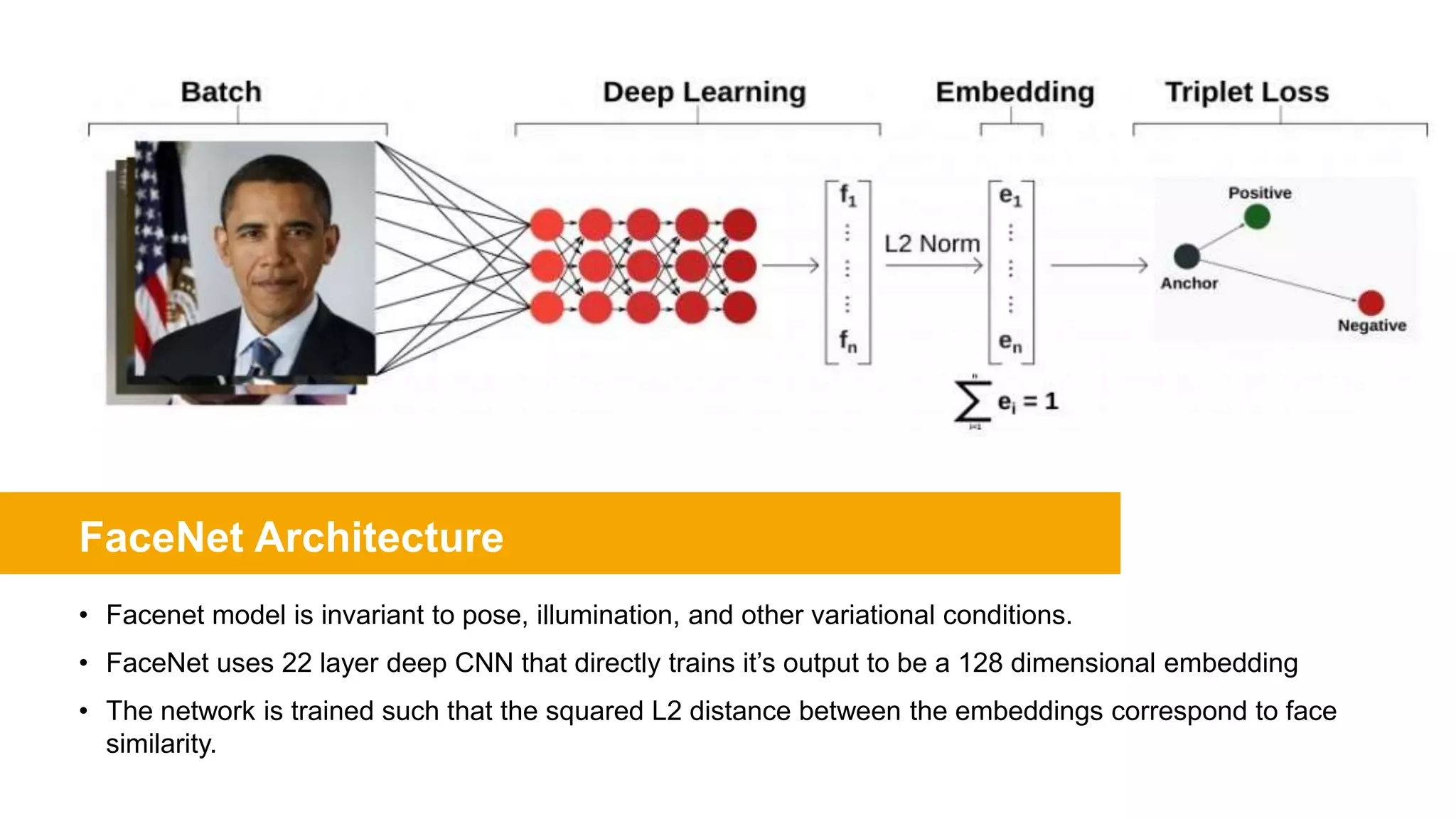
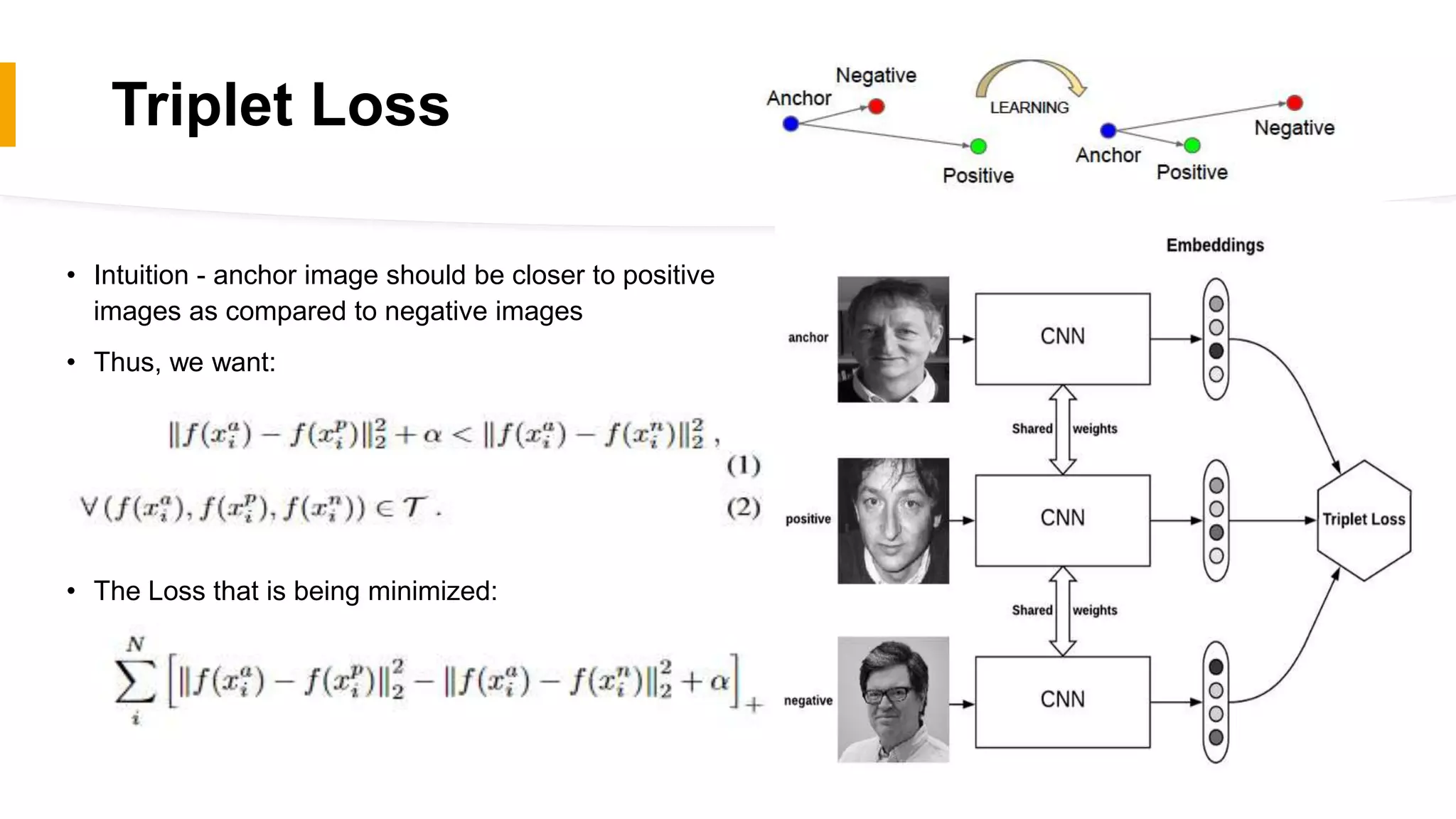
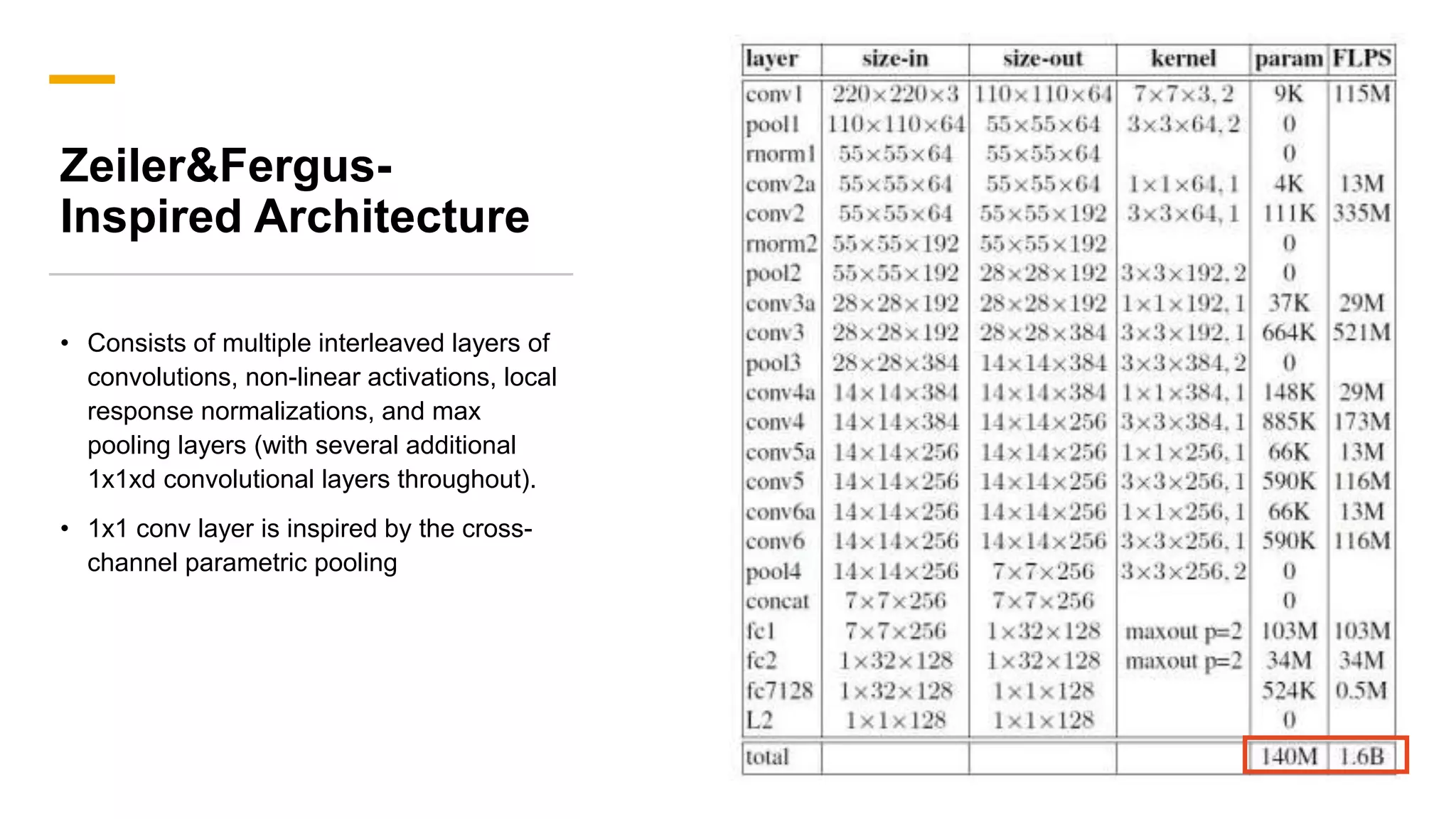
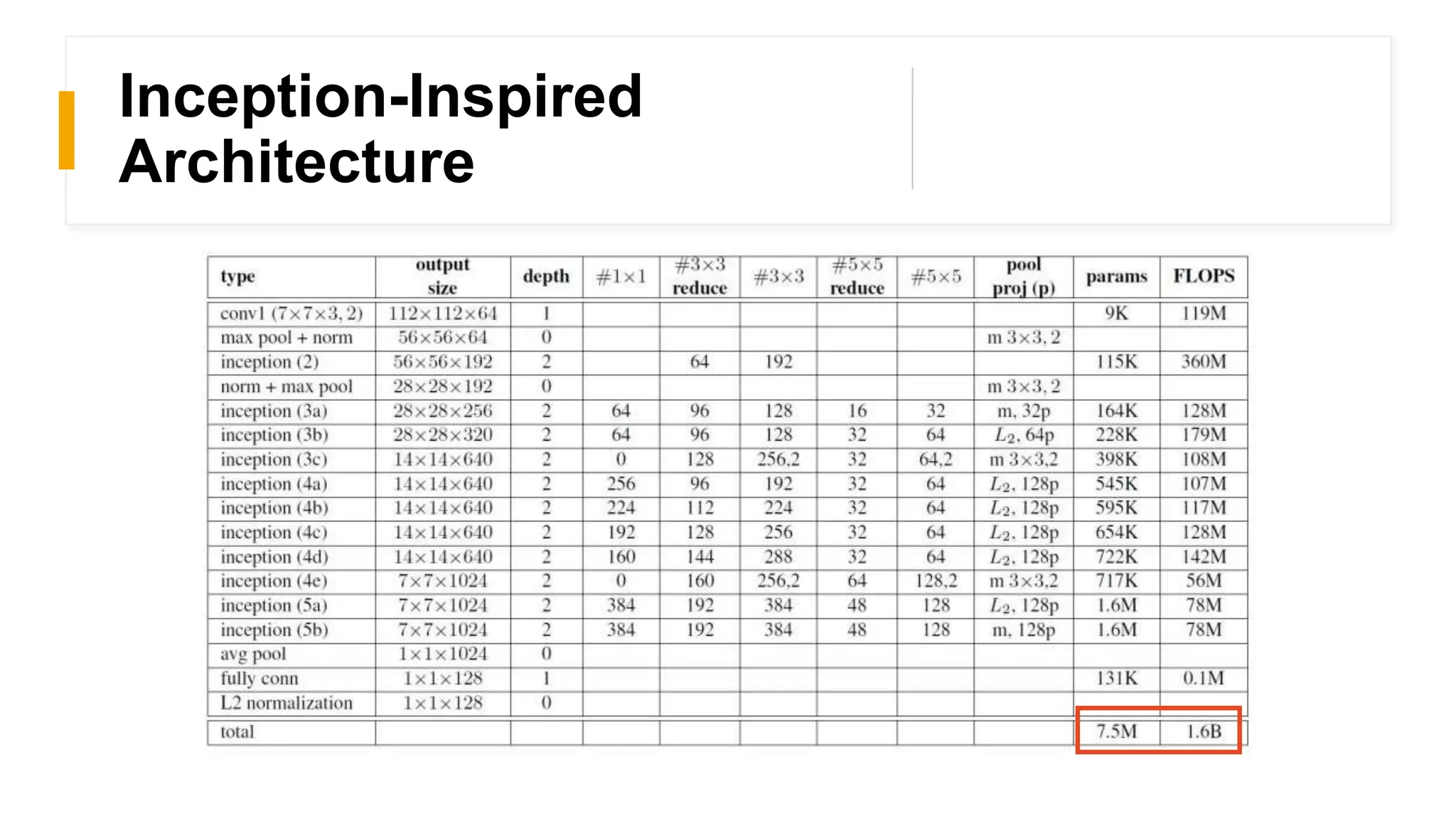
FaceNet provides a unified embedding for face recognition, verification, and clustering tasks using a deep convolutional neural network. It was developed by Google researchers and achieved state-of-the-art results on benchmark datasets, cutting the error rate by 30% compared to previous work. The model uses a 22-layer CNN that maps face images to 128-dimensional embeddings, where distances between embeddings correspond to face similarity. It was trained with triplet loss to optimize the embeddings.



![FaceNet Model Overview
• FaceNet provides a unified embedding for face
recognition, verification and clustering tasks.
• Developed by Google Researchers - Schroff et al. at
Google in their 2015 paper
• FaceNet learns a mapping from face images to a
compact Euclidean space where distances directly
correspond to a measure of face similarity.
• A deep CNN is trained to optimize the embedding itself
using a novel online triplet mining method.
• These face embeddings achieved state-of-the-art
results on standard face recognition benchmark
datasets (cuts the error rate in comparison to the best
published result [2015] by 30%](https://image.slidesharecdn.com/facedetection-220726113604-ee833928/75/Face-Detection-pptx-4-2048.jpg)



















![Handwritten Digit Recognition and performance of various modelsation[autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/presentationautosaved-210810075721-thumbnail.jpg?width=640&height=640&fit=bounds)

























































