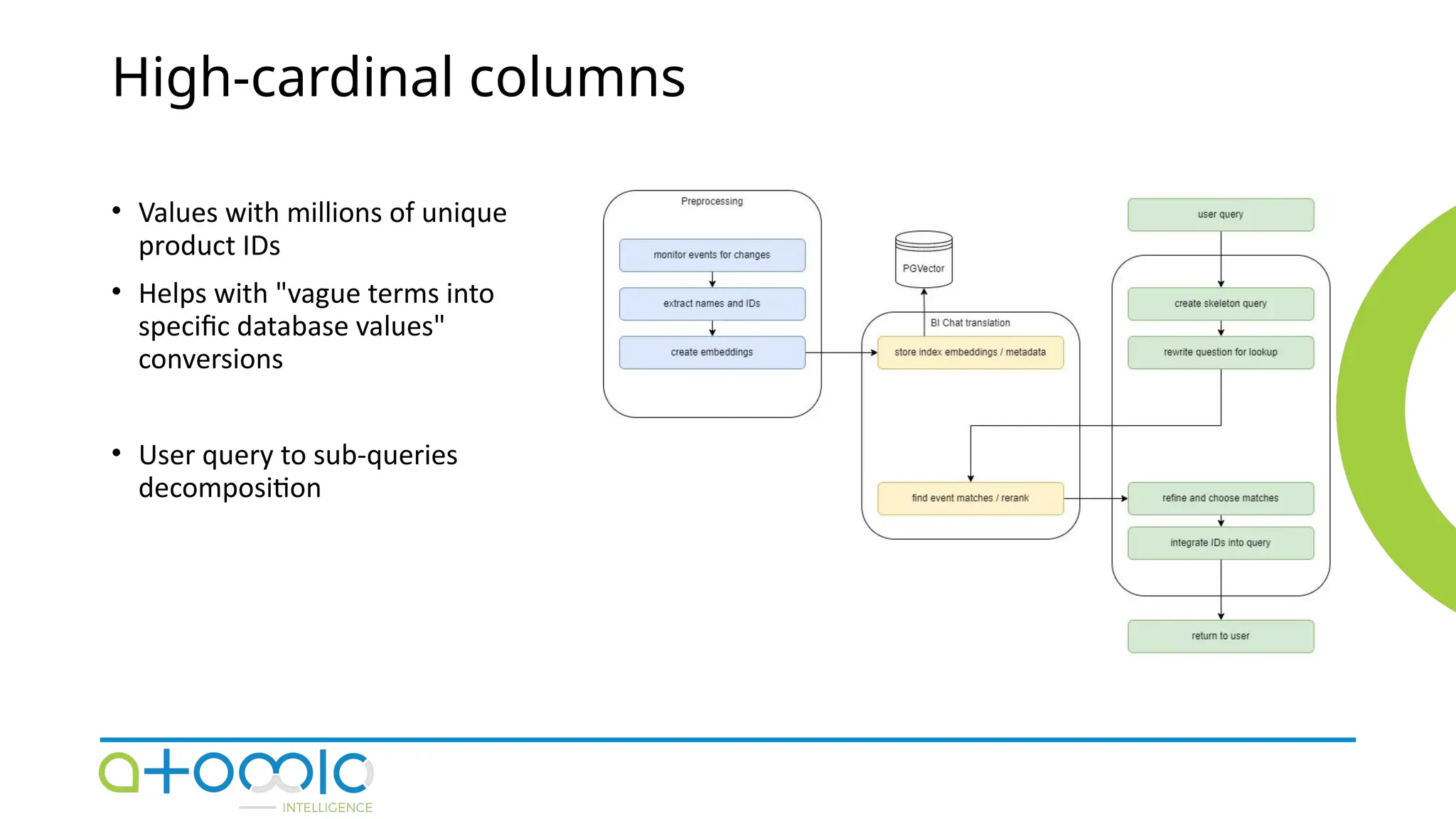
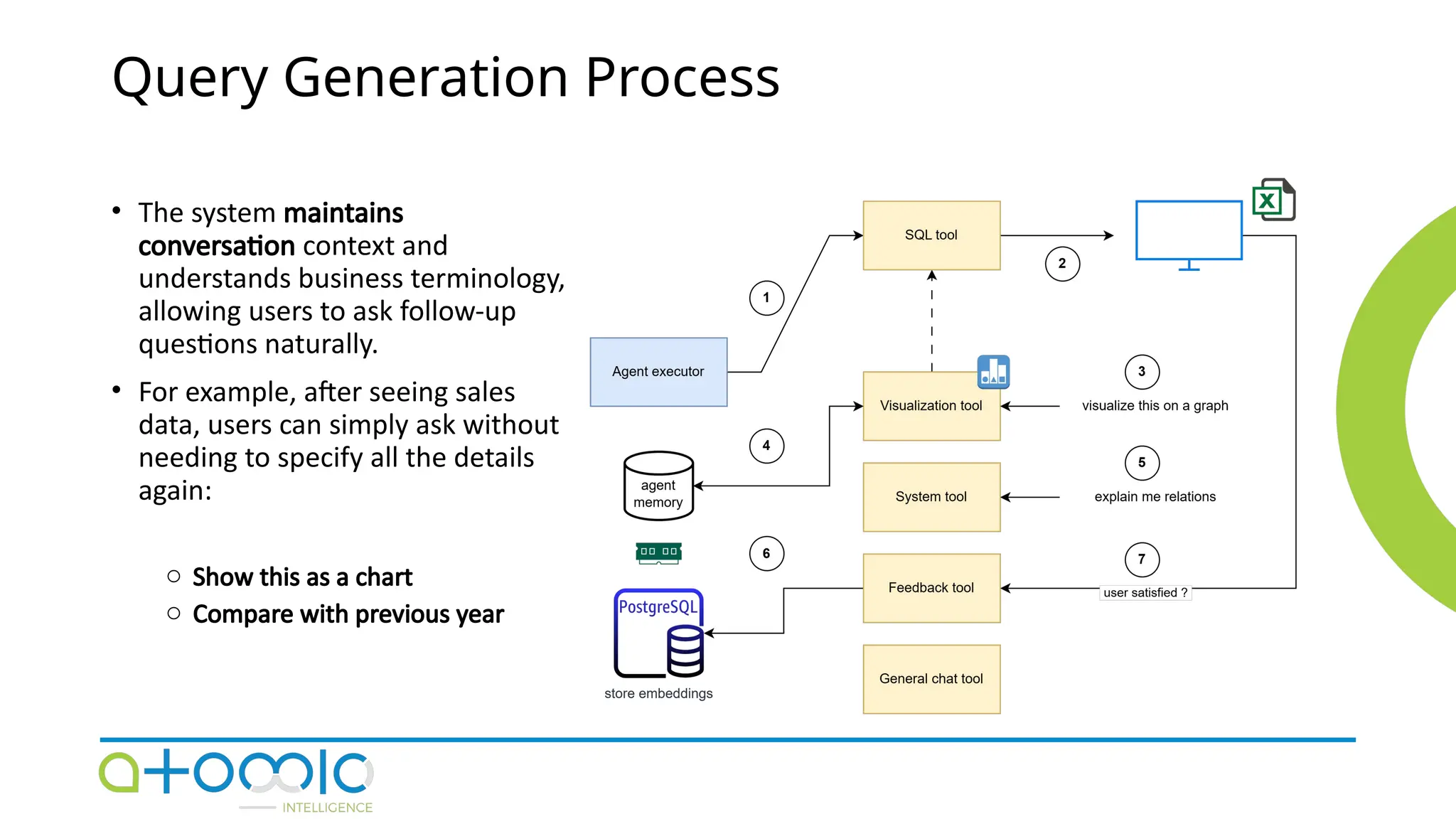
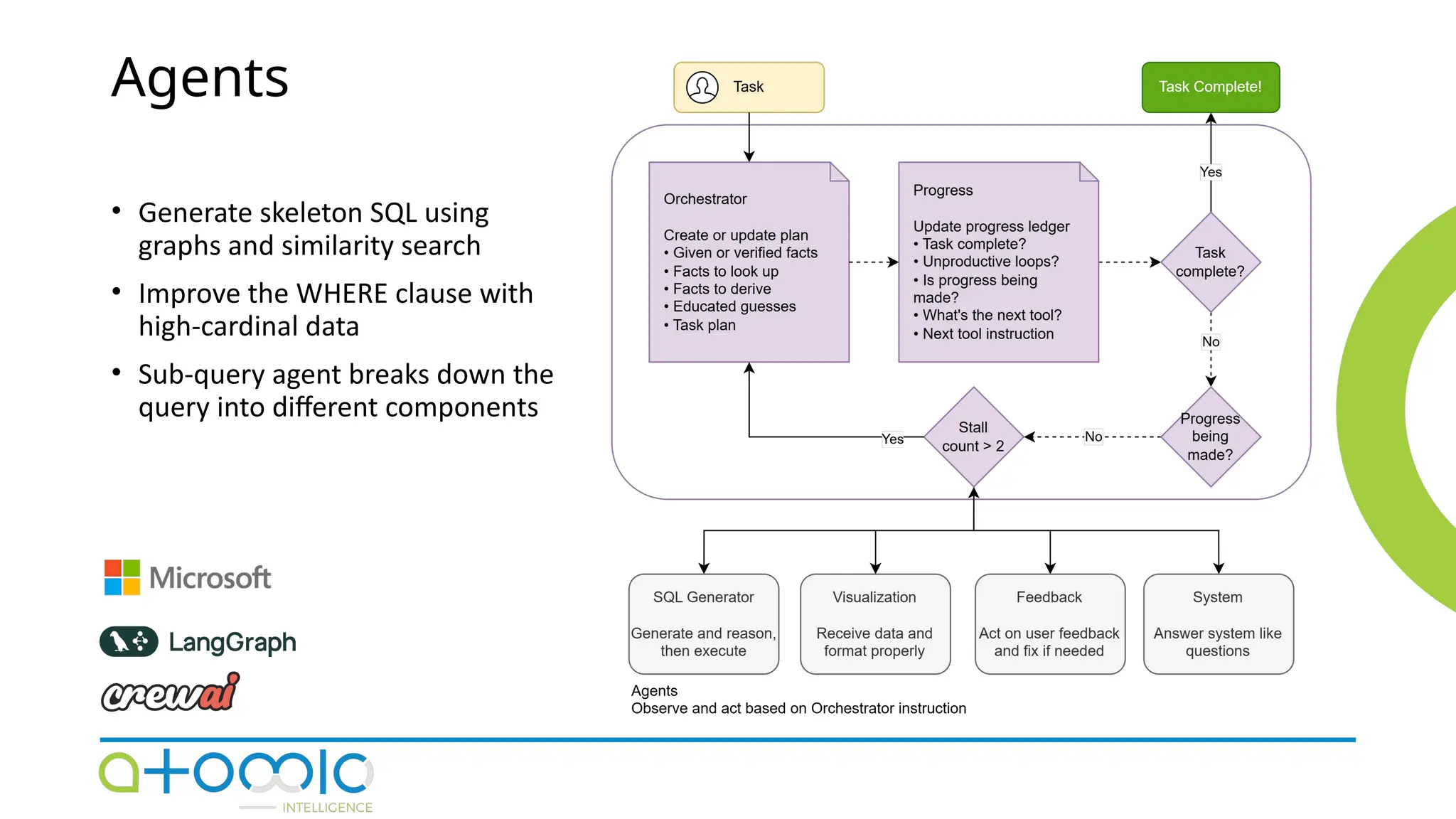
🌍📱👉COPY LINK & PASTE ON GOOGLE https://9to5mac.org/after-verification-click-go-to-download-page👈
It stands out in 3D modeling and animation by offering a unique technology known as "Meta mesh." This innovation allows you to seamlessly merge tree trunks and branches into a single surface, ensuring smooth transitions at their contact points. Additionally, Meta Mesh provides the freedom to craft tree trunks of any desired shape, giving you unparalleled control over the realism of your creations.